Centos7下PostgreSQL11安装主从及压测
一、 环境准备
postgresql搭建主从复制
服务器:
主:192.168.175.80
从:192.168.175.82
端口:5432
配置环境:
1.创建用户组用户
groupadd postgres
useradd -g postgres postgres
2.安装依赖包:
yum -y install gcc gcc-c++ bzip2 gzip zip unzip openssl openssl-devel zlib-devel zlib -y
yum install readline-devel -y
- 创建目录
①/opt/itom
②/data/pgdata
③/tmp/itom 作为安装包路径
4.配置环境变量
[root@www ~]# vi /etc/profile
export PATH=$PATH:/usr/pgsql-11/bin
[root@www ~]# source /etc/profile
[root@www ~]# systemctl restart postgresql-11
执行命令 source /etc/profile 令配置生效
二、安装
1、安装rpm包
yum install -y yum install -y https://download.postgresql.org/pub/repos/yum/10/redhat/rhel-7.8-x86_64/pgdg-redhat-repo-42.0-11.noarch.rpm
- 安装客户端
yum install -y postgresql-11
3、安装服务器
yum install -y postgresql11-server
默认创建一个‘postgres’的系统账号,用于执行PostgreSQL;同时生成一个'postgres'的数据库;
4、初始化
/usr/pgsql-11/bin/postgresql11-setup initdb
5、设置开机自启、启动
systemctl enable postgresql-11
systemctl start postgresql-11
三、配置使用
1、修改用户密码
su postgres //yum安装的默认创建一个'postgres'用户
psql -U postgres // 进入postgres数据库
alter user postgres with password 'sieiot12@!'
四、 主从配置
1、切换到postgres用户(安装好生成默认的用户)
su - postgres
psql 进入数据库
2、创建账号并授权
postgres=# create role 账户名 login replication encrypted password '密码';
3、修改/var/lib/pgsql/11/data/pg_hba.conf配置文件.
IPv4 local connections:
host all all 127.0.0.1/32 ident
添加如下内容
host replication repl 192.168.175.0/23 md5
host all repl 192.168.175.0/23 trust
4、修改postgresql.conf
-bash-4.2$ vi /var/lib/pgsql/11/data/postgresql.conf
listen_addresses = '192.168.175.80'
wal_level = hot_standby #热备模式
max_wal_senders= 6 #可以设置最多几个流复制链接,差不多有几个从,就设置多少
wal_keep_segments = 10240 #重要配置
wal_send_timeout = 60s
max_connections = 512 #从库的 max_connections要大于主库
archive_mode = on #允许归档
archive_command = 'cp %p /url/path%f' #根据实际情况设置
五、从数据库配置
1、切换到postgres
su - postgres
2、拷贝master配置相关文件。
-bash-4.2$ rm -rf /var/lib/pgsql/11/data/*
-bash-4.2$ pg_basebackup -h 192.168.175.80 -U repl -D /var/lib/pgsql/11/data -X stream -P
-bash-4.2$ cp /usr/pgsql-11/share/recovery.conf.sample /var/lib/pgsql/11/data/recovery.conf
3、修改recovery.conf文件
standby_mode = on
primary_conninfo = 'host=192.168.175.80 port=5432 user=master创建的用户名 password='密码'
trigger_file = '/var/lib/pgsql/11/data/trigger.kenyon' #主从切换时后的触发文件
recovery_target_timeline = 'latest'
4、修改postgresql.conf文件vi /var/lib/pgsql/11/data/postgresql.conf
listen_addresses = 192.168.175.81
wal_level = hot_standby
max_connections = 1000 #一般从的最大链接要大于主的。
hot_standby = on #说明这台机器不仅仅用于数据归档,也用于查询
max_standby_streaming_delay = 30s
wal_receiver_status_interval = 10s #多久向主报告一次从的状态。
hot_standby_feedback = on #如果有错误的数据复制,是否向主进行范例
六、检测
1、在master数据库中测试
select client_addr,sync_state from pg_stat_replication;

2、在master数据库中创建test数据库

3、在从数据库中查看数据库是否同步。

七、使用pgbench对PostgreSQL进行压力测试
1、安装pgbench:yum install postgresql10-contrib
2、初始化pgbench使用的库
首先将shell切换到postgres用户下,使用psql新建一个测试用的数据库pgbench
postgres=# CREATE DATABASE pgbench;
CREATE DATABASE
postgres=# \q

然后执行如下命令初始化pgbench库
# pgbench -i [option...] [dbname]
pgbench -i pgbench

默认会在pgbench库中初始化四张表:
table # of rows
---------------------------------
pgbench_branches 1
pgbench_tellers 10
pgbench_accounts 100000
pgbench_history 0
初始数据只有10万行,我们可以使用-s参数增加初始化时候的数据量
pgbench -i pgbench -s 100


耗时56s
3、使用默认的测试脚本
完成了测试库的初始化后,就可以使用不加-i参数的pgbench命令进行测试了。
# pgbench [options] dbname
pgbench pgbench
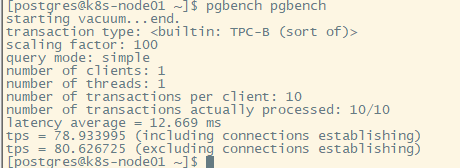
# pgbench [options] dbname
starting vacuum 表示清理缓存
transaction type 表示测试用的事务脚本类型(TPC-B measures throughput in terms of how many transactions per second a system can perform,TPC-B类型表示测试每秒处理事务个数)
scaling factor 表示比例因子,使用pgbench内建测试脚本的时候不需要理会该参数
query mode 表示查询协议,我也不知道什么意思=。=
number of clients 表示客户端数量
number of threads 表示工作线程数量
number of transactions per client 表示每个客户端执行的测试事务数量
number of transations actually processed 表示实际执行完成的事务数量(= 客户端数 * 每客户端执行事务数)
tps 表示每秒能处理多少个事务(transactions per second)
3.1 参数
完成了测试库的初始化后,就可以使用不加-i参数的pgbench命令进行测试了。
-c clients
模拟客户端的数量,也就是并发数据库会话的数量。缺省是1。
-C
为每个事务建立一个新的连接,而不是每客户端会话只执行一次。 这对于测量连接开销是有用的。
-d
打印调试输出。
-D varname=value
定义一个自定义脚本使用的变量(见下文)。允许使用多个-D选项。
-f filename
从filename中读取事务脚本,而不使用内建事务脚本。见下文获取细节。 -N、-S、和-f是互相排斥的。
-j threads
pgbench中工作线程的数量。在多CPU的机器上使用多个线程会很有帮助。 客户端的数量必须是线程数量的倍数,因为每个线程都有相同数量的客户端会话管理。 缺省是1。
-l
记录每个事务写入日志文件的时间。见下文获取细节。
-M querymode
提交查询到服务器使用的协议:
simple:使用简单的查询协议。
extended:使用扩展的查询协议。
prepared:使用带有预备语句的扩展查询协议。
缺省是简单的查询协议。(参阅第 48 章获取更多信息。)
-n
运行测试时不执行清理。如果你正在运行一个不包含标准表pgbench_accounts、 pgbench_branches、pgbench_history、和 pgbench_tellers的自定义测试,那么该选项是必需的。
-N
不要更新pgbench_tellers和pgbench_branches。 这将避免争用这些表,但是它使得测试用例更不像TPC-B。
-r
在benchmark完成后报告每个命令的平均每语句延迟(从客户的角度看的执行时间)。 见下文获取细节。
-s scale_factor
在pgbench的输出中报告指定的比例因子。在内建的测试中,这不是必需的; 正确的比例因子将通过计数pgbench_branches表中的行数检测到。 不过,在测试自定义benchmark(-f选项)时,比例因子将报告为1,除非使用了该选项。
-S
执行只有select的事务,替代类似TPC-B的测试。
-t transactions
每个客户端运行的事务数量。缺省是10。
-T seconds
运行测试这么多秒,而不是每客户端固定数量的事务。-t 和-T是互相排斥的。
-v
在运行测试之前清理四个标准表。既不用-n也不用-v, pgbench将清理pgbench_tellers和pgbench_branches表, 截断pgbench_history表。
--aggregate-interval=seconds
汇总时间间隔的长度(以秒计)。可能只与-l选项一起使用, 日志包含每间隔的总结(事务的数量、最小/最大延迟和可用于方差估计的两个额外字段)。
目前在Windows上不支持这个选项。
--sampling-rate=rate
采样率,在写入数据到日志时使用,以减少生成日志的数量。如果给出了这个选项, 则只记录指定比例的事务。1.0意味着记录所有事务,0.05意味着只记录了5%的事务。
在处理日志文件时记得计算上采样率。例如,计算tps值时,需要乘以相应的数字 (比如,0.01的采样率,将只得到1/100的实际tps)。
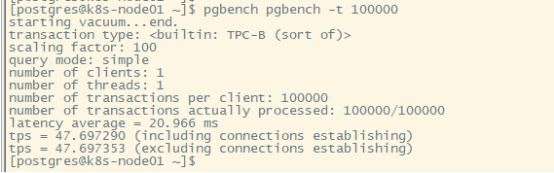
# 测试10w个事务
pgbench pgbench -t 100000
测试300秒
pgbench pgbench -T 300

3.2 默认的事务脚本
pgbench默认使用内建的事务脚本进行测试,每个事务包括如下七个命令:
1. BEGIN;
2. UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
3. SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
4. UPDATE pgbench_tellers SET tbalance = tbalance + :delta WHERE tid = :tid;
5. UPDATE pgbench_branches SET bbalance = bbalance + :delta WHERE bid = :bid;
6. INSERT INTO pgbench_history (tid,bid,aid,delta,mtime) VALUES (:tid, :bid, :aid, :delta, CURRENT_TIMESTAMP);
7. END;
注:如果你声明了-N,那么不包含步骤4和5。如果你声明了-S, 那么只发出SELECT。
八、性能压力测试
测试内容:
PostgreSQL默认测试脚本,含UPDATE、INSERT还有SELECT等操作,模拟一次简短的 “查询---交易---确认”过程。
测试模型:TCP-B
关注指标:TPS
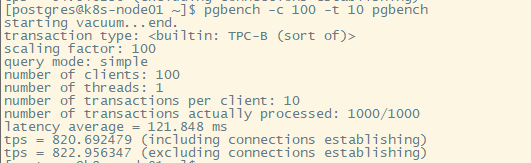
实验一:
100个用户,每个用户10个事务:
pgbench -c 100 -t 10 pgbench
500个用户,每个用户10个事务:

800个用户,每个用户一个事务:这里报错,修改一下连接数

查看一下默认的连接数上限:
show max_connections;

修改为1000,再来
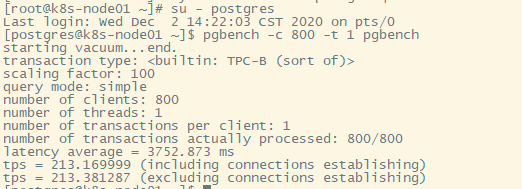
800个用户,每个用户5个事务
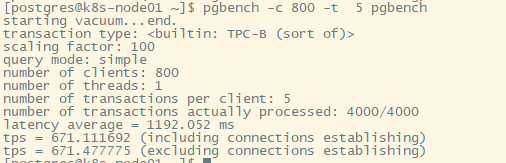
算上链接建立时间,单纯增加事务量对性能改善还是可以的,tps每秒处理事务有所增加。
使用并行压测
500个用户,每用户5个事务,4线程并发处理

改善还是比较客观的,串行接近极限后,横向的增加并行还是有性能提升空间的。
把用户数提升到800看一下:
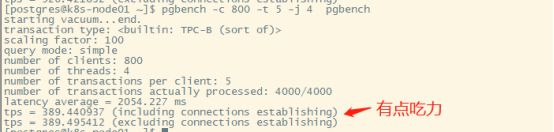
再回到500用户,把并发增加一倍:

把用户数提高一下,那么可以看一下具体在哪个环节延迟比较高,然后调整一下语句后者是逻辑思路:
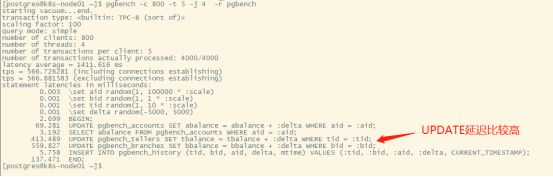
模拟交易测试:
平时我们在网上买东西、团购卷、订机票等等的时候,一般最后结账的时候看一眼信息、输入以下支付密码,然后不经意的点一下付款成功的信息,我们假设平均大概在20秒左右。

如上是测试结果,对于不同的业务内容不同,软硬件配置不同,测试结果会有很大的出入。