Kaldi语音识别技术(八) ----- 整合HCLG
Kaldi语音识别技术(八) ----- 整合HCLG
文章目录
- Kaldi语音识别技术(八) ----- 整合HCLG
-
- HCLG 概述
- 组合LG.fst
-
-
- 可视化 LG.fst
-
- 组合CLG.fst
-
-
- 可视化CLG.fst
-
- 生成H.fst
- 组合HCLG.fst
-
- 生成HaCLG.fst
- 生成HCLG.fst
HCLG 概述
HCLG= min(det(H o min(det(C o min(det(L o G)))))
将四者逐层合并,即可得到最后的图。其中, o表示组合,det表示确定化,min表示最小化。
WFST的融合一般是从大到小,即先将G与L进行融合,再一次融合C、H,每次融合都要进行确定化(determinisation)和最小化(minimisation),最小化是指将WFST转换为一个状态节点和边更少的等价WFST,提高搜索的效率。HCLG的组合可以参考 kaldi/wsj/s5/utils/mkgraph.sh

组合LG.fst
- fsttablecompose
用法:
fsttablecompose
Composition algorithm [between two FSTs of standard type, in tropical
semiring] that is more efficient for certain cases-- in particular,
where one of the FSTs (the left one, if --match-side=left) has large
out-degree
Usage: fsttablecompose (fst1-rxfilename|fst1-rspecifier) (fst2-rxfilename|fst2-rspecifier) [(out-rxfilename|out-rspecifier)]
使用实列:
cd ~/kaldi && mkdir HCLG
fsttablecompose ~/kaldi/data/L/lang/L_disambig.fst ~/kaldi/data/G/normal/G.fst | fstdeterminizestar --use-log=true | fstminimizeencoded | fstpushspecial | fstarcsort --sort_type=ilabel > ~/kaldi/data/HCLG/LG.fst

fstisstochastic 这是一个诊断步骤,他打印出两个数字,最小权重和最大权重
fsttablecompose 将两个fst(L.fst、G.fst)合并成一个fst(LG.fst),将前端输出字符对应上后端输入即可,合并后前端输入作为合并后fst之输入,后端输出作为合并后输出;
fstdeterminizestar 做确定化(从一个状态接收同一个输入后只会跳转到一个状态),消除空转移,降低图的冗余度;
fstminimizeencoded 将fst最小化,将权重尽量前推,尽量利用上语言模型的信息,避免重要路径被剪枝;
fstisstochastic 进行归一化,保证状态上各输出概率之合为1。
可视化 LG.fst
- fstprint
cd ~/kaldi/data
fstprint --isymbols=./G/normal/phones.txt --osymbols=./G/normal/words.txt ./HCLG/LG.fst > ./HCLG/LG.txt
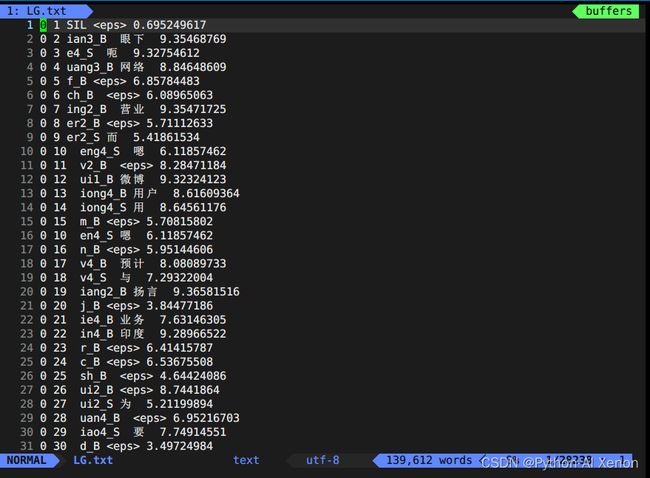
- fstdraw
fstdraw --isymbols=./G/normal/phones.txt --osymbols=./G/normal/words.txt ./HCLG/LG.fst > ./HCLG/LG.dot # 生成dot文件
dot -Tsvg ./HCLG/LG.dot > LG.svg # 转成svg矢量图(放大不会失真)
所需时间很长,不进行尝试。
组合CLG.fst
fstcomposecontext
用法:
fstcomposecontext
Composes on the left with a dynamically created context FST
Usage: fstcomposecontext [ [] ]
E.g: fstcomposecontext ilabels.sym < LG.fst > CLG.fst
使用实列:
cd ~/kaldi/data/HCLG
fstcomposecontext --context-size=1 --central-position=0 --read-disambig-syms=/root/kaldi/data/G/normal/phones/disambig.int --write-disambig-syms=disambig_ilabels.int disambig_ilabels < LG.fst > CLG.fst
参数详解:
–context-size=1 单音素模型
–central-position=0 中间音素位置为0
–read-disambig-syms disambig.int来自生成的L或G过程中生成的phones文件夹中的文件,输入文件LdG-Ngram.fst来自于上一步合并的LdG-Ngram.fst模型。

在Kaldi中一般不会显式创建出单独的C.fst再和LG 组合,不用fsttablecompose命令,而是使用fstcomposecontext 工具根据LG.fst动态的生成CLG.fst。当然也可以先创建C.fst,然后使用fsttablecompose命令融合,但是这种方式相当耗时。 这里构建出来disambig_ilabels.int和disambig_ilabels 2个文件,用于生成Ha.fst。
可视化CLG.fst
- fstprint
fstprint fstprint --isymbols=../G/normal/phones.txt --osymbols=../G/normal/words.txt ./CLG.fst > CLG.txt
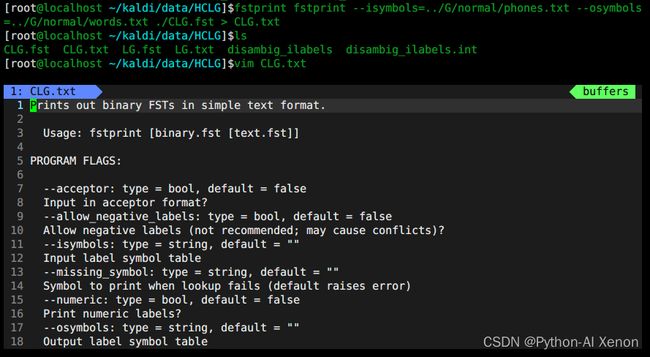
- fstdraw
fstdraw --isymbols=./G/normal/phones.txt --osymbols=../G/normal/words.txt ../CLG.fst > CLG.dot # 再使用dot工具转为图片即可
生成H.fst
make-h-transducer
make-h-transducer是基于HMM拓扑结构构建不带自转移的声学模型Ha.fs
用法:
make-h-transducer
Make H transducer from transition-ids to context-dependent phones,
without self-loops [use add-self-loops to add them]
Usage: make-h-transducer []
e.g.:
make-h-transducer ilabel_info 1.tree 1.mdl > H.fst
使用实列:
make-h-transducer disambig_ilabels /root/kaldi/data/H/mono/tree /root/kaldi/data/H/mono/final.mdl > Ha.fst
参数详解:
第一个输入参数(disambig_ilabels )为组合CLG.fst时生成的。
第二个输入参数为 GMM训练生成的决策树(tree)。
第三个输入参数为 GMM训练生成的最终模型。(Ha.fst中的a表示没有自环(self-loop))。

组合HCLG.fst
生成HaCLG.fst
fsttablecompose
fstrmsymbols:去除HaCLG.fst模型中与消歧相关的转移。disambig_tid.int为组合CLG.fst时生成的。
用法:
fsttablecompose
Composition algorithm [between two FSTs of standard type, in tropical
semiring] that is more efficient for certain cases-- in particular,
where one of the FSTs (the left one, if --match-side=left) has large
out-degree
Usage: fsttablecompose (fst1-rxfilename|fst1-rspecifier) (fst2-rxfilename|fst2-rspecifier) [(out-rxfilename|out-rspecifier)]
使用实列:
fsttablecompose Ha.fst CLG.fst | fstdeterminizestar --use-log=true | fstrmsymbols disambig_tid.int | fstrmepslocal | fstminimizeencoded | fstpushspecial > HaCLG.fst

1、为HaCLG.fst模型添加自环
add-self-loops --self-loop-scale=0.1 --reorder=true /root/kaldi/data/H/mono/final.mdl < HaCLG.fst
生成HCLG.fst
2、将HaCLG转换为HCLG
fstconvert --fst_type=const HaCLG.fst >HCLG.fst
至此,HCLG.fst已经生成,整个kaldi语音识别系统的核心内容已经构建完成,只需要将其进行应用即可!
有问题欢迎私信或者留言探讨,完整的虚拟机克隆后面会放评论区,感谢支持!
推荐文章: Kaldi的HCLG构图过程可视化