1.词汇表征
1.1 one-hot词编码的缺陷
回顾上一节的词向量表示方式:one-hot编码。即根据拥有的尽可能多的语料,整理一份词典,词典长度为n,使得每个词对应一个n*1的词向量,其中该词索引所在的位置为1,其余位置为0. 比如,如下图,woman这个词在索引为9853的位置上是1,其余位置为0,这就是one-hot方式的word representation.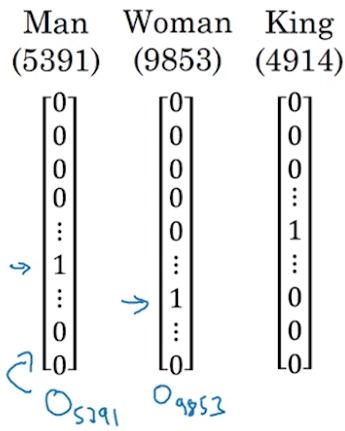
one-hot的词汇表征很简单,但是也有致命缺点,它无法表示词与词之间的相似性。
举个简单的例子:
I want a glass of orange __.
假设我先告诉你空格是填的是juice。然后再给你下面这个句子:
I want a glass of apple __.
你肯定想到也可以填juice啊,因为你知道orange与apple都是水果,它们在某种意义上有相似性。但是!!! 如果我们使用的是one-hot形式对词进行编码的话,我们完全无法根据词向量来计算词与词之间的相似性,而两个one-hot词向量的内积永远也等于0.
1.2 特征化表征
什么叫做特征化的表示,比如选一个特征是“gender”,于是每个词都可以评估出一个与gender相似性的值,”man”为-1,”woman”为1, 而apple与gender完全无关,为0,以此类推,如下表示:
假设,有300个特征,那么每个词就会形成一个300*1的词向量量,向量的每个维度都有特定特征的含义。由于”man”和”woman”是很相近的词,它们在很多特征维度上都有相近的值,因此这两个向量的距离会很近,即内积获得的相似性会很高:
因此再拿这个例子来说,由于orange与apple的词向量相似性高,因此可以根据orange后面填juice推到出apple后面也可以填juice.
I want a glass of orange .
I want a glass of apple .
总之,特征化的表示能比one-hot更好得表示不同的词
但是要注意的是,实际上的词向量,并不是有清晰直观的特征,告诉你第一维是性别,第二维是高贵等等,而是比这复杂得多,但我们可以去这样理解,就是向量中的每一维都代表着某个特征。
1.3可视化词嵌入
假设我们已经获得了300维的词向量,那么可以将它降维到2维空间,并且画在二维坐标上,如下,可见相似的词会被聚在一起
常见的可视化算法有t-SNE算法,来自于laurens van der maaten和Geoff Hinton的论文。
最后说一说为什么这个方法叫做embedding嵌入,想象一个300维的空间,一个词对应多300维的向量,就像是嵌在这个空间中的一个点,因此取名为嵌入。
2.词嵌入的应用
2.1 词嵌入在命名实体识别中的应用
假设有这样一个句子: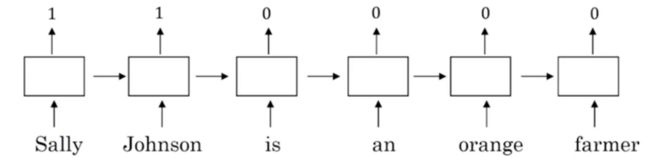
其中,Sally Johnson是一个人名,因此它们对应的预测应该是1,其余词的预测为0.我们之所以判断Sally Johnson是一个人名,而非公司名,是因为这句话的后面说了Sally Johnson是一个farmer(农民),fammer自然是一个人了。
由于训练中已经知道了,后面出现了farmer,那么前面的实体应该是人名,因此Robert Lin的预测为1.在这个例子中,使用one-hot或者词嵌入或许都能正确识别出。
但是,假设把”apple farmer”改成”durian cultivator(榴莲培育家)”呢?训练集中从未出现过durian和cultivator这两个词,于是one-hot方式就傻眼了,但是词嵌入的方式却仍然游刃有余。因为词嵌入的表征可以体现词与词之间的相似关系,而apple与durain, farmer与cultivator有很大的相似性,因此虽然训练集中压根就没有学到过这两个词,模型也可以预测出durian cultivator也是一个人。
以上可以看到,就算我们的训练样本比较少,没有覆盖尽可能多的词或样本类型,模型还是可以根据词嵌入向量来做更准确的预测。这里词嵌入的表征方式简直功不可没。那么词嵌入是如何得来的呢?你可以考察很大的数据集,可是是一亿或这100亿个词(来自于不需要标注的文本),然后对文进行学习,获得词嵌入的向量,这个大文本自然是越大越好,尽可能得包含所有的词,其中就有durain和cultivator,于是你就可以发现durain和apple等水果很相近。
用大量的文本训练出词嵌入,然后将词嵌入运用到只有小量样本的模型中,这就是运用了“迁移学习”。
另一点要注意的是,上图画的是一个单向的RNN,实际上做命名实体识别,一般使用的是双向RNN。
2.2总结词嵌入做迁移学习的步骤
(1)从大量的文本语料中学习词嵌入的向量(1-100亿词),或者直接从网上下载别人与训练好的向量。
(2)将词嵌入迁移到你只有少量样本的任务中,使得用几百维的向量代替之前上万维的one-hot向量。
(3)在新的数据上微调词嵌入向量。但是若你的样本数据很少,一般就不做微调了。
对迁移学习再多说一句,当有两个任务A,B。在A任务中你有大量的标注的数据,而B中却只有少量,于是可以将在A中学习到的东西迁移到B中,以弥补B因为样本少而导致的缺陷。
2.3 词嵌入与人脸编码
词嵌入与人脸编码有些奇妙的关系。
在使用卷积神经网络进行人脸对比时,过程如下图,输入一张图片,一层一层计算后最后会得到一个向量(比如128维),然后去比较两张图片的这两个向量的相似性,即对图片进行了编码。
词嵌入也差不多,对词进行了编码,因此两者有相似之处。
两者的不同之处是:
输入任何一张图片,都能得到一个图像编码的向量;而词嵌入是需要事先确定词库,假设有1亿个词参与了训练,如果出现另一个新词,那么将无法得到新词的词向量。
3.词嵌入的特性
3.1 词嵌入的类比推理特性
词嵌入还有一个很迷人的特性,那就是帮助类比推理,尽管类比推理在NLP的应用中不是最重要的角色,不过它帮助人们认识词嵌入到底做了什么。
假设我们已经获取了以下这些词的特征表示,并且假设词嵌入就是以下4个维度的向量。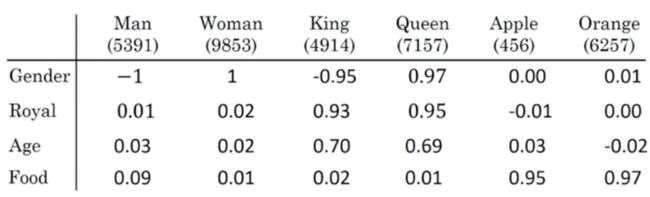
现在告诉你man对应的是woman:man--->woman,问king对应的是什么词:king--->?。你肯定会说king当然对应的是queen了,是的,你知道,但是计算机不知道啊,因此我们可以借助词嵌入的特性去通过类比找到这个对应的词。
正如上图,我们知道了man,woman的词向量,分别用e_man, e_woman表示,将这两个词向量相减得到一个向量; 同时将e_king与e_queen相减:
以上现象可见,通过词嵌入可以进行类比推理,根据man--->woman找到king--->?
也就是找出一个词\(w\), 使得它的词向量\(e_w\)与\(e_{king}-e_{man}+e_{woman}\)的向量最相近。
3.2 余弦相似性
前面讲了辣么多词相似性相似性相似性,但是相似性到底如何计算呢?常用的词向量之间的相似性一般用余弦相似性计算: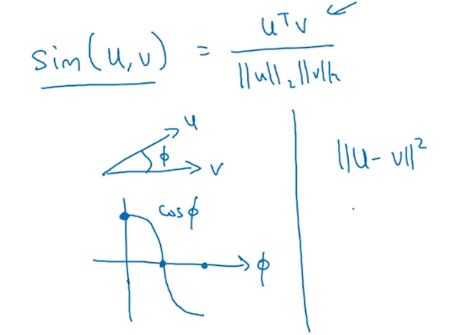
还有很多计算相似性的方法,比如欧式距离\(||u-v||^2\)
4.嵌入矩阵
上面几节分别讲了什么是词嵌入,词嵌入的应用与特性,现在开始,要具体讲一讲,我们到底是如何得到这个词嵌入的。获取词嵌入,其实就是去求一个嵌入矩阵(Embedding matrix)。于是这一节先来介绍下什么是嵌入矩阵。
假设有10000个词的词典,若按字母排,就是从\(a, aaron,......,orange,......zulu, 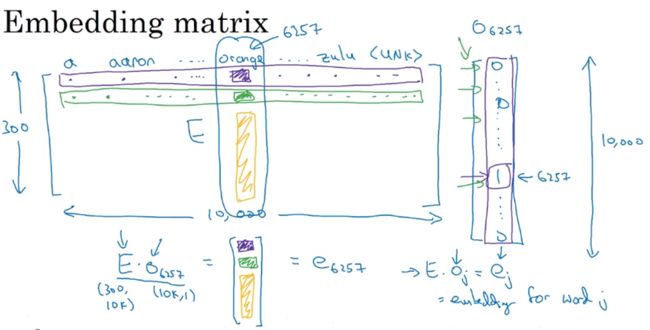
要得到每个词在次嵌入矩阵中对应的向量,使嵌入矩阵乘以这个词的one-hot向量即可。
嵌入矩阵记为\(E\),维度是(30010000)
某个词one-hot词向量(比如orange是排在词典的6257位,记为O_6257)
因此它们的积:\(E * O_6257\),会得到一个300 * 1的向量,其实就是这个词在嵌入举证对应的那一列向量。
推而广之,某个词\(O_j\)的嵌入向量(j是该词在词典中的位置),就是嵌入矩阵乘以该词的one-hot向量。
因此这一节,你只需要知道我们需要去训练这样一个嵌入矩阵,然后用这个嵌入矩阵与one-hot向量相乘,可以得到嵌入向量。
但需要注意的是,上面我们好像看似轻而易举得得到了嵌入矩阵与one-hot向量相乘的结果,但在实际计算中,由于向量的维数巨大,相乘的操作会带来巨大的计算量,因此实际中,往往直接根据词的索引去取出嵌入矩阵中对应的那一列向量。
5.学习词嵌入
在深度学习的历史上,人们曾经用很复杂的模型结构来训练词嵌入,随着不断得探索,现在我们已经可以用很简单的模型结构来训练出非常好的效果,特别是在大数据样本的情况下。但是我们仍然从最初的复杂模型开始讲起,这样你才能更深入得理解简单的模型到底为什么会取得好的效果。
假如你要构建一个语言模型,要根据前面的单词预测出下面这句话空格中的单词(单词下方的数字是该词在词典中的索引位置):
实践证明,建立一个语言模型,是学习词嵌入的好方法。因此我们现在来建立一个神经网络预测序列中的下一个单词。
- 首先空格前面的每个单词都匹配上对应的one-hot向量;
- 然后去乘以一个嵌入矩阵\(E\)(一开始这个\(E\)是一个随机初始化的300*10000的矩阵);
- 接着相乘后得到每个词的嵌入向量(如\(e_4343\))。
- 所有词嵌入向量都作为神经网络的输入
- 经过一个隐层之后,再输入softmax层,做10000(词典的长度)的分类,即输出层有10000个神经元,输出后可形成1*10000的向量,最好的预期是这个向量中,只有该词所在的索引位置为1,其他位置为0.

将每次输出的1*10000维向量与真实期望的词向量(上面是juice)计算损失,通过梯度下降法去调整嵌入矩阵中的值,使得潜入矩阵越来越能优秀地表征对应的词。
在实际中,往往会设置一个固定长度的窗口,比如5,意思是用前4个词去预测后一个词,这样就可以去适应非常长的句子了。
不单单可以设置不同长度的窗口,还可以使用前后文,比如用该词的前面4个词后4个词来预测该词;也可以只用前面一个词,或者前后一个词等。但实践证明,如果你的目的是训练一个语言模型,那么使用前后4个词可能效果更好,若你的目的是得到词嵌入矩阵,那么使用前后1个词也会很好。
因此,综上所述,通过以上训练语言模型的过程,就可以顺便得到了词嵌入矩阵。这是早期最成功的词嵌入学习算法之一。
6.word2vec
上一节介绍了一个复杂版本的词嵌入算法,现在来介绍一个更简单更灵活的模型来获得词嵌入,其中一种叫做Skip-grames。本节内容的大多数思想来自与Tomas Mikolov, Kai Chen,Greg Corrado 和Jeff Dean.
6.1 Skip-gram
假设给你这样一个句子:![]()
在skip-gram模型中,要做的是抽取上下文context与目标词target配对,来构造一个监督学习问题。上下文并不一定要是前一个词或者离得最近的四个单词之类,而是随机选择一个词作为上下文词,比如随机选择一个context词:orange.接着再随机选择一个在一定词距中的target词,比如随机选到了:juice,或者随机选到了前面的词:glass(词距是一开始认为设定的,比如前后10个词中随机选)。
显然,这不是一个简单的监督学习,因为context词前后n个词距中许多不同词。但构造这个监督学习模型,并不是去解决模型本身的问题,而是想通过这个训练过程,去得到中间的词嵌入矩阵。
现在来讲讲模型的细节,假设仍然使用一个10000词的词表(当然实际上要大得多)。并且已经随机取了一对context和target词,比如分别是context:orange–>target:juice.模型的过程和上一节一样:
输入context词的one-hot词向量
–>乘以初始化的词嵌入矩阵E
–>得到词嵌入向量
–>经过softmax层
–>输出词汇表大小长度的词向量y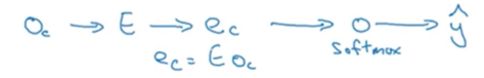
softmax层的计算公式如下: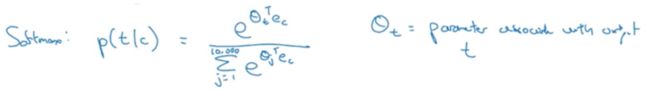
损失函数如下:是两个one-hot词向量的差值之和
\(y\)是context词的one-hot词向量,\(\hat{y}\)是模型softmax层的输出,也是一个长度与前者相当的词向量。
这个模型有两类参数,一个是词嵌入矩阵E中的值,一个somtmax层中的参数,随着损失函数的最小化,这两类参数都会得到优化,并且越来越准确,从而我们就得到了我们最终想要的词嵌入矩阵啦~以上就是skip-gram模型~
6.2 problems with softmax classification
但是上面讲述的Skip-grames模型有一个很大的缺点,就是计算量太大了。来看softmax的计算公式: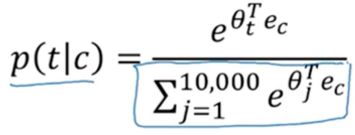
分母部分需要对词汇表中的每个词都计算后求和,一般情况下词汇表都会很大,因此求和操作是相当慢的。那么如何解决呢,下面就来讲一讲。
6.2.1 分级softmax 分类器
在一些文献中你会看到hierarchical softmax classider。什么意思呢?也就是在sofmax层不一次到位求出每个词的概率,而是通过分类的方式,第一个分类器告诉你这个词是在词汇表的5000前还是后,第二个分类器告诉你是在2500前还是后,以此类推,直到找到那个准确的词。像我们平时玩的猜数字游戏,一个人先在纸上写好一个数字,然后开始让大家猜,然后一步一步逼近真实数字,直到猜中的人接受真心话大冒险
画出来的形状是树状的,每个节点是一个分类器: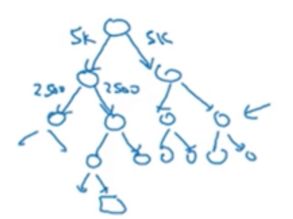
7.负采样Nagtive sampling
上面一节讲述了用分级softmax 分类器去降低softmax层的计算复杂度,这一节讲述一个更好的方法,,叫做负采样,来一起看看吧~
7.1 过程详述
(1)准备样本
还是这句话:![]()
和上一节一样,随机采出一个词作为context词,再在给定的词距下随机获取该词的target词,形成一组样本:orange-->juice。这组样本是一个正样本。
有了正样本,就肯定需要负样本,负样本是这样得到的:context词不变,然后随机从词典中采样出k个词,这些词可以是句子中没有的词,也允许是句子中有的词,总之随缘就好,不强求,于是context词就与这些随机从词典中采样的词形成了几对负样本: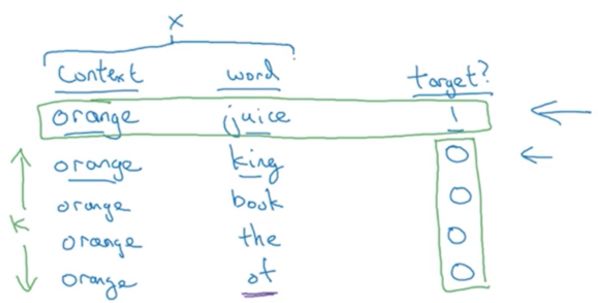
关于k的数目,如果你的数据集很小,那么k在5-20之间,如果你有大数据集,那么k在2-5之间
(2)训练模型
有了样本之后,就可以训练一个监督模型了。
模型的输入x是词对,也就是我们上面准备好的正样本与负样本;模型的输出y是一个二分类,若正样本则为1,负样本则为0。显而易见,这个模型对目的是去学习两个词是否是临近词,临近词为正样本,非临近词为负样本。
这样的二分类我们选择用逻辑回归模型去构造: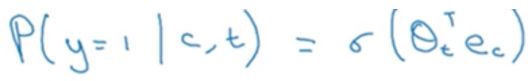
公式里有两个参数,一个是目标词的参数向量\(θ(t)\),一个是上下文词\(e(c)\),即每个contxt word的词嵌入向量。利用上面公示预测处\(t,c\)共现时\(y=1\)时的概率
纵观整个神经网络模型,前面的套路不变:
(1)输入context word的one-hot向量
(2)乘以嵌入矩阵\(E\)
(3)得到context word的词嵌入
(4)进入神经网络,输出10000维向量(10000是词典长度)
要注意的是第(4)步,这个输出并不是之前的softmax的10000个概率,而是10000个逻辑回归二分类器,表示词典中每个索引上的词是否与context临近。
但!并不是每次训练都要训练全部10000个逻辑回归,我们只训练其中5个,分别是,那个正样本的target词所在位置的逻辑回归模型,和另外四个采样的负样本所在位置的模型(假设我们设置了k=4)。
如此以来,原来复杂的要计算10000次的softmax层变成了计算相对简单的10000个逻辑回归二分类模型,且每次训练只需要训练\(k+1\)个logistic unit,是不是大大减小了计算量呢~
7.2如何选取负样本
那么如何进行更优的负采样呢?
论文的作者Mikoolov等人根据经验认为根据一下经验值采样会更好:
\(w_i\)表示第\(i\)个词,\(f(w_i)\)表示第\(i\)个词在所有语料中的词频。但是这是针对英文单词的分布的,中文的不知道适不适用呢~
8.GloVe词向量
前面讲了word2vec算法进行词嵌入的学习,这一节将介绍另一种也表现很好且更简单的算法:GloVe算法(global vectors for word representatiom)。虽然它并没有word2vec那么火,但是也有人热衷于它。
又是这句话:![]()
word2vec中获取了词对:context–>target。在glove中使词对的关系明确化。
\(X_{ij}\)表示词i出现在j的上下文的次数,这里用\(ij\)来表示\(tc\),因此\(X_{ij}\)等同于\(X_{tc}\)(\(t\)表示\(target\), \(c\)表示\(context\))。
实际上,\(X_{ij}\)也经常与\(X_{ji}\)对称,比如当你将窗口设定为前后10个词时。
也就是说word2vec中判断的是两个是否相邻,GloVe关注的是两个词相邻出现对次数
因此,GloVe model的具体做法是酱紫的:
其目标函数是最小化以下公式:![]()
\(θ(i)\)和\(e(j)\)分别表示target word与context word的词嵌入向量;
\(f(X_{ij})\)是一个权重项,对于像the, a, an,of等停用词会给予较小权重,对于durain这种稀有词但有蛮重要点词给予增加权重;
\(log(X_{ij})\)表示的是i词与j词的相似程度。
由于此处是i和j是对称的,因此最终词嵌入\(e(w)\)可以是\(θ(w)\)与\(e(w)\)的均值
9.情感分类Sentiment classification
情感分类是指对一个文本(一篇文章,新闻,微博评论等等)预测出笔者对所描述的东西的情感是正向的还是负向的(喜欢还是讨厌),是NLP中一个应用很普遍,业务需求很旺盛的一个部分。在没有词嵌入向量之前,我们需要标注大量的数据去训练这个有监督的分类模型,但是现在有了词嵌入后,需要的样本量就大大减少了哦~
9.1 输入与输出
首先明确输入输出
首先输入是一段文本;输出是要预测的相应的情感,可以是正负的二分类,也可以是评级的多分类(比如影评和淘宝评价又5个等级)
9.2简单的模型
a.先来说说一个简单的模型。 此时假设我们已经训练好了一个优先的嵌入矩阵E;
b.将输入文本中的每个词都在E中找到对应的词嵌入e,可以用上文介绍过的方法,即用该词的one-hot词向量去乘以E;
c.将所有词嵌入求均值或者加和,将n个向量变成一个向量。这里n的大小其实就文本中词的个数假设词向量是300维的,那么最终求均值或和之后,就生成一个新的300维的向量;
d.将这个300维的向量做为神经网络的输入(即输入层又300个神经元),经过一个softmax分类层,输出情感的分类,若又5类情感,则输出层又5个神经元。

但这个模型有巨大的缺点,就是不考虑词的顺序,假设评论如下:
“completely lacking in good taste, good service, and good ambience”
这句话说是lacking, 但是却又3个good,因此直接将词向量均值或求和,就会认为是good,并没有捕捉到前面说的是lacking good XXX.
9.3 RNN for sentiment classification
要捕捉顺序上的信息,此时果断就需要RNN来闪亮登场了!
同样是输入每个词的词嵌入向量,在最后一个时刻的输出情感的分类结果,具体结构如下: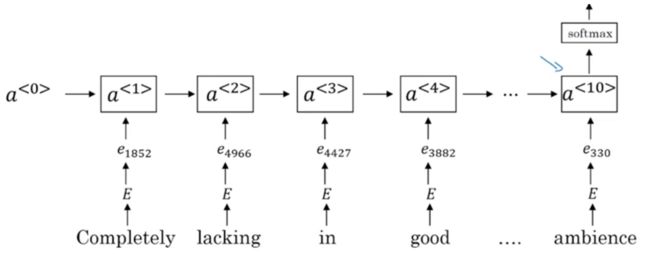
10.词嵌入除偏
10.1 什么偏?
这里,除偏的偏,不是机器学习里技术上的bias,而是偏见的偏,话不多说,举几个例子你就懂。![]()
比如上面这句,男人之于程序员 就像 女人之于家庭主妇
中国同胞们肯定就疑惑了,这句话好像没啥偏见啊,而且还挺准的。咳咳,我大中华真是直男成灾啊。你说说凭啥女性就不能做程序员,男性就不能在家带孩子。![]()
再比如上面这句,父亲之于医生 就像 母亲之于护士
是的,的确在国内,医生男的居多,护士大多都是女性,因此直男又要反驳这哪里有bais,明明是社会常态啊。
不同社会下的语料训练出的词向量,会反应当下的性别,种族,年龄等偏见,这与当下的社会,经济,政治,文化状态都相关。也许某些观念在我们骨子里已经根深蒂固,且无法与之相抗,也不能要求整个社会的改变,但至少将被广泛应用于人类社会方方面面的机器学习与人工智能,能杜绝掉被这些传统意识形态的束缚,能真正成功不带任何偏见,没有有色眼镜,公正公平平等得去效力于各行各业的业务场景中。
10.2 如何除偏
假设有这样几个词: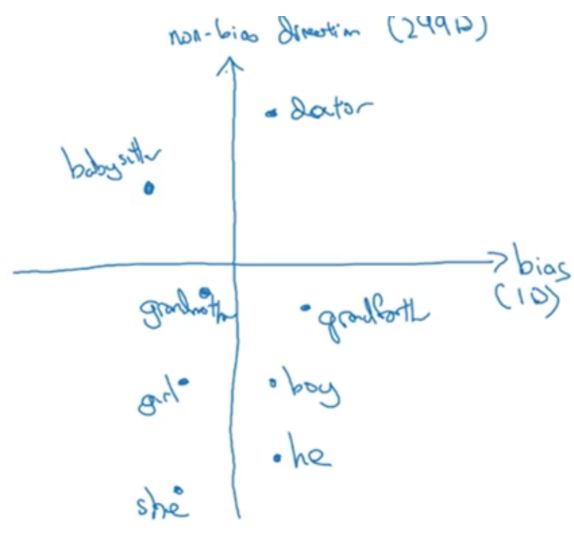
- 第一步:Identify bias direction
以除去性别偏见为例,将性别词相减,然后再求均值
\(e_{he}\) - \(e_{she}\)
\(e_{male}\) - \(e_{female}\)
…
–>\(average\)
从上图的分布可见,横轴代表了偏见的方向,给它1个维度;纵轴代表了无偏见的方向,给它299个维度(这里讲述地比实际论文中要简单,论文中的偏见方向不只1维,而且以上也不是简单得求均值,而是用起一只分解的方法。
- 第二步:Neutralize 中和偏见。
有一些词本身就有性别上的信息,比如he,she,father,mother;而有一些词本身和性别并无关系,如doctor, nurse, homemaker, computer-programer等,即在性别上是中立等,因此需要对这些词做消除偏见(以上坐标中doctot是在男性那一侧,应该调整到在男性女性中间。
- 第三步:Equalze pair 均衡。
比如使得babysiter能够到gramdfather和grandermother的距离一样近。做法就是将gramdfather和grandermother移动到根据纵轴对称,而将babysiter移动到纵轴上。
那么如何找出哪些词是中立词呢,论文的作者建立了二分类到监督模型进行中立与非中立的分类。
参考文献:【序列模型】第二课--自然语言处理与词嵌入