05目标检测-区域推荐(Anchor机制详解)
目录
一、问题的引入
二、解决方案-设定的anchor boxes
1.高宽比(aspect ratio)的确定
2.尺度(scale)的确定
3.anchor boxes数量的确定
三、Anchor 的在目标检测中是怎么用的
1、anchor boxes对真值bounding box编码的步骤
2、为什么要回归偏移量而不是绝对坐标
3、输出特征图和锚框有什么关系
四、 Anchor 的本质
在了解RPN网络前我们先了解一些相关概念区域推荐(Anchor机制)。
一、问题的引入
往往,图片上的每一处位置都有可能出现目标物体,并且目标的大小是不确定的。那有什么办法能检出所有的物体呢?最容易想到的办法就是,以一个像素为中心截取很多个不同宽高比和大小的小块,每个小块都检测一下包不包含物体,如果包含物体,该物体的位置就是刚刚截取的这个小块的位置,同时再预测一下它的类别是什么。这样就可以做到不漏掉当前这个像素上的任何宽高比和大小的物体了;那刚刚截取的这个小块就是一个anchor box。
为了检出图像中不同位置的物体,使用滑动窗口的方式,从左到右,从上到下,把图像扫描一遍,每个像素点上都取很多小块进行检测,这样就可以保证不同位置、不同大小的物体都不漏掉了。Fig. 1是一个扫描检查的示例。

这种方法容易理解并且确实有效,但是缺点也是突出的----计算量太大了。假如一张图片的特征图大小为640*640,在图像中每一个像素上取10个不同宽高比不同大小的框做检测,则需要检测的框就会有640 x 640 x 10 = 4096000,太多了,如下图。那怎么改进呢?

其实,对于上面的问题有两个明显可以改善的点:
- 一是4096000个扫描框重叠(overlap)太多了
- 一是这些框里有很多框是背景,不包含物体,没有检测的必要。
所以,设法在保证覆盖整张图的基础上,略去重叠太严重的框,避开背景框,找高质量的、可能包含目标物体的候选框进行检测就显得尤为重要,可以以此来降低运算量,提高检测速度。
anchor boxes就是我们在检测之前确定的一系列候选框。我们默认,图片上会出现的所有物体,都会被我们设定的anchor boxes所覆盖。anchor box选择的好坏直接关系到两个方面:
- 一是能不能很好的覆盖整张图
- 一是能不能框住图片中可能出现的每个物体
所以anchor box的设定非常重要,既关系到精度的好坏,又关系到速度的快慢(速度仅就以上所说的扫描法而言)。
二、解决方案-设定的anchor boxes
使用设定的anchor boxes进行降低运算量,提高检测速度。anchor boxes如何设定呢?我们通过以下步骤完成:
- 高宽比(aspect ratio)的确定
- 尺度(scale)的确定
- anchor boxes数量的确定
举例来说明:假如要在一个数据集上做物体检测, 该数据集的图片分辨率均为256 x 256 , 数据集里绝大多数数目标物体的尺寸为 40 x 40或80 x 40。
1.高宽比(aspect ratio)的确定
因为绝大多数 数据集里目标物体的尺寸为 40 *40或80* 40,这说明数据集中绝大多数物体的真值边框的高宽比为1:1和2:1。 根据这个信息就可以确定锚框的高宽比信息,为这个数据集设计anchor boxes时其高宽比至少需要包括1:1和2:1。 这里举例为方便就只取1:1和2:1。
2.尺度(scale)的确定
尺度是指物体的高或宽与图片的高或宽之间的比值。例如图片的宽为256px,图片中物体的宽为40px,则该物体的尺度为40/256=0.15625,也就是说该物体占了图片15.62%的宽度。
为了选一组能更好的代表数据集里目标的尺度,我们应该以数据集中目标物体的最大尺度值和最小尺度值为上下限。如,数据集中物体的尺度的最小值和最大值分别为0.15625和0.3125,我们准备在这个范围内设置3种scale,则可以选择 {0.15625, 0.234375, 0.3125}。
3.anchor boxes数量的确定
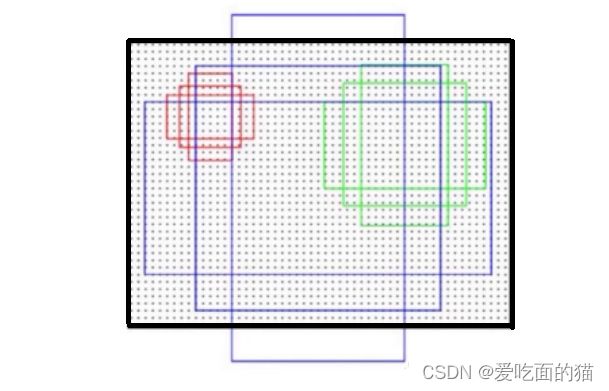
我们的scales(尺度)为 {0.15625, 0.234375, 0.3125},高宽比 aspect ratios为{1:1, 2:1}, 则每一个锚点上的一组锚框的数量为3x2 = 6个。如下图所示,即有3种{0.15625, 0.234375, 0.3125}大小,每一种大小都有两种高宽比{1:1, 2:1}。

按照以上方法所说,锚点是指256x256图像中的每一个像素,按基于anchor的神经网络目标检测来讲,锚点为网络最终输出特征图上的每一个点。
三、Anchor 的在目标检测中是怎么用的
在网络中anchor boxes是被用来编码目标物体的位置。目标检测一般是不会直接检测物体边框的绝对坐标的,而是检测其相对某一个锚框的偏移量,如下图中绿色真值框对蓝色边框的偏移。数据集中所有的目标均会被编码成对anchor boxes的偏移。如1.1问题引入中的图片, 锚框有非常多个,对一张图片来说,可能包含多个物体,有非常多个anchor boxes, 那怎么用anchor boxes对真值进行编码呢?

1、anchor boxes对真值bounding box编码的步骤
- a. 对每一个anchor box,算出其和哪一个真值bounding box的交并比(intersection over union score)最大
- b. 如果交并比>50%,则当前anchor box负责当前真值bounding box对应物体的检测,求真值bounding box对该anchor box的偏移
- c. 如果交并比介于40%与50%之间,不能确定该anchor是不是包含该物体,属于含糊框。
- d. 如果交并比<40%,则认为该anchor框到的都是背景,将该anchor划分为背景类。
- 除了被分配物体的锚框外,对只含背景的锚框和含糊框,偏移赋0,分类赋背景。
编码之后,物体检测类网络的回归目标变成回归编码好的偏移量了。
图片作为网络(神经网络)的输入,中间经过特征提取, 得到特征图。假设网络输出的特征图分辨率为7*7,而特征图上的每一个像素都有一组锚框。假如一组锚框的数量为2x3=6个(宽高比为2:1和1:1, 尺度为{0.15625, 0.234375, 0.3125}),则该特征图对应的回归网络中的锚框总数为7x7x2x3=296个,即296个anchor box。这个296个anchor box分别与真实值即目标物体bounding box(含分类信息和是否是背景类型信息)进行编码,得到每个anchor box到目标物体bounding box的偏移量(如果anchor box是含糊框或背景框,则偏移量为0),最总得到296个框的偏移量和分类信息。因此物体检测类网络的回归目标变成回归编码好的偏移量了。
对一个训练好的网络,其输出中,只包含背景的锚框的分类为背景,偏移为0;包含物体的锚框,其分类为物体的类别,偏移为锚框与物体真实边框之间的偏移。
2、为什么要回归偏移量而不是绝对坐标
神经网络的特性之一是位移不变性。例如对一张包含树的照片,不管树在这张图片的左上角还是右下角,网络输出的分类都是树,分类结果不会因为树在照片中位置的变化而变化。所以,对于一棵树,不管它在图片中的位置是什么,回归网络都偏向于为它输出相同的位置坐标,可见位移不变性和我们需要的位置坐标变化是冲突的,这显然是不行的。转而回归偏移的话,不管树在图像中的什么位置,其对它所在的锚框的偏移量基本是一致的,更加适合神经网络回归。
3、输出特征图和锚框有什么关系
锚框不是应该放在输入图上吗,为什么说输出特征图上的每一个点一组锚框?
如图所示,输出特征图(最右边3 x 3的小特征图)上的任何一个点都可以映射到输入图片上(感受野的意思),也就是说按照比例和网络的下采样,对输出特征图上的任意一点,在输入图片上都可以成比例找到它的对应位置。例如,在输出特征图上(0, 0)的点在输入图片上的对应位置为(2, 2)。
其次,假如检测的类别为10个类别,每个锚框的偏移量是4((x,y,w,h)4个位置的偏移量),则每个anchor box是10+4=14,假如每个锚点对应6个锚框,则是6x14,此时输出的3x3特征图的维度是 3x3x6x14 = 3 x3 x84 ( = 3 x3 x6 x14)。则输出特征图上点(0, 0)处的84个通道对应的值是 输入图(2, 2)位置上6个锚框的偏移量和分类值。
3 x3 x84 = 3x3x6x14中,6表示6个anchor box, 14表示偏移量和类别数,14中4为(x,y,w,h)的4个位置的偏移量,14中的10为类别数。
通过这样的隐式映射关系,将所有的anchor box都放在了输入图片上。

四、 Anchor 的本质
Anchor 的本质是 SPP(spatial pyramid pooling) 思想的逆向。而SPP本身是将不同尺寸的输入 resize 成为相同尺寸的输出,所以SPP的逆向就是,将相同尺寸的输出,倒推得到不同尺寸的输入。
区域推荐:
- 称为Anchor机制,即n*c*w*h ,其中n代表样本数,c代表通道数,w和h代表图像高度和宽度
- 将w*h区域内的每个1个点作为候选区域中心点,进行提取候选区域,这样的每个点都称为Anchor。
- 以某个点为候选区域中心点进行提取候选区域时候,通常会按照一定的比例来提取。例如fastRCN中每个中心点提取9个候选区域。因此1个w*h的区域需要提取候选区域为 w*h*9个。
- 针对这些候选区域和真值(GT),利用真值来对这些后续区域进行筛选,经过筛选后得到正负样本,
- 其中正样本就是包含了候选目标的区域,而是否包含则通常是通过IOU进行判断,即真值与候选区域的重叠的覆盖面积判断,
- 如果真值和后续区域重叠的面积超过70%,就是正样本。如果小于30%就是负样本。
- 这里的0.7和0.3都是超参,可自行设定。