论文阅读:BotFinder: A Novel Framework for Social Bots Detection in Online Social Networks Based
目录
摘要
1 Introduction
3 Our Proposed Method: BotFinder
3.1 Overview
3.2 Step1: Feature Engineering
3.3 Step2: Similarity Calculation
3.4 Step3: community detection
4 Experiment
4.2 Data processing
论文链接:https://assets.researchsquare.com/files/rs-1871702/v1_covered.pdf?c=1659021986
摘要
近年来,随着在线社交网络(OSN)的广泛普及,用户数量也呈指数级增长。与此同时,社交机器人(即由程序控制的账户)也在不断增加。OSN 的服务提供商经常使用它们来保持社交网络的活跃。同时,一些社交机器人的注册也是出于恶意目的。有必要检测这些恶意社交机器人,以呈现真实的舆论环境。我们提出的 BotFinder 是一个检测 OSN 中恶意社交机器人的框架。具体来说,它结合了机器学习和图方法,从而可以有效地提取社交机器人的潜在特征。在特征工程方面,我们生成二阶特征,并使用编码方法对具有高卡因度的变量进行编码。这些特征充分利用了有标签和无标签样本。在图方面,我们首先通过嵌入方法生成节点向量,然后进一步计算人类和机器人向量之间的相似度;接着,我们使用无监督方法扩散标签,从而再次提高性能。为了验证所提方法的性能,我们在人工智能竞赛提供的数据集上进行了大量实验,该数据集由 800 多万条用户记录组成。结果表明,我们的方法达到了 0.8850 的 F1 分数,大大优于目前的技术水平。
1 Introduction
在过去的几十年里,在线社交网络(OSN)在我们的日常生活中发挥着越来越重要的作用,人类可以借助它进行实时交流,更方便、更有效地维护自己的社会关系。目前有许多全球流行的社交平台,如 Facebook、Twitter 等,将世界各地的用户联系在一起。此外,与报纸等传统媒体相比,OSN 也已成为个人获取社会新闻的最流行渠道。
社交机器人,即由程序控制的账户,可用于保持社交网络的活跃度。尽管 OSN 中存在有益的社交机器人,但一些恶意社交机器人的出现也会产生有害影响。例如,有些人出于各种目的注册大量账户,如恶意增加粉丝或点赞数。这些恶意行为已成为威胁社交网络平台健康发展的重要信息安全问题[1-2]。因此,有必要对这些恶意社交机器人进行检测,也就是社交机器人检测。目前的研究大多针对 Twitter 等国外平台,而针对国内 OSN 的研究较少。
因此,众多学者致力于研究社交僵尸的检测问题。目前与社交机器人检测相关的工作主要分为两类,即机器学习方法和基于图的方法。然而,这一课题仍然存在一些挑战:
1) 一般来说,大多数方法都依赖于单一算法来识别社交机器人,但由于数据集的多样性,这可能不是理想的选择。
2) 在实践中,大部分数据是无标签的,这表明标签的数量通常很少。因此,如何有效利用无标签数据是一个巨大的挑战;
为了应对上述挑战,我们在此联合考虑了用户的资料、行为和用户之间的关系。此外,我们还提出了一种综合机制 BotFinder,通过结合特征工程和图方法来检测社交机器人。首先,对数据集进行特征工程,提取全局信息。然后,我们通过嵌入方法生成节点向量。然后,我们计算人类和机器人向量之间的相似度。最后,我们采用无监督方法(这里考虑使用社群检测算法)来进一步提高性能。利用所提出的算法,我们可以很容易地检测出那些机器账户。
本文的贡献概述如下:
1) 首先,当孤立节点较多时,图算法可能表现不佳。而机器学习方法则无法学习拓扑结构。因此,我们结合机器学习方法和图方法来克服这些问题。
2) 其次,在特征工程中,我们试图获得二阶特征,并采用编码方法对具有高卡片性(或换句话说,包含大量不同值)的变量进行编码。就图而言,我们通过嵌入方法生成节点向量。然后,我们利用无监督方法扩散标签,以提高性能。这些方法充分利用了有标签和无标签样本。
本文接下来的内容安排如下。第 2 节,我们回顾了一些相关工作。在第 3 节中,我们将介绍拟议框架 BotFinder。然后,在第 4 节中,我们将详细描述所研究的数据集,并进行充分的分析实验。最后,我们将在第 5 节中总结我们的研究。
3 Our Proposed Method: BotFinder
在本节中,我们主要介绍 BotFinder,它主要包括三个步骤: 1) 我们在表格数据上体现特征工程技术;2) 我们得出节点嵌入,然后测量人类和机器人之间的相似性;3) 我们应用社群检测算法来进一步提高性能。
3.1 Overview
图 1 详细说明了这些步骤。第一步,利用特征工程技术生成特征矩阵。第二步,使用图嵌入方法生成相似性矩阵,然后合并这两个矩阵。之后,我们采用 LightGBM [30] 训练合并矩阵,并推断出临时结果。第三步,我们使用社群检测方法生成部分结果,并利用这些结果修正 LightGBM 的结果。
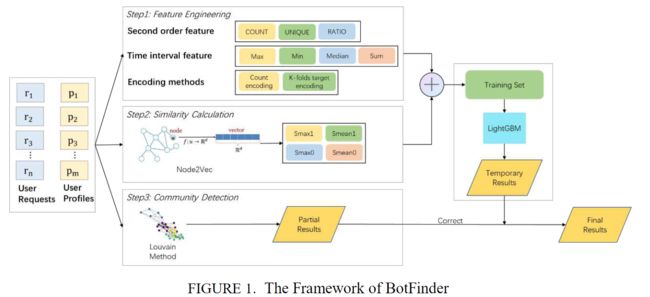
3.2 Step1: Feature Engineering
这里,我们尝试获取二阶特征、时间间隔特征、计数编码和k倍目标编码。然后,我们应用 LightGBM 来训练获得的特征并推断临时结果。
二阶特征:为了表示表中分类变量的组合,我们假设二阶特征表示为 (, , )。
这里反映的是活动程度。具体来说,我们选择一对变量(即 V1 和 V2),并预期记录这对变量在数据集中出现的次数。我们将其简称为 (V1,V2)。例如,用户使用设备类型(V1)iPhone12,1 和应用程序版本(V2)126.7.0 的组合向某人竖起大拇指,这个组合在数据集中出现 k 次。那么,使用 iPhone12,1 和 126.7.0 的用户将获得T值 k。
而表示特定范围内的多样性。我们使用一个变量(V1)作为主键,在另一个变量(V2)中记录唯一类别的数量。我们将其缩写为 (V1)[V2]。例如,对于使用设备类型(V1)iPhone12,1 的用户,数据集中有 k 个不同的应用程序版本。那么,使用 iPhone12,1 的用户将得到为 k的 值。
描述了计数的比例。计算公式为 (v1, v2)/(v1) 。例如,设备类型(V1)iPhone12,1 和应用程序版本(V2)126.7.0 的组合出现 k 次,设备类型(V1)iPhone12 在数据集中出现 v 次。那么,所有使用 iPhone12,1 和 126.7.0 的用户将得到 k/v 值。
时间间隔功能: 不同用户的请求时间间隔各不相同。在此,我们主要考虑时间间隔的最大值、最小值、中位数和总和。
计数编码: 计数编码是用数据集上计算出的计数来替换类别。然而,某些变量的计数可能是相同的,这可能会导致两个类别被编码为相同的值。这将导致模型性能下降。因此,我们在此引入一种目标编码技术。
K 折目标编码(或可能性编码、影响编码、平均值编码): 目标编码是通过目标(标签)对分类变量进行编号。在这里,我们用目标的相应概率替换分类变量的每个类别。为减少目标泄漏,我们采用 k 折目标编码。具体做法如下 (a) 将训练数据分成 10 倍。(b) 将第 2~10 个折叠目标的平均值视为第 1 个折叠的编码值,并同样计算第 2~10 个折叠的编码值。(c) 利用训练数据的目标值确定测试数据的编码值。
3.3 Step2: Similarity Calculation
在这里,我们采用 Node2vec [21] 来获取用户的节点嵌入(向量),然后计算用户与标签用户之间嵌入的余弦相似度。相似度值表示两个用户拥有相同标签的概率,例如,如果用户 1 和用户 2 之间的余弦相似度相对较大,则他们拥有相同标签的概率很高。
例如,A和 B表示用户/账户的两个节点向量。两个向量的余弦相似度计算公式为
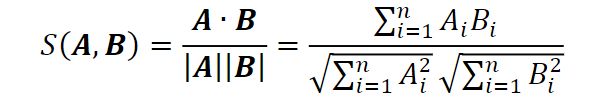
其中 Ai 和 Bi 分别表示向量A 和 B的元素.
然后,对于训练集和测试集中的每个节点向量C,我们计算它在机器人和人类之间的最大余弦相似度和平均余弦相似度,用向量 [Smax1, Smean1, Smax0, Smean0] 表示如下
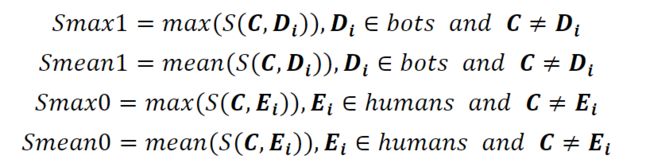
其中 Di和Ei 表示节点向量
流程如下图所示:

3.4 Step3: community detection
在社群检测方面,我们采用了典型的卢万方法 [17],将构建的图划分为不同的社群。然后,我们将用以下规则为社区贴标签: 1) 如果有标签的用户属于同一社区,则社区中的所有用户都应具有相同的标签。2) 如果一个社区中的用户没有任何标签,或者用户的标签不同,我们将不进行预测。
不过,预测可能无法覆盖所有用户。因此,该规则的性能有限。但该规则的结果比 LightGBM 更准确。通过将上述两个步骤结合起来,可以进一步提高性能。
4 Experiment
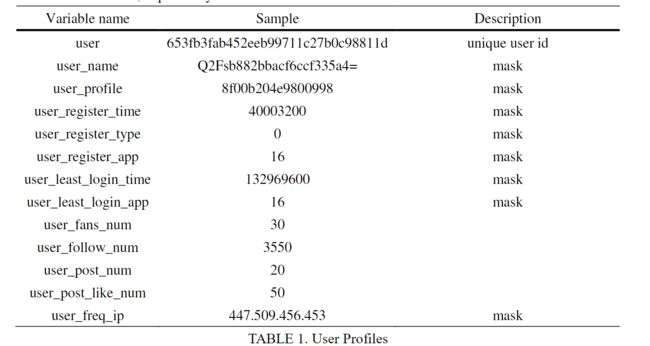
为了评估所提议机制的性能,我们从人工智能竞赛中收集了一个数据集(https://security.bytedance.com/fe/ai-challenge#/sec- project?id=2&active=1)。该数据集包含 800 多万条记录,包括用户资料和用户请求(关注或喜欢某人)。数据集的基本信息如表 1 和表 2 所示:表 1 显示了用户的个人信息(个人资料),而表 2 则说明了用户的行为(请求),包括当时用于发起请求的设备和应用程序版本。
任务描述如下
给定用户配置文件及其请求。只有一小部分用户被标记。因此,我们必须建立一个合理、可解释且有效的模型,以便从用户中检测出恶意机器人。

然后,我们在表 3 中进行了简单的统计分析。标签为 1 的请求表示该请求被阻止,相应的用户为机器人。我们发现,机器人的数量明显少于人类的数量。
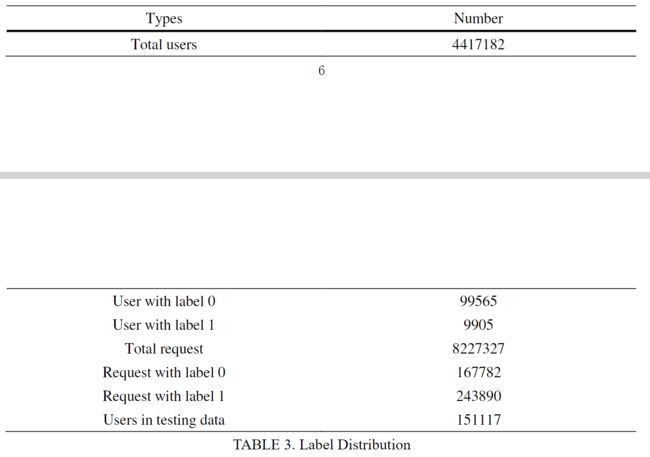
4.2 Data processing
本节将详细介绍数据处理过程。总的来说,我们在变量 "用户 "上将用户资料矩阵与用户请求矩阵合并,并对用户请求进行预测。对于特征工程,不同变量的处理过程如表 4 所示。操作完成后,我们得到特征工程矩阵

在相似性计算中,我们利用 3 种关系得出图形,然后计算相似性。我们利用 "request_ip"、"request_device_id "和 "request_target "关系得到图。例如,如果两个用户使用相同的 IP,或关注相同的目标,或共享相同的设备,他们之间就会有一条边。
1) 使用 "request_ip "构建图: 在此,我们分析了每个 IP 关联的用户数量,相应结果见表 5。我们发现,在大多数情况下,每个 IP 只关联一个用户。然而,构建的图可能无法覆盖所有用户。

因此,我们预计将排除只有 1 个用户的 IP。此外,还存在一些拥有超过 1000 个用户的 IP,它们可能是公共 IP。这些公共 IP 的存在会导致构建的图中出现大量的边,从而削弱用户之间的关联。因此,为简单起见,我们也排除了用户数量超过 1000 的 IP。表 6 显示了排除后每个 IP 关联用户数量的量化值。共有 26,836,730 条边和 1,953,559 个节点,占所有用户的 44.23%。