【深度学习-seq2seq模型-附实现机器翻译的核心代码】
深度学习
- 深度学习-seq2seq模型
-
- 什么是seq2seq模型
- 应用场景
- 架构
-
- 编码器
- 解码器
- 训练 & 预测
- 损失
- 预测
- 评估BLEU
-
- BELU背后的数学意义
- 模型参考论文
深度学习-seq2seq模型
本文的网络架构模型参考 Sutskever et al., 2014以及Cho et al., 2014
什么是seq2seq模型
Sequence to sequence (seq2seq)是由encoder(编码器)和decoder(解码器)两个RNN组成的(注意本文中的RNN指代所有的循环神经网络,包括RNN、GRU、LSTM等)。
其中encoder负责对输入句子的理解,输出context vector(上下文变量)给decoder,decoder负责对理解后的句子的向量进行处理,解码,获得输出
应用场景
主要用来处理输入和输出序列长度不定的问题,在之前的RNN一文中,RNN的分类讲解过,其中就包括多对多结构,这个seq2seq模型就是典型的多对多,还是长度不一致的多对多,它的应用有很多场景,比如机器翻译,机器人问答,文章摘要,由关键字生成对话等等
例如翻译场景:
【hey took the little cat to the animal center】-> [他们把这只小猫送到了动物中心]
输入和输出长度没法一致
架构

整个架构是编码器-解码器结构
编码器
一般都是一个普通的RNN结构,不需要特殊的实现
class Encoder(nn.Module):
"""用于序列到序列学习的循环神经网络 编码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Encoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.gru = nn.GRU(embed_size, num_hiddens, num_layers, dropout=dropout)
def forward(self, X, *args):
# input shape (batchsize, num_steps)-> (batchsize, num_steps, embedingdim)
X = self.embedding(X)
# 交换dim,pythorch要求batchsize位置
X = X.permute(1, 0, 2)
# encode编码
# out的形状 (num_steps, batch_size, num_hiddens)
# state的形状: (num_layers, batch_size, num_hiddens)
output, state = self.gru(X)
return output, state
解码器
在 (Sutskever et al., 2014)的设计:
输入序列的编码信息送入到解码器中来生成输出序列的。
(Cho et al., 2014)设计: 编码器最终的隐状态在每一个时间步都作为解码器的输入序列的一部分。
上面架构图中展示的正式这种设计
在解码器中,在训练的时候比较特殊,可以允许真实值(标签)成为原始的输出序列, 从源序列词元“”“Ils”“regardent”“.” 到新序列词元 “Ils”“regardent”“.”“”来移动预测的位置。
解码器
class Decoder(nn.Module):
"""用于序列到序列学习的循环神经网络 解码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Decoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
# 与普通gru区别:input_size增加num_hiddens,用于input输入解码器encode的输出
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs):
# 初始化decode的hidden, 使用enc_outputs[1],enc_outputs格式(output, hidden state)
return enc_outputs[1]
def forward(self, X, state):
"""
:param X: input, shape is (num_steps, batch_size, embed_size)
:param state: hidden state, shape is( num_layers,batch_size, num_hiddens)
:return:
"""
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X).permute(1, 0, 2)
# 广播state的0维,使它与X具有相同的num_steps的维度,方便后续拼接,输出context的shape(num_steps, batch_size, num_hiddens)
context = state[-1].repeat(X.shape[0], 1, 1)
# conect input and context (num_steps, batch_size, embed_size+num_hiddens)
x_and_context = torch.cat((X, context), 2)
# output的形状:(num_steps, batch_size, num_hiddens)
# state的形状:(num_layers,batch_size,num_hiddens)
output, state = self.rnn(x_and_context, state)
# output的形状(batch_size,num_steps,vocab_size)
output = self.dense(output).permute(1, 0, 2)
return output, state
训练 & 预测
def train(net, data_iter, lr, num_epochs, tgt_vocab, device):
net.to(device)
loss = MaskedSoftmaxCELoss()
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
for epoch in range(num_epochs):
num_tokens = 0
total_loss = 0
for batch in data_iter:
optimizer.zero_grad()
X, X_valid_len, Y, Y_valid_len = [x.to(device) for x in batch]
bos = torch.tensor([tgt_vocab['' ]] * Y.shape[0],
device=device).reshape(-1, 1)
dec_input = torch.cat([bos, Y[:, :-1]], 1) # 强制教学
Y_hat, _ = net(X, dec_input)
# Y_hat的形状(batch_size,num_steps,vocab_size)
# Y的形状batch_size,num_steps
# loss内部permute Y_hat = Y_hat.permute(0, 2, 1)
l = loss(Y_hat, Y, Y_valid_len)
# 损失函数的标量进行“反向传播”
l.sum().backward()
#梯度裁剪
grad_clipping(net, 1)
#梯度更新
optimizer.step()
num_tokens = Y_valid_len.sum()
total_loss = l.sum()
print('epoch{}, loss{:.3f}'.format(epoch, total_loss/num_tokens))
损失
这里特别的说明一下,NLP中的损失通常用的都是基于交叉熵损失的masksoftmax损失,它只是在交叉熵损失的基础上封装了一点,mask了pad填充的词元,这个损失函数的意思,举个例子说明一下:
假设解码器的lable是【they are watching】,通常会用unk等pad这些句子到一定的长度,这个长度是代码中由你自行指定的,也是decoder的num_steps,比如我们设置了10,那么此时整个输入会被pad成【they are wathing unk unk unk unk unk unk unk eos】,但是计算损失的时候,我们不需要计算这部分,对应的损失需要置为0
预测
预测与评估的过程相同,但是稍有不同的是,预测过程不知道真实的输出标签,所以都是用上一步的预测值来作为下一个时间步的输入的。这里不再复述
评估BLEU
与其他输出固定的评估不一样,这次是一个句子的评估,常用的方法是:BLEU(bilingual evaluation understudy),最早用于机器翻译,现在也是被广泛用于各种其他的领域

BLEU的评估都是n-grams词元是否出现在标签序列中
lenlable表示标签序列中的词元数和
lenlpred表示预测序列中的词元数
pn 预测序列与标签序列中匹配的n元词元的数量, 与 预测序列中
n元语法的数量的比率
BELU肯定是越大越好,最好的情况肯定是1,那就是完全匹配
举个例子:给定标签序列A B C D E F 和预测序列 A B B C D
lenlable是6
lenlpred是5
p1 1元词元在lable和 pred中匹配的数量 B C D 也就是4 与 预测序列中1元词元个数 5 也就是0.8
其他pi也是依次计算 i 从1取到预测长度 -1 (也就是4)分别计算出来是3/4 1/3和0
前面的)
BLUE实现简单,此处也不再展现代码了
BELU背后的数学意义
首先后面概率相加的这部分:
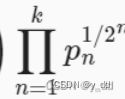
n元词法,当n越长则匹配难度越大, 所以BLEU为更长的元语法的精确度分配更大的权重,否则一个不完全匹配的句子可能会比全匹配的概率更大,这里就表现为,n越大,pn1/2n就越大
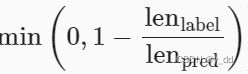
这一项是惩罚项,越短的句子就会降低belu分数,比如
给定标签序列A B C D E F 和预测序列 A B 和ABC 虽然p1 和p2 都是1,惩罚因此会降低短序列的分数
篇幅有限,代码无法一一展现,如果需要全部代码的小伙伴可以私信我
模型参考论文
Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. Advances in neural information processing systems (pp. 3104–3112).
Cho et al., 2014a
Cho, K., Van Merriënboer, B., Bahdanau, D., & Bengio, Y. (2014). On the properties of neural machine translation: encoder-decoder approaches. arXiv preprint arXiv:1409.1259.
Cho et al., 2014b
Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078.
李沐 动手深度学习