十三、函数式编程(3)
本章概要
- 高阶函数
- 闭包
- 作为闭包的内部类
- 函数组合
- 柯里化和部分求值
- 纯函数式编程
- 本章小结
高阶函数
这个名字可能听起来令人生畏,但是:高阶函数(Higher-order Function)只是一个消费或产生函数的函数。
我们先来看看如何产生一个函数:
import java.util.function.*;
interface FuncSS extends Function<String, String> {
} // [1]
public class ProduceFunction {
static FuncSS produce() {
return s -> s.toLowerCase(); // [2]
}
public static void main(String[] args) {
FuncSS f = produce();
System.out.println(f.apply("YELLING"));
}
}
输出结果:
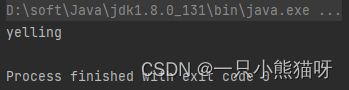
这里,produce() 是高阶函数。
[1] 使用继承,可以轻松地为专用接口创建别名。
[2] 使用 Lambda 表达式,可以轻松地在方法中创建和返回一个函数。
要消费一个函数,消费函数需要在参数列表正确地描述函数类型。代码示例:
import java.util.function.*;
class One {
}
class Two {
}
public class ConsumeFunction {
static Two consume(Function<One, Two> onetwo) {
return onetwo.apply(new One());
}
public static void main(String[] args) {
Two two = consume(one -> new Two());
}
}
当基于消费函数生成新函数时,事情就变得相当有趣了。代码示例如下:
import java.util.function.*;
class I {
@Override
public String toString() {
return "I";
}
}
class O {
@Override
public String toString() {
return "O";
}
}
public class TransformFunction {
static Function<I, O> transform(Function<I, O> in) {
return in.andThen(o -> {
System.out.println(o);
return o;
});
}
public static void main(String[] args) {
Function<I, O> f2 = transform(i -> {
System.out.println(i);
return new O();
});
O o = f2.apply(new I());
}
}
输出结果:
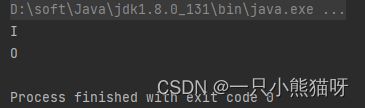
在这里,transform() 生成一个与传入的函数具有相同签名的函数,但是你可以生成任何你想要的类型。
这里使用到了 Function 接口中名为 andThen() 的默认方法,该方法专门用于操作函数。 顾名思义,在调用 in 函数之后调用 andThen()(还有个 compose() 方法,它在 in 函数之前应用新函数)。 要附加一个 andThen() 函数,我们只需将该函数作为参数传递。 transform() 产生的是一个新函数,它将 in 的动作与 andThen() 参数的动作结合起来。
闭包
在上一节的 ProduceFunction.java 中,我们从方法中返回 Lambda 函数。 虽然过程简单,但是有些问题必须再回过头来探讨一下。
闭包(Closure)一词总结了这些问题。 它非常重要,利用闭包可以轻松生成函数。
考虑一个更复杂的 Lambda,它使用函数作用域之外的变量。 返回该函数会发生什么? 也就是说,当你调用函数时,它对那些 “外部 ”变量引用了什么? 如果语言不能自动解决,那问题将变得非常棘手。 能够解决这个问题的语言被称作 支持闭包,或者称作 词法定界(lexically scoped ,基于词法作用域的)( 也有用术语 变量捕获 variable capture 称呼的)。Java 8 提供了有限但合理的闭包支持,我们将用一些简单的例子来研究它。
首先,下列方法返回一个函数,该函数访问对象字段和方法参数:
import java.util.function.*;
public class Closure1 {
int i;
IntSupplier makeFun(int x) {
return () -> x + i++;
}
}
但是,仔细考虑一下,i 的这种用法并非是个大难题,因为对象很可能在你调用 makeFun() 之后就存在了——实际上,垃圾收集器几乎肯定会保留以这种方式被绑定到现存函数的对象。当然,如果你对同一个对象多次调用 makeFun() ,你最终会得到多个函数,它们共享 i 的存储空间:
import java.util.function.*;
public class SharedStorage {
public static void main(String[] args) {
Closure1 c1 = new Closure1();
IntSupplier f1 = c1.makeFun(0);
IntSupplier f2 = c1.makeFun(0);
IntSupplier f3 = c1.makeFun(0);
System.out.println(f1.getAsInt());
System.out.println(f2.getAsInt());
System.out.println(f3.getAsInt());
}
}
输出结果:

每次调用 getAsInt() 都会增加 i,表明存储是共享的。
如果 i 是 makeFun() 的局部变量怎么办? 在正常情况下,当 makeFun() 完成时 i 就消失。 但它仍可以编译:
import java.util.function.*;
public class Closure2 {
IntSupplier makeFun(int x) {
int i = 0;
return () -> x + i;
}
}
由 makeFun() 返回的 IntSupplier “关住了” i 和 x,因此即使makeFun()已执行完毕,当你调用返回的函数时i 和 x仍然有效,而不是像正常情况下那样在 makeFun() 执行后 i 和x就消失了。 但请注意,我没有像 Closure1.java 那样递增 i,因为会产生编译时错误。代码示例:
// {WillNotCompile}
import java.util.function.*;
public class Closure3 {
IntSupplier makeFun(int x) {
int i = 0;
// x++ 和 i++ 都会报错:
return () -> x++ + i++;
}
}
x 和 i 的操作都犯了同样的错误:被 Lambda 表达式引用的局部变量必须是 final 或者是等同 final 效果的。
如果使用 final 修饰 x和 i,就不能再递增它们的值了。代码示例:
import java.util.function.*;
public class Closure4 {
IntSupplier makeFun(final int x) {
final int i = 0;
return () -> x + i;
}
}
那么为什么在 Closure2.java 中, x 和 i 非 final 却可以运行呢?
这就叫做等同 final 效果(Effectively Final)。这个术语是在 Java 8 才开始出现的,表示虽然没有明确地声明变量是 final 的,但是因变量值没被改变过而实际有了 final 同等的效果。 如果局部变量的初始值永远不会改变,那么它实际上就是 final 的。
如果 x 和 i 的值在方法中的其他位置发生改变(但不在返回的函数内部),则编译器仍将视其为错误。每个递增操作则会分别产生错误消息。代码示例:
// {无法编译成功}
import java.util.function.*;
public class Closure5 {
IntSupplier makeFun(int x) {
int i = 0;
i++;
x++;
return () -> x + i;
}
}
等同 final 效果意味着可以在变量声明前加上 final 关键字而不用更改任何其余代码。 实际上它就是具备 final 效果的,只是没有明确说明。
在闭包中,在使用 x 和 i 之前,通过将它们赋值给 final 修饰的变量,我们解决了 Closure5.java 中遇到的问题。代码示例:
import java.util.function.*;
public class Closure6 {
IntSupplier makeFun(int x) {
int i = 0;
i++;
x++;
final int iFinal = i;
final int xFinal = x;
return () -> xFinal + iFinal;
}
}
上例中 iFinal 和 xFinal 的值在赋值后并没有改变过,因此在这里使用 final 是多余的。
如果改用包装类型会是什么情况呢?我们可以把int类型改为Integer类型研究一下:
// {无法编译成功}
import java.util.function.*;
public class Closure7 {
IntSupplier makeFun(int x) {
Integer i = 0;
i = i + 1;
return () -> x + i;
}
}
编译器非常聪明地识别到变量 i 的值被更改过。 包装类型可能是被特殊处理了,我们再尝试下 List:
import java.util.*;
import java.util.function.*;
public class Closure8 {
Supplier<List<Integer>> makeFun() {
final List<Integer> ai = new ArrayList<>();
ai.add(1);
return () -> ai;
}
public static void main(String[] args) {
Closure8 c7 = new Closure8();
List<Integer>
l1 = c7.makeFun().get(),
l2 = c7.makeFun().get();
System.out.println(l1);
System.out.println(l2);
l1.add(42);
l2.add(96);
System.out.println(l1);
System.out.println(l2);
}
}
输出结果:
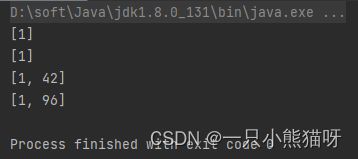
可以看到,这次一切正常。我们改变了 List 的内容却没产生编译时错误。通过观察本例的输出结果,我们发现这看起来非常安全。这是因为每次调用 makeFun() 时,其实都会创建并返回一个全新而非共享的 ArrayList。也就是说,每个闭包都有自己独立的 ArrayList,它们之间互不干扰。
请注意我已经声明 ai 是 final 的了。尽管在这个例子中你可以去掉 final 并得到相同的结果(试试吧!)。 应用于对象引用的 final 关键字仅表示不会重新赋值引用。 它并不代表你不能修改对象本身。
我们来看看 Closure7.java 和 Closure8.java 之间的区别。我们看到:在 Closure7.java 中变量 i 有过重新赋值。 也许这就是触发等同 final 效果错误消息的原因。
// {无法编译成功}
import java.util.*;
import java.util.function.*;
public class Closure9 {
Supplier<List<Integer>> makeFun() {
List<Integer> ai = new ArrayList<>();
ai = new ArrayList<>(); // Reassignment
return () -> ai;
}
}
上例,重新赋值引用会触发错误消息。如果只修改指向的对象则没问题,只要没有其他人获得对该对象的引用(这意味着你有多个实体可以修改对象,此时事情会变得非常混乱),基本上就是安全的。
让我们回顾一下 Closure1.java。那么现在问题来了:为什么变量 i 被修改编译器却没有报错呢。 它既不是 final 的,也不是等同 final 效果的。因为 i 是外部类的成员,所以这样做肯定是安全的(除非你正在创建共享可变内存的多个函数)。是的,你可以辩称在这种情况下不会发生变量捕获(Variable Capture)。但可以肯定的是,Closure3.java 的错误消息是专门针对局部变量的。因此,规则并非只是 “在 Lambda 之外定义的任何变量必须是 final 的或等同 final 效果” 那么简单。相反,你必须考虑捕获的变量是否是等同 final 效果的。 如果它是对象中的字段(实例变量),那么它有独立的生命周期,不需要任何特殊的捕获以便稍后在调用 Lambda 时存在。(注:结论是——Lambda 可以没有限制地引用 实例变量和静态变量。但 局部变量必须显式声明为final,或事实上是final 。)
作为闭包的内部类
我们可以使用匿名内部类重写之前的例子:
import java.util.function.*;
public class AnonymousClosure {
IntSupplier makeFun(int x) {
int i = 0;
// 同样规则的应用:
// i++; // 非等同 final 效果
// x++; // 同上
return new IntSupplier() {
@Override
public int getAsInt() {
return x + i;
}
};
}
}
实际上只要有内部类,就会有闭包(Java 8 只是简化了闭包操作)。在 Java 8 之前,变量 x 和 i 必须被明确声明为 final。在 Java 8 中,内部类的规则放宽,包括等同 final 效果。
函数组合
函数组合(Function Composition)意为“多个函数组合成新函数”。它通常是函数式编程的基本组成部分。在前面的 TransformFunction.java 类中,就有一个使用 andThen() 的函数组合示例。一些 java.util.function 接口中包含支持函数组合的方法 。
| 组合方法 | 支持接口 |
|---|---|
andThen(argument) |
|
| 执行原操作,再执行参数操作 | **Function |
| BiFunction | |
| Consumer | |
| BiConsumer | |
| IntConsumer | |
| LongConsumer | |
| DoubleConsumer | |
| UnaryOperator | |
| IntUnaryOperator | |
| LongUnaryOperator | |
| DoubleUnaryOperator | |
| BinaryOperator** | |
compose(argument) |
|
| 执行参数操作,再执行原操作 | **Function |
| UnaryOperator | |
| IntUnaryOperator | |
| LongUnaryOperator | |
| DoubleUnaryOperator** | |
and(argument) |
|
| 原谓词(Predicate)和参数谓词的短路逻辑与 | **Predicate |
| BiPredicate | |
| IntPredicate | |
| LongPredicate | |
| DoublePredicate** | |
or(argument) |
|
| 原谓词和参数谓词的短路逻辑或 | **Predicate |
| BiPredicate | |
| IntPredicate | |
| LongPredicate | |
| DoublePredicate** | |
negate() |
|
| 该谓词的逻辑非 | **Predicate |
| BiPredicate | |
| IntPredicate | |
| LongPredicate | |
| DoublePredicate** |
下例使用了 Function 里的 compose()和 andThen()。代码示例:
import java.util.function.*;
public class FunctionComposition {
static Function<String, String>
f1 = s -> {
System.out.println(s);
return s.replace('A', '_');
},
f2 = s -> s.substring(3),
f3 = s -> s.toLowerCase(),
f4 = f1.compose(f2).andThen(f3);
public static void main(String[] args) {
System.out.println(f4.apply("GO AFTER ALL AMBULANCES"));
}
}
输出结果:
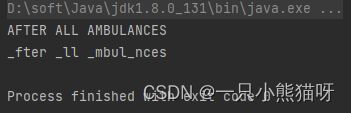
这里我们重点看正在创建的新函数 f4。它调用 apply() 的方式与常规几乎无异。
当 f1 获得字符串时,它已经被f2 剥离了前三个字符。这是因为 compose(f2) 表示 f2 的调用发生在 f1 之前。
下例是 谓词(Predicate) 的逻辑运算演示.代码示例:
import java.util.function.*;
import java.util.stream.*;
public class PredicateComposition {
static Predicate<String>
p1 = s -> s.contains("bar"),
p2 = s -> s.length() < 5,
p3 = s -> s.contains("foo"),
p4 = p1.negate().and(p2).or(p3);
public static void main(String[] args) {
Stream.of("bar", "foobar", "foobaz", "fongopuckey")
.filter(p4)
.forEach(System.out::println);
}
}
输出结果:

p4 获取到了所有谓词(Predicate)并组合成一个更复杂的谓词。解读:如果字符串中不包含 bar 且长度小于 5,或者它包含 foo ,则结果为 true。
正因它产生如此清晰的语法,我在主方法中采用了一些小技巧,并借用了下一章的内容。首先,我创建了一个字符串对象的流,然后将每个对象传递给 filter() 操作。 filter() 使用 p4 的谓词来确定对象的去留。最后我们使用 forEach() 将 println 方法引用应用在每个留存的对象上。
从输出结果我们可以看到 p4 的工作流程:任何带有 "foo" 的字符串都得以保留,即使它的长度大于 5。 "fongopuckey" 因长度超出且不包含 foo 而被丢弃。
柯里化和部分求值
柯里化(Currying)的名称来自于其发明者之一 Haskell Curry。他可能是计算机领域唯一姓氏和名字都命名过重要概念的人(另外就是 Haskell 编程语言)。 柯里化意为:将一个多参数的函数,转换为一系列单参数函数。
import java.util.function.*;
public class CurryingAndPartials {
// 未柯里化:
static String uncurried(String a, String b) {
return a + b;
}
public static void main(String[] args) {
// 柯里化的函数:
Function<String, Function<String, String>> sum =
a -> b -> a + b; // [1]
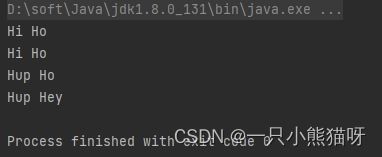
System.out.println(uncurried("Hi ", "Ho"));
Function<String, String>
hi = sum.apply("Hi "); // [2]
System.out.println(hi.apply("Ho"));
// 部分应用:
Function<String, String> sumHi =
sum.apply("Hup ");
System.out.println(sumHi.apply("Ho"));
System.out.println(sumHi.apply("Hey"));
}
}
输出结果:
[1] 这一连串的箭头很巧妙。注意,在函数接口声明中,第二个参数是另一个函数。
[2] 柯里化的目的是能够通过提供单个参数来创建一个新函数,所以现在有了一个“带参函数”和剩下的 “自由函数”(free argument) 。实际上,你从一个双参数函数开始,最后得到一个单参数函数。
我们可以通过继续添加层级来柯里化一个三参数函数:
import java.util.function.*;
public class Curry3Args {
public static void main(String[] args) {
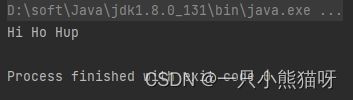
Function<String, Function<String, Function<String, String>>> sum = a -> b -> c -> a + b + c;
Function<String, Function<String, String>> hi = sum.apply("Hi ");
Function<String, String> ho = hi.apply("Ho ");
System.out.println(ho.apply("Hup"));
}
}
输出结果:
对于每一级的箭头级联(Arrow-cascading),你都会在类型声明周围包裹另一个 Function 。
处理基本类型和装箱时,请使用适当的函数式接口:
import java.util.function.*;
public class CurriedIntAdd {
public static void main(String[] args) {
IntFunction<IntUnaryOperator> curriedIntAdd = a -> b -> a + b;
IntUnaryOperator add4 = curriedIntAdd.apply(4);
System.out.println(add4.applyAsInt(5));
}
}
输出结果:
9
可以在互联网上找到更多的柯里化示例。通常它们是用 Java 之外的语言实现的,但如果理解了柯里化的基本概念,你可以很轻松地用 Java 实现它们。
纯函数式编程
只要多加练习,用没有函数式支持的语言也可以写出纯函数式程序(即使是 C 这样的原始语言)。Java 8 让函数式编程更简单,不过我们要确保一切是 final 的,同时你的所有方法和函数没有副作用。因为 Java 在本质上并非是不可变语言,所以编译器对我们犯的错误将无能为力。
这种情况下,我们可以借助第三方工具,但使用 Scala 或 Clojure 这样的语言可能更简单。因为它们从一开始就是为保持不变性而设计的。你可以采用这些语言来编写你的 Java 项目的一部分。如果必须要用纯函数式编写,则可以用 Scala(需要一些练习) 或 Clojure (仅需更少的练习)。虽然 Java 支持并发编程,但如果这是你项目的核心部分,你应该考虑在项目部分功能中使用 Scala 或 Clojure 之类的语言。