Pytorch框架详解
文章目录
- 引言
- 1. 安装与配置
-
- 1.1 如何安装PyTorch
- 1.2 验证安装
- 2. 基础概念
-
- 2.1 张量(Tensors)
-
- 2.1.1 张量的基本特性
- 2.1.2 创建张量
- 2.1.3 张量操作
- 2.2 自动微分(Autograd)
-
- 2.2.1 基本使用
- 2.2.2 计算梯度
- 2.2.3 停止追踪历史
- 2.2.4 自定义梯度函数
- 2.2.5 其他注意事项
- 3. 计算图和自动微分
-
- 3.1 计算图的概念
-
- 3.1.1 节点和边
- 3.1.2 前向传播和反向传播
- 3.1.3 动态和静态计算图
- 3.1.4 计算图和自动微分
- 3.1.5 优点和局限性
- 3.2 如何使用Autograd
-
- 3.2.1 张量与梯度追踪
- 3.2.2 进行张量操作
- 3.2.3 反向传播
- 3.2.4 停止梯度追踪
- 3.2.5 计算更复杂的梯度
- 3.3 自定义梯度
-
- 3.3.1 例子:自定义 ReLU 函数
- 3.3.2 使用自定义 Autograd 函数
- 4. 神经网络基础
-
- 4.1 模块(nn.Module)
-
- 4.1.1 基本结构
- 4.1.2 简单示例
- 4.1.3 参数管理
- 4.1.4 嵌套模块
- 4.1.5 损失函数与优化器
- 4.1.6 GPU 支持
- 4.2 激活函数
-
- 4.2.1 ReLU(Rectified Linear Unit)
- 4.2.2 Sigmoid
- 4.2.3 Tanh(Hyperbolic Tangent)
- 4.2.4 Leaky ReLU
- 4.2.5 Softmax
- 4.2.6 其他激活函数
- 4.2.7 使用激活函数
- 4.3 nn.Sequential
-
- 4.3.1 基本用法
- 4.3.2 嵌套使用
- 4.3.3 使用 OrderedDict
- 4.3.4 注意事项
- 4.4 损失函数
-
- 4.4.1 均方误差损失(Mean Squared Error Loss, MSE)
- 4.4.2 交叉熵损失(Cross Entropy Loss)
- 4.4.3 二元交叉熵损失(Binary Cross Entropy Loss)
- 4.4.4 Hinge Loss
- 4.4.5 自定义损失函数
- 4.4.6 使用损失函数
- 5. 优化算法
-
- 5.1 梯度下降(Gradient Descent)
-
- 5.1.1 基本原理
- 5.1.2 变体
- 5.1.3 在 PyTorch 中使用梯度下降
- 5.1.4 注意事项
- 5.2 其他优化算法(如Adam, RMSProp等)
-
- 5.2.1 Adam(Adaptive Moment Estimation)
- 5.2.2 RMSProp(Root Mean Square Propagation)
- 5.2.3 Adagrad
- 5.2.4 Adadelta
- 5.2.5 FTRL(Follow The Regularized Leader)
- 5.2.6 优化器选择注意事项
- 6. 数据加载和预处理
-
- 6.1 使用DataSet
- 6.2 使用DataLoader
- 6.3 自定义数据集
-
- 6.3.1 创建自定义 Dataset
- 6.3.2 使用自定义 Dataset
- 6.3.3 数据预处理
- 7. 实战:构建一个简单的神经网络
-
- 7.1 数据准备
- 7.2 构建模型
- 7.3 训练模型
- 7.4 评估模型
- 8. 调试和可视化
-
- 8.1 使用TensorBoard
-
- 8.1.1 安装 TensorBoard
- 8.1.2 导入 TensorBoard
- 8.1.3 初始化 SummaryWriter
- 8.1.4 记录标量、图像、直方图等
- 8.1.5 启动 TensorBoard
- 8.1.6 关闭 SummaryWriter
- 8.2 Debugging技巧
-
- 8.2.1 打印形状和类型
- 8.2.2 使用断言
- 8.2.3 打印梯度信息
- 8.2.4 使用 **.item()** 和 **.detach()**
- 8.2.5 使用 PyTorch 的 torch.set_printoptions
- 8.2.6. PyTorch 内置的 Debugging 工具
- 8.2.7 使用标准的 Python Debugging 工具
- 8.2.8 Logging
- 9. 模型保存和加载
-
- 9.1 保存模型参数
-
- 9.1.1 保存整个模型
- 9.1.2 仅保存模型参数
- 9.1.3 注意事项
- 9.2 加载模型参数
-
- 9.2.1 注意以下几点:
- 10. 高级主题
-
- 10.1 使用GPU加速
-
- 10.1.1 检查 GPU 是否可用
- 10.1.2 指定设备
- 10.1.3 将模型移动到 GPU
- 10.1.4 将数据移动到 GPU
- 10.1.5 多 GPU 使用(可选)
- 10.2 分布式训练
-
- 10.2.1 分布式训练的方式
- 10.2.2 初始化分布式环境
- 10.2.3 分布式数据并行
- 10.2.4 损失和优化器
- 10.2.5 加载和保存模型
- 10.2.6 示例代码
- 10.3 量化
-
- 10.3.1 预备步骤
- 10.3.2 准备模型
- 10.3.3 选择量化配置
- 10.3.4 静态量化示例
- 10.3.5 动态量化示例
- 10.3.6 量化感知训练示例
- 10.3.7 优缺点
- 11. PyTorch生态圈
-
- 11.1 torchvision
-
- 11.1.1 预训练模型
- 11.1.2 数据集
- 11.1.3 数据转换
- 11.1.4 工具函数
- 11.1.5 示例
- 11.2 torchaudio
-
- 11.2.1 主要功能
- 11.2.2 示例
- 11.2.3 使用场景
- 11.3 torchtext
-
- 11.3.1 主要功能
- 11.3.2 示例
- 11.3.3 使用场景
引言
- 什么是Pytorch?
PyTorch是一个开源的机器学习库,用于各种计算密集型任务,从基本的线性代数和优化问题到复杂的机器学习(深度学习)应用。它最初是由Facebook的AI研究实验室(FAIR)开发的,现在已经成为一个广泛使用的库,拥有庞大的社群和生态系统。
主要特点:
- 张量计算能力 :PyTorch提供了一个多维数组(也称为张量)的数据结构,该数据结构可用于执行各种数学运算。它也提供了用于张量计算的丰富库。
- 自动微分:PyTorch通过其Autograd模块提供自动微分功能,这对于梯度下降和优化非常有用。
- 动态计算图:与其他深度学习框架(如TensorFlow的早期版本)使用静态计算图不同,PyTorch使用动态计算图。这意味着图在运行时构建,这使得更灵活的模型构建成为可能。
- 简洁的API:PyTorch的API设计得直观和易于使用,这使得开发和调试模型变得更加简单。
- Python集成:由于PyTorch紧密集成了Python,因此它可以轻松地与Python生态系统(包括NumPy、SciPy和Matplotlib)协同工作。
- 社群和生态系统:由于其灵活性和易用性,PyTorch赢得了大量开发者和研究人员的喜爱。这导致了一个活跃的社群以及大量的第三方库和工具。
- 多平台和多后端支持:PyTorch不仅支持CPU,还支持NVIDIA和AMD的GPU。它也有一个生产就绪的部署解决方案——TorchServe。
- 丰富的预训练模型和工具箱:通过torchvision、torchaudio和torchtext等库,PyTorch提供了丰富的预训练模型和数据加载工具。
1. 安装与配置
1.1 如何安装PyTorch
在Windows、macOS和Linux上使用pip安装
- 仅CPU版本:
pip install torch torchvision
- 具有CUDA支持的版本:
首先,请确保已安装了与PyTorch兼容的CUDA版本。然后,运行以下命令:
pip install torch torchvision torchaudio -f https://download.pytorch.org/whl/cu102/torch_stable.html
这里cu102对应于您安装的CUDA版本。请根据实际情况修改。
在Linux和Windows上使用Conda安装
- 仅CPU版本:
conda install pytorch torchvision cpuonly -c pytorch
- 具有CUDA支持的版本:
conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch
这里cudatoolkit=10.2对应于您安装的CUDA版本。请根据实际情况修改。
1.2 验证安装
安装完成后,可以通过运行以下Python代码来验证安装是否成功:
import torch
print(torch.__version__)
如果这段代码成功运行并打印出PyTorch的版本号,那么您就成功地安装了PyTorch。
由于PyTorch经常更新,最好是查看其官方安装指南以获取最新的安装命令和兼容性信息。
2. 基础概念
2.1 张量(Tensors)
张量(Tensors)是PyTorch中用于存储和操作数据的基本单位。在数学上,张量是一个多维数据容器,类似于向量和矩阵的泛化。在PyTorch中,张量用于编码输入和输出数据、模型参数以及在模型训练过程中的中间数据。
2.1.1 张量的基本特性
- 数据类型(dtype): 张量可以包含各种数据类型,如整数(int),浮点数(float)等。
- 形状(shape): 张量的形状由其各维度(axis)的大小组成。比如一个3x4的矩阵有形状(3, 4)。
2.1.2 创建张量
在PyTorch中,有多种方式可以创建张量:
- 从Python列表创建
import torch
tensor_from_list = torch.tensor([1, 2, 3])
- 使用内置函数创建
zeros_tensor = torch.zeros(2, 3)
ones_tensor = torch.ones(2, 3)
rand_tensor = torch.rand(2, 3)
- 从已有的张量创建
new_tensor = torch.ones_like(rand_tensor)
- 从NumPy数组创建
import numpy as np
numpy_array = np.array([1, 2, 3])
tensor_from_numpy = torch.from_numpy(numpy_array)
2.1.3 张量操作
PyTorch提供了大量的张量操作,包括但不限于:
- 算术操作: 加、减、乘、除等
sum_tensor = torch.add(tensor_from_list, tensor_from_list)
- 形状操作: 改变形状,转置等
reshaped_tensor = tensor_from_list.view(3, 1)
- 索引、切片和连接: 选取和组合张量
sliced_tensor = tensor_from_list[:2]
- 数学函数: 对数、指数、平方根等
sqrt_tensor = torch.sqrt(tensor_from_list)
- 统计函数: 求和、平均、最大值、最小值等
max_value = torch.max(tensor_from_list)
2.2 自动微分(Autograd)
在训练模型时,通常需要计算函数(通常是损失函数)相对于模型参数的导数或梯度。PyTorch中的autograd包提供了自动微分功能,它能够自动地追踪对张量的所有操作并进行微分。
2.2.1 基本使用
创建一个张量并设置requires_grad=True以追踪它的计算历史:
import torch
# 创建一个张量并设置 requires_grad=True 用于追踪其计算历史
x = torch.ones(2, 2, requires_grad=True)
print(x)
进行张量操作:
y = x + 2
print(y)
由于y是通过一个操作创建的,它会有一个grad_fn属性:
print(y.grad_fn)
进行更多的操作:
z = y * y * 3
out = z.mean()
print(z, out)
2.2.2 计算梯度
通过调用.backward()方法,可以计算所有requires_grad=True的张量的梯度。这将反向传播梯度。
例如:
# 对于单个标量输出,无需为 backward() 指定任何参数
out.backward()
# 输出 d(out)/dx
print(x.grad)
2.2.3 停止追踪历史
在某些情况下,可能不希望追踪张量的计算历史。这可以通过.detach()方法实现,或者使用with torch.no_grad():代码块包裹不需要追踪的代码。
print(x.requires_grad)
print((x ** 2).requires_grad)
with torch.no_grad():
print((x ** 2).requires_grad)
2.2.4 自定义梯度函数
可以通过继承torch.autograd.Function并实现forward和backward方法来定义自己的自动微分运算。
2.2.5 其他注意事项
- 如果 requires_grad=True 但你又不想计算某些步骤的梯度,你可以用 .detach() 或者 with torch.no_grad(): 来停止自动微分。
- 逻辑操作(比如条件语句)在自动微分中是不可导的。因此,它们不会影响反向传播过程。
自动微分大大简化了梯度计算的过程,这在优化复杂模型时特别有用。这是PyTorch作为一个深度学习框架中最强大的特点之一。
3. 计算图和自动微分
3.1 计算图的概念
计算图是一种特殊的有向图,用于描述如何从输入数据和初值参数计算输出结果。这样的图有助于有效地组织如何进行数值计算,特别是对于梯度计算或反向传播。
3.1.1 节点和边
- 节点(Nodes): 计算图中的节点通常表示数据(通常是张量)或者运算(例如加法、乘法等)。
- 边(Edges): 边则表示数据之间的依赖关系。一条从节点A到节点B的边表示B的计算依赖于A的值。
3.1.2 前向传播和反向传播
- 前向传播(Forward Propagation): 在前向传播阶段,计算从输入节点开始,沿着边经过中间节点,最终到达输出节点。这个过程实际上是在执行图中定义的各种数学运算。
- 反向传播(Backpropagation): 在反向传播阶段,梯度(或导数)是从输出节点开始计算的,然后沿着与前向传播相反的路径回传到输入节点。这个过程用于更新模型参数以优化某个目标函数。
3.1.3 动态和静态计算图
- 静态计算图(Static Computational Graphs): 在这种模式下,计算图在运行前就被定义好,并且在整个训练过程中保持不变。TensorFlow的早期版本主要使用静态计算图。
- 动态计算图(Dynamic Computational Graphs): 在动态模式下,计算图是在运行时构建的。这意味着每一次前向传播都会创建一个新的计算图。PyTorch主要使用动态计算图,这使得它更灵活,更容易调试,但有时可能会牺牲一定的性能。
3.1.4 计算图和自动微分
在PyTorch中,当你执行一个操作时,PyTorch会动态地构建一个计算图。每个张量都是图中的一个节点,每个操作(函数)都是一个边。当调用 .backward() 方法时,PyTorch会从当前张量(通常是损失)开始,沿着这个图进行反向传播来计算梯度。
3.1.5 优点和局限性
- 优点: 计算图提供了一种高效的方式来组织和执行计算,尤其是在涉及到梯度计算和优化时。
- 局限性: 构建和存储计算图会占用额外的内存和计算资源,尤其是对于非常复杂的模型和大规模的数据。
3.2 如何使用Autograd
Autograd 是 PyTorch 提供的自动微分库,用于自动计算神经网络(或其他可微函数)的梯度。它是训练神经网络时用于反向传播(backpropagation)的核心组件。下面是如何使用 Autograd 的一些基本示例和解释。
3.2.1 张量与梯度追踪
首先,创建一个张量并设置 requires_grad=True 以追踪其计算历史。
import torch
# 创建一个张量并追踪其计算历史
x = torch.ones(2, 2, requires_grad=True)
print(x)
3.2.2 进行张量操作
执行一些张量操作。这些操作会被 Autograd 动态地记录下来,用于构建计算图。
y = x + 2
z = y * y * 3
out = z.mean()
print(y)
print(z)
print(out)
3.2.3 反向传播
调用 .backward() 来进行反向传播。这会计算 out(我们的输出张量)相对于 requires_grad=True 的所有输入张量(在这个例子中只有 x)的梯度。
out.backward()
查看梯度 d(out)/dx。
print(x.grad)
3.2.4 停止梯度追踪
有几种方式可以停止梯度追踪:
- 使用 .detach(): 创建一个内容相同但不需要梯度的新张量。
x_detached = x.detach()
- 使用 torch.no_grad(): 在该上下文管理器中执行的所有操作都不会追踪梯度。
with torch.no_grad():
y = x + 2
3.2.5 计算更复杂的梯度
在默认情况下,梯度会累加到 .grad 属性中。这对于循环或递归网络是非常有用的。如果不想累加梯度,你可以在每次迭代前手动将其归零。
x.grad.zero_()
3.3 自定义梯度
在 PyTorch 中,如果你想实现一个不是库中内建的梯度计算过程,或者你想对现有操作的梯度计算进行修改,你可以通过定义自己的 Autograd 函数来实现。这通常涉及到继承 torch.autograd.Function 类,并实现 forward 和 backward 方法。
3.3.1 例子:自定义 ReLU 函数
以下是一个自定义的 ReLU(Rectified Linear Unit)激活函数的例子。
import torch
class MyReLU(torch.autograd.Function):
@staticmethod
def forward(ctx, input_tensor):
# 保存用于后续梯度计算的信息
ctx.save_for_backward(input_tensor)
# 实现 ReLU 操作
output_tensor = input_tensor.clamp(min=0)
return output_tensor
@staticmethod
def backward(ctx, grad_output):
# 获得 forward 传播阶段保存的信息
input_tensor, = ctx.saved_tensors
# 计算 ReLU 的梯度
grad_input = grad_output.clone()
grad_input[input_tensor < 0] = 0
return grad_input
在这个例子中,forward 方法实现了 ReLU 的正向传播,并通过 ctx.save_for_backward 方法保存了输入张量,以便在反向传播中使用。
backward 方法负责计算梯度。它接受一个参数 grad_output,即损失函数相对于正向传播输出的梯度,然后返回损失函数相对于正向传播输入的梯度。
3.3.2 使用自定义 Autograd 函数
一旦你定义了自己的 Autograd 函数,你可以像使用内建的 PyTorch 操作一样使用它。
# 使用自定义的 ReLU
relu = MyReLU.apply
# 创建一个张量并应用自定义的 ReLU
x = torch.randn(5, 5, requires_grad=True)
y = relu(x)
# 计算梯度
z = y.sum()
z.backward()
# 查看梯度
print(x.grad)
这种方式可以用于更复杂的操作和梯度计算,甚至可以用于实现自己的优化算法。
注意,自定义 Autograd 函数的使用通常仅推荐给高级用户,因为这需要对反向传播和梯度计算有深入的理解。对于大多数应用场景,PyTorch 的内建操作和自动微分功能已经足够使用。
4. 神经网络基础
4.1 模块(nn.Module)
在 PyTorch 中,nn.Module 是神经网络模块的基类,它是一个非常重要的概念,用于构建和管理神经网络。
4.1.1 基本结构
一个自定义的网络层或者整个神经网络都应当继承 nn.Module 类,并实现其方法。最常见的方法是 _ init _(构造函数)和 forward。
- _ init_ 方法: 用于初始化网络层和参数。
- forward 方法: 定义了前向传播的计算过程。
4.1.2 简单示例
下面是一个简单的线性回归模型,它只包含一个线性层。
import torch
import torch.nn as nn
class LinearRegressionModel(nn.Module):
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(input_dim, output_dim)
def forward(self, x):
out = self.linear(x)
return out
4.1.3 参数管理
nn.Module 自动跟踪你定义的可训练参数。例如,nn.Linear 层的权重和偏置都是可训练参数。你可以使用 parameters() 或者 named_parameters() 方法来获取模型中的所有参数。
model = LinearRegressionModel(1, 1)
# 打印模型的参数
for name, param in model.named_parameters():
print(name, param.data)
4.1.4 嵌套模块
nn.Module 可以包含其他 nn.Module,允许你构建嵌套结构。这是实现更复杂网络架构(如 ResNet、BERT 等)的关键。
class TwoLayerNN(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(TwoLayerNN, self).__init__()
self.layer1 = nn.Linear(input_dim, hidden_dim)
self.layer2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = torch.relu(self.layer1(x))
x = self.layer2(x)
return x
4.1.5 损失函数与优化器
尽管 nn.Module 主要用于定义网络结构和前向传播,但 PyTorch 也提供了与之配套的损失函数(如 nn.CrossEntropyLoss、nn.MSELoss 等)和优化器(如 torch.optim.SGD, torch.optim.Adam 等)。
4.1.6 GPU 支持
通过调用 .to(device) 方法,你可以轻松地将所有模型参数和缓冲区移动到 GPU。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
4.2 激活函数
激活函数在神经网络中扮演着非常重要的角色,它们引入了非线性特性,使得神经网络能够逼近更复杂的函数。如果没有激活函数,即使多层神经网络也只能表示线性映射。下面是一些常用的激活函数和它们在 PyTorch 中的使用方式:
4.2.1 ReLU(Rectified Linear Unit)
ReLU 是最常用的激活函数之一。它在正数范围内是线性的,而在负数范围内输出为零。
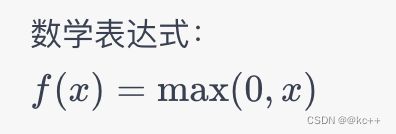
在 PyTorch 中的使用:
import torch.nn as nn
relu = nn.ReLU()
或者在模型定义中:
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(x)
return x
4.2.2 Sigmoid
Sigmoid 函数将任何输入都压缩到 0 和 1 之间。

在 PyTorch 中的使用:
sigmoid = nn.Sigmoid()
4.2.3 Tanh(Hyperbolic Tangent)
Tanh 函数将任何输入都压缩到 -1 和 1 之间。

在 PyTorch 中的使用:
tanh = nn.Tanh()
4.2.4 Leaky ReLU
Leaky ReLU 是 ReLU 的一个变种,它允许负数有一个小的正梯度。

在 PyTorch 中的使用:
leaky_relu = nn.LeakyReLU(0.01)
4.2.5 Softmax
Softmax 常用于分类问题的输出层。它将输入转换为概率分布。

在 PyTorch 中的使用:
softmax = nn.Softmax(dim=1) # dim 指定了哪一个维度将被归一化
4.2.6 其他激活函数
还有很多其他的激活函数,如 Swish、Mish、SELU 等,有些已经被包含在了 PyTorch 的 torch.nn 库中,有些则需要自定义实现。
4.2.7 使用激活函数
通常在定义网络结构时,激活函数作为一个层被添加到 nn.Sequential 容器中,或在 forward 方法中被调用。
import torch.nn as nn
# 使用 nn.Sequential
model = nn.Sequential(
nn.Linear(10, 20),
nn.ReLU(),
nn.Linear(20, 1)
)
# 在 forward 方法中
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.layer1 = nn.Linear(10, 20)
self.layer2 = nn.Linear(20, 1)
def forward(self, x):
x = nn.functional.relu(self.layer1(x))
x = self.layer2(x)
return x
4.3 nn.Sequential
nn.Sequential 是 PyTorch 中的一个容器模块,用于简单地堆叠不同的层,以创建一个更大的模型。使用 nn.Sequential,你可以快速地定义和部署模型,而不需要定义一个完整的类。它特别适用于相对简单的前向传播模型。
4.3.1 基本用法
下面是一个使用 nn.Sequential 构建的简单多层感知机(MLP)模型的例子:
import torch
import torch.nn as nn
model = nn.Sequential(
nn.Linear(64, 128), # 输入层到隐藏层的线性变换,输入维度64,输出维度128
nn.ReLU(), # 隐藏层使用的激活函数
nn.Linear(128, 10) # 隐藏层到输出层的线性变换,输入维度128,输出维度10
)
# 随机生成一个输入张量,维度为 [batch_size, input_features]
input_tensor = torch.randn(16, 64)
# 使用模型进行前向传播
output_tensor = model(input_tensor)
在这个例子中,模型有两个线性层和一个 ReLU 激活层。数据将按照这些层在 nn.Sequential 中定义的顺序进行传播。
4.3.2 嵌套使用
也可以在 nn.Sequential 中嵌套其它 nn.Sequential 模块或自定义模块,使结构更加清晰:
block1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=3),
nn.ReLU(),
nn.MaxPool2d(2)
)
block2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=3),
nn.ReLU(),
nn.MaxPool2d(2)
)
model = nn.Sequential(
block1,
block2,
nn.Flatten(),
nn.Linear(32 * 6 * 6, 10)
)
4.3.3 使用 OrderedDict
还可以使用 OrderedDict 来给每一层命名:
from collections import OrderedDict
model = nn.Sequential(OrderedDict([
('first_linear', nn.Linear(64, 128)),
('first_activation', nn.ReLU()),
('second_linear', nn.Linear(128, 10))
]))
这样你可以通过名字来访问特定的层:
print(model.first_linear)
4.3.4 注意事项
尽管 nn.Sequential 非常方便,但它也有局限性。例如,它不能处理具有多个输入或输出的层,或者层与层之间存在复杂的连接关系(比如残差连接)。对于这些更复杂的情况,你通常需要自定义一个继承自 nn.Module 的模型类。
4.4 损失函数
损失函数(或目标函数、成本函数)是用于衡量模型预测与真实数据间差异的一种方式。优化模型实际上就是通过改变模型参数来最小化这个损失函数。
PyTorch 提供了多种内建的损失函数,这些损失函数一般都在 torch.nn 模块下。以下是一些常用的损失函数:
4.4.1 均方误差损失(Mean Squared Error Loss, MSE)
用于回归问题。
import torch
import torch.nn as nn
criterion = nn.MSELoss()
prediction = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
loss = criterion(prediction, target)
4.4.2 交叉熵损失(Cross Entropy Loss)
用于分类问题。
criterion = nn.CrossEntropyLoss()
prediction = torch.randn(3, 5, requires_grad=True)
target = torch.empty(3, dtype=torch.long).random_(5)
loss = criterion(prediction, target)
4.4.3 二元交叉熵损失(Binary Cross Entropy Loss)
用于二分类问题。
criterion = nn.BCELoss()
prediction = torch.randn(3, requires_grad=True)
target = torch.empty(3).random_(2)
loss = criterion(prediction, target)
4.4.4 Hinge Loss
用于支持向量机(SVM)相关问题。
criterion = nn.HingeEmbeddingLoss()
prediction = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
loss = criterion(prediction, target)
4.4.5 自定义损失函数
也可以很容易地定义自己的损失函数。自定义损失函数需要继承 nn.Module 类,并实现 forward 方法。
class MyCustomLoss(nn.Module):
def __init__(self):
super(MyCustomLoss, self).__init__()
def forward(self, prediction, target):
loss = (prediction - target).abs().mean()
return loss
criterion = MyCustomLoss()
prediction = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5)
loss = criterion(prediction, target)
4.4.6 使用损失函数
一旦选定了合适的损失函数,可以将其与优化器(如 SGD、Adam 等)结合使用,通过反向传播(Backpropagation)来更新模型参数。
import torch.optim as optim
# 创建模型和数据
model = nn.Linear(5, 1)
prediction = model(torch.randn(3, 5))
target = torch.randn(3, 1)
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 计算损失
loss = criterion(prediction, target)
# 反向传播和参数更新
optimizer.zero_grad() # 清除之前梯度
loss.backward() # 反向传播
optimizer.step() # 更新参数
5. 优化算法
5.1 梯度下降(Gradient Descent)
梯度下降(Gradient Descent)是一种优化算法,用于最小化函数(通常是损失函数)。在机器学习和深度学习中,梯度下降是用于更新模型参数以减小损失函数值的主要方法。
5.1.1 基本原理

5.1.2 变体
- 批量梯度下降(Batch Gradient Descent): 在每次更新中使用所有的数据。这种方式适用于小数据集,但不适合大数据集。
- 随机梯度下降(Stochastic Gradient Descent,SGD): 在每次更新中随机选择一个样本来进行梯度计算和更新。这种方法适用于大数据集。
- 小批量梯度下降(Mini-batch Gradient Descent): 介于上面两者之间,每次更新使用一个小批量的样本。
5.1.3 在 PyTorch 中使用梯度下降
在 PyTorch 中,使用梯度下降通常非常简单。PyTorch 的 torch.optim 包提供了多种优化算法,其中包括各种梯度下降的变体。
下面是一个简单的例子,演示如何使用 SGD 优化器:
import torch
import torch.nn as nn
import torch.optim as optim
# 创建一个简单的线性模型
model = nn.Linear(2, 1)
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 随机生成一些输入数据和目标数据
input_data = torch.randn(10, 2)
target_data = 3 * input_data[:, 0] + 2 * input_data[:, 1]
# 前向传播
output = model(input_data)
# 计算损失
loss = criterion(output, target_data)
# 反向传播
optimizer.zero_grad()
loss.backward()
# 更新参数
optimizer.step()
5.1.4 注意事项
- 学习率(Learning Rate): 选择合适的学习率非常重要。太小的学习率会导致收敛速度非常慢,而太大的学习率可能会导致模型在最优解附近震荡或者发散。
- 局部最小值(Local Minima): 对于非凸函数,梯度下降可能会陷入局部最小值。在实践中,对于高维数据,这通常不是一个大问题。
- 动量(Momentum): 为了加速训练和避免陷入局部最小值,可以使用动量。PyTorch 的 torch.optim.SGD 中有一个 momentum 参数可供使用。
5.2 其他优化算法(如Adam, RMSProp等)
除了传统的梯度下降(Gradient Descent)和其变种(如随机梯度下降,Stochastic Gradient Descent或SGD)外,还有多种其他优化算法被广泛应用于机器学习和深度学习领域。这些算法通常旨在解决梯度下降的某些限制,例如选择合适的学习率、陷入局部最优解等问题。
5.2.1 Adam(Adaptive Moment Estimation)
Adam 是一种自适应学习率优化算法,集成了 AdaGrad 和 RMSProp 的思想。Adam 同时考虑了一阶动量和二阶动量,因此能在各种条件下都有较好的表现。
import torch.optim as optim
optimizer = optim.Adam(model.parameters(), lr=0.001)
5.2.2 RMSProp(Root Mean Square Propagation)
RMSProp 是一种自适应学习率优化算法,它调整每个参数的学习率,适用于非平稳目标函数。
optimizer = optim.RMSprop(model.parameters(), lr=0.01)
5.2.3 Adagrad
Adagrad 是一种自适应学习率优化算法,它为每个参数分配一个独立的学习率。虽然它在处理稀疏数据时表现得很好,但可能不适用于训练深度学习模型,因为学习率可能过早地变得非常小。
optimizer = optim.Adagrad(model.parameters(), lr=0.01)
5.2.4 Adadelta
Adadelta 是 Adagrad 的一个扩展,旨在减缓 Adagrad 学习率下降的速度。
optimizer = optim.Adadelta(model.parameters(), lr=1.0)
5.2.5 FTRL(Follow The Regularized Leader)
FTRL 是一种专为大规模在线学习场景设计的优化算法,常用于广告点击率预测等大规模稀疏数据问题。
optimizer = optim.FTRL(model.parameters(), lr=0.1, l1_penalty=1e-3, l2_penalty=1e-3)
5.2.6 优化器选择注意事项
- 学习率调度: 不同的优化算法可能需要不同的学习率或学习率调度策略。PyTorch 提供了 torch.optim.lr_scheduler 来方便地调整学习率。
- 超参数调优: 除了学习率,很多优化算法还有其他超参数(如 Adam 的 beta1、beta2,RMSProp 的 alpha 等)。
6. 数据加载和预处理
在 PyTorch 中,Dataset 和 DataLoader 类提供了一个高效、灵活的方式来加载和预处理数据。它们使得数据的批量处理、打乱和并行加载变得简单。
6.1 使用DataSet
要创建自定义 Dataset,你需要继承 torch.utils.data.Dataset 类并实现 _ len _ 和 _ getitem _ 方法。
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, data, labels):
self.data = data
self.labels = labels
def __len__(self):
return len(self.data)
def __getitem__(self, index):
return self.data[index], self.labels[index]
这样,就可以使用你自己的数据来初始化这个 Dataset。
6.2 使用DataLoader
DataLoader 类用于创建一个数据加载器,它可以接受任何实现了 _ len_ 和 _getitem _ 方法的数据集。DataLoader 提供了多种实用功能,如自动批量处理、打乱数据和并行数据加载。
from torch.utils.data import DataLoader
# 创建自定义数据集
my_dataset = MyDataset(data, labels)
# 创建 DataLoader 实例
data_loader = DataLoader(my_dataset, batch_size=4, shuffle=True)
# 使用 DataLoader
for batch_data, batch_labels in data_loader:
# 进行模型训练或评估
6.3 自定义数据集
创建自定义数据集在 PyTorch 中是相对简单的,只需要继承 torch.utils.data.Dataset 类,并实现 _ len _ 和 _ getitem _ 方法。下面是一个创建自定义数据集的基础示例:
6.3.1 创建自定义 Dataset
from torch.utils.data import Dataset
import torch
class CustomDataset(Dataset):
def __init__(self, data_array, labels_array):
self.data = data_array
self.labels = labels_array
def __len__(self):
return len(self.data)
def __getitem__(self, index):
sample_data = self.data[index]
sample_label = self.labels[index]
return sample_data, sample_label
在这个例子中,_ init _ 方法用于初始化数据集,将数据和标签作为输入参数。_ len _ 方法返回数据集中的样本数,而 _ getitem _ 方法返回给定索引处的数据和标签。
6.3.2 使用自定义 Dataset
创建了自定义 Dataset 后,你可以非常容易地将其与 PyTorch 的 DataLoader 配合使用。
from torch.utils.data import DataLoader
# 初始化自定义数据集
data_array = torch.randn(100, 3, 32, 32) # 100个 3x32x32 的随机张量
labels_array = torch.randint(0, 2, (100,)) # 100个随机标签 (0或1)
custom_dataset = CustomDataset(data_array, labels_array)
# 使用 DataLoader
data_loader = DataLoader(custom_dataset, batch_size=10, shuffle=True)
for data, label in data_loader:
# 这里进行你的训练/验证代码
pass
6.3.3 数据预处理
如果需要在数据集上执行某种形式的预处理或数据增强,可以在 _ getitem _ 方法内部实现它,或者使用 torchvision.transforms。
from torchvision import transforms
class CustomDatasetWithTransforms(Dataset):
def __init__(self, data_array, labels_array):
self.data = data_array
self.labels = labels_array
self.transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
def __len__(self):
return len(self.data)
def __getitem__(self, index):
sample_data = self.data[index]
sample_label = self.labels[index]
if self.transform:
sample_data = self.transform(sample_data)
return sample_data, sample_label
这样,就创建了一个具有数据预处理功能的自定义数据集。使用自定义数据集和数据加载器(DataLoader)是 PyTorch 中数据处理的推荐方法,因为它们提供了一个灵活且易于使用的数据处理框架。
7. 实战:构建一个简单的神经网络
7.1 数据准备
首先,我们会使用 PyTorch 的内置数据集,例如 MNIST,作为我们的数据源。
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_dataset = datasets.MNIST('./data', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
7.2 构建模型
接下来,我们构建一个简单的全连接网络(也称为多层感知器,MLP)。
import torch.nn as nn
import torch.nn.functional as F
class SimpleMLP(nn.Module):
def __init__(self):
super(SimpleMLP, self).__init__()
self.fc1 = nn.Linear(28*28, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 28*28)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return F.log_softmax(x, dim=1)
7.3 训练模型
model = SimpleMLP()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()
for epoch in range(5):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Epoch: {} [{}/{}]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset), loss.item()))
7.4 评估模型
用测试集来评估模型。
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = model(data)
test_loss += criterion(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
8. 调试和可视化
8.1 使用TensorBoard
TensorBoard 是一个可视化工具,它可用于展示训练过程中的各种参数和指标,从而使模型开发更加直观。PyTorch 提供了与 TensorBoard 的原生集成。
8.1.1 安装 TensorBoard
首先,你需要安装 TensorBoard。如果你还没有安装,可以使用以下命令来安装:
pip install tensorboard
8.1.2 导入 TensorBoard
导入 PyTorch 的 SummaryWriter 类,这是与 TensorBoard 交互的主要接口。
from torch.utils.tensorboard import SummaryWriter
8.1.3 初始化 SummaryWriter
创建一个 SummaryWriter 对象。
writer = SummaryWriter('runs/experiment_1')
该命令会创建一个名为 runs/experiment_1 的目录,其中将包含所有的日志文件。
8.1.4 记录标量、图像、直方图等
可以使用 SummaryWriter 的各种方法来记录你感兴趣的信息。
- 标量(例如,损失或准确度):
for epoch in range(num_epochs):
# ... 训练过程 ...
writer.add_scalar('Training Loss', loss, epoch)
- 图像:
# 将一批图像添加到 TensorBoard
images, labels = next(iter(train_loader))
writer.add_images('Training Images', images)
- 直方图(例如,模型权重分布):
for name, param in model.named_parameters():
writer.add_histogram(name, param, epoch)
- 也可以添加模型图:
writer.add_graph(model, images)
8.1.5 启动 TensorBoard
在命令行中,使用以下命令启动 TensorBoard:
tensorboard --logdir=runs
然后,打开浏览器并导航到 http://localhost:6006/。
8.1.6 关闭 SummaryWriter
完成所有操作后,关闭 SummaryWriter。
writer.close()
这样,就可以在 TensorBoard 中看到各种可视化结果,这有助于模型的调试和优化。TensorBoard 还有许多其他高级功能,比如 embeddings 可视化,PR curves 等。
8.2 Debugging技巧
8.2.1 打印形状和类型
当你遇到与张量操作有关的问题时,首先检查张量的形状和数据类型。
print("Tensor shape:", tensor.size())
print("Tensor type:", tensor.dtype)
8.2.2 使用断言
使用断言来确保代码逻辑符合你的预期。
assert tensor.size(0) == 64, "Expected batch size of 64"
8.2.3 打印梯度信息
在反向传播过程中,查看各层梯度的值和形状可以提供很多有用的信息。
def print_grad(grad):
print(grad)
tensor.register_hook(print_grad)
8.2.4 使用 .item() 和 .detach()
在调试过程中,你可能需要将单一值从 PyTorch 张量转化为 Python 数值。使用 .item() 可以达到这一目的。注意,这仅适用于只含有单一元素的张量。
single_value = tensor.item()
如果你想将一个有多个元素的张量从计算图中分离出来,并将其转化为 NumPy 数组,可以使用 .detach()。
array = tensor.detach().cpu().numpy()
8.2.5 使用 PyTorch 的 torch.set_printoptions
这个函数能够让你更灵活地控制张量的打印方式。
torch.set_printoptions(precision=2, sci_mode=False)
8.2.6. PyTorch 内置的 Debugging 工具
- torch.autograd.set_detect_anomaly(True): 这将帮助你找出哪里产生了 NaN 或无穷值。
8.2.7 使用标准的 Python Debugging 工具
也可以使用 Python 的标准库 pdb 或者更高级的工具,如 ipdb,来进行逐行的代码跟踪。
在你想要暂停的代码行前加入:
import pdb; pdb.set_trace()
然后,你就能在终端中执行一些检查。
8.2.8 Logging
除了直接在代码中插入 print 语句或断点之外,还可以使用 Python 的 logging 库来记录重要的运行时信息。
import logging
logging.basicConfig(level=logging.INFO)
logging.info("Loss: %s, Accuracy: %s", loss, accuracy)
9. 模型保存和加载
9.1 保存模型参数
在 PyTorch 中保存和加载模型有多种方式,但主要分为两类:
- 保存整个模型(包括结构和参数)
- 仅保存模型参数
9.1.1 保存整个模型
这种方式会保存模型的结构以及参数,但需要注意的是这种方式保存的模型会比较大,并且在加载模型时还需要有模型类的定义。
保存:
torch.save(model, 'model.pth')
加载:
model = torch.load('model.pth')
9.1.2 仅保存模型参数
这种方式只保存模型的参数,不保存模型的结构。这样生成的文件会小很多,并且在加载模型时只需要有与之结构相匹配的模型。
保存:
torch.save(model.state_dict(), 'params.pth')
加载:
model = TheModelClass(*args, **kwargs) # 先实例化模型类,*args, **kwargs是初始化需要的参数
model.load_state_dict(torch.load('params.pth'))
9.1.3 注意事项
- 设备兼容性: 在加载模型时需要注意模型和加载模型的设备(CPU 或 GPU)需要匹配,或者你需要指定正确的设备。
# 如果保存时模型在 GPU,加载到 CPU
model.load_state_dict(torch.load('params.pth', map_location=torch.device('cpu')))
# 如果保存时模型在 CPU,加载到 GPU
model.load_state_dict(torch.load('params.pth'))
model.to('cuda')
- 版本兼容性:在不同版本的 PyTorch 间保存和加载模型可能会有兼容性问题。
- 在 nn.DataParallel 中保存模型:如果你的模型是在多个 GPU 上训练的,需要小心地保存 state_dict。
# 推荐这种方式
torch.save(model.module.state_dict(), 'params.pth')
9.2 加载模型参数
加载 PyTorch 模型的参数通常与保存模型的方式有关。通常有两种主要方法来加载模型参数:
- 从完整模型加载: 这种方法是在保存整个模型(包括结构和参数)后进行的。在这种情况下,你可以使用 torch.load 方法直接加载模型。此方法要求保存模型时的模型类定义可用。
model = torch.load('model.pth')
- 从保存的参数加载: 这是更常用(也更推荐)的方法。首先,你需要实例化一个与保存模型结构相同的模型,然后使用 load_state_dict 方法加载参数。
model = TheModelClass(*args, **kwargs) # 初始化模型实例
model.load_state_dict(torch.load('params.pth'))
9.2.1 注意以下几点:
- 设备: 如果模型在 GPU 上训练并保存,但你希望在 CPU 上加载它,或者反之,则需要在 torch.load 方法中指定 map_location 参数。
- 从 GPU 保存,加载到 CPU:
model.load_state_dict(torch.load('params.pth', map_location=torch.device('cpu')))
- 从 CPU 保存,加载到 GPU:
model.load_state_dict(torch.load('params.pth'))
model.to('cuda')
- 模型状态: 务必确保模型是在恰当的状态下(如训练或评估状态)。
model.eval() # 或者 model.train()
- 多 GPU 训练: 如果模型参数是使用 nn.DataParallel 保存的,那么在单个 GPU 或 CPU 上加载参数时,需要特别处理。
# 在加载模型定义后
model = nn.DataParallel(model) # 包装为 DataParallel 类型
model.load_state_dict(torch.load('params.pth'))
或者,如果你在多 GPU 上训练并保存了模型,但希望在单个设备上加载:
# 保存时使用 model.module.state_dict()
model.load_state_dict(torch.load('params.pth'))
10. 高级主题
在 PyTorch 中使用 GPU 进行模型训练和推理通常能大幅加速计算。以下是一些如何使用 GPU 的基础步骤:
10.1 使用GPU加速
10.1.1 检查 GPU 是否可用
首先,你需要检查是否有可用的 CUDA 支持的 GPU。
print(torch.cuda.is_available())
10.1.2 指定设备
在开始之前,你需要指定你想使用的设备。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
这里,“cuda:0” 表示使用第一个 GPU。如果有多个 GPU,你可以通过更改索引(例如 “cuda:1”,“cuda:2” 等)来选择其他 GPU。
10.1.3 将模型移动到 GPU
接下来,你可以使用 .to() 方法将模型的所有参数和缓冲区移动到 GPU。
model.to(device)
10.1.4 将数据移动到 GPU
在进行前向和后向传播之前,你需要确保输入数据和标签也在 GPU 上。
inputs, labels = inputs.to(device), labels.to(device)
10.1.5 多 GPU 使用(可选)
如果你有多个 GPU,可以使用 nn.DataParallel 来进行数据并行处理。
model = nn.DataParallel(model)
这会让模型在所有可用的 GPU 上进行训练,自动分配数据并收集结果。
10.2 分布式训练
分布式训练是一种使用多个计算节点来加速深度学习模型训练和扩大模型规模的方法。在 PyTorch 中,分布式训练通常通过 torch.distributed API 来实现。
10.2.1 分布式训练的方式
- 数据并行: 这是最简单的分布式训练形式,通常用于单个机器上的多个 GPU。每个 GPU 负责模型的一个部分,并且数据分割成多个小批次(mini-batch)分布到各个 GPU 上。
- 模型并行: 这通常用于那些无法在单个 GPU 上放下的大型模型。在这种情况下,模型的不同部分会被分配到不同的 GPU 上。
- 数据并行 + 模型并行: 这是上述两种方式的组合。
10.2.2 初始化分布式环境
在开始分布式训练之前,必须初始化分布式环境。
import torch.distributed as dist
dist.init_process_group(backend='nccl', init_method='tcp://localhost:23456', rank=0, world_size=1)
10.2.3 分布式数据并行
PyTorch 提供了 torch.nn.DataParallel 和 torch.nn.parallel.DistributedDataParallel 类来简化数据并行的实现。
使用 DistributedDataParallel
from torch.nn.parallel import DistributedDataParallel
model = model.to(device) # 先把模型移到设备上
model = DistributedDataParallel(model)
10.2.4 损失和优化器
损失和优化器的实现与非分布式训练基本相同,但需要注意各个节点上的梯度累计。
10.2.5 加载和保存模型
在分布式环境中,通常只需要从一个进程中保存或加载模型。
10.2.6 示例代码
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel
# 初始化分布式环境
dist.init_process_group(backend='nccl')
# 设备设置
device = torch.device("cuda")
# 创建模型和数据
model = YourModel()
model = model.to(device)
model = DistributedDataParallel(model)
data_loader = YourDataloader()
# 损失和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
# 训练循环
for epoch in range(epochs):
for batch in data_loader:
inputs, targets = batch
inputs = inputs.to(device)
targets = targets.to(device)
# 前向传播
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, targets)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# ... 可能的评估、保存模型等
10.3 量化
模型量化是一种减小模型大小和提高推理速度的技术,通常以牺牲一定量的模型准确性为代价。PyTorch 提供了一整套的量化工具,支持多种量化方法。
10.3.1 预备步骤
确保你的 PyTorch 安装包括了量化所需的依赖项。量化功能在 PyTorch 1.3.0 以上版本可用。
10.3.2 准备模型
通常,量化会在一个已经训练好的模型上进行。你也可以在训练阶段包括量化,这被称为量化感知训练。
10.3.3 选择量化配置
- 静态量化: 只量化模型权重,不需要访问数据。
- 动态量化: 模型权重和激活都是动态量化的。
- 量化感知训练(QAT): 在训练阶段就进行量化。
10.3.4 静态量化示例
import torch
import torch.quantization
# 准备模型和数据
model = torch.load('my_model.pth')
model.eval()
# 指定量化配置并量化模型
quantized_model = torch.quantization.quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.qint8
)
# 保存量化后的模型
torch.save(quantized_model.state_dict(), 'my_quantized_model.pth')
10.3.5 动态量化示例
import torch
import torch.quantization
# 准备模型和数据
model = torch.load('my_model.pth')
model.eval()
# 量化模型
quantized_model = torch.quantization.quantize_dynamic(model)
# 保存量化后的模型
torch.save(quantized_model.state_dict(), 'my_quantized_model.pth')
10.3.6 量化感知训练示例
量化感知训练通常涉及对模型权重进行伪量化,同时还会对输入进行量化。这样可以让模型在训练阶段就适应量化引入的误差。
import torch
import torch.quantization
# 准备模型
model = YourModel()
model.qconfig = torch.quantization.get_default_qconfig('fbgemm')
torch.quantization.prepare(model, inplace=True)
# 模型训练
# ...
# 转换为量化模型
torch.quantization.convert(model, inplace=True)
10.3.7 优缺点
- 优点: 模型大小减小,推理速度加快。
- 缺点: 可能会损失一定的模型准确性。
11. PyTorch生态圈
11.1 torchvision
torchvision 是一个与 PyTorch 配合使用的库,用于处理计算机视觉任务。它提供了以下几个主要的功能:
11.1.1 预训练模型
torchvision 包含了许多预训练的模型,例如 VGG, ResNet, MobileNet 等。这些模型可以用于迁移学习或直接用于推理。
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True)
11.1.2 数据集
torchvision 包括常用的计算机视觉数据集,例如 CIFAR-10, MNIST, ImageNet 等。
from torchvision.datasets import MNIST
train_dataset = MNIST(root='./data', train=True, transform=None, download=True)
11.1.3 数据转换
提供了多种用于图像处理和增强的转换方法。
from torchvision import transforms
transform = transforms.Compose([
transforms.RandomSizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
11.1.4 工具函数
torchvision 还包括用于计算机视觉的一些实用函数,如非极大值抑制(NMS)。
11.1.5 示例
以下是一个使用 torchvision 来加载预训练模型并进行图像分类的简单示例:
import torch
import torchvision.models as models
from torchvision import transforms
from PIL import Image
# 加载预训练模型
model = models.resnet18(pretrained=True)
model.eval()
# 图像预处理
input_image = Image.open("your_image.jpg")
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0)
# 推理
with torch.no_grad():
output = model(input_batch)
# 获取预测结果
_, predicted_idx = torch.max(output, 1)
print(predicted_idx)
11.2 torchaudio
torchaudio 是一个与 PyTorch 协同工作的库,专门用于处理音频数据和音频信号处理任务。torchaudio 提供了一系列工具,包括用于音频数据加载、转换和特征提取的方法,以及一些预训练的音频处理模型。
11.2.1 主要功能
数据加载和保存
torchaudio 支持多种音频格式的读取和写入,包括但不限于 WAV, MP3, FLAC 等。
import torchaudio
# 读取音频文件
waveform, sample_rate = torchaudio.load('audio_file.wav')
# 保存音频文件
torchaudio.save('output_audio_file.wav', waveform, sample_rate)
音频变换
torchaudio 提供了许多用于音频处理的转换方法,如梅尔频率倒谱系数(MFCC)、声谱图创建、重采样等。
import torchaudio.transforms as T
# 创建声谱图
spectrogram = T.Spectrogram()(waveform)
# 计算 MFCC
mfcc = T.MFCC()(waveform)
预训练模型
虽然 torchaudio 不像 torchvision 那样拥有大量预训练模型,但它确实包括一些特定任务的预训练模型,如波形到波形的生成模型。
数据集
torchaudio 也包括一些用于训练和测试音频模型的标准数据集。
from torchaudio.datasets import YESNO
yesno_data = YESNO('./', download=True)
11.2.2 示例
下面是一个使用 torchaudio 加载音频文件并计算其 MFCC 的简单示例:
import torchaudio
import torchaudio.transforms as T
# 加载音频文件
waveform, sample_rate = torchaudio.load('audio_file.wav')
# 计算 MFCC
mfcc_transform = T.MFCC(
sample_rate=sample_rate,
n_mfcc=12,
melkwargs={
'n_fft': 400,
'hop_length': 160,
'center': False,
'pad_mode': 'reflect',
'power': 2.0,
'norm': 'slaney',
'onesided': True,
}
)
mfcc = mfcc_transform(waveform)
print("MFCC Shape:", mfcc.shape)
11.2.3 使用场景
torchaudio 主要用于以下几个方面:
- 语音识别
- 音乐生成和分类
- 音频事件检测
- 音频信号增强
11.3 torchtext
torchtext 是一个与 PyTorch 配合使用的文本处理库。它为自然语言处理(NLP)任务提供了一组工具,以便于数据加载、文本预处理、词汇表创建等。torchtext 设计用于方便地处理各种文本数据集,并与 PyTorch 中的其他模块(如 nn.Module)无缝地集成。
11.3.1 主要功能
数据加载
torchtext 支持从各种来源(如CSV文件、JSON文件、文本文件等)加载数据。
from torchtext.data import TabularDataset
train_data, test_data = TabularDataset.splits(
path='./data', train='train.csv', test='test.csv', format='csv',
fields=[('text', TEXT), ('label', LABEL)]
)
文本预处理
它也包括一系列文本预处理工具,如分词、词干提取、数字化等。
from torchtext.data import Field
TEXT = Field(tokenize=custom_tokenize, lower=True)
词汇表管理
torchtext 允许您轻松地创建和管理词汇表,并与 PyTorch 张量无缝集成。
TEXT.build_vocab(train_data, vectors="glove.6B.100d")
批处理与数据迭代
torchtext 提供了灵活的批处理和数据迭代器选项。
from torchtext.data import Iterator, BucketIterator
train_iter, test_iter = BucketIterator.splits(
(train_data, test_data), batch_size=32, sort_key=lambda x: len(x.text)
)
预训练词向量
torchtext 也支持多种预训练的词向量,如 GloVe 和 FastText。
11.3.2 示例
以下是一个使用 torchtext 进行数据预处理的简单示例:
from torchtext.data import Field, TabularDataset, BucketIterator
# 定义字段
TEXT = Field(sequential=True, tokenize='spacy', lower=True)
LABEL = Field(sequential=False, use_vocab=False)
# 创建数据集
fields = {'text': ('text', TEXT), 'label': ('label', LABEL)}
train_data, test_data = TabularDataset.splits(
path='./data',
train='train.json',
test='test.json',
format='json',
fields=fields
)
# 构建词汇表
TEXT.build_vocab(train_data, max_size=10000, vectors='glove.6B.100d')
# 创建数据迭代器
train_iterator, test_iterator = BucketIterator.splits(
(train_data, test_data),
batch_size=32,
device='cuda'
)
11.3.3 使用场景
torchtext 主要用于以下几个方面:
- 文本分类
- 序列标注
- 语言模型训练
- 机器翻译