Storm 流式计算框架介绍
文章目录
- 1.Storm简介
-
- 1.1 DAG(有向无环图)
- 1.2 Storm介绍
-
- 1.2.1 Storm 简介
- 1.2.2 Storm的优点
- 1.2.3 Storm的特性
- 1.3 Storm与Hadoop对比
-
- 相似点:
- 不同点:
- 1.4 Storm物理架构
- 1.5 Storm并行机制
-
- 1.5.1 配置拓扑的并行度
- 1.6 Storm计算架构
-
- 1.6.1 **Topology**
- 1.6.2 **Stream**
- **1.6.3 Tuple**
- 1.6.4 **Spout**
- 1.6.5 **Bolt**
- 1.6.6 **StreamGroup**
- **1.6.7 Reliablity**
- 1.7 Storm的数据分发策略
-
- **ShuffleGrouping**
- **FieldsGrouping**
- **AllGrouping**
- **GlobalGrouping**
- **DirectGrouping**
- **Localorshufflegrouping**
- **NoneGrouping**
- **customGrouping**
- 1.8 Storm的内部通信机制
-
- 1.8.1 **Worker进程间通信原理**
- 1.8.2 **Worker进程内通信原理**
- 1.9 Storm的容错机制
-
- **1.9.1 集群节点宕机**
- **1.9.2 进程故障**
- 1.9.3 **任务级容错**
- **1.9.4 消息的完整性**
- **1.9.5 记录级容错Storm的DRPC**
1.Storm简介
1.1 DAG(有向无环图)
有向无环图Directed Acyclic Graph(DAG)
-
DAG是一个没有 有向循环的、有限的有向图 。
- 它由有限个顶点和有向边组成,每条有向边都从一个顶点指向另一个顶点;
- 从任意一个顶点出发都不能通过这些有向边回到原来的顶点。
- 有向无环图就是从一个图中的任何一点出发,不管走过多少个分叉路口,都没有回到原来这个
点的可能性。
-
条件
-
每个顶点出现且只出现一次
-
若存在一条从顶点 A 到顶点 B 的路径,那么在序列中顶点 A 出现在顶点 B 的前面。
-
-
计算一个DAG的拓扑关系
- 1→4表示4的入度+1,4是1的邻接点
- 首先将边与边的关系确定,建立好入度表和邻接表。
- 从入度为0的点开始删除,如上图显然是1的入度为0,先删除。
- 判断有无环的方法,对入度数组遍历,如果有的点入度不为0,则表明有环。
{ 1, 2, 4, 3, 5 }
1.2 Storm介绍
1.2.1 Storm 简介
http://storm.apache.org/
Storm是Twitter开源的分布式实时大数据处理框架,被业界称为实时版Hadoop。随着越来越多的场景对Hadoop的MapReduce高延迟无法容忍,比如网站统计、推荐系统、预警系统、金融系统(高频交易、股票)等等,大数据实时处理解决方案(流计算)的应用日趋广泛,目前已是分布式技术领域最新爆发点,而Storm更是流计算技术中的佼佼者和主流。
Storm对于实时计算的意义类似于Hadoop对于批处理的意义。Hadoop提供了map、reduce原语,使我们的批处理程序变得简单和高效。同样,Storm也为实时计算提供了一些简单高效的原语,而且Storm的Trident是基于Storm原语更高级的抽象框架,类似于基于Hadoop的Pig框架,让开发更加便利和高效。
1.2.2 Storm的优点
Storm 实现的一些特征决定了它的性能和可靠性的,Storm 使用 Netty 传送消息,这就消除了中间的排队过程,使得消息能够直接在任务自身之间流动,在消息的背后,是一种用于序列化和反序列化
Storm 的原语类型的自动化且高效的机制。
Storm 的一个最有趣的地方是它注重容错和管理,Storm 实现了有保障的消息处理,所以每个元组(Turple)都会通过该拓扑(Topology)结构进行全面处理;
如果一个元组还未处理会自动从Spout处重发,Storm 还实现了任务级的故障检测,在一个任务发生故障时,消息会自动重新分配以快速重新开始处理。
1.2.3 Storm的特性
-
适用场景广泛:storm可以实时处理消息和更新DB,对一个数据量进行持续的查询并返回客户端(持续计算)
-
对一个耗资源的查询作实时并行化的处理(分布式方法调用,即DRPC),storm的这些基础API可以满足大量的场景。
-
可伸缩性高: Storm的可伸缩性可以让storm每秒可以处理的消息量达到很高。
-
Storm使用ZooKeeper来协调集群内的各种配置使得Storm的集群可以很容易的扩展。
-
保证无数据丢失:实时系统必须保证所有的数据被成功的处理。storm保证每一条消息都会被处理。
-
异常健壮:storm集群非常容易管理,轮流重启节点不影响应用。
-
容错性好:在消息处理过程中出现异常, storm会进行重试
-
语言无关性:Storm的topology和消息处理组件(Bolt)可以用任何语言来定义。
1.3 Storm与Hadoop对比
相似点:
| Hadoop | Storm | |
|---|---|---|
| 系统角色 | JobTracker | Nimbus |
| 系统角色 | TaskTracker | Supervisor |
| 系统角色 | Child | Worker |
| 应用名称 | Job | Topology |
| 组件接口 | Mapper/Reducer | Spout/Bolt |
- Nimbus:Nimbus在Storm中用于资源分配和作业调度,类比Hadoop中的Job Tracker
- Supervisor:Supervisor在Storm中用于接收Nimbus分配的任务,并且启动和停止用于完成这些任务对的Worker进程。Supervisor类比Hadoop中的TaskTracker
- Worker:运行Storm中具体组件逻辑的进程。这里的组件指的是Spout或者Bolt,对比Hadoop.x的Child进程。
- Topology:Topology是Storm中运行的一个任务,类比Hadoop.x中的一个作业(Job)
- Spout:在一个Topology中产生源数据流的组件
- Bolt:在一个Topology中接收数据,并进行逻辑处理的组件,称为Transformation
不同点:
| Hadoop | Storm | |
|---|---|---|
| 数据来源 | Hadoop处理的是HDFS上TB级别的数据(历史数据) | Storm处理的是实时新增的某一笔数据(实时数据) |
| 处理过程 | Hadoop是分Map阶段和Reduce阶段 | Storm是由用户定义处理流程,流程中可以包含多个步骤,每个步骤可以是数据源(Spout)或处理逻辑(Bolt) |
| 是否结束 | Hadoop最后是要结束的 | Storm没有结束状态,到最后一步时,就停在那,直到有新数据进入时再从头开始 |
| 处理速度 | Hadoop是以处理HDFS上大量数据为目的的,处理速度慢 | Storm是只要处理新增的某一笔数据即可,可以做到很快 |
| 适用场景 | Hadoop是在要处理批量数据时用的,不讲究时效性 | Storm是要处理某一新增数据时使用的,讲究时效性 |
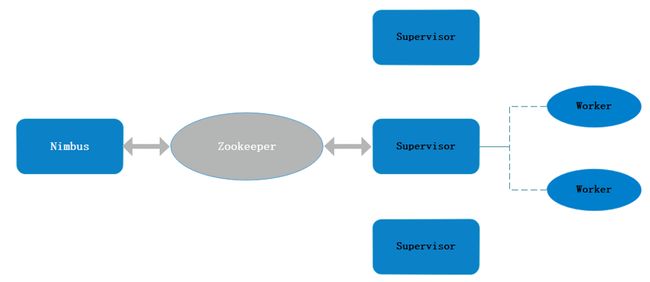
1.4 Storm物理架构
nimbus
- Storm的Master,负责资源分配和任务调度。一个Storm集群只有一个Nimbus。
- 集群的主节点,对整个集群的资源使用情况进行管理
- 但是nimbus是一个无状态的节点,所有的一切都存储在Zookeeper
supervisor
-
Storm的Slave,负责接收Nimbus分配的任务,管理所有Worker
-
一个Supervisor节点中包含多个Worker进程。默认是4个
-
一般情况下一个topology对应一个worker
woker
工作进程(Process),每个工作进程中都有多个Task。
Task
-
在 Storm 集群中每个 Spout 和 Bolt 都由若干个任务(tasks)来执行。
-
worker中每一个spout/bolt的线程称为一个task
-
同一个spout/bolt的task可能会共享一个物理线程(Thread),该线程称为executor
1.5 Storm并行机制
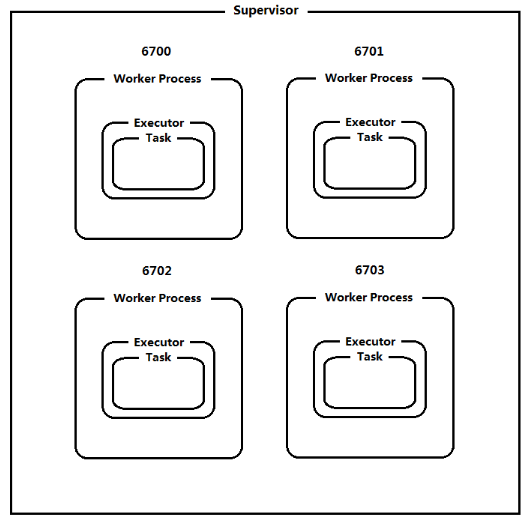
- Topology由一个或多个Spout/Bolt组件构成。运行中的Topology由一个或多个Supervisor节点中的 Worker构成
- 默认情况下一个Supervisor节点运行4个Worker,由defaults.yaml/storm.yaml中的属性决定:
supervisor.slots.ports:6700 6701 6702 6703 - 在代码中可以使用new Config().setNumWorkers(3),最大数量不能超过配置的supervisor.slots.port数量。
- Worker为特定拓扑的一个或多个组件Spout/Bolt产生一个或多个Executor。默认情况下一个Worker运行一个Executor。
- Executor为特定拓扑的一个或多个组件Spout/Bolt实例运行一个或多个Task。默认情况下一个Executor运行一个Task.
- 一般情况下,executor的数量尽量不要大于task
1.5.1 配置拓扑的并行度
-
配置worker的数量
//注意此参数不能大于supervisor.slots.ports数量。 Config config = new Config(); config.setNumWorkers(3); -
配置Executor的数量
TopologyBuilder builder = new TopologyBuilder(); //设置Spout的Executor数量参数parallelism_hint builder.setSpout(id, spout, parallelism_hint); //设置Bolt的Executor数量参数parallelism_hint builder.setBolt(id, bolt, parallelism_hint); -
配置任务Task数量
TopologyBuilder builder = new TopologyBuilder(); //设置Spout的Executor数量参数parallelism_hint,Task数量参数val builder.setSpout(id, spout, parallelism_hint).setNumTasks(val); //设置Bolt的Executor数量参数parallelism_hint,Task数量参数val builder.setBolt(id, bolt, parallelism_hint).setNumTasks(val);
示例代码:
//启动Topology Config
conf = new Config();
//设置项目需要的进程数
conf.setNumWorkers(2);
topologyBuilder.setBolt("Blue", new WordcountBoltLine(), 2);
topologyBuilder.setBolt("Green", new WordcountBoltLine(), 2).setNumTasks(4)
topologyBuilder.setBolt("Yellow", new WordcountBoltLine(), 6)

设置workers为2,说明该项目有两个进程,默认情况下Executor数量和Task数量是一比一的,且Exector在Worker中也是均匀分配的。
如上如例子,Blue设置两个Executor,那么默认两个Executor分在两个Worker中,并且每个Executor分配一个Task。
Green设置两个Executor,4个Task,那么两个Executor分在两个Worker中,且每一个Executor中包含两个Task
Yellow设置六个Executor,那么6个Executor分在两个Worker中,并且默认每个Executor包含一个Task
1.6 Storm计算架构
- 流式计算框架
- 客户端将数据发送给MQ(消息队列),然后传递到Storm中进行计算
- 最终计算的结果存储到数据库中(HBase,Mysql)
- 客户端不要求服务器返回结果,客户端可以一直向Storm发送数据
- 客户端相当于生产者,Storm相当于消费者
1.6.1 Topology
计算拓扑
Storm 的拓扑是对实时计算应用逻辑的封装,它的作用与 MapReduce 的任务(Job)很相似,区别在于 MapReduce 的一个 Job 在得到结果之后总会结束,而拓扑会一直在集群中运行,直到你手动去终止它。
拓扑还可以理解成由一系列通过数据流(Stream Grouping)相互关联的 Spout 和 Bolt 组成的拓扑结构。
1.6.2 Stream
数据流(Streams)是 Storm 中最核心的抽象概念。
一个数据流指的是在分布式环境中并行创建、处理的一组元组(tuple)的无界序列。数据流可以由一种能够表述数据流中元组的域(fields)的模式来定义。
1.6.3 Tuple
Stream中最小数据组成单元每个tuple可以包含多列,字段类型可以是: integer, long, short, byte, string, double, float,boolean和byte array。其结构就类似于python语法中的元组
1.6.4 Spout
数据源(Spout)是拓扑中数据流的来源。
一般 Spout 会从一个外部的数据源读取元组然后将他们发送到拓扑中。
根据需求的不同,Spout 既可以定义为可靠的数据源,也可以定义为不可靠的数据源。
一个可靠的 Spout能够在它发送的元组处理失败时重新发送该元组,以确保所有的元组都能得到正确的处理;storm在检测到一个tuple被整个topology成功处理的时候调用ack, 否则调用fail。
不可靠的 Spout 就不会在元组发送之后对元组进行任何其他的处理。一个 Spout可以发送多个数据流。
1.6.5 Bolt
拓扑中所有的数据处理均是由 Bolt 完成的。
通过数据过滤(filtering)、函数处理(functions)、聚合(aggregations)、联结(joins)、数据库交互等功能。
一个 Bolt 可以实现简单的数据流转换,而更复杂的数据流变换通常需要使用多个 Bolt 并通过多个步骤完成。
第一级Bolt的输出可以作为下一级Bolt的输入。而Spout不能有上一级。
Bolt 几乎能够完成任何一种数据处理需求。
Bolts的主要方法是execute(死循环)连续处理传入的tuple,成功处理完每一个tuple调用OutputCollector的ack方法,以通知storm这个tuple被处理完成了。
处理失败时,可以调fail方法通知Spout端可以重新发送该tuple。
1.6.6 StreamGroup
为拓扑中的每个 Bolt 的确定输入数据流是定义一个拓扑的重要环节。
数据流分组定义了在 Bolt 的不同任务(tasks)中划分数据流的方式。在 Storm 中有八种内置的数据流分组方式。
1.6.7 Reliablity
可靠性
Storm 可以通过拓扑来确保每个发送的元组都能得到正确处理。通过跟踪由 Spout 发出的每个元组构成的元组树可以确定元组是否已经完成处理。
每个拓扑都有一个“消息延时”参数,如果 Storm 在延时时间内没有检测到元组是否处理完成,就会将该元组标记为处理失败,并会在稍后重新发送该元组。
1.7 Storm的数据分发策略
ShuffleGrouping
随机分组,随机派发stream里面的tuple,保证每个bolttask接收到的tuple数目大致相同。
轮询,平均分配
//设置拓扑关系(Bolt)
//如果不设置Task的数量,默认executor:Task为1:1
topologyBuilder.setBolt("numberBolt",new NumberBolt()).shuffleGrouping("numberSpout");
优点:
为tuple选择task的代价小;
bolt的tasks之间的负载比较均衡;
缺点:
上下游components之间的逻辑组织关系不明显;
FieldsGrouping
按字段分组
topologyBuilder.setBolt("FieldBolt",new FieldBolt(),3).fieldsGrouping("groupSpout",new Fields("word"));
比如,按"user-id"这个字段来分组,那么具有同样"user-id"的tuple会被分到相同的Bolt里的一个
task,而不同的"user-id"则可能会被分配到不同的task。
一般来说,例如需要统计单词个数的时候,如果Executor的个数不唯一,如果使用随机分组,那么有可能相同的分组会在不同的Task中,导致无法计算出该单词的数量。因此一般会使用一个Bolt将句子切分为单词,之后使用FieldsGrouping的分发方式,按照单词字段分发,相同的单词就会分到相同的Bolt中。
优点:
上下游components之间的逻辑组织关系显著;
缺点:
付出为tuple选择task的代价;
bolt的tasks之间的负载可能不均衡,根据field字段而定;
AllGrouping
广播发送,对于每一个tuple,所有的bolts都会收到
topologyBuilder.setBolt("AllBolt",new AllBolt(),2).allGrouping("groupSpout")
The stream is replicated across all the bolt’s tasks. Use this grouping with care.
优点:
上游事件可以通知下游bolt中所有task;
缺点:
tuple消息冗余,对性能有损耗,请谨慎使用;
GlobalGrouping
全局分组,把tuple分配给taskid最低的task。
The entire stream goes to a single one of the bolt’s tasks. Specifically, it goes to the task
with the lowest id.
优点:
所有上游消息全部汇总,便于合并、统计等;
缺点:
bolt的tasks之间的负载可能不均衡,id最小的task负载过重;
DirectGrouping
指向型分组,这是一种比较特别的分组方法,用这种分组意味着消息(tuple)的发送者指定由消息接收者的哪个task处理这个消息。
只有被声明为DirectStream的消息流可以声明这种分组方法。
而且这种消息tuple必须使用emitDirect方法来发射。
消息处理者可以通过TopologyContext来获取处理它的消息的task的id(OutputCollector.emit方法也会返回task的id)
优点:
Topology的可控性强,且组件的各task的负载可控;
缺点:
当实际负载与预估不符时性能削弱;
Localorshufflegrouping
本地或随机分组。如果目标bolt有一个或者多个task与源bolt的task在同一个工作进程中,tuple将
会被随机发送给这些同进程中的tasks。否则,和普通的ShuffleGrouping行为一致
If the target bolt has one or more tasks in the same worker process, tuples will be
shuffled to just those in-process tasks. Otherwise, this acts like a normal shuffle
grouping.
优点:
相对于ShuffleGrouping,因优先选择同进程task间传输而降低tuple网络传输代价,但因寻找同进程的task而消耗CPU和内存资源,因此应视情况来确定选择ShuffleGrouping或LocalOrShuffleGrouping;
缺点:
上下游components之间的逻辑组织关系不明显;
NoneGrouping
不分组,这个分组的意思是说stream不关心到底怎样分组。目前这种分组和Shufflegrouping是一
样的效果。有一点不同的是storm会把使用nonegrouping的这个bolt放到这个bolt的订阅者同一个
线程里面去执行(未来Storm如果可能的话会这样设计)。
customGrouping
自定义,相当于mapreduce那里自己去实现一个partition一样
1.8 Storm的内部通信机制
1.8.1 Worker进程间通信原理
worker进程间消息传递机制,消息的接收和处理的流程如下图
-
worker进程
为了管理流入和传出的消息,每个worker进程都有一个独立的接收线程和发送线程接收线程来负责将外部发送过来的消息移动到对应的executor线程的incoming-queue中
发送线程负责从worker的transfer-queue中读取消息,并通过网络发送给其他worker
-
executor线程
每个executor有独立的incoming-queue 和outgoing-queue
Worker接收线程将收到的消息通过task编号传递给对应的executor的incoming-queues,executor有单独的线程分别来处理spout/bolt的业务逻辑,业务逻辑输出的中间数据会存放在outgoing-queue。
当executor的outgoing-queue中的tuple达到一定的阀值,executor的发送线程将批量获取outgoing-queue中的tuple,并发送到transfer-queue中
每个worker进程控制一个或多个executor线程,用户可在代码中进行配置。其实就是我们在代码中设置的并发度个数。
-
通信技术
netty:Netty是一个NIO client-server(客户端服务器)框架
https://blog.csdn.net/qq_28959087/article/details/86501141
1.8.2 Worker进程内通信原理
Disruptor是一个Queue。
Disruptor是实现了“队列”的功能,而且是一个有界队列(长度有限)。而队列的应用场景自然就
是“生产者-消费者”模型
Disruptor一种线程之间信息无锁的交换方式
(使用CAS(Compare And Swap/Set)操作)
Disruptor主要特点
- 没有竞争=没有锁=非常快。
- 所有访问者都记录自己的序号的实现方式,允许多个生产者与多个消费者共享相同的数据结构。
- 在每个对象中都能跟踪序列号(ring buffer,claim Strategy,生产者和消费者),加上神奇的cache line padding,就意味着没有为伪共享和非预期的竞争。
Disruptor 核心技术点
Disruptor可以看成一个事件监听或消息机制,在队列中一边生产者放入消息,另外一边消费
者并行取出处理.
底层是单个数据结构:一个ring buffer(环形数据缓冲区)
每个生产者和消费者都有一个次序计算器,以显示当前缓冲工作方式。每个生产者消费者能够操作自己的次序计数器的能够读取对方的计数器,生产者能够读取消费者的计算器确保其在没有锁的情况下是可写的。
核心组件
Ring Buffer 环形的缓冲区,负责对通过 Disruptor 进行交换的数据(事件)进行存储和更新。Sequence 通过顺序递增的序号来编号管理通过其进行交换的数据(事件),对数据(事件)的处理过程总是沿着序号逐个递增处理。
RingBuffer底层是个数组,次序计算器是一个64bit long 整数型,平滑增长。
1.9 Storm的容错机制
1.9.1 集群节点宕机
Nimbus宕机
- 单点故障
- 从1.0.0版本以后,Storm的Nimbus是高可用的。
非Nimbus节点
故障时,该节点上所有Task任务都会超时,Nimbus会将这些Task任务重新分配到其他服务器上运行
1.9.2 进程故障
Worker
每个Worker中包含数个Bolt(或Spout)任务。
Supervisor负责监控这些任务,当worker失败后会尝试在本机重启它
如果启动过程中仍然一直失败,并无法向Nimbus发送心跳,Nimbus会将该Worker重新分配到其他服务器上
Supervisor
无状态(所有的状态信息都存放在Zookeeper中来管理)
快速失败(每当遇到任何异常情况,都会自动毁灭)
-
快速失败(fail-fast)
- 在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改)则会抛出Concurrent Modification Exception
- java.util包下的集合类都是快速失败的,不能在多线程下发生并发修改
-
安全失败(fail-safe)
- 采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的。而是先复制原有集合内容,在拷贝的集合上进行遍历
- java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用,并发修改。
Nimbus
无状态(所有的状态信息都存放在Zookeeper中来管理)
快速失败(每当遇到任何异常情况,都会自动毁灭)
1.9.3 任务级容错
Bolt任务crash引起的消息未被应答。
- 此时,acker中所有与此Bolt任务关联的消息都会因为超时而失败,对应的Spout的fail方法将被调用。
acker任务失败。
- 如果acker任务本身失败了,它在失败之前持有的所有消息都将超时而失败。Spout的fail方法将被调用。
Spout任务失败。
- 在这种情况下,与Spout任务对接的外部设备(如MQ)负责消息的完整性。
1.9.4 消息的完整性
-
消息的完整性定义
-
每个从Spout(Storm中数据源点)发出的Tuple(Storm中最小的消息单元)可能会生成成千上万个新的Tuple
-
形成一颗Tuple树,当整颗Tuple树的节点都被成功处理了,我们就说从Spout发出的Tuple被
完全处理了。

-
-
消息完整性机制–Acker
- acker的任务就是追踪从spout中流出来的每一个message id绑定的若干tuple的处理路径,如果在用户设置的最大超时时间内这些tuple没有被完全处理,那么acker就会告知spout该消息处理失败了
- 相反则会告知spout该消息处理成功了。
-
XOR异或
-
异或的运算法则为:0异或0=0,1异或0=1,0异或1=1,1异或1=0(同为0,异为1)
-
A xor B…xor B xor A = 0,其中每一个操作数出现且仅出现两次
-
验证方式:
spout或者bolt在处理完tuple后,都会告诉acker我已经处理完了该源tuple(如tupleId=1),如果emit一个tuple的话,同时会告诉acker我发射了一个tuple(如tupleId=2),如果在大量的高并发的消息的情况下,传统的在内存中跟踪执行情况的方式,内存的开销会非常大,甚至内存溢
-
acker巧妙的利用了xor的机制,只需要维护一个msgId的标记位即可,处理方法是acker
在初始的时候,对每个msgId初始化一个校验值ack-val(为0),在处理完tuple和emit tuple的时候,会先对这两个个值做xor操作,生成的中间值再和acker中的当前校验值ack-val做xor生成新的ack-val值,当所有的tuple都处理完成都得到确认,那么最后的ack-val自然就为0了
-
1.9.5 记录级容错Storm的DRPC
DRPC (Distributed RPC) 分布式远程过程调用
DRPC 是通过一个 DRPC 服务端(DRPC server)来实现分布式 RPC 功能的。
DRPC Server 负责接收 RPC 请求
并将该请求发送到 Storm中运行的 Topology
等待接收 Topology 发送的处理结果,并将该结果返回给发送请求的客户端。
DRPC设计目的:
为了充分利用Storm的计算能力实现高密度的并行实时计算。
Storm接收若干个数据流输入,数据在Topology当中运行完成,然后通过DRPC将结果进行输出。
客户端通过向 DRPC 服务器发送待执行函数的名称以及该函数的参数来获取处理结果。
实现该函数的拓扑使用一个DRPCSpout 从 DRPC 服务器中接收一个函数调用流。
DRPC 服务器会为每个函数调用都标记了一个唯一的 id。
随后拓扑会执行函数来计算结果,并在拓扑的最后使用一个名为 ReturnResults 的 bolt 连接
到 DRPC 服务器
根据函数调用的 id 来将函数调用的结果返回。
客户端给DRPC服务器发送要执行的方法的名字,以及这个方法的参数。
实现了这个函数的topology使用DRPCSpout从DRPC服务器接收函数调用流。每个函数调用被DRPC服务器标记了一个唯一的id。 随后topology计算结果,在topology的最后一个叫做ReturnResults的bolt会连接到DRPC服务器,并且把这个调用的结果发送给DRPC服务器(通过那个唯一的id标识)。DRPC服务器用那个唯一id来跟等待的客户端匹配上,唤醒这个客户端并且把结果发送给它。