(2023,NAS & 进化算法 & 解释)用于少样本学习的神经微调搜索
Neural Fine-Tuning Search for Few-Shot Learning
公众号:EDPJ(添加 VX:CV_EDPJ 进交流群获取资料)
目录
0. 摘要
1. 简介
2.相关工作
2.1. 用于少样本学习的适应
2.2. 神经架构搜索(NAS)
3. 神经微调搜索(NFTS)
3.1. 少样本学习背景
3.2. 定义搜索空间
3.3. 训练超级网
3.4. 寻找最优路径
4. 实验
4.1. 实验设置
4.2. 与最新(state-of-the-art,SOTA)的比较
4.3. 消融研究
4.4. 更深入的分析
5. 结论
参考
S. 总结
S.1 主要思想
S.2 方法
0. 摘要
在 few-shot 识别中,已经在一组类上训练的分类器需要快速适应并泛化到一组不相交的新类。 为此,最近的研究表明了用精心设计的适应架构进行微调的功效。 然而这就提出了一个问题:如何设计最优的适应策略? 在本文中,我们通过神经架构搜索(neural architecture search,NAS)的视角来研究这个问题。 给定一个预先训练的神经网络,我们的算法会发现适配器(adaptor)的最佳安排,哪些层要保持冻结,哪些层需要微调。 我们通过将 NAS 方法应用于残差网络和视觉转换器(vision transformers,ViT)来展示其通用性,并报告元数据集和元相册上最先进的性能。
1. 简介
少样本识别 [23,33,51] 旨在从少数示例中学习新颖的概念,通常是通过快速自适应在一组不相交的标签上训练的模型。 许多解决方案采用元学习(meta-learning)视角 [16, 25, 38, 41, 43],或者在源类上训练强大的特征提取器 [44, 50] - 两者都假设训练和测试类从相同的底层分布中抽取,例如手写字符 [24] 或 ImageNet 类别 [48]。 后来的工作考虑了一个更现实和更具挑战性的问题变体,其中分类器不仅应该跨视觉类别,而且还应该跨不同的视觉领域执行少样本适应 [46, 47]。 在这种跨域问题变体中,针对新域定制特征提取器非常重要,一些研究通过动态特征提取器 [2, 40] 或特征集合 [12, 28, 32] 解决了这个问题。 另一组研究采用简单而有效的微调策略来适应 [10,21,29,53],这些策略主要是启发式的。 因此,之前的工作提出的一个重要问题是:如何设计最优的适应策略? 在本文中,我们朝着回答这个问题迈出了一步。
少样本适应的微调方法必须在适应大量或少量参数之间进行权衡。 前者可以更好地适应,但存在在少样本训练集上过度拟合的风险。 后者降低了过度拟合的风险,但限制了适应新类别和领域的能力。 最近的 PMF [21] 通过仔细调整学习率同时微调整个特征提取器来管理这种权衡。 TSA [29] 和 ETT [53] 通过冻结特征提取器权重并插入一些参数高效的适应模块来管理它,这些模块足够轻量,可以以几次镜头的方式进行训练。 FLUTE [45] 通过选择性微调一小部分 FILM [36] 参数来管理它,同时保持其中大部分参数固定。 尽管取得了这些进展,在小样本学习(few-shot learning,FSL)微调方法中管理适应/泛化权衡的最佳方法仍然是一个悬而未决的问题。 例如,哪些层应该进行微调? 应插入哪种适配器以及插入何处? 虽然 PMF、TSA、ETT、FLUTE 等提供了一些直观的建议,但我们提出了一种更系统的方法来回答这些问题。
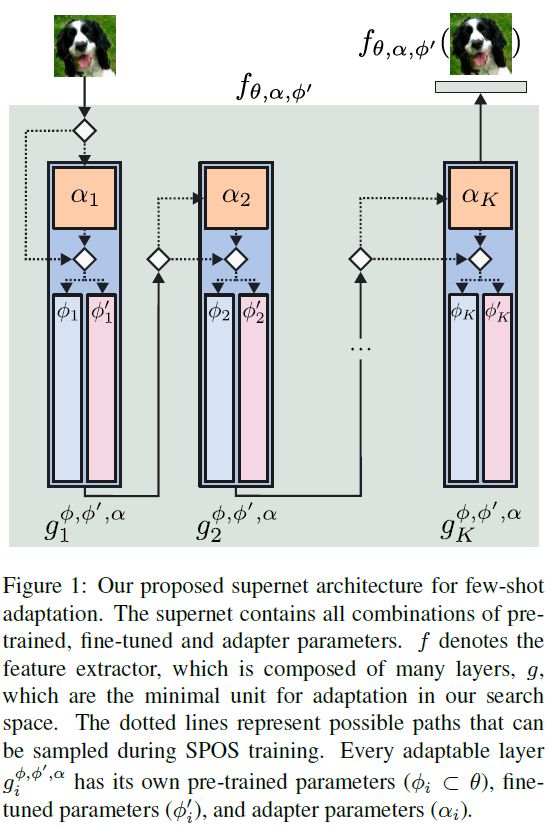
在本文中,我们通过开发神经架构搜索(NAS)算法来寻找最佳的自适应架构,从而推进了基于自适应的 FSL 范式。 给定初始预训练的特征提取器,我们的 NAS 确定应微调的架构子集,以及应插入自适应模块的层子集。 我们从 NAS [4,7,8,18,55] 最近的工作中汲取灵感,该工作提出了随机单路径一次性(Single-Path One-Shot,SPOS)[18] 权重共享策略的修订版本。 具体来说,给定预训练的 ResNet [19] 或 Vision Transformer (ViT) [11],我们考虑一个搜索空间,它由每层包含或不包含特定于任务的适配器以及可学习参数的冻结或微调来定义。 基于这个搜索空间,我们构建了一个超级网络 [3],通过在每个前向传递中采样随机路径来训练它 [18]。 我们的超网架构如图 1 所示,其中上述决策被绘制为决策节点 (⋄),可能的路径用虚线标记。
虽然超网训练与标准 NAS 方法有些相似,但由于 FSL 设置的固有特征,后续搜索提出了新的挑战。 具体来说,由于跨域 FSL 在测试时考虑了许多包括新域的数据集,因此搜索单个模型(NAS 中的普遍范式 [5,27,31,49])是否是最佳选择就变得值得怀疑了。 另一方面,每段(episode)架构选择太慢,并且可能会过度适应小型支持集。
受这些挑战的推动,我们提出了一种新颖的 NAS 算法,该算法在训练时列出少量架构上不同的配置,但推迟最终选择,直到在测试时已知数据集和段(episode)。 我们凭经验表明,这不仅计算效率高,而且还显着改善了结果,特别是当训练时只有有限数量的域可用时。 我们将我们的方法称为“神经微调搜索”(Neural Fine-Tuning Search,NFTS)。
NFTS 定义了一个与两个主要架构系列(即卷积网络和 transformers)相关的通用搜索空间,并且选择要考虑的特定适配器模块是一个超参数,而不是一个硬约束。 在本文中,我们考虑使用目前 ResNet 和 ViT(分别为 TSA 和 ETT)最先进的适配器模块,但可以将更多的自适应架构添加到搜索空间中。
2.相关工作
2.1. 用于少样本学习的适应
基于梯度的适应。参数高效的适应模块之前已应用于多域学习和迁移学习。 一个重要的例子是 Residual Adapters [39],它是添加到 ResNet 块中的轻量级 1x1 卷积滤波器。 它们最初是为多领域学习而提出的,但对于 FSL 也很有用,因为它们提供了更新特征提取器的能力,同时又足够轻量,以避免在少样本情况下严重过度拟合。 特定任务适配器 (TSA) [29] 将此类适配器与 URL [28] 预训练主干一起使用,以在元数据集基准 [46] 上实现 CNN 的最先进结果。 同时,出于类似的原因,提示 [22] 和前缀 [30] 调整是 transformer 架构参数有效适应的既定示例。 在 FSL 中,高效 transformer 调整 (Efficient Transformer Tuning,ETT) [53] 使用 DINO [6] 预先训练的主干网,将类似的策略应用于少样本 ViT 适应。
PMF [21]、FLUTE [45] 和 FT [10] 重点关注现有参数的自适应,而不插入新参数。 为了管理小样本机制中的适应/过度拟合权衡,PMF 微调整个 ResNet 或 ViT 主干网,但要仔细管理学习率。 同时,FLUTE 手工挑选一组带有修改后的 ResNet 主干的 FILM 参数,用于少样本微调,同时保持大部分特征提取器冻结。
上述所有方法都对适配器在骨干网中的放置位置或允许/禁止微调哪些参数进行启发式选择。 然而,由于不同的输入层代表不同的特征 [7, 54],因此可以更好地决定要更新哪些特征。 此外,在多域设置中,不同的目标数据集可能受益于关于要更新哪些模块的不同选择。 本文采用基于 Auto-ML-NAS 的方法来系统地解决这个问题。
前馈自适应。上述方法都使用随机梯度下降来更新自适应过程中的特征。 我们简要提到 CNAPS [40] 和导数(derivatives) [2] 作为使用前馈网络来调节特征提取过程的竞争性工作。 然而,与基于梯度的方法 [17] 相比,这些动态特征提取器不太能够泛化到全新的领域,因为适应模块本身存在分布外问题。
2.2. 神经架构搜索(NAS)
神经架构搜索(NAS)是一个大且经过充分研究的主题 [14],我们在这里不尝试对其进行详细回顾。 主流 NAS 的目标是发现新的架构,在多样本机制中从头开始对单个数据集进行训练时,可以实现高性能。 为此,研究旨在开发更快的搜索算法 [1,18,31,52] 和更有效的搜索空间[9,15,37,56]。 我们以流行的 SPOS [18] 系列搜索策略为基础,将整个搜索空间封装在一个超级网络中,该超级网络通过随机采样路径进行训练,然后搜索算法确定最佳路径。
我们针对多域 FSL 问题开发了 SPOS 策略的实例。 我们构建了一个搜索空间,适合将先前的架构参数有效地适应一组新的类别,并扩展 SPOS 以在一组数据集上学习,并有效地推广到新的数据集。 这与在相同数据集和相同类别集上进行训练和评估的传统 SPOS 范式不同。
虽然最近存在一些 NAS 工作试图有效地解决类似的 “训练一次,搜索多次” 问题 [4,26,34,35],但朴素地使用这些方法有两个严重的缺点:
- 他们假设在初始训练超网之后,后续搜索不涉及任何训练(例如,仅执行搜索以考虑不同的 FLOPs 约束,同时假设不同配置的准确性保持不变),因此可以有效地完成 - 这在如前所述的 FSL 设置中并非如此 。
- 即使在测试时朴素地搜索每个数据集在计算上是可行的,我们设置的少样本性质也会带来架构过度拟合每个 episode 中考虑的小支持集的重大风险。
3. 神经微调搜索(NFTS)
3.1. 少样本学习背景
![]()
![]()
![]()
分别是 D 个分类域的集合,包含 n 个样本的任务以及它们指定的真实标签。通过在包含很少示例的支持集
![]()
上进行训练,少样本分类被定义为学习正确分类查询集(query)的问题。
![]()
这可以通过找到目标为
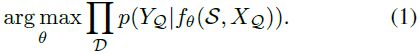
的分类器 f_θ 的参数 θ 来实现。在实践中,如果 θ 是在小支持集 S 上使用随机梯度下降随机初始化和训练的,它将过度拟合并且无法泛化到 Q。为了解决这个问题,可以利用从一些已知类到新类的知识迁移。 形式上,每个域 ˉD 被划分为两个不相交的集合 ˉD_train 和 ˉD_test,通常分别称为“元训练(meta-train)”和“元测试(meta-test)”。 这些集合中的标签也是不相交的,即 Y_train ∩ Y_test = ∅。 在这种情况下,通过使用元训练集最大化等式 1 中的目标来训练 θ,但总体目标是在将知识转移到元测试时充分执行。
从元训练转移到元测试的知识可以采取多种形式 [20]。 正如前面所讨论的,我们的目标是推广一系列的小样本方法 [21,29,53],其中参数 θ 在参数子集 φ ⊂ θ 被微调之前被传输; 并可能通过附加针对目标任务训练的附加“适配器”参数 α 来扩展。 对于元测试,等式 1 因此可以重写为
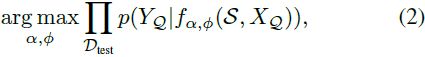
在本文中,我们重点关注根据以下方面找到最佳适应策略的问题:(i)需要微调的参数的最佳子集 φ ⊂ θ,以及(ii)要添加的最佳特定于任务的参数 α 。
3.2. 定义搜索空间
![]()
是架构中适应的最小单元。 我们认为这些是当代深度架构中的重复单元,例如 ResNet 中的卷积层或 ViT 中的自注意力块。 如果特征提取器 f_θ 由 K 个具有可学习参数 φ_k 的单元组成,则假设所有其他参数保持固定,我们表示
![]()
为了符号的简洁性,我们现在将省略索引并将每个这样的层称为 g_φ。 遵循最先进的技术 [21,29,45,53],我们还假设可以通过将额外的适配器参数 α 插入到 g_φ 中,或者通过微调层参数 φ 来执行特定于任务的适应 。
这允许我们将搜索空间定义为每层两个独立的二元决策:(i)包含或不包含附加到 g_φ 的适配器模块,以及(ii)决定是否使用预先训练的参数 φ 或它们经过微调的对应项 φ′ 进行替换。 因此,搜索空间的大小为 (2^2)^K = 4^K。 对于 ResNets,我们使用 TSA [29] 提出的自适应架构,其中残差适配器 h_α(由 α 参数化)连接到 g_φ
![]()
其中 x ∈ R^W,H,C。 对于 ViT,我们使用 ETT [53] 提出的自适应架构,其中可调整的前缀被添加到多头自注意力模块 A_qkv 之前,并且残差适配器被附加到每个解码器块中的 A_qkv 和前馈模块 z 中。
![]()
其中 x ∈ R^D 且 [· ; ·]表示串联操作。 请注意,在 ViT 的情况下,适配器不是输入特征的函数,而只是添加的偏移量。

无论架构如何,每一层
![]()
都由三组参数 φ, φ′ 和 α 参数化,分别表示初始参数、微调参数和适配器参数。 因此,当从该搜索空间中采样配置(即路径)时,每个这样的层都可以作为表 1 中列出的变体之一进行采样。
3.3. 训练超级网
遵循 SPOS [18],我们的搜索空间以超网
![]()
的形式实现; 一个“超级”架构,包含从第 3.2 节中详述的决策派生的所有可能的架构。 它的参数化如下:(i) θ,来自主干架构 f_θ 的冻结参数,(ii) α,来自适配器 h_α,以及 (iii) φ′,来自每层
![]()
的微调参数。
我们使用原型损失 L(f, S,Q) 作为超网训练以及随后的搜索和微调期间的核心目标。
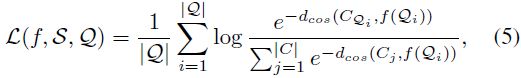
其中C_Qi表示对应于 Q_i 真实类别的类质心的嵌入,d_cos表示余弦距离。 类质心集 C 被计算为属于同一类的支持示例的平均嵌入:
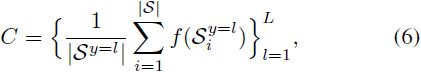
其中 L 表示 S 中唯一标签的数量。
具体来说,对于超网训练,令 P 为大小为 4^K 的集合,枚举可以从搜索空间采样的 K 层的所有可能序列。 将从超网采样的一个路径表示为
![]()
我们在多个 episodes 和路径上最小化等式 5 中损失的期望,因此最终目标变为:
![]()
算法1用伪代码总结了超网训练算法。

3.4. 寻找最优路径
使用第 3.3 节中描述的方法训练的超网
![]()
包含 4^K 个模型,通过权重共享交织在一起。 正如第 1 节中所解释的,我们的目标是寻找性能最好的模型,但主要挑战与我们不知道在测试时将使用哪些数据进行适应这一事实有关。 一种极端的方法是在训练时搜索单一解决方案,并在整个测试过程中简单地使用它,而不管潜在的领域转移如何。 另一种方法是推迟搜索,并在每次测试时向我们提供新的支持集时从头开始执行搜索。 然而,两者都有其缺点。 因此,我们提出了这一过程的概括,其中搜索分为两个阶段——一个阶段在训练期间,另一个阶段在测试期间。
元训练时间。 搜索负责从整个搜索空间中预选一个含有 N 个模型的集合。 其主要目的是减轻在测试时(当只有少量数据可用时)可能发生的潜在过度拟合,同时提供足够的多样性以成功地将架构适应到不同的测试域集。 形式上,我们搜索路径序列 (p1, p2, ..., pN),其中:
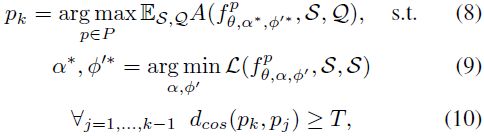
其中 T 表示路径 pk 和 pj 之间的余弦距离的标量阈值,A 是最近质心分类器(nearest centroid classifier,NCC)的分类精度[43],
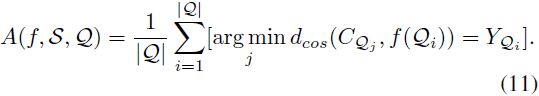
值得注意的是,我们使用查询集测量解决方案的准确性,在对单独的支持集进行微调后(等式 9),然后对多个 episode 进行平均,以避免过度拟合特定的支持集(等式 8)。 我们还采用了多样性约束,以所选路径的二进制编码之间的余弦距离的形式(等式10),以便在接下来的测试时间搜索中提供足够的灵活性。

为了有效地获得序列 {p1, ..., pN},我们使用进化搜索来查找使等式 8 最大化的点,然后从进化搜索历史中选择满足等式 10 中约束的 N个最佳表现者。算法 2 总结了训练时搜索。

元测试时间。 对于给定的元测试集,我们决定预选的 N 个模型中哪一个最适合适应给定的支持集数据。 当支持集可能特别超出域时,它可以作为故障保护来抵消训练时做出的初始选择的偏差。 正式地,特定 episode 中使用的最终路径 p* 定义为:
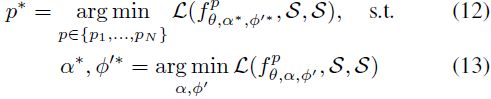
值得注意的是,我们通过在支持集(等式 13)上对其进行微调并在同一支持集(等式 12)上测试其性能来测试 N 个模型中的每一个。 这是因为支持集是我们在测试时拥有的唯一数据源,并且我们无法在不冒微调过程质量风险的情况下从中提取不相交的验证集。 值得注意的是,虽然此步骤存在过度拟合的风险,但如前所述,在训练时预先选择模型应该已经将后续搜索限制为仅不太可能过度拟合的模型。 由于 N 在我们的实验中保持较小,因此我们使用朴素网格搜索来查找 p*。
该方法是现有 NAS 方法的推广,因为它在 N = 1 或 N = 4^K 时都能恢复。 我们的主张是,由于前面提到的原因,N 的中间值比任何极端值更有可能为我们提供更好的结果。 特别是,我们希望预先选择 1 < N ≤ 4^K 模型,以便在测试时引入合理的开销,同时改善结果,特别是在训练时接触不同领域可能受到限制的情况下。 在我们的评估中,我们比较 N = 3 和 N = 1 来检验这一假设。 我们不包括与 N = 4^K 的比较,因为它在我们的设置中在计算上不可行(对每个测试集执行相当于训练时间搜索将需要我们总共微调 ≈ 14 * 10^6 个模型)。
4. 实验
4.1. 实验设置
元数据集评估。我们在元数据集 [40, 46] 的扩展版本上评估 NFTS,元数据集是目前最常用的少样本分类基准,由 13 个公开可用的数据集组成:FGVC Aircraft、CU Birds、Describable Textures( DTD)、FGVCx Fungi、ImageNet、Omniglot、QuickDraw、VGG Flowers、CIFAR-10/100、MNIST、MSCOCO 和交通标志。 有两种评估协议:单域学习和多域学习。 在单域设置中,在训练和元训练期间只能看到 ImageNet,而在多域设置中,可以看到前八个数据集(FGVC Aircraft 到 VGG Flower)。 对于元测试,每个域至少采样 600 个episode。
在元相册(Meta-Album)上评估。 此外,我们在最近引入的元相册上评估 NFTS [47]。 元相册比元数据集更加多样化。 我们使用当前可用的 Sets 0-2,其中包含跨越 10 个领域的 30 个数据集的 1000 多个独特标签,包括显微镜、遥感、制造、植物病害、字符识别和人类行为识别任务等。 默认评估协议为 variable-way variable-shot,元相册评估遵循 5-way variable-shot 设置,其中 shot 数量通常为 1、5、10 和 20。对于元测试,结果平均超过 1800 episodes。
架构。我们采用两种不同的主干架构,ResNet-18 [19] 和 ViT-small [11]。 遵循 TSA [29],使用知识蒸馏方法 URL [28] 在可见域上对 ResNet-18 主干进行预训练,并且按照 ETT [53],在 ImageNet 可见部分上,使用自监督方法 DINO [6] 对 ViT-small 主干进行预训练。 我们考虑用于 ResNet 的 TSA 残差适配器 [29, 39] 和用于 ViT 的前缀调整 [30, 53] 适配器。 这主要是为了能够与使用完全相同的适配器系列的相同基础架构上的先前工作进行直接比较,而不会在混合适配器类型方面引入新的混杂因素 [29, 53]。 然而,我们的框架是灵活的,这意味着它可以接受任何适配器类型,甚至其搜索空间中的多种类型。
4.2. 与最新(state-of-the-art,SOTA)的比较
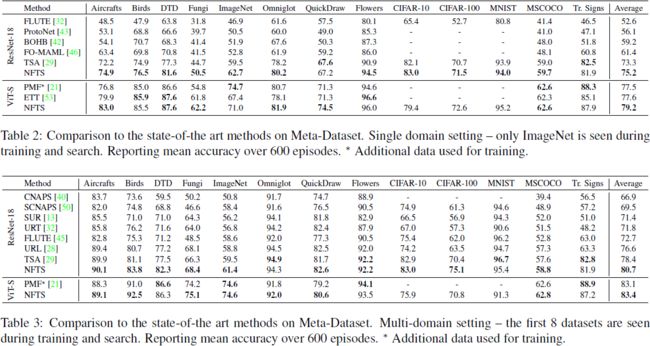
元数据集。 单域和多域训练设置的元数据集结果分别如表 2 和表 3 所示。 我们可以看到,在 ResNet 和 ViT 架构的所有竞争对手方法中,NFTS 获得了最佳的平均性能。 对于该基准测试,与先前最先进技术相比的优势通常很大,在 ResNet-18 单域中比 TSA +1.9%,在多域中比 TSA +2.3%,在 VITsmall 单域中比 ETT +1.6%。 多域情况下增加的余量是直观的,因为我们的框架有更多的数据来学习最佳路径。
我们重申,PMF、ETT 和 TSA 是我们搜索空间的特殊情况,分别对应于:(i) 全部微调且不包含适配器,(ii) 在每一层包含 ETT 适配器,同时冻结所有骨干权重,以及 (iii) 在每一层都包含 TSA 适配器,同时冻结所有骨干权重。 我们还与 ETT 和 TSA 共享初始预训练主干(但不与 PMF 共享,因为它使用更强大的预训练模型和附加数据)。 因此,我们比这些竞争对手取得的优势可归因于我们在何处微调以及在何处插入新适配器参数方面寻找合适架构的系统方法。

元相册。 元相册的结果如图 4 所示,作为 5-way 设置内 shot 数量的函数,遵循 [47]。 我们可以看到,在整个支持集大小范围内,我们的 NFTS 主导了 [47] 中所有经过良好调整的基线。余量很大,例如在 5-way/5-shot 操作点时大于 5%。 这一结果证实,我们的框架可以扩展到比之前在元数据集中考虑的更加多样化的数据集和领域。
4.3. 消融研究
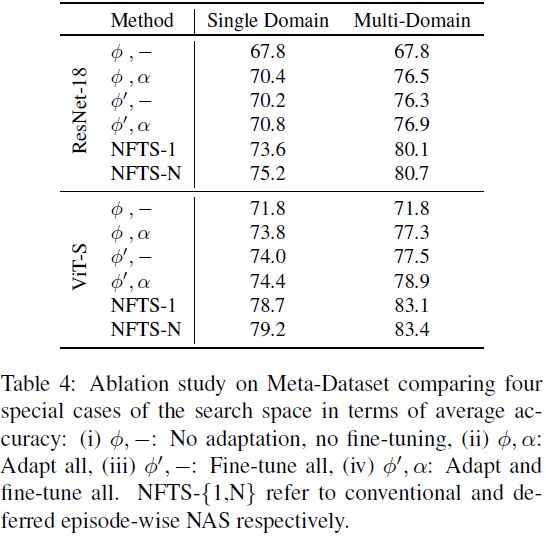
为了更准确地分析我们的架构搜索在少样本性能中所扮演的角色,我们还针对搜索空间的四个角对最终模型进行了消融研究:(i)仅初始模型,使用预先训练的特征提取器和简单的 NCC 分类器,大致对应于 SimpleShot [50],(ii) 仅完全适应,使用固定特征提取器,大致对应于 TSA [29]、ETT [53]、FLUTE [45] 和其他 —— 取决于基本架构和适配器的选择,(iii)完全微调模型,大致对应于 PMF [21],以及(iv)完全微调和自适应的组合。 从表 4 的结果中我们可以看到,微调 (ii)、适配器 (iii) 及其组合 (iv) 都对线性读出基线 (i) 进行了改进。 但都比 NFTS 系统优化的适配架构差。
该消融还将使用 SPOS 架构搜索找到的 top-1 适应架构的结果与我们新颖的渐进方法进行比较,该方法将最终的架构选择推迟到按 episode 的决策。 我们的延迟架构选择改进了元训练中的 top-1 架构,展示了每个数据集/剧集架构选择的价值(另请参见第 4.4 节)。
4.4. 更深入的分析
消融研究定量地显示了适应架构搜索相对于常见的固定适应策略的好处。 在本节中,我们的目标是分析:我们的 NAS 策略发现了什么样的适应架构,以及它是如何发现的?
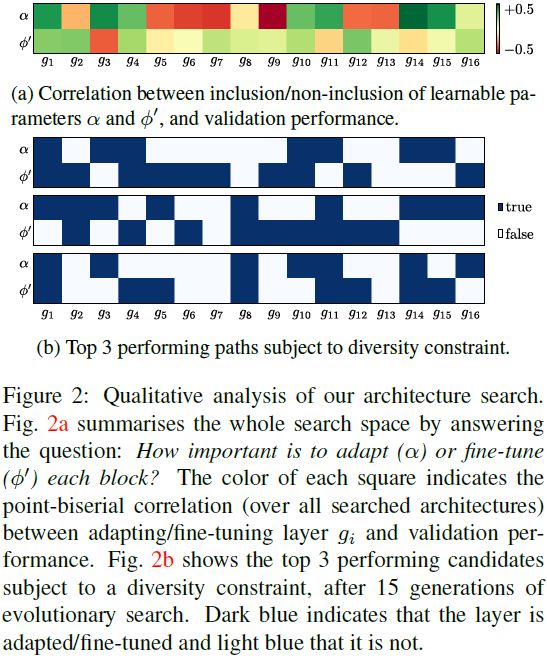
发现的架构。我们首先总结整个搜索空间的结果,即哪些层优先进行微调,哪些层优先插入适配器,哪些层不优先插入适配器,如图 2a 所示。 这些块表示层(列)和适配器/微调(行),颜色表示架构决策与验证性能是正相关(绿色)还是负相关(红色)。 我们可以看到结果很复杂,没有简单的模式,正如现有工作 [21,29,53] 所假设的那样。 也就是说,我们的 NAS 确实发现了一些可解释的趋势。 例如,适配器应包含在早期/晚期 ResNet-18 层,而不是第 5-9 层。
接下来,我们在图 2b 中显示了受多样性约束的前三个执行路径。 我们从图 2a 中看到这些遵循搜索空间中的强劲趋势。 例如,它们总是适应 (α) 块 14 而从不适应块 9。然而,另一方面,它们确实包括不同的决策(例如是否微调 (φ') 块 15),这在图 2a 中没有强烈指出。

最后,我们分析图 2b 中的一小组 N = 3 候选架构在元测试期间的使用情况。 回想一下,这个小集合允许我们执行高效的最小 episode-wise NAS,包括训练期间未见过的新数据集。 表 5 中的结果显示了元测试(着色)过程中保留的数据集选择每种架构的频率,以及仅使用该架构的每个数据集的性能是多少。 它展示了我们的方法如何成功地学习在每个数据集的基础上选择最合适的架构,即使对于未见过的数据集也是如此。 这种独特的能力超越了之前的工作 [21,29,53],其中所有领域都必须依赖相同的适应策略,尽管它们有不同的适应需求。
路径搜索过程。此外,我们在图 3 中说明了路径搜索过程。该图显示了我们的 2K 维架构搜索空间的 2D t-SNE 投影,其中点是不同迭代的进化搜索过程的候选架构。 这些点根据其验证准确性进行着色。 从结果中我们可以看到: 最初的候选者集合广泛分散,表现普遍较低(左),并逐渐向更紧密的高表现候选者聚集(右)。 受多样性约束的前 3 个执行路径(也在图 2b 中示出)以紫色轮廓标注。
讨论。 正如第 4.3 节中分析的那样,我们的方法可以用于 top-1 —— 其中每个 episode 都是给定所选架构的纯粹微调操作; 或如上所述的 top-N 架构模式 —— 每个情节都会根据进化搜索期间产生的候选名单执行迷你架构选择,以及微调。 我们注意到,虽然后者在测试期间略微增加了成本(实际上 N = 3×),但这与在测试期间以不同学习率重复适应的竞争对手类似或更少(4× 成本),或者利用骨干集成(8× 成本)[13, 32]。
5. 结论
在本文中,我们提出了 NFTS,一种新颖的基于神经架构搜索的方法,它发现了基于梯度的小样本学习的最佳适应架构。 NFTS 包含几个最近的强大的启发式适应架构作为其搜索空间中的特例,我们通过系统架构搜索表明它们都表现出色,从而在元数据集和元相册上达到了新的最先进水平。 虽然在本文中我们使用简单而粗略的搜索空间来与先前工作的手工设计的适应策略进行简单直接的比较,但在未来的工作中,我们将扩展该框架以包括更丰富的适应策略范围和更细粒度的搜索。
参考
Eustratiadis P, Dudziak Ł, Li D, et al. Neural Fine-Tuning Search for Few-Shot Learning[J]. arXiv preprint arXiv:2306.09295, 2023.
S. 总结
S.1 主要思想
少样本域自适应(Few-shot domain adaptation)的一个重要方法是对精心设计的自适应架构进行微调。那么,如何设计最优的自适应策略?本文通过神经架构搜索(neural architecture search,NAS)来研究这个问题。本文提出 “神经微调搜索”(Neural Fine-Tuning Search,NFTS),这是一种新颖的 NAS 算法,它可以找到基于梯度的小样本学习的最佳适应架构。
S.2 方法
给定两个预训练的主要架构系列,卷积网络(ResNet) 和 transformers(Vision Transformer (ViT)),NFTS 定义了一个与它们相关的通用搜索空间,这个搜索空间由每层包含或不包含特定于任务的适配器以及可学习参数的冻结或微调来定义。这里,特定适配器(adaptor)模块被考虑为一个超参数,而不是一个硬约束。基于这个搜索空间,构建了一个超级网络,通过在每个前向传递中采样随机路径来训练它。超网架构如图 1 所示,其中上述决策被绘制为决策节点 (⋄),可能的路径用虚线标记。
超级网包含搜索空间的所有可能架构, 它的参数包括:(i) 来自主干架构的冻结参数,(ii) 来自适配器的参数,以及 (iii) 来自每层的微调参数。使用原型损失作为超网训练以及随后的搜索和微调期间的核心目标。
最优路径(模型)搜索分为两个阶段:
- 在元训练阶段,搜索负责从整个搜索空间中预选一个含有 N 个模型的集合,并使用进化搜索选择 N 个最佳表现的模型。 其主要目的是减轻在测试时(当只有少量数据可用时)可能发生的潜在过度拟合,同时提供足够的多样性以成功地将架构适应到不同的测试域集。。
- 在元测试阶段,通过在支持集上对模型进行微调并在同一支持集上测试其性能,决定预选的 N 个模型中哪一个最适合适应给定的支持集数据。
可解释性。通过总结整个搜索空间的结果,可以发现哪些层优先进行微调,哪些层优先插入适配器,哪些层不优先插入适配器。