SRE&运维面试相关高频题库
网络相关
1、TCP三次握手
目的:确认双方收发能力是否正常,指定自己的初始化序列号为后面可靠性传输做准备。
过程:
第一次握手客户端向服务端发送syn报文,指明客户端初始化序列号(在发送连接请求后等待匹配的连接请求)
第二次握手服务器收到客户端的syn,发送syn报文作为应答,指定自己的初始化序列号,同时把isn+1作为ack的值,标识收到syn,希望收到的下一个数据第一个字节序列号是x+1。(在收到和发送一个连接请求后等待对连接请求的确认)
第三次握手客户端收到服务端响应的syn报文后发送ack报文,一样isn+1作为ack的值表示收到syn,希望收到的下一个数据第一个字节序列号是y+1,并指明客户端的序列号。(一个打开的连接,数据可以传送给用户)
2、浏览器请求全过程
- 解析dns得到ip地址
- 客户端与服务器建立请求(三次握手)
- 客户端发起请求
- 服务器根据请求端口号、路径找到对应文件,响应源代码给客户端
- 客户端拿到请求数据开始解析页面及请求资源
- 客户端渲染页面
- web服务器断开链接(四次挥手)
http完整请求过程流程图(图文结合诠释请求过程)
3、OSI七层模型
应用层,网络服务与最终用户的一个接口。
表示层,数据的表示、安全、压缩。
会话层,建立、管理、终止会话。
传输层,定义传输数据的协议端口号,以及流控和差错校验。
网络层,进行逻辑地址寻址,实现不同网络之间的路径选择。
数据链路层,建立逻辑连接、进行硬件地址寻址、差错校验等功能。
物理层,确保原始的数据可在各种物理媒体上传输。
4、TCP/IP4层模型
数据链路层,实现网卡接口的网络驱动程序,以处理数据在物理媒介上的传输;
网络层,实现数据包的选路和转发;
传输层,为两台主机上的应用程序提供端到端的通信;
应用层,负责处理应用程序的逻辑。
5、Cookie和Session的区别
cookie 和session的区别是:cookie数据保存在客户端,session数据保存在服务器端。
两个都可以用来存私密的东西,同样也都有有效期的说法,区别在于session是放在服务器上的,过期与否取决于服务期的设定,cookie是存在客户端的,过去与否可以在cookie生成的时候设置进去。
(1)、cookie数据存放在客户的浏览器上,session数据放在服务器上 ;
(2)、cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗,如果主要考虑到安全应当使用session ;
(3)、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,如果主要考虑到减轻服务器性能方面,应当使用COOKIE ;
(4)、单个cookie在客户端的限制是3K,就是说一个站点在客户端存放的COOKIE不能3K;
(5)、所以将登陆信息等重要信息存放为SESSION;其他信息如果需要保留,可以放在COOKIE中。
6、状态码(权限状态码)
1** 类状态码称之为Information 状态吗,表示信息正在处理。
2** 类状态码称为为Success状态码,表示请求正常完成。
3类状态码称之为Redirection 重定向状态码,表示需要客户端进行附加操作(如跳转。重定向)
4类状态码称之为客户端Error状态码,通常是由于客户端的错误导致的。
5**类状态吗称为Server Error状态码,通常是服务端的错误导致的。
常见状态码及释义
| 400 | 客户端请求语法错误,服务器无法理解 |
|---|---|
| 404 | 无法根据客户端请求找到资源 |
| 405 | 客户端请求的方法被禁止 |
| 504 | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | 服务器不支持请求的http协议,无法完成处理 |
| 403 | 权限拒绝 |
7、Http/Https区别
1、https的端口是443,而http的端口是80,且两者的连接方式不同
2、http传输是明文的,而https是用ssl进行加密的,https的安全性更高
3、https是需要申请证书的,而http不需要。
8、Https简述
HTTPS的前后端通信过程:首先,客户端请求服务器,服务器发送CA和公钥给客户端,客户端通过自身的可信CA列表查看服务器的CA是否在可信列表内,如果在的话就去CA校验证书的合法性,若合法,则客户端将会产生随机数用服务器的公钥加密后发送给服务器,这是服务器用自身的私钥解密,这样经过几次通信之后,双方会达成一个统一的对称密钥用于通信。这样便建立了安全的连接。
9、Post/Get请求区别
一、功能不同
1、get是从服务器上获取数据。
2、post是向服务器传送数据。
二、过程不同
1、get是把参数数据队列加到提交表单的ACTION属性所指的URL中,值和表单内各个字段一一对应,在URL中可以看到。
2、post是通过HTTP post机制,将表单内各个字段与其内容放置在HTML HEADER内一起传送到ACTION属性所指的URL地址。用户看不到这个过程。
三、获取值不同
1、对于get方式,服务器端用Request.QueryString获取变量的值。
2、对于post方式,服务器端用Request.Form获取提交的数据。
四、传送数据量不同
1、get传送的数据量较小,不能大于2KB。
2、post传送的数据量较大,一般被默认为不受限制。但理论上,IIS4中最大量为80KB,IIS5中为100KB。
五、安全性不同
1、get安全性非常低。
2、post安全性较高。
服务器相关
1、服务器开机过程
- 开机bios自检,检查cpu、硬盘等硬件信息
- 读取主引导记录(mbr),进行mbr引导
- grub引导,确定加载操作系统信息
- 加载内核
- 运行init进程,init进程是所有进程的起点
- 通过/etc/inittab进行文件初始化
2、如何优化linux系统
不用root用户,建立其他用户用sudo授权管理
仅用root远程链接,更改默认ssh端口
配置国内yum源
关闭iptable及selinux
调整文件描述符数量
精简开机启动
更改字符集支持中文
去除系统及内核版本登陆前的显示
锁定系统关键文件
3、进程和线程
进程是CPU、内存分配的基本单位,是程序执行时的一个实例
线程是程序执行时的最小单位,是进程的执行流
4、Linux 文件系统 ext4 和 ext3 的变化
第四扩展文件系统ext4,是linux文件系统当前版本。第三扩展文件系统ext3增加日志特性。ext4支持更大的单个文件,更多的子目录。扩展子目录向后兼容,ext3可以挂载为ext4也可以挂载为ext2(日志不可访问)。ext4不可挂载为ext2,ext3。
5、Cache 和 Buffer 的区别
共性:
都属于内存,数据都是临时的,一旦关机数据都会丢失。
差异:
A.buffer是要写入数据;cache是已读取数据。
B.buffer数据丢失会影响数据完整性,源数据不受影响;cache数据丢失不会影响数据完整性,但会影响性能。
C.一般来说cache越大,性能越好,超过一定程度,导致命中率太低之后才会越大性能越低。buffer来说,空间越大性能影响不大,够用就行。cache过小,或者没有cache,不影响程序逻辑(高并发cache过小或者丢失导致系统忙死除外)。buffer过小有时候会影响程序逻辑,如导致网络丢包。
D.cache可以做到应用透明,编写应用的可以不用管是否有cache,可以在应用做好之后再上cache。当然开发者显式使用cache也行。buffer需要编写应用的人设计,是程序的一部分。
6、软连接和硬连接的区别。
硬链接是同一个文件;软链接是指向,不是相同文件
软链接支持跨分区,硬链接不支持
原始文件删除后,硬链接无事,软链接无法使用。
硬链接不支持目录实现,软链接可以
7、load的含义
系统负载(System Load)是系统CPU繁忙程度的度量,即有多少进程在等待被CPU调度(进程等待队列的长度)
平均负载(Load Average)是一段时间内系统的平均负载,这个一段时间一般取1分钟、5分钟、15分钟
单核情况下
Load < 0.7时:系统很闲,马路上没什么车,要考虑多部署一些服务
0.7 < Load < 1时:系统状态不错,马路可以轻松应对
Load == 1时:系统马上要处理不多来了,赶紧找一下原因
Load > 5时:马路已经非常繁忙了,进入马路的每辆汽车都要无法很快的运行
1分钟Load>5,5分钟Load<1,15分钟Load<1:短期内繁忙,中长期空闲,初步判断是一个“抖动”,或者是“拥塞前兆”
1分钟Load>5,5分钟Load>1,15分钟Load<1:短期内繁忙,中期内紧张,很可能是一个“拥塞的开始”
1分钟Load>5,5分钟Load>5,15分钟Load>5:短中长期都繁忙,系统“正在拥塞”
1分钟Load<1,5分钟Load>1,15分钟Load>5:短期内空闲,中长期繁忙,不用紧张,系统“拥塞正在好转”
8、Load高的不同情况以及对应的排查思路
先排查哪些进程cpu占用率高。 通过命令 ps aux
查看对应java进程的每个线程的CPU占用率。通过命令:ps -Lp 15047 cu
追踪线程内部,查看load过高原因。通过命令:jstack 15047
cpu load的飙升,一方面可能和full gc的次数增大有关,一方面可能和死循环有关系
使用iostat 命令查看r/s(读请求),w/s(写请求),avgrq-sz(平均请求大小),await(IO等待), svctm(IO响应时间)
9、Swap分区的含义
swap主要是在内存不够用的时候,将部分内存上的数据交换到swap空间上,以便让系统不会因为内存不够用而导致oom或者更致命的情况出现。当内存使用存在压力的时候,开始触发内存回收行为,就可能会使用swap空间。Swap 把这些不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存
10、查看文件命令
linux系统中列出文件清单命令有:ls命令,cat命令,more命令,less命令,head命令,grep命令,fgrep命令和egrep命令
11、去重
uniq -c
12、异常和中断的区别
结论:中断由硬件设备产生
当我们在敲击键盘的同时就会产生中断,当硬盘读写完数据之后也会产生中断,所以,我们需要知道,中断是由硬件设备产生的,而它们从物理上说就是电信号,之后,它们通过中断控制器发送给CPU,接着CPU判断收到的中断来自于哪个硬件设备(这定义在内核中),最后,由CPU发送给内核,有内核处理中断。
结论:异常由cpu产生
CPU处理程序的时候一旦程序不在内存中,会产生缺页异常;当运行除法程序时,当除数为0时,又会产生除0异常。所以,大家也需要记住的是,异常是由CPU产生的,同时,它会发送给内核,要求内核处理这些异常
13、Kill和Kill-9的区别
kill pid的作用是向进程号为pid的进程发送SIGTERM(这是kill默认发送的信号),该信号是一个结束进程的信号且可以被应用程序捕获。若应用程序没有捕获并响应该信号的逻辑代码,则该信号的默认动作是kill掉进程,这是终止指定进程的推荐做法。
kill -9 pid则是向进程号为pid的进程发送SIGKILL(该信号的编号为9),从文本上面的说明可知,SIGKILL既不能被应用程序捕获,也不能被阻塞或忽略,其动作是立即结束指定进程,通俗的说,应用程序捕获,也不能被阻塞或忽略,其动作是立即结束指定进程。
14、服务器CPU负载很高,但是使用率不高
可以通过指令** ps -axjf 查看是否存在 D 状态进程,(不可中断睡眠状态)**
1、首先查看是哪些进程的CPU占用率最高(如下可以看到详细的路径)
ps -aux --sort -pcpu | more
# 定位有问题的线程可以用如下命令
ps -mp pid -o THREAD,tid,time | more
2、查看JAVA进程的每个线程的CPU占用率
ps -Lp 5798 cu | more # 5798是查出来进程PID
3、追踪线程,查看负载过高的原因,使用JDK下的一个工具
jstack 5798 # 5798是PID
jstack -J-d64 -m 5798 # -j-d64指定64为系统
jstack 查出来的线程ID是16进制,可以把输出追加到文件,导出用记事本打开,
再根据系统中的线程ID去搜索查看该ID的线程运行内容,可以和开发一起排查。
:::info
网站相关进程导致负载高处理办法:
1、直接把网站php或http或tomcat等网站服务重启,很多时候负载就降下来了
2、也可能是网站代码漏洞导致的,需要反馈开发一起查找原因和处理
3、把重复的tomcat kill全部掉重新启动
mysql进程导致的负载高处理办法:
1、常见的就是mysql慢查询导致,可以在mysql慢查询日志找到相关sql语句,这需要对sql进行优化
2、还可以进入mysql,用show full processlist\G;查看那个mysql进程执行时间比较久的慢查询。如果是内部后台使用的语句,可以先kill掉,优化后再执行。
3、mysql读写太频繁,如果是读写频繁可以在%wa等待输入输出看的出来占用cpu百分比很大。也可以通过命令iostat查看系统读写情况。
还有可能是网络原因,系统硬件原因等
:::
15、排序
sort -n
16、查看系统维度的CPU load
定位负载高根音:首先要找到哪几个线程在占用cpu,之后再通过线程的id值在堆栈文件中查找具体的线程
vmstat命令
格式:vmstat -n 1# -n 1 表示结果一秒刷新一次。
示例输出:
[root@wangerxiao ~]# vmstat -t 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- -----timestamp-----
r b swpd free buff cache si so bi bo in cs us sy id wa st CST
3 0 0 5910832 134096 3931732 0 0 0 1 0 1 0 0 100 0 0 2016-11-13 19:57:36
0 0 0 5910816 134096 3931732 0 0 0 0 274 511 0 0 100 0 0 2016-11-13 19:57:37
io
- bi 从块设备接收的块(block/s)
- bo 发送给块设备的块(block/s).如果这个值长期不为0,说明内存可能有问题,因为没有使用到缓存(当然,不排除直接I/O的情况,但是一般很少有直接I/O的)
system
- in (interrupt) 每秒的中断次数,包括时钟中断,需要关注,这两个值越大,内核消耗CPU会越大
- cs (context switch) 进程上下文切换次数,需要关注
cpu
- us 用户进程占用CPU时间比例,需要关注us+sy是否已经为100%
- sy 系统占用CPU时间比例
- id CPU空闲时间比
- wa IO等待时间比(IO等待高时,可能是磁盘性能有问题了)
- st steal time
proc
r (Running or Runnnable)是就绪队列的长度,也就是正在运行和等待CPU的进程数。对比cpu的个数,如果等待进程大于cpu个数,需要注意
b (Blocked) 则是处于不可中断睡眠状态的进程数
r: 表示系统中 CPU 等待处理的线程。由于 CPU 每次只能处理一个线程,所以,该数值越大,通常表示系统运行越慢。
us:用户模式消耗的 CPU 时间百分比。该值较高时,说明用户进程消耗的 CPU 时间比较多,比如,如果该值长期超过 50%,则需要对程序算法或代码等进行优化。
sy:内核模式消耗的 CPU 时间百分比。
wa:IO 等待消耗的 CPU 时间百分比。该值较高时,说明 IO 等待比较严重,这可能磁盘大量作随机访问造成的,也可能是磁盘性能出现了瓶颈。
id:处于空闲状态的 CPU 时间百分比。如果该值持续为 0,同时 sy 是 us 的两倍,则通常说明系统则面临着 CPU 资源的短缺。
top命令
示例输出:
[root@wangerxiao ~]# top
top - 20:02:37 up 35 days, 23:33, 2 users, load average: 0.00, 0.01, 0.05
Tasks: 296 total, 1 running, 295 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.1 us, 0.1 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 12139008 total, 5998320 free, 2074896 used, 4065792 buff/cache
KiB Swap: 2098172 total, 2098172 free, 0 used. 9739056 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1006 influxdb 20 0 5001836 332224 11568 S 1.0 2.7 1172:51 influxd
3578 icinga 20 0 1399032 12792 5152 S 0.3 0.1 136:59.57 icinga2
30207 root 20 0 40800 2120 1328 R 0.3 0.0 0:00.10 top
1 root 20 0 196848 11904 2348 S 0.0 0.1 7:32.27 systemd
- us:用户态CPU时间
- sy:内核态CPU时间
- ni:低优先级用户态CPU时间
- id:空闲时间
- wa:等待I/O的CPU时间
- hi:处理硬中断的CPU时间
- si:处理软中断的CPU时间
- st:当系统运行在虚拟机中的时候,被其他虚拟机占用的CPU时间
进程状态:
R(Running) 表示进程在CPU的就绪队列中,正在运行或者正在等待运行
D(Disk Sleep) 不可中断状态睡眠,一般表示进程正在和硬件交互,并且交互过程不允许被其他进程或中断打断【系统硬件出现故障会导致此进程增多,需关注是不是I/O等性能问题】
Z(Zombie) 僵尸进程 ,也就是进程实际上已经结束了,但是父进程还没有收回它的资源(比如进程的描述符,PID等)
S(Interruptible Sleep) 也就是可中断状态失眠,表示进程因为等待某个事件而被系统挂起。当进程等待事件发生时,它会被唤醒并进入R状态。
I(Idel) 空闲状态,用在不可中断睡眠的内核线程上,硬件交互导致的不可中断进程用D表示,但对于某些内核进程来说,它们又可能实际上并没有任何负载,用Idel正是为了区分这种情况,要注意,D状态的进程会导致平均负载升高,I状态的进程不会
T或者t,也就是Stopped或Traced的缩写,表示进程处于暂停或者跟踪状态
X(Dead)表示进程已经消亡,不会在top中查看到
进程组表示一组相互关联的进程,比如每个子进程都是父进程所在组的成员;
会话是指共享同一个控制终端的一个或多个进程组。
可以直接在界面输入大小字母 P,来使监控结果按 CPU 使用率倒序排列,进而定位系统中占用 CPU 较高的进程。最后,根据系统日志和程序自身相关日志,对相应进程做进一步排查分析,以判断其占用过高 CPU 的原因。** **按下数字 1 切换到所有 CPU 的使用情况,观察一会儿按 Ctrl+C 结束。
strace
strace 正是最常用的跟踪进程系统调用的工具。所以,我们从 pidstat 的输出中拿到进程的 PID 号,比如 6082,然后在终端中运行 strace 命令,并用 -p 参数指定 PID 号
$ strace -p 6082
strace: attach: ptrace(PTRACE_SEIZE, 6082): Operation not permitted
pefr top
$ perf top
Samples: 833 of event 'cpu-clock', Event count (approx.): 97742399
Overhead Shared Object Symbol
7.28% perf [.] 0x00000000001f78a4
4.72% [kernel] [k] vsnprintf
4.32% [kernel] [k] module_get_kallsym
3.65% [kernel] [k] _raw_spin_unlock_irqrestore
...
类似与top,它能够实时显示占用CPU时钟最多的函数或者指令,因此可以用来查找热点函数
输出结果中,第一行包含三个数据,分别是采样数(Samples)、事件类型(event)和事件总数量(Event count)。
比如这个例子中,perf 总共采集了 833 个 CPU 时钟事件,而总事件数则为 97742399。
另外,采样数需要我们特别注意。如果采样数过少(比如只有十几个),那下面的排序和百分比就没什么实际参考价值了。
再往下看是一个表格式样的数据,每一行包含四列,分别是:
第一列 Overhead ,是该符号的性能事件在所有采样中的比例,用百分比来表示。
第二列 Shared ,是该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等。第三列 Object ,是动态共享对象的类型。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。
最后一列 Symbol 是符号名,也就是函数名。
当函数名未知时,用十六进制的地址来表示。还是以上面的输出为例,我们可以看到,占用 CPU 时钟最多的是 perf 工具自身,不过它的比例也只有 7.28%,说明系统并没有 CPU 性能问题。 perf top 的使用你应该很清楚了吧。
17、上下文切换
针对频繁上下文问题,我们可以使用vmstat命令来进行查看,cs(context switch)一列则代表了上下文切换的次数。
如果我们希望对特定的 pid 进行监控那么可以使用 pidstat -w pid命令,cswch 和 nvcswch 表示自愿及非自愿切换。
18、磁盘排查
使用df -hl来查看文件系统状态

可以通过 iostat -d -k -x来进行分析

最后一列%util可以看到每块磁盘写入的程度,而rrqpm/s以及wrqm/s分别表示读写速度,一般就能帮助定位到具体哪块磁盘出现问题了。
另外我们还需要知道是哪个进程在进行读写,一般来说开发自己心里有数,或者用 iotop 命令来进行定位文件读写的来源。
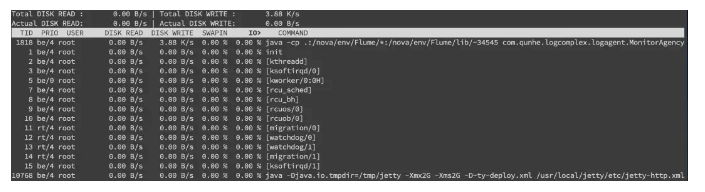
拿到 tid,转换成 pid,可以通过 readlink 来找到 pidreadlink -f /proc/*/task/tid/…/…

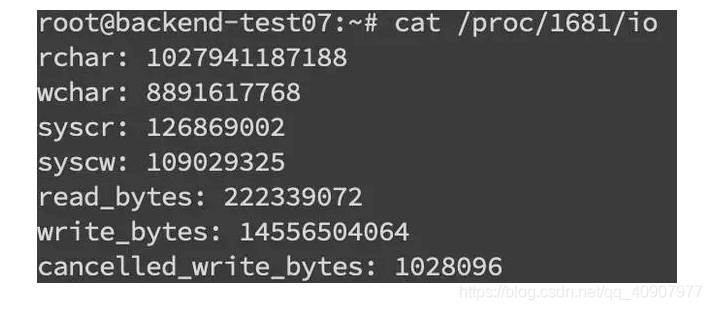
找到 pid 之后就可以看这个进程具体的读写情况cat /proc/pid/io
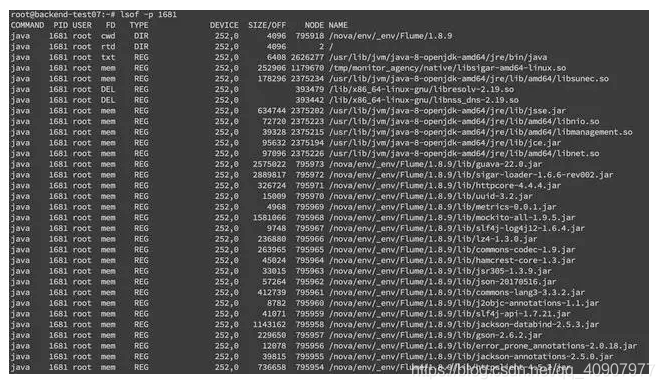
lsof 命令来确定具体的文件读写情况 lsof -p pid
19、内存排查
内存问题排查起来相对比 CPU 麻烦一些,场景也比较多。主要包括 OOM、GC 问题和堆外内存
一般来讲,我们会先用 free 命令先来检查一发内存的各种情况。

20、堆内内存
内存问题大多还都是堆内内存问题。表象上主要分为 OOM 和 Stack Overflow。
Jvm 中的内存不足,OOM 大致可以分为以下几种:
1、Exception in thread “main” java.lang.OutOfMemoryError: unable to create new native thread
这个意思是没有足够的内存空间给线程分配 Java 栈,基本上还是线程池代码写的有问题,比如说忘记 shutdown,所以说应该首先从代码层面来寻找问题,使用 jstack 或者 jmap。如果一切都正常,JVM 方面可以通过指定Xss来减少单个 thread stack 的大小。另外也可以在系统层面,可以通过修改/etc/security/limits.confnofile 和 nproc 来增大 os 对线程的限制。
2、Exception in thread “main” java.lang.OutOfMemoryError: Java heap space
这个意思是堆的内存占用已经达到-Xmx 设置的最大值,应该是最常见的 OOM 错误了。解决思路仍然是先应该在代码中找,怀疑存在内存泄漏,通过 jstack 和 jmap 去定位问题。如果说一切都正常,才需要通过调整Xmx的值来扩大内存。
3、Caused by: java.lang.OutOfMemoryError: Meta space
这个意思是元数据区的内存占用已经达到XX:MaxMetaspaceSize设置的最大值,排查思路和上面的一致,参数方面可以通过XX:MaxPermSize来进行调整(这里就不说 1.8 以前的永久代了)。
4、Stack Overflow
5、Exception in thread “main” java.lang.StackOverflowError
表示线程栈需要的内存大于 Xss 值,同样也是先进行排查,参数方面通过Xss来调整,但调整的太大可能又会引起 OOM。
21、Apache三种工作模式
prefork模式 安全 一对一 不能处理高并发
worker模式主进程-子进城-多个线程可以处理高并发
event模式 keepli 长链接一定时间段内减少请求次数
22、Apache优化
1.利用apache自带的rotatelogs工具,做日志切割减少文件大小,保证单个日志文件不过大。
2.错误页面美化,访问失败时将被访问网页指定到固定的网址
3.屏蔽apache版本等敏感信息
4.vim httpd.conf 配置静态缓存,提高用户访问体验 (gif png css等格式)
5.禁止解析php,新增目录权限标签 ,禁止解析用户上传到脚本
ps:优化网站安全等----CDN,通过服务器分发CDN后让不同域用户就近访问,提高效率。

23、Nginx和Apache优缺点
apache 适合动态处理,稳定,功能强
优点
1.存在时间长,资源丰富
2.模块多,想要的功能基本都能实现
3.动静态解析稳定
缺点:
相对其他服务而言,工作模式时同步阻塞型,导致资源消耗高,并发能力差
nginx 适合静态处理,简答,效率高
优点
1.高性能轻量级服务,占用更少内存及资源
2.并发能力强,nginx请求时异步非阻塞,高并发下依旧可以低消耗
3.高度模块化设计,编写模块相对简单
4.社区活跃,各种高性能模块产出迅速
缺点:
动态处理上需要使用fastcgi连接php的fpm服务,相比apache不占优势。

24、为什么Nginx并发能力强
nginx以异步非阻塞方式工作,充分利用空闲work进程处理请求。
客户端发生request,服务器分配work进程处理。
立即处理完成的,处理后work进程释放资源,进行下一个request处理。
不能处理完的work进程注册返回事件,接着处理其他request,之前的request结果返回后,在触发返回事件,由空闲work进程处理。
同步:收到送达短信,下楼等送达
异步:收到送达短信下去取,快递到楼下后取
25、Nginx常用模块及功能
http_ssl_module 实现服务器加密传输模块,保证数据传输过程安全 https 443端口
http_filter resize 图片裁剪,将大图生成缩略图,保证传输效率
http_rewrite_module 通过正则匹配完成条件判断,进行域名或url重写
http_proxy_module 默认开始 但是需要配置 反向代理功能,一般会和 upstream 模块一起使用,完成压力分摊
http_upstream_module 负载均衡,用来对后台服务器的任务调度分配,分配原则可以通过算法控制,常见的RR 轮询
26、
数据库相关
1、Mysql减少主从延迟
- 确认硬件差距
- 主从复制单线程,如果写并发大会导致延迟,升级系统版本至支持多线程版本
- 慢sql多
- 网络延迟
- master负载过大,主库读写压力大导致延迟
- slave负载大,多台slave分担请求,留一台仅做备份,不做其他使用。优化减少延迟参数
2、数据库系统load高的一般原因
- 业务并发调用全表扫描/带有order by 排序的SQL语句。
- SQL语句没有合适索引/执行计划出错/update/delete where扫描全表,阻塞其他访问相同表的sql执行.SQL语句没有合适索引/执行计划出错/update/delete
where扫描全表,阻塞其他访问相同表的sql执行。 - 存在秒杀类似的业务比如聚划算10点开团或者双十一秒杀,瞬时海量访问给数据库带来冲击。
- 数据库做逻辑备份(需要全表扫描)或者多实例的压缩备份(压缩时需要大量的cpu计算,会导致系统服务器load飙高)
- 磁盘写入方式改变 比如有writeback 变为 write through磁盘写入方式改变 比如有writeback 变为 write through。RAID卡都有写cache(Battery Backed Write Cache),写cache对IO性能的提升非常明显,因为掉电会丢失数据,所以必须由电池提供支持。
电池会定期充放电,一般为90天左右,当发现电量低于某个阀值时,会将写cache策略从writeback置为writethrough,相当于写cache会失效,这时如果系统有大量的IO操作,可能会明显感觉到IO响应速度变慢,cpu
队列堆积系统load 飙高。
3、怎么优化sql的索引
4、Mysql主从同步原理
- MYSQL主从同步是异步复制的过程,整个同步需要开启3线程,master上开启bin-log⽇志(记录数据库增、删除、修改、更新操作);
- Slave开启I/O线程来请求master服务器,请求指定bin-log中position点之后的内容;
- Master端收到请求,Master端I/O线程响应请求,bin-log、position之后内容返给salve;
- Slave将收到的内容存⼊relay-log中继⽇志中,(记录master ip、bin-log、position、⽤户名密码);
- Slave端SQL实时监测relay-log⽇志有更新,解析更新的sql内容,解析成sql语句,再salve库中执⾏;
- 执⾏完毕之后,Slave端跟master端数据保持⼀致!
5、数据库分库分表
一. 分表
对于访问极为频繁且数据量巨大的单表来说,我们首先要做的就是减少单表的记录条数,以便减少数据查询所需要的时间,提高数据库的吞吐,这就是所谓的分表!
二. 分库
分表能够解决单表数据量过大带来的查询效率下降的问题,但是,却无法给数据库的并发处理能力带来质的提升。面对高并发的读写访问,当数据库master
服务器无法承载写操作压力时,不管如何扩展slave服务器,此时都没有意义了。
因此,我们必须换一种思路,对数据库进行拆分,从而提高数据库写入能力,这就是所谓的分库
6、增删改查授权
1.创建用户 create uer xxxx@ "%" identified by '123456';
2.创建数据库 create database web;
3.创建数据表 creata table a1 (id int ,name char(30));
4.插入数据 insert into a2 (id,name,age)values (1,‘张三’,21);
1.删除用户 drop user xxx@‘%’;
2.删除数据库 drop database web;
3.删除数据表 drop table a1;
4.删除数据 delete from a2 where age between 23 and 25;
5.删除数据 delete from a2 where id=5;
1.修改表数据 update a2 set ager=21 where id=3;
2.修改数据表名称 alter table a2 rename a1;
3.修改表字段类型 describe a1 ; alter table a1 modify name char(50); describe a1;
1.添加删除字段 alter table a1 add time detetime;
1.查数据库 show databases;
2.查看库内所有表 show tables;
3.查指定数据表字段结构 describe a1;
4.查看所有mysql用户密码及登陆方式 select user,password,host from mysql,user;
1.给存在用户授权 grant all on aa.a1 to xxxx@‘%’;
2.创建用户并授权 grant all on aa.a1 to xxxx@‘%’ identified by '123456';
3.取消abc用户的删除库、表、表中数据权限 revoke drop,delete on aa.a1 from adc@‘%’;
4.查看指定用户授权 show grants for xxxx@‘%’;
5.取消删除权限 show grants for xxxx@‘%’;
7、SQL启动关闭
启动
service mysql start
/etc/init.d/mysqlid start
mysqld_safe &
关闭
service mysql stop
/etc/init.d/mysqlid stop
mysqladmin -uroot -p123456 shutdown
8、主从故障切换
主,接受数据
从,备份数据
开启主服务器binlog日志志
1.登陆从库查看post信息,post越大代表数据更完整,作为新主库,然后提升为新主库,登陆从库(新主)执行 stop slave
2.修改my.cnf配置文件,开启从binlog日志并重启数据库服务,登陆数据库执行restet master ,show masterstatus\G; 查看主库信息,创建授权同步用户与权限和网站使用数据库用户权限,修改对于服务器ip地址等信息,确保网络畅通。
3.登陆其他从库,执行change master操作查看同步状态。
9、单台性能瓶颈突破
横向:推硬件
纵向:利用第三方代理工具amoebe,完成类似nginx反向代理功能,分配流量到从服务器上,降低主库压力、读写分离
10、索引
索引本质是数据结构,排好序快速查找数据结构,可以提高查找效率。 类似字典的目录,随机的io查询变成顺序的io查询,先查索引空间,在查表空间。
主键索引
单值索引:一个索引只包含单个列,一个表可以有多个单列索引,如果字段会被经常用来检索就可以用单值索引
复合索引:一个索引包含多个列,如电话薄上姓+名,最好不超过5个字短
唯一索引:所有列单值必须唯一,允许有空值
缺点:
1.索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,索引列也要占用空间。
2.索引提高查询速度,降低更新表速度,如对表进行insert、updata。因为更新表示mysql不仅要保存数据,还要保存索引文件,每次更新添加了一个索引列的字段,都会调整因为更新带来的键值变化后的索引信息。
3.索引只是提高效率的一个因素,如果mysql有大数据量大表,就需要画时间研究,建立优秀索引,或优化查询。
Java相关
1、Full GC 的问题,为什么出现FULL GC的问题,为什么内存满
- 系统并发高、执行耗时过长,或者数据量过大,导致 young gc频繁,且gc后存活对象太多,但是survivor 区存放不下(太小 或 动态年龄判断) 导致对象快速进入老年代 老年代迅速堆满
- 发程序一次性加载过多对象到内存 (大对象),导致频繁有大对象进入老年代 造成full gc
- 存在内存溢出的情况,老年代驻留了大量释放不掉的对象, 只要有一点点对象进入老年代 就达到 full gc的水位了
- 元数据区加载了太多类 ,满了 也会发生 full gc
- 堆外内存 direct buffer memory 使用不当导致
- 也许, 你看到老年代内存不高 重启也没用 还在频繁发生full gc, 那么可能有人作妖,在代码里搞执行了 System.gc();
:::info
如果有监控,那么通过图形能比较直观、快速的了解gc情况;
如果没有监控,那么只能看gc日志或jstat来分析 这是基本技能 一定要熟练
观察年轻代 gc的情况,多久执行一次、每次gc后存活对象有多少 survivor区多大
存活对象比较多 超过survivor区大小或触发动态年龄判断 => 调整内存分配比例
观察老年代的内存情况 水位情况,多久执行一次、执行耗时多少、回收掉多少内存
如果在持续的上涨,而且full gc后回收效果不好,那么很有可能是内存溢出了 => dump 排查具体是什么玩意
如果年轻代和老年代的内存都比较低,而且频率低 那么又可能是元数据区加载太多东西了,其实如果是自己负责的系统,可能要看是不是发版改了什么配置、代码。
:::
2、分析内存的命令是什么,dump整个线程,怎么把堆栈信息打出来
jstack 是 JDK 自带的工具,用于 dump 指定进程 ID(PID)的 JVM 的线程堆栈信息。
# 打印堆栈信息到标准输出
jstack PID
# 打印堆栈信息到标准输出,会打印关于锁的信息
jstack -l PID
强制打印堆栈信息到标准输出,如果使用 jstack PID 没有响应的情况下(此时 JVM 进程可能挂起),加 -F 参数
jstack -F PID
使用 jcmd
jcmd 是 JDK 自带的工具,用于向 JVM 进程发送命令,根据命令的不同,可以代替或部分代替 jstack、jmap 等。可以发送命令 Thread.print 来打印出 JVM 的线程堆栈信息。
3、定位异常代码位置
1、使用top命令定位异常进程。可以看见12836的CPU和内存占用率都非常高
此时可以再执行ps -ef | grep java,查看所有的java进程,在结果中找到进程号为12836的进程,即可查看是哪个应用占用的该进程。
- 使用top -H -p 进程号查看异常线程
- 使用printf “%x\n” 线程号将异常线程号转化为16进制
- 使用jstack 进程号|grep 16进制异常线程号 -A90来定位异常代码的位置(最后的-A90是日志行数,也可以输出为文本文件或使用其他数字)。可以看到异常代码的位置。
大数据相关
1、HDFS写流程
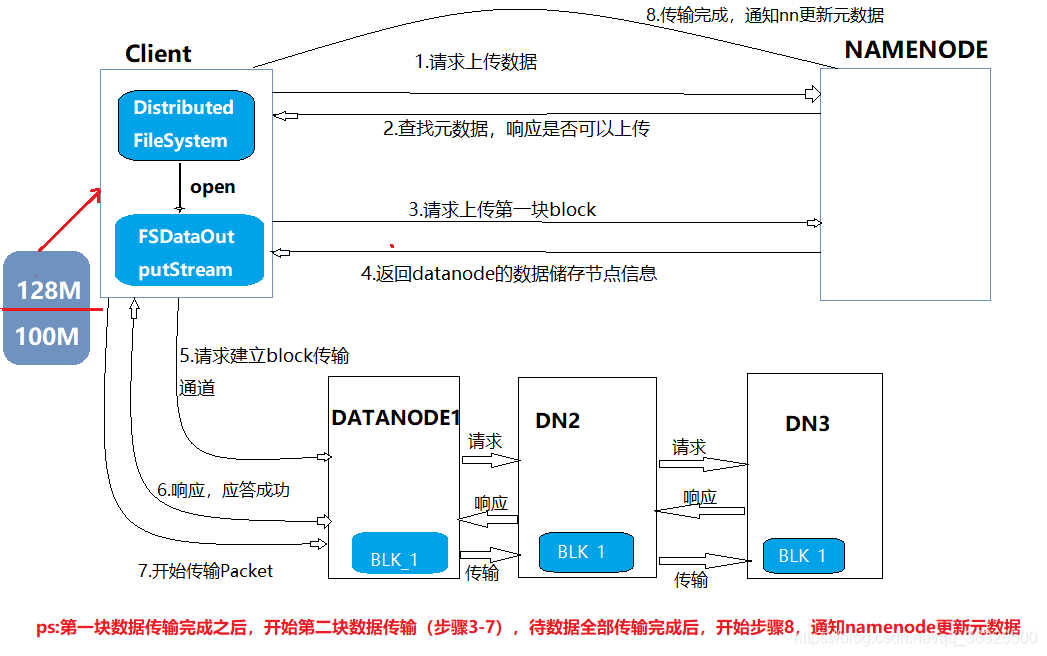
1.客户端向namenode发出请求上传数据;
2.namenode在接到请求之后,开始查找元数据(查找是否存在这个目录以及查询上传者是否有这个权限),查询后向客户端响应是否可以上传数据。
3.客户端接到响应之后,再开始请求上传第一块数据(数据分块是由客户端操作的),例如图中的0-128m为第一块数据。
4.namenode接到请求后,向客户端返回datanode节点信息(副本放在哪个节点上,例如放在DN1,DN2,DN3这三台机器上)。一般规则有近远远,近远近
5.客户端根据返回的副本信息向datanode请求建立传输通道,以级联的方式进行请求
6.datanode向客户端响应,若都应答成功,则传输通道建立成功。
7.开始传输数据,以packet方式传输,以chunk为单位进行校验,默认1m。
8.第一块上传成功,第二块开始从3-7步骤继续传输
9.待传输完成之后,客户端向namenode报告数据传输远程,由namenode更新元数据
2、HDFS读流程

1.客户端请求下载数据
2.nn检测数据是否存在,给客户端响应
3.客户端请求下载第一块数据
4.nn返回目标文件的元数据
5.客户端请求dn建立传输通道
6.dn响应
7.开始传输数据
3、ELK日志分析系统
ELK常见的架构
Elasticsearch + Logstash + Kibana
这是一种最简单的架构。这种架构,通过logstash收集日志,Elasticsearch分析日志,然后在Kibana(web界面)中展示。这种架构虽然是官网介绍里的方式,但是往往在生产中很少使用。
Elasticsearch + Logstash + filebeat + Kibana
与上一种架构相比,这种架构增加了一个filebeat模块。filebeat是一个轻量的日志收集代理,用来部署在客户端,优势是消耗非常少的资源(较logstash), 所以生产中,往往会采取这种架构方式,但是这种架构有一个缺点,当logstash出现故障, 会造成日志的丢失。
Elasticsearch + Logstash + filebeat + redis(也可以是其他中间件,比如kafka(集群化)) + Kibana
这种架构是上面那个架构的完善版,通过增加中间件,来避免数据的丢失。当Logstash出现故障,日志还是存在中间件中,当Logstash再次启动,则会读取中间件中积压的日志。目前我司使用的就是这种架构,我个人也比较推荐这种方式。
:::info
在生产环境中,由于logstash消耗资源过多,我们一半采用filebeat轻量级日志收集代理,让logstash专注于日志格式化,又由于生产环境中日志量过大,logstash一旦故障,会导致日志的丢失,所以要在filebeat与logstash中增加一个中间件redis或kafka来起一个缓存汇聚作用
:::

4、集群数据均衡
节点间数据均衡,利用率相差不超过10%
磁盘间数据均衡
配置lzo压缩
5、HDFS参数调优hdfs-site.xml
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。 对于大集群或者有大量客户端的集群来说,通常需要增大参数dfs.namenode.handler.count的默认值10
6、YARN参数调优yarn-site.xml
内存利用率不够,这个一般是Yarn的2个配置造成的,单个任务可以申请的最大内存大小,和Hadoop单个节点可用内存大小。调节这两个参数能提高系统内存的利用率。
yarn.nodemanager.resource.memory-mb
表示该节点上YARN可使用的物理内存总量,默认是8192(MB)注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。
yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是8192(MB)
7、Hadoop优化
NameNode的本地目录可以配置成多个,且每个目录存放内容相同,进而增加可靠性
DataNode可以配置成多个目录,每个目录存储的数据不一样(数据不是副本)
8、硬件选择
主流机器基本都是x86类型的机器,系统盘建议做成raid1采用ssd类别的盘这样既保证稳定性,又可以提高速度。数据盘基本上就是采用4T或8T这种机械盘,10块或12块或者更多。
关于这种数据盘较多的机器我们就要进行一些规划,比如大数据集群中的datanode与nodemanager节点可以使用这种机械盘,我们可以把数据盘做成raid0,挂载到/mnt下,由于hadoop的特性,即使坏掉一块或者整个机器都挂掉都不会产生数据丢失,但是有时候由于业务的特殊性,比如hbase需要更快更高的查询能力,那么这种机械盘可以换成ssd加快数据读取与存储。
关于hadoop的组件中其他比较重要的节点呢,如namenode这种组件,其实很简单,给予足够的内存与CPU,根目录使用ssd即可,目前线上的生产经验来看,超线程56C内存512G根1T的机器完全可以支撑起1000台节点左右的集群正常工作了。这里需要说一下,前提是你的集群健康,文件数没有那么庞大的情况下。
9、关闭swap空间
对于hadoop集群来说,如果使用系统默认设置,会导致swap分区被频繁使用,集群会不断发出警告。所以在搭建cloudera-manager的时候,会建议调整vm.swappiness参数
:::info
echo 0>/proc/sys/vm/swappiness
echo “echo 0 > /proc/sys/vm/swappiness”>>/etc/rc.d/rc.local
swapoff –a
:::
10、关闭透明页面压缩
已启用透明大页面压缩,可能会导致重大性能问题。
:::info
echo never > /sys/kernel/mm/transparent_hugepage/enabled echo never > /sys/kernel/mm/transparent_hugepage/defrag echo “echo never > /sys/kernel/mm/transparent_hugepage/defrag” >>/etc/rc.d/rc.local echo "echo never > /sys/kernel/mm/transparent_hugepage/enabled “>>/etc/rc.d/rc.local
:::
11、优化最大文件打开数
:::info
echo “* soft nofile 65535” >> /etc/security/limits.conf
echo “* hard nofile 65535” >> /etc/security/limits/conf
:::
12、hdfs块大小选择
默认是128M,但是生产集群规模较大,加上集群治理的文件数已经很低,所以就调整到了1GB,这里要注意的是hbase组件也在hdfs上则这个参数会对hlog也有作用,hlog的块大小也是相应的数值,所以要合理设置这个大小。
13、提高block迁移速度
提高block迁移速度有三个参数
第一个如下,增加DataNode上转移block的Xceiver的个数上限。
DataNode上同时用于balancer的Xceiver的个数受到了BlockBananceThrottler限制。可以适当调大如下的配置。这个参数还是需要谨慎调节,关系到rpc等待时间,其实50有点大了,可以调整至30.详细看这个网址说明的很清楚。https://blog.csdn.net/wisgood/article/details/47857549
14、平衡带宽
15、如何发挥集群最佳性能
原则1:CPU核数分配原则
数据节点:建议预留2~4个核给OS和其他进程(数据库,HBase等)外,其他的核分配给YARN。
控制节点:由于运行的进程较多,建议预留6~8个核。
原则2:内存分配
除了分配给OS、其他服务的内存外,剩余的资源应尽量分配给YARN。
原则3:虚拟CPU个数分配
节点上YARN可使用的虚拟CPU个数建议配置为逻辑核数的1.5~2倍之间。如果上层计算应用对CPU的计算能力要求不高,可以配置为2倍的逻辑CPU。
原则4:提高磁盘IO吞吐率
尽可能挂载较多的盘,以提高磁盘IO吞吐率。
16、影响性能的因素
因素1:文件服务器磁盘I/O
一般磁盘顺序读写的速度为百兆级别,如第二代SATA盘顺序读的理论速度为300Mbps,只从一个盘里读,若想达到1Gbps每秒的导入速度是不可能的。并且若从一个磁盘读,单纯依靠增加map数来提高导入速率也不一定可以。因为随着map数变多,对于一个磁盘里的文件读,相当由顺序读变成了随机读,map数越多,磁盘读取文件的随机性越强,读取性能反而越差。如随机读最差可变成800Kbps。 因此需要想办法增大文件服务器的磁盘IO读效率,可以使用专业的文件服务器,如NAS系统,或者使用更简单的方法,把多个磁盘进行Raid0或者Raid5。
因素2:文件服务器网络带宽
单个文件服务器的网络带宽越大越好,建议在10000Mb/s以上。
因素3:集群节点硬件配置
集群节点硬件配置越高,如CPU核数和内存都很多,可以增大同时运行的map或reduce个数,如果单个节点硬件配置难以提升,可以增加集群节点数。
因素4:SFTP参数配置
不使用压缩、加密算法优先选择aes128-cbc,完整性校验算法优先选择[email protected]
因素5:集群参数配置
Manager
提升Manager配置服务参数的效率
根据集群节点数优化Manager配置
HBase
提升BulkLoad效率
提升连续put场景性能
Put和Scan性能综合调优
提升实时写数据效率
提升实时读数据效率
JVM参数优化
HDFS提升写性能
JVM参数优化
使用客户端元数据缓存提高读取性能
使用当前活动缓存提升客户端与NameNode的连接性能
Hive
建立表分区
Join优化
Group By优化
数据存储优化
SQL优化
使用Hive CBO优化查询
Kafka
Kafka性能调优
MapReduce
多CPU内核下的调优配置
确定Job基线
Shuffle调优
大任务的AM调优
推测执行
通过“Slow Start”调优
MR job commit阶段优化
Solr
索引集分片划分建议
Solr公共读写调优建议
Solr over HBase调优建议
Solr over HDFS调优建议
Spark
Spark Core调优
SQL和DataFrame调优
Spark Streaming调优
Spark CBO调优
Carbon性能调优
Storm
Storm性能调优
YARN
通过容器可重用性提高任务的完成效率
抢占任务
任务优先级
节点配置调优
JVM参数优化
12.2 Manager
12.2.1 提升Manager配置服务参数的效率
操作场景
在安装集群或者扩容节点以后,集群中可能添加了较多数量的节点。此时如果系统管理员在FusionInsight Manager上修改服务参数、保存新配置并重启服务时,Manager的Controller进程可能占用大量内存,增加了CPU工作负荷,用户需要等待一段时间才能完成参数修改。系统管理员可以根据实际业务使用情况,手动增加Controller的JVM启动参数中内存参数,提升配置服务参数的效率。
对系统的影响
该操作需要在主管理节点重新启动Controller,重启期间会造成FusionInsight Manager暂时中断。备管理节点Controller无需重启。
前提条件
已确认主备管理节点IP。
操作步骤
使用PuTTY,以omm用户登录主管理节点。
执行以下命令,切换目录。
cd ${BIGDATA_HOME}/om-server/om/sbin
执行以下命令修改Controller启动参数文件“controller.sh”,并保存退出。
vi controller.sh
修改配置项“JAVA_HEAP_MAX”的参数值。例如,集群中包含了400个以上的节点,建议修改如下,表示Controller最大可使用8GB内存:
JAVA_HEAP_MAX=-Xmx8192m
执行以下命令,重新启动Controller。
sh ${BIGDATA_HOME}/om-server/om/sbin/restart-controller.sh
提示以下信息表示命令执行成功:
End into start-controller.sh
执行sh ${BIGDATA_HOME}/om-server/om/sbin/status-oms.sh,查看Controller的“ResHAStatus”是否为“Normal”,并可以重新登录FusionInsight Manager表示重启成功。
使用PuTTY,以omm用户登录备管理节点,并重复步骤 2~步骤 3。
12.2.2 根据集群节点数优化Manager配置
操作场景
FusionInsight集群规模不同时,Manager相关参数差异较大。在集群容量调整前或者安装集群时,用户可以手动指定Manager集群节点数,系统将自动调整相关进程参数。
说明:
在安装集群时,可以通过Manager安装配置文件中的“cluster_nodes_scale”参数指定集群节点数。
操作步骤
使用PuTTY,以omm用户登录主管理节点。
执行以下命令,切换目录。
cd ${BIGDATA_HOME}/om-server/om/sbin
执行以下命令查看当前集群Manager相关配置。
sh oms_config_info.sh -q
执行以下命令指定当前集群的节点数。
命令格式:sh oms_config_info.sh -s 节点数
例如:
sh oms_config_info.sh -s 10
根据界面提示,输入“y”:
The following configurations will be modified:
Module Parameter Current Target
Controller controller.Xmx 4096m => 8192m
Controller controller.Xms 1024m => 2048m
...
Do you really want to do this operation? (y/n):
界面提示以下信息表示配置更新成功:
...
Operation has been completed. Now restarting OMS server. [done]
Restarted oms server successfully.
说明:
配置更新过程中,OMS会自动重启。
相近数量的节点规模对应的Manager相关配置是通用的,例如100节点变为101节点,并没有新的配置项需要刷新。
12.3 HBase
12.3.1 提升BulkLoad效率
操作场景
批量加载功能采用了MapReduce jobs直接生成符合HBase内部数据格式的文件,然后把生成的StoreFiles文件加载到正在运行的集群。使用批量加载相比直接使用HBase的API会节约更多的CPU和网络资源。
ImportTSV是一个HBase的表数据加载工具。
前提条件
在执行批量加载时需要通过“Dimporttsv.bulk.output”参数指定文件的输出路径。
操作步骤
参数入口:执行批量加载任务时,在BulkLoad命令行中加入如下参数。
表12-1 增强BulkLoad效率的配置项
参数
描述
配置的值
-Dimporttsv.mapper.class
用户自定义mapper通过把键值对的构造从mapper移动到reducer以帮助提高性能。mapper只需要把每一行的原始文本发送给reducer,reducer解析每一行的每一条记录并创建键值对。
说明:
当该值配置为“org.apache.hadoop.hbase.mapreduce.TsvImporterByteMapper”时,只在执行没有HBASE_CELL_VISIBILITY OR HBASE_CELL_TTL选项的批量加载命令时使用。使用“org.apache.hadoop.hbase.mapreduce.TsvImporterByteMapper”时可以得到更好的性能。
org.apache.hadoop.hbase.mapreduce.TsvImporterByteMapper
和
org.apache.hadoop.h
因素6:Linux文件预读值
设置磁盘文件预读值大小为16384,使用linux命令:
echo 16384 > /sys/block/sda/queue/read_ahead_kb
Python接口自动化测试
1、Requests方法
请求
requests.get()
.post()
.delete()
.put()
.ququest() 最核心方法
返回
.text 返回text格式
.content 返回字节格式
.json 返回字典格式
.cookies 返回cookie信息 那是
2、四种常见请求方式
请求方式:get、post、delete、put
请求参数类型:键值对、json格式、文件格式
get 传递url、param 多个参数在url中用&分割,代码用,分割
post 传递url、(deta、json任意一个)
3、Json、Deta区别
deta:
数据报文:dict字典类型,默认情况情况下请求头:appliction/x-from-urlencoded,表示以from表单方式进行传参,格式a=1&b=2&c=3。
数据报文:str类型,默认请求头 text/plain(如果是字典格式需要转换成str格式传参)
json:
数据报文:不管是dict字典还是str类型,默认都是appliction/json。
格式{“a”.1,“b”.2} kv格式
json.dumps(data) 序列号 字典dict转换str
json.loads(data) 反序列化 str转换字典dict
deta只能传递简单的只有键值对的dict或者str格式,json一般只能传递dict格式
4、Cookies鉴权
网页接口基本都要做cookie鉴权,不常用
通过session实现cookie鉴权,常用
5、接口自动化框架封装
接口自动化框架封装第一步统一请求方式。
6、pytest用例管理框架
安装 pip install pytest
1.py文件必须以test_开头或者_test结尾
2.测试用例需要以test_开头
3.类名以test开头