pandas入门
Pandas 是在 Numpy 上的封装。 继承了 Numpy 的所有优点,但是这种封装有好有坏
我们对比一下两者创建的形式和效果
import pandas as pd
import numpy as np
a=np.array([[1,2],[3,4]])
b=pd.DataFrame(
{
"a":[1,2],
"b":[3,4]
}
)
print(a,"\n",b)

Pandas 就像字典一样,还记录着数据的外围信息, 比如标签(Column 名)和索引(Row index)
可以简单理解为Numpy 是 Python 里的列表,而 Pandas 是 Python 里的字典
Pandas 和 NumPy 都是Python中用于数据处理和分析的重要库,但它们具有不同的优点和缺点,适用于不同类型的任务和应用场景。
Pandas的优点:
-
表格数据处理: Pandas以DataFrame的形式支持表格型数据处理,这种结构非常适合处理多维数据,例如SQL数据库或电子表格。DataFrame允许你轻松地执行各种操作,如筛选、合并、聚合、透视等。
-
标签: Pandas提供了丰富的标签,可以用于行和列,使得数据的访问和操作更加直观和容易理解。
-
缺失数据处理: Pandas提供了有效的方法来处理缺失数据,这在实际数据分析中非常常见。你可以轻松地填充、删除或插入缺失的数据。
-
时间序列数据: Pandas对时间序列数据的支持非常强大,包括日期范围生成、滚动窗口、时间重采样等功能。
-
数据可视化: Pandas可以与其他数据可视化库(如Matplotlib和Seaborn)结合使用,以便快速生成图表和可视化数据。
Pandas的缺点:
-
性能: 对于大型数据集,Pandas的性能可能不如NumPy,因为Pandas的DataFrame会消耗更多的内存和计算资源。
-
学习曲线: 对于初学者来说,Pandas的学习曲线可能较陡峭,因为需要了解各种函数和概念,如索引、层次化索引、多级列等。
NumPy的优点:
-
性能: NumPy是一个高性能的数值计算库,它用C语言编写,并且对数组操作进行了优化。对于大型数据集和数值计算任务,NumPy通常比Pandas更快。
-
多维数组: NumPy的核心数据结构是多维数组(ndarray),它非常适合进行数学和科学计算,如线性代数、统计分析和信号处理。
-
广泛的数学函数: NumPy提供了大量的数学和统计函数,包括线性代数、傅立叶变换、随机数生成等。
-
与其他库的集成: NumPy与许多其他科学计算库(如SciPy、scikit-learn)以及数据可视化库(如Matplotlib)紧密集成,使得它成为构建复杂数据分析和科学计算应用的基础。
NumPy的缺点:
-
缺少表格数据结构: NumPy主要关注多维数组,缺少直接支持表格数据的数据结构。这使得处理类似数据库表格或电子表格的数据时,需要使用较多的代码。
-
不适用于非数值数据: NumPy主要用于数值数据,不太适用于处理文本或混合类型的数据。
综上所述,Pandas和NumPy在数据处理和分析中各有其优点和缺点,通常会根据任务的性质和需求来选择使用哪个库,甚至可以同时使用它们以发挥各自的优势。如果需要处理表格型数据、进行数据清洗和转换,通常会首选Pandas。如果需要进行数值计算、线性代数运算或高性能的科学计算,NumPy可能更适合。
基本操作
从文件读取数据
excel文件
我们先创建一个excel文件

import pandas as pd
# 读取
a=pd.read_excel("体检数据.xlsx")
print(a)
# index_col=0,把第一个 column(学号)的数据当做 row 索引
a=pd.read_excel("体检数据.xlsx",index_col=0)
print(a)
# 修改(此时原始数据并没有被修改)
a.loc[2,"体重"]=1
print(a)
# 保存(此时新保存的excel里的数据是被修改后的)
a.to_excel("保存的体检数据.xlsx")

-
.loc[]是pandas库用于选择DataFrame中特定行和列的方法。在这里,它被用来定位特定的行和列。 -
[2, "体重"]是.loc[]的参数,这里表示选择第2行(索引为2的行)和名为"体重"的列。
csv或txt等纯文本文件
我们先创建一个csv文件
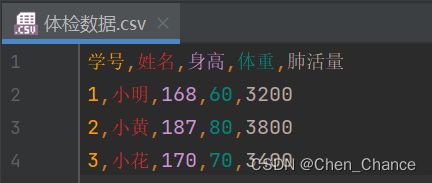
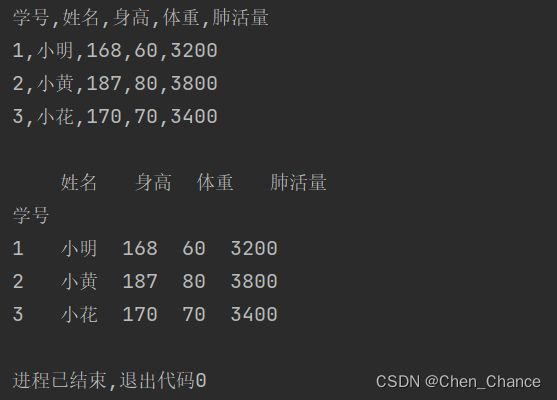
# 用python方法打开
with open("体检数据.csv","r",encoding="utf-8") as f:
print(f.read())
# 用pandas打开,sep表示分割符号,如果别人给你的数据不走常规用+分割,那么你的sep就要是+
a=pd.read_csv("体检数据.csv",index_col=0,sep=",")
print(a)
# 保存
a.to_csv("保存的体检数据.csv")
a.to_excel("保存的体检数据.xlsx")
其他有趣的方法
后面再补上
Pandas 中的数据是什么
数据序列Series(一维)
Pandas 中的 Series 的核心其实就是一串类似于 Python List 的序列。只是它要比 Python List 丰富很多, 有更多的功能属性
# list和pd的Series的区别
a=[11,22,33]
b=pd.Series(a)
print(a)
print(b)
# 自定义索引
b=pd.Series(a,index=["a","b","c"])
print(b)
b=pd.Series({"a":11,"b":22,"c":33})
print(b)
# 将列表换成numpy数组
import numpy as np
b=pd.Series(np.random.rand(3),index=["a","b","c"])
print(b)
# 把Series返回成numpy数组或list
print(b.to_numpy())
print(b.values.tolist())

b.to_numpy() 和 b.values 功能基本上是相同的,它们都用于将 pandas DataFrame 中的数据转换为 NumPy 数组,但有一些微小的差异:
-
命名不同:
b.to_numpy()是一个方法,而b.values是一个属性。使用方法时需要添加括号,而属性不需要。 -
版本兼容性:在较旧版本的 pandas 中,可能没有
to_numpy()方法,因此b.values是更通用的选择。 -
潜在性能:在某些情况下,
b.to_numpy()可能会在性能上略优于b.values,因为它可以更好地处理某些特殊情况,例如,当 DataFrame 包含不同数据类型的列时,to_numpy()可以将数据类型更好地匹配到 NumPy 数组的数据类型,而b.values会将所有列都强制转换为一种通用数据类型。
总的来说,功能上它们是相同的,可以根据个人偏好选择使用哪个,但在大多数情况下,它们都会产生相似的结果。
数据表DataFrame(二维)
a=pd.DataFrame([[1,2],[3,4]])
print(a)
# 第一行,第0列的数字
print(a.at[1,0])
# 通过字典的方式创建,修改的是列索引
a=pd.DataFrame({"col1":[1,3],"col2":[2,4]})
print(a)
# 由DataFrame创建Series
print(a["col1"])
print(type(a["col1"]))
# 由Series创建DataFrame
print(pd.DataFrame({"col1":pd.Series([1,3]),"col2":pd.Series([2,4])},index=["a","b"]))
# 获取行索引和列索引
print(a.index,"\n",a.columns)
#json格式转换成DataFrame
json=[
{"age":18,"weight":"60"},
{"age":20,"weight":"70"},
]
print(pd.DataFrame(json,index=["jack","rose"]))
#DataFrame转换成numpy
print(a.to_numpy())
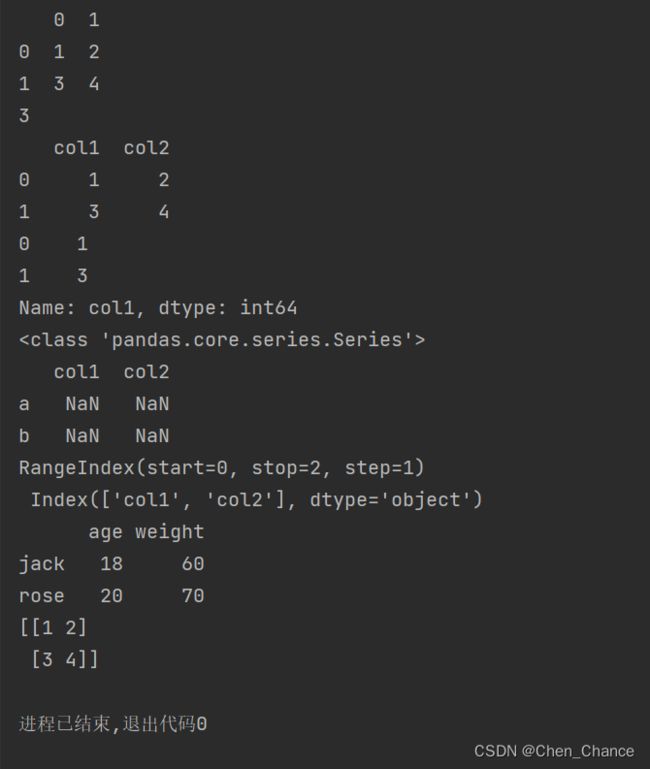
我们发现有一处的值都是Nan,这是什么原因,我们先定位到是哪个语句出了问题
# 由Series创建DataFrame
print(pd.DataFrame({"col1":pd.Series([1,3]),"col2":pd.Series([2,4])},index=["a","b"]))
在这段代码中,创建了一个新的 pandas DataFrame,但在创建过程中似乎存在一个问题,导致数据出现NaN(Not a Number)。让我来解释问题所在:
你尝试创建一个DataFrame,其中包含两列(“col1"和"col2”),并且给定了index参数来指定行的索引,索引为[“a”, “b”]。但是,问题在于,你的数据中包含的是pd.Series对象,并且这两个Series对象的索引与你的DataFrame的索引不匹配。
默认情况下,pandas会根据索引来对齐数据。由于你的两个Series对象没有与DataFrame索引[“a”, “b”]匹配的索引标签,所以在对齐数据时,会导致所有值都变成NaN。
要解决这个问题,你可以通过确保你的pd.Series对象具有与DataFrame索引匹配的索引标签,或者使用NumPy数组等其他数据结构来创建DataFrame。以下是两种可能的解决方法:
- 确保索引匹配:
import pandas as pd
data = {"col1": pd.Series([1, 3], index=["a", "b"]),
"col2": pd.Series([2, 4], index=["a", "b"])}
df = pd.DataFrame(data)
print(df)
- 使用NumPy数组创建DataFrame:
import pandas as pd
import numpy as np
data = {"col1": np.array([1, 3]),
"col2": np.array([2, 4])}
df = pd.DataFrame(data, index=["a", "b"])
print(df)
这样,你将能够创建一个包含正确数据的DataFrame,而不会出现NaN值。
选取数据
我们先准备一个DataFrame
import pandas as pd
import numpy as np
data=np.arange(-12,12).reshape(6,4)
a=pd.DataFrame(data,index=list("abcdef"),columns=list("ABCD"))
print(a)

选Column
看到了上面这份数据后,我们发现,DataFrame 会分 Column 和 Row(index)。如果你搞机器学习,通常我们的 Column 是特征,Row 是数据样本, 在要对某个特征进行分析的时候,比如要做特征数值分布的分析,我们得把特征取出来吧。 那么你可以这么做。
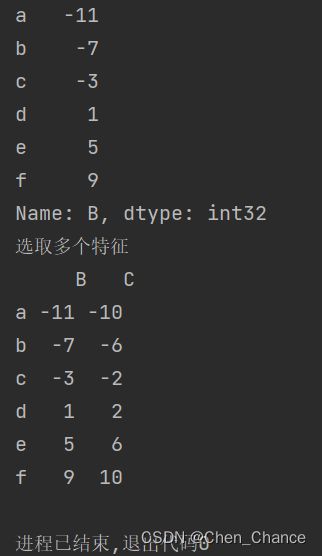
#选取一个特征
print(a["B"])
#选取多个特征
print("选取多个特征","\n",a[["B","C"]])
loc(通过自定义的序号索引)
# loc选择指定行和列
print(a.loc["a":"c","B":"C"])
# loc选定指定行所有内容
print(a.loc[["a","c"],:])

iloc(通过默认的序号索引)
# iloc选择指定行列
print(a.iloc[2:3,1:3])
#iloc选择指定行所有内容
print(a.iloc[[3,1],:])

loc和iloc混搭
有时候,我们需要混搭 loc 和 iloc 的方式,比如我想要选取第 2 到第 4 位数据的 A C 两个特征,采用索引转换的方式,比如我在 .loc 模式下,将序号索引转换成 .loc 的标签索引。
# 转换成loc,即把索引都转成默认数字索引
row_labels=a.index[2:4]
print(row_labels)
print(a.loc[row_labels,["A","C"]])
col_labels = a.columns[[0, 3]]
print(col_labels)
print(a.loc[row_labels,col_labels])
# 转换成iloc,即把索引都转成自定义的索引
col_index=a.columns.get_indexer(col_labels)
print(col_index)
row_index=a.index.get_indexer(row_labels)
print(row_index)
print(a.iloc[row_index,col_index])
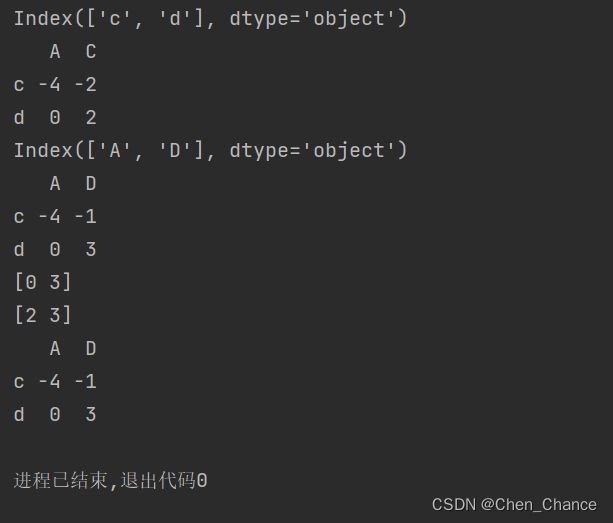
条件过滤筛选
选在 A Column 中小于 0 的那些数据
print(a["A"]<0)
print(a[a["A"]<0])
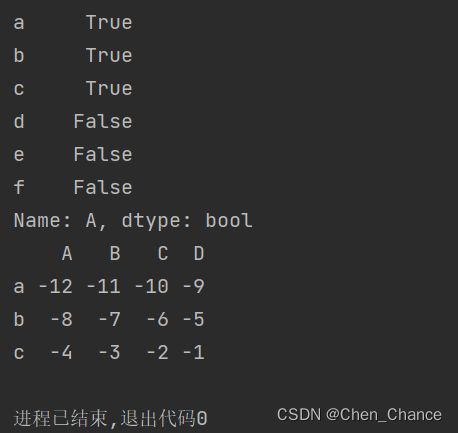
选在第一行数据不小于 -10 的数据
print(a.loc[:,~(a.iloc[0]<-10)])
#等价于
print(a.loc[:,a.iloc[0]>=-10])
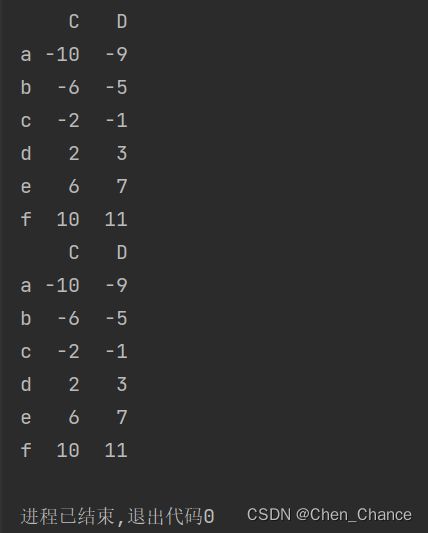
选在第一行数据不小于 -10 或小于 -11 的数据
i0=a.iloc[0]
print(i0)
print(a.loc[:,~(i0<-10)|(i0<-11)])

小插曲
print(a.iloc[:,~(a.iloc[0]<-10)])
如果用的是iloc,即上面这段代码执行时,就会报错
loc 的行索引可以接受布尔值,用于筛选行数据。当你传递一个布尔Series给 loc 的行索引时,它将返回满足条件为True的行。这是一种非常有用的功能,可以用来根据某些条件选择DataFrame中的行。
例如,假设你有一个DataFrame df,你可以使用布尔索引来选择满足某些条件的行,如下所示:
# 创建一个布尔Series,选择年龄大于30的行
condition = df['年龄'] > 30
# 使用布尔索引选择满足条件的行
selected_rows = df.loc[condition]
# 打印满足条件的行
print(selected_rows)
在上面的示例中,condition 是一个布尔Series,它选择了DataFrame中年龄大于30的行,然后通过 df.loc[condition] 来选择这些行。这将返回一个包含满足条件的行的新DataFrame。
所以,loc 的行索引可以接受布尔值,用于基于条件选择行。
iloc 通常不用于接受布尔值来选择行。它主要用于基于整数位置来选择数据,而不是基于条件或布尔值来选择数据。
如果你想使用布尔值来选择行,通常应该使用 loc。使用布尔索引和 loc 结合可以方便地根据条件筛选行数据,如我在前面的回答中所示。对于 iloc,通常使用整数索引或整数切片来选择行和列,而不是布尔值索引。
例如,以下是一个使用 iloc 来选择前三行的示例:
selected_rows = df.iloc[0:3, :]
在这个示例中,iloc 使用整数切片选择了前三行,而不是基于布尔条件选择。如果你想基于条件选择行,请使用 loc。
总而言之,loc的行索引可以用布尔值,但是iloc不可以,这也就是出错的原因
因为当我们执行这段代码时,会发现结果是布尔值
print(~(a.iloc[0]<-10))
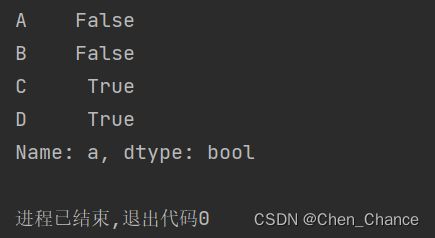
Series和DataFrame类似
我们同样先建一个Series
list_data=list(range(-4,4))
a=pd.Series(list_data,index=list("abcdefgh"))
print(a)
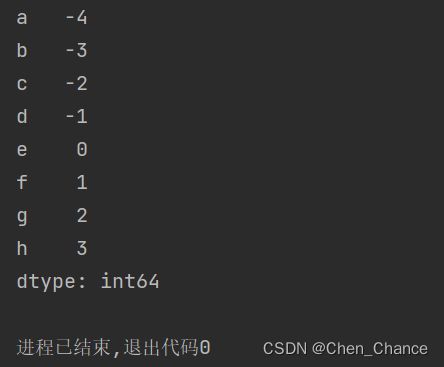
#按照标签选择数据loc
print(a.loc["a":"c"])
print(a.loc[["a","b"]])
#按照index选择数据iloc
print(a.iloc[2:4])
print(a.iloc[[3,1]])
#iloc和loc混用
print(a.iloc[a.index.get_indexer(["a","b"])])
print(a.index.get_indexer(["a","b"]))
print(a.loc[a.index[[3,2]]])
print(a.index[[3,2]])
#按照条件过滤筛选
print(a.loc[a<-3])
print(a.loc[(a>-3)&(a<3)])
print(a.loc[(a<-3)|(a>2)])

统计展示
基础统计方法
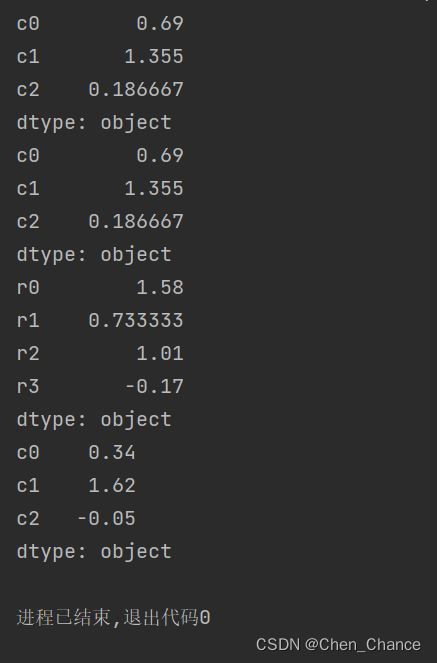
数据
import pandas as pd
import numpy as np
data=np.array([
[1.39, 1.77, None],
[0.34, 1.91, -0.05],
[0.34, 1.47, 1.22],
[None, 0.27, -0.61]
])
a=pd.DataFrame(data,index=["r0","r1","r2","r3"],columns=["c0","c1","c2"])
print(a)

快速总结
print(a.describe())

这里,会显示出来 count 计数(剔除掉 None 或者 NAN 这种无效数据),所以你在结果中能看到 c0,c2 两个的有效数是 3 个,而 c1 有效数有 4 个。
unique 表示的是每个 column 中有多少独特的数据。这个在初步感知数据丰富度上会有一定的作用。
top 表示出现最多的数据是哪一个,这组数据在 c0 column 处,我们能观察到 0.34 出现了两次,所以它选的 top 是 0.34,如果出现的数字概率相同,则选最先出现的数字
freq 是继续了 top,表述的是这个出现频率最多的数据,出现的次数有多少次。
上面这份数据还不是纯数据,如果是存数值型的数据,我们跑 describe() 还能看到统计学的信息。
a=pd.DataFrame(np.random.random((4,3)),columns=["c0","c1","c2"])
print(a)
print(a.describe())
创建了一个包含4行和3列的DataFrame,其中每个元素都是从0到1之间的随机数。然后,你使用 a.describe() 方法来生成关于这个DataFrame中数值列的统计摘要。以下是你的代码输出和结果的解释:
首先,创建了一个DataFrame a,它包含4行和3列的随机数。这是你的DataFrame的内容:
c0 c1 c2
0 0.412172 0.409382 0.289723
1 0.289591 0.943983 0.319834
2 0.834625 0.394380 0.121346
3 0.592600 0.340653 0.239218
接下来,使用 a.describe() 来生成统计摘要,结果如下:
c0 c1 c2
count 4.000000 4.000000 4.000000
mean 0.532997 0.522849 0.242030
std 0.229065 0.272370 0.102891
min 0.289591 0.340653 0.121346
25% 0.386007 0.389205 0.221967
50% 0.502386 0.401881 0.264471
75% 0.649376 0.535525 0.284533
max 0.834625 0.943983 0.319834
解释每一行统计信息:
count表示每列的非缺失值数量,由于这是随机生成的数据,因此每列都有4个非缺失值。mean表示每列的平均值。例如,‘c0’ 列的平均值约为0.533。std表示每列的标准差,衡量数据的离散程度。例如,‘c1’ 列的标准差约为0.272。min和max分别表示每列的最小值和最大值,即数据范围。25%、50%和75%分别表示第25、50和75百分位数,它们对应于数据的第一四分位数、中位数和第三四分位数。这些百分位数可用于了解数据的分布。
均值中位数
print(a.mean())
#对a的第0个维度求均值
print(a.mean(axis=0))
#对a的第1个维度求均值
print(a.mean(axis=1))
# 跳过 None 或者 NaN的数据的某列或某行(这段代码后面再修改,有些没弄清楚的地方)
# print(a.mean(axis=0,skipna=False))
#求中位数
print(a.median())
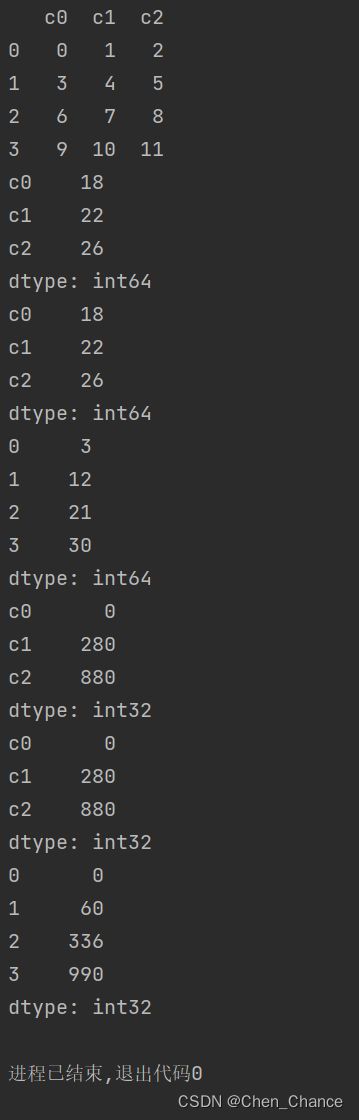
累加累乘
a=pd.DataFrame(np.arange(12).reshape((4,3)),columns=["c0","c1","c2"])
print(a)
# 累加
print(a.sum())
print(a.sum(axis=0))
print(a.sum(axis=1))
# 累乘
print(a.prod())
print(a.prod(axis=0))
print(a.prod(axis=1))
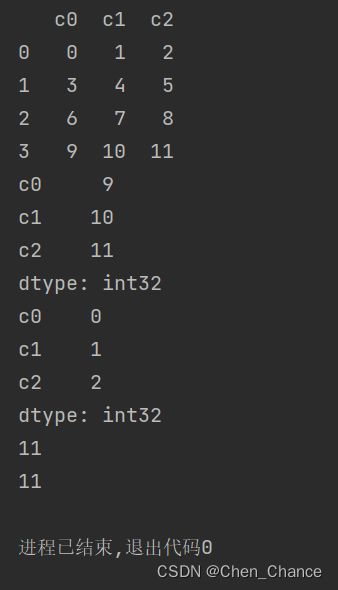
最大最小
a=pd.DataFrame(np.arange(12).reshape((4,3)),columns=["c0","c1","c2"])
print(a)
# 对一个维度进行最大最小值的找取
print(a.max())
print(a.min())
# 找全局的最大最小值
print(a.max().max())
print(a.values.ravel().max())
最后两行代码是用来获取一个数据结构(可能是一个NumPy数组或Pandas DataFrame)中的最大值,并且使用了不同的方法来实现相同的目标。让我们一一解释这两行代码:
-
print(a.max().max()):a可能是一个二维的数据结构,比如一个NumPy数组或Pandas DataFrame。a.max()这一部分首先计算a中每列的最大值(如果是DataFrame的话,这将是每个列的最大值),并将结果返回为一个新的数据结构,可能是一个NumPy数组或Pandas Series,其最大值是该列的最大值。.max()第二次调用max()方法,这次是在上一步结果的基础上,计算最大值,即计算所有列的最大值的最大值,返回一个标量值。
-
print(a.values.ravel().max()):a可能是一个NumPy数组或Pandas DataFrame。a.values是一个将NumPy数组或DataFrame转换为NumPy数组的属性。它将数据结构转换为一个二维数组,其中每个元素对应于原始数据结构中的元素。.ravel()是NumPy中的一个函数,用于将多维数组转换为一维数组,即将数组展平。- 最后,
.max()用于计算展平后的一维数组中的最大值,返回一个标量值,即数组中的最大元素。
总结:这两行代码都是为了获取给定数据结构中的最大值,但它们使用了不同的方法。第一行代码首先计算每列的最大值,然后找到这些最大值中的最大值。第二行代码将数据展平为一维数组,然后计算该一维数组中的最大值。这两种方法都可以用来找到数据结构中的最大值,但是根据具体的情况和数据类型选择合适的方法。
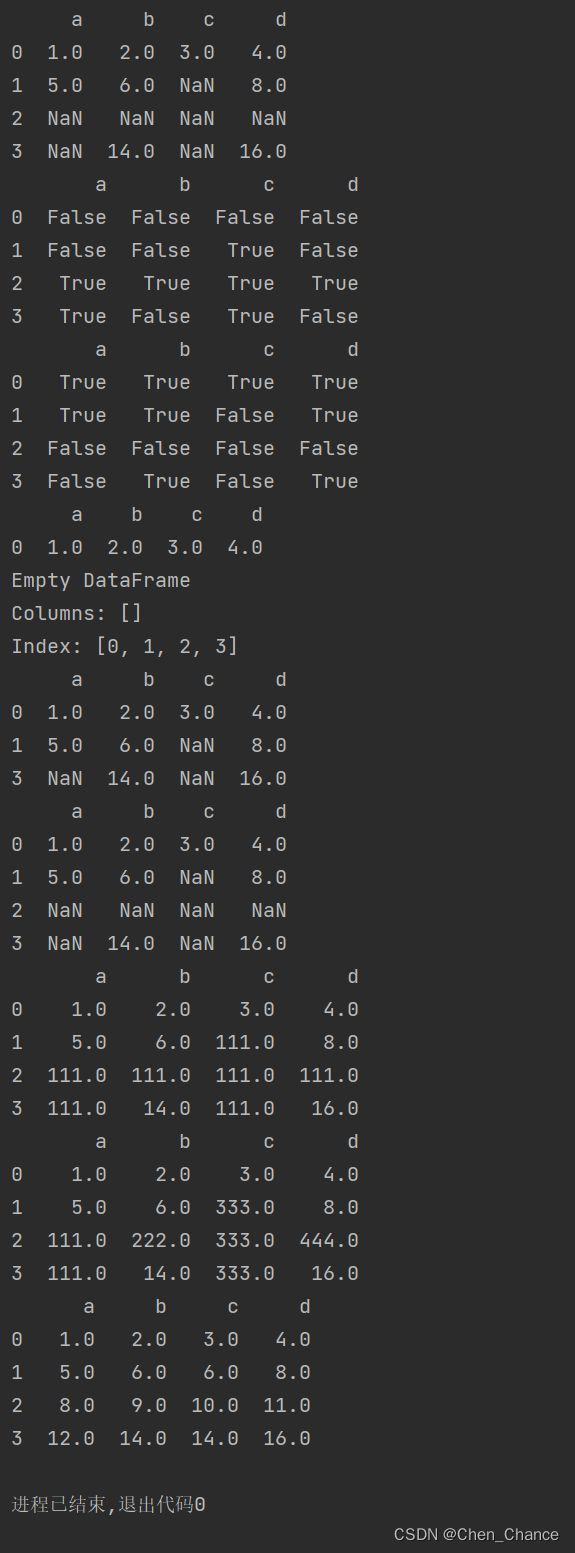
处理空值
a=pd.DataFrame([[1,2,3,4],
[5,6,None,8],
[None,None,None,None],
[None,14,None,16]],columns=list("abcd"))
print(a)
print(a.isnull())#true为空
print(a.notnull())#flase为空
# 放弃有空值的数据的整行
print(a.dropna())
#放弃有空值数据的整列
print(a.dropna(axis=1))
# 有值留下来,只去掉全为空的整行的数据
print(a.dropna(how="all"))
# 有值留下来,只去掉全为空的整列的数据
print(a.dropna(how="all",axis=1))
# 对空值进行填充
print(a.fillna(111))
# 对不同特征做差异化的填充数据
b={"a":111,"b":222,"c":333,"d":444}
print(a.fillna(value=b))
# 你甚至可以用一个全新的DataFrame来做空值的填充
b=pd.DataFrame(np.arange(16).reshape((4,4)),columns=list("abcd"))
print(a.fillna(b))
获取索引
a=pd.DataFrame([[1,2,3,0],
[3,4,None,1],
[3,5,2,1],
[3,2,2,3]],
columns=list("abcd"))
print(a)
print(a.idxmax())
print(a.idxmin())
print(a.idxmax(skipna=False))

绘制图表
散点图Scatter
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
n=128 #数据数量
a=pd.DataFrame({
"x":np.random.normal(0,1,n),
"y":np.random.normal(0,1,n),
})
color=np.arctan2(a["y"],a["x"])
a.plot.scatter("x","y",c=color,s=60,alpha=0.5,cmap="rainbow")
plt.show()
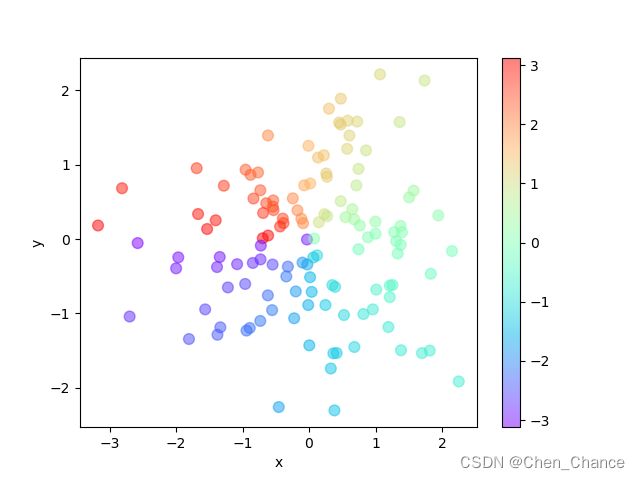
这段代码使用NumPy、Pandas和Matplotlib库生成一个散点图,其中包含128个数据点,每个数据点由两个随机正态分布的值(x和y坐标)组成。以下是代码的详细解释:
-
import numpy as np:导入NumPy库,并为其取一个别名np,以便在代码中使用更短的名称引用库中的函数和对象。 -
import pandas as pd:导入Pandas库,并为其取一个别名pd,以便在代码中使用更短的名称引用库中的函数和对象。 -
import matplotlib.pyplot as plt:导入Matplotlib库中的pyplot模块,并为其取一个别名plt,以便在代码中使用更短的名称引用该模块中的函数。 -
n = 128:定义变量n,表示数据点的数量,本例中为128。 -
a = pd.DataFrame(...):创建一个Pandas DataFrame对象a,其中包含两列数据:"x"列和"y"列。这两列数据分别使用NumPy的np.random.normal()函数生成,该函数用于生成服从正态分布(均值为0,标准差为1)的随机数。因此,DataFramea包含128行,每行有一个x和y坐标。 -
color = np.arctan2(a["y"], a["x"]):计算每个数据点的颜色值。np.arctan2()函数用于计算每个数据点的极坐标角度,其参数分别是y坐标和x坐标,结果表示颜色映射中的角度值。 -
a.plot.scatter("x", "y", c=color, s=60, alpha=0.5, cmap="rainbow"):使用Pandas DataFrame的plot.scatter()方法创建散点图。具体参数如下:"x"和"y":分别指定x轴和y轴的数据列。c=color:使用上面计算的颜色值来指定每个点的颜色。s=60:指定散点的大小为60。alpha=0.5:指定点的透明度为0.5,使得点具有一定的透明度。cmap="rainbow":指定颜色映射为"rainbow",这将使不同的角度值映射到不同的颜色。
-
plt.show():最后,使用Matplotlib的show()函数显示散点图。
综上所述,这段代码生成了一个具有128个随机数据点的散点图,每个点的位置由DataFrame a 中的"x"和"y"列确定,颜色由极坐标角度确定。这种可视化方式可以用于显示数据点之间的分布和关系。
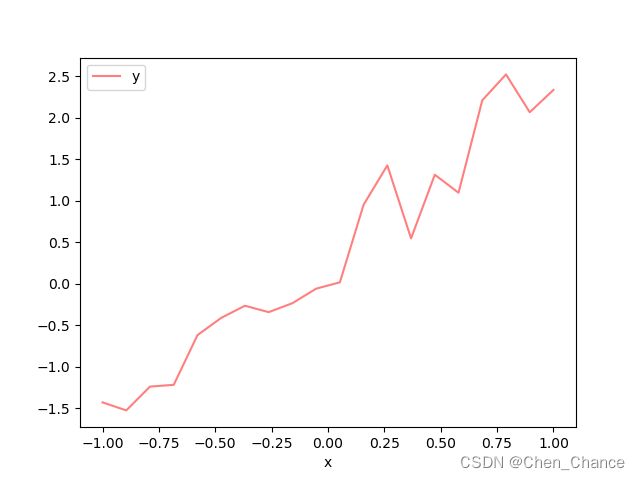
折线图Plot
# 绘制单条线
n=20
x=np.linspace(-1,1,n)
y=x*2+0.4+np.random.normal(0,0.3,n)
a=pd.DataFrame({"x":x,"y":y})
a.plot(x="x",y="y",alpha=0.5,c="r")
plt.show()
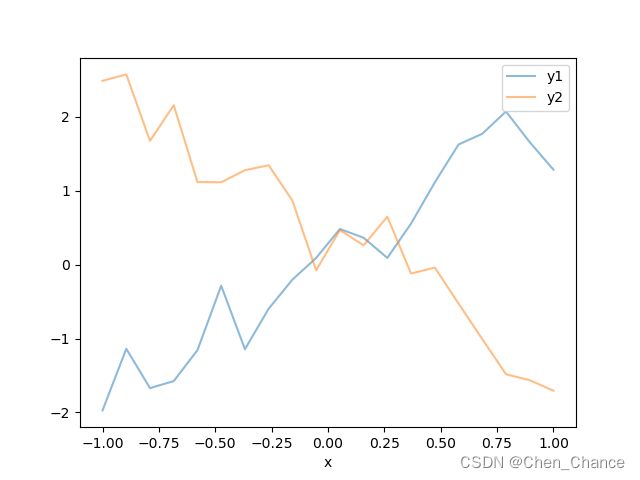
#绘制多条线
n=20
x=np.linspace(-1,1,n)
y1=x*2-0.1+np.random.normal(0,0.3,n)
y2=x*(-2)+0.4+np.random.normal(0,0.3,n)
a=pd.DataFrame({
"x":x,
"y1":y1,
"y2":y2
})
a.plot(x="x",y=["y1","y2"],alpha=0.5)
plt.show()
条形图Bar
# 看5组数据,每组还有3个数据
a=pd.DataFrame(np.random.rand(5,3),columns=list("abc"))
a.plot.bar()
plt.show()
# 把每行的3列数据放在一列上看
a.plot.bar(stacked=True)
plt.show()
# 我想横着看
a.plot.barh()
plt.show()
分布图Hist
# 单个分布图
b=np.random.normal(0,0.3,100)
a=pd.DataFrame({"a":b})
a.plot.hist()
plt.show()
#多个分布图重合
a=pd.DataFrame(
{
"a":np.random.randn(10)+1,
"b":np.random.randn(10),
"c":np.random.rand(10)-4
}
)
# bins=20:这是一个可选参数,用于指定直方图的柱子(条形)数量。
# 在这里,设置为20,表示将数据范围分成20个区间,
# 并在每个区间内绘制直方图的柱子。这可以控制直方图的分辨率,
# 使你可以更清晰地看到数据的分布情况。
a.plot.hist(alpha=0.5,bins=20)
plt.show()

饼图Pie
# 画一个饼状图
a=pd.DataFrame(
{"boss":np.random.rand(4)},
index=["meeting","supervise","teaching","study"]
)
print(a)
# figsize=(7, 7):这是一个可选参数,用于指定绘制的图形的尺寸。
# 在这里,设置为(7, 7),表示饼图将以7x7的尺寸绘制,
# 以确保饼图具有适当的大小。
a.plot.pie(y="boss",figsize=(7,7))
plt.show()
# 画多个饼状图
a=pd.DataFrame(
{"boss":np.random.rand(4),
"smallboss":np.random.rand(4)},
index=["meeting","supervise","teaching","study"]
)
a.plot.pie(subplots=True,figsize=(9,9))
plt.show()
面积图Area
a=pd.DataFrame(
np.random.rand(10,4),
columns=list("abcd")
)
print(a)
a.plot.area()
plt.show()
# 不想堆砌起来,起点我想统一
a.plot.area(stacked=False)
plt.show()
数据处理
运算方法
筛选赋值运算
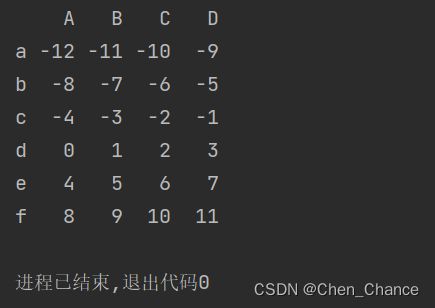
先新建一个数据
import pandas as pd
import numpy as np
data=np.arange(-12,12).reshape((6,4))
a=pd.DataFrame(
data,
index=list("abcdef"),
columns=list("ABCD")
)
print(a)
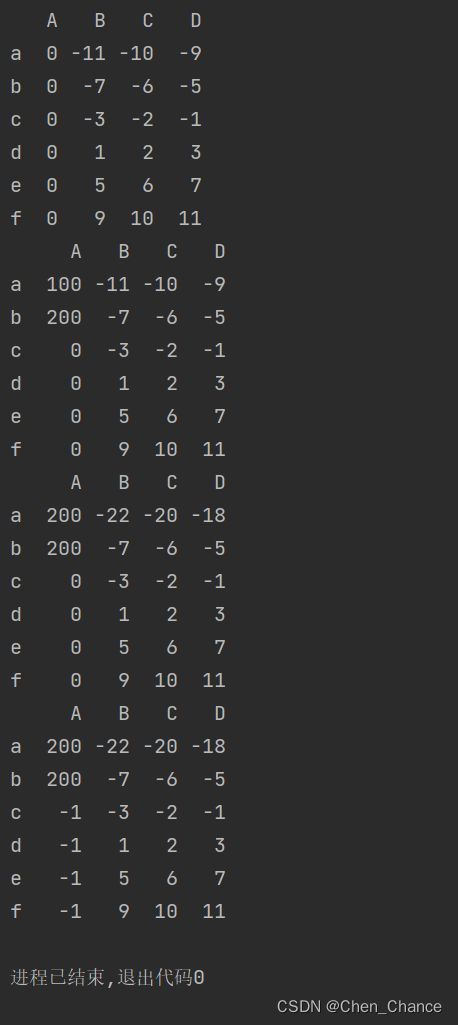
# 对第一列×0
a["A"]*=0
print(a)
#iloc 找的是 index,loc 找的是标签
a.loc["a","A"]=100
a.iloc[1,0]=200
print(a)
a.loc["a",:]=a.loc["a",:]*2
print(a)
a["A"][a["A"]==0]=-1
print(a)
这行代码a["A"][a["A"]==0]=-1对Pandas DataFrame(假设为a)进行了一系列操作,让我来解释它的作用:
-
a["A"]:首先,从DataFramea中选择名为"A"的列,这是一个Series对象,包含了列"A"的所有值。 -
[a["A"] == 0]:使用布尔索引,这部分代码将返回一个与列"A"具有相同索引的布尔Series,其中每个元素的值为True或False,取决于对应位置的元素是否等于0。换句话说,它会创建一个布尔掩码,用于筛选出列"A"中值为0的行。 -
= -1:最后,这部分代码将列"A"中值为0的行,使用赋值操作将它们的值改为-1。换句话说,它将DataFrame中所有等于0的值替换为-1。
总结起来,这行代码的作用是将DataFrame df 中名为"A"的列中所有等于0的值替换为-1。这种操作通常用于数据预处理,以将特定值替换为其他值,以符合分析或可视化的需求。
Apply方法
针对数据做自定义功能的运算
先构建一个数据
a=pd.DataFrame([[1,2]]*3,columns=["A","B"])
print([[1,2]]*3)
print(a)

# 对a做平方根运算
print(np.sqrt(a))
#用apply方法
print(a.apply(np.sqrt))
# 看上去apply似乎更麻烦了,但是别急,他的强大之处还在后面
def func(x):
return x[0]*2,x[1]+1
print(a.apply(func,axis=1))
# "expand" 表示要扩展函数的返回值,以便每个返回值都成为一个新的列。
print(a.apply(func,axis=1,result_type="expand"))
# reult_type="broadcast",
# 那么原 column 和 index 名会继承到新生成的数据中
print(a.apply(func,axis=1,result_type="broadcast"))
# 只改一个 column
def func(x):
return x["A"]*10
print(a.apply(func,axis=1))
# 返回原a,但只有一个 column 被修改了
a["A"]=a.apply(func,axis=1)
print(a)

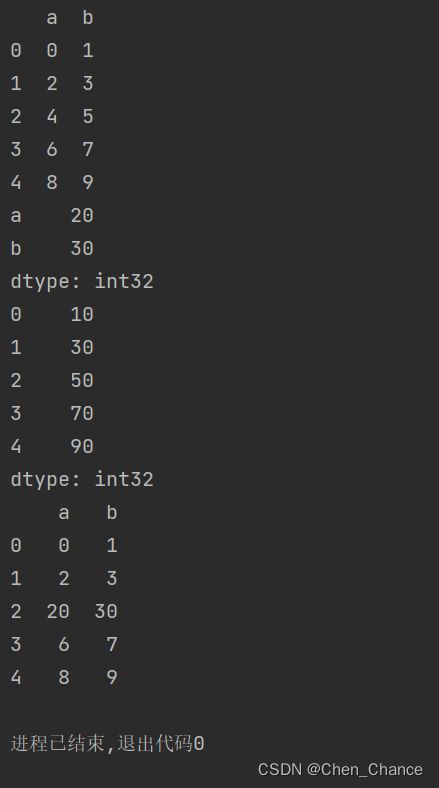
# 对row进行操作
a=pd.DataFrame(np.arange(10).reshape((5,2)),columns=list("ab"))
print(a)
def func(r):
return r[1]*10
last_row=a.apply(func,axis=0)
print(last_row)
# 对比看下axis=0和1的区别
b=a.apply(func,axis=1)
print(b)
a.iloc[2,:]=last_row
print(a)
文字处理
格式化字符
#先对标python中自带的文字处理功能
import pandas as pd
py_s = "A,B,C,Aaba,Baca,CABA,dog,cat"
pd_s = pd.Series(
["A", "B", "C", "Aaba", "Baca", "CABA", "dog", "cat"],
dtype="string")
print(py_s.upper())
print(pd_s.str.upper())
# 注意如果要用到 Pandas 丰富的文字处理功能,
# 你要确保 Series 或者 DataFrame 的 dtype="string"
#如果不是我们要调整到string格式
pd_not=pd.Series(
["A", "B", "C", "Aaba", "Baca", "CABA", "dog", "cat"],
)
print(pd_not.dtype)
pd_s=pd_not.astype("string")
print(pd_s.dtype)
# 我们接着对比python功能
print(py_s.lower())
print(pd_s.str.lower())
print([len(s) for s in py_s.split(",")])
print(pd_s.str.len())
# 对比对文字的裁剪
# str.strip() : 去除字符串两边的空格
# str.lstrip() : 去除字符串左边的空格
# str.rstrip() : 去除字符串右边的空格
py_s=[" jack","jill "," jesse ","frank"]
pd_s=pd.Series(py_s,dtype="string")
print([s.strip() for s in py_s])
print(pd_s.str.strip())
print([s.lstrip() for s in py_s])
print(pd_s.str.lstrip())
print([s.rstrip() for s in py_s])
print(pd_s.str.rstrip())
# 对比split拆分的方法
py_s = ["a_b_c", "jill_jesse", "frank"]
pd_s = pd.Series(py_s, dtype="string")
print([s.split("_") for s in py_s])
print(pd_s.str.split("_"))
print(pd_s.str.split("_",expand=True))
#DataFrame也是一样的
pd_df=pd.DataFrame([["a","b"],["c","d"]])
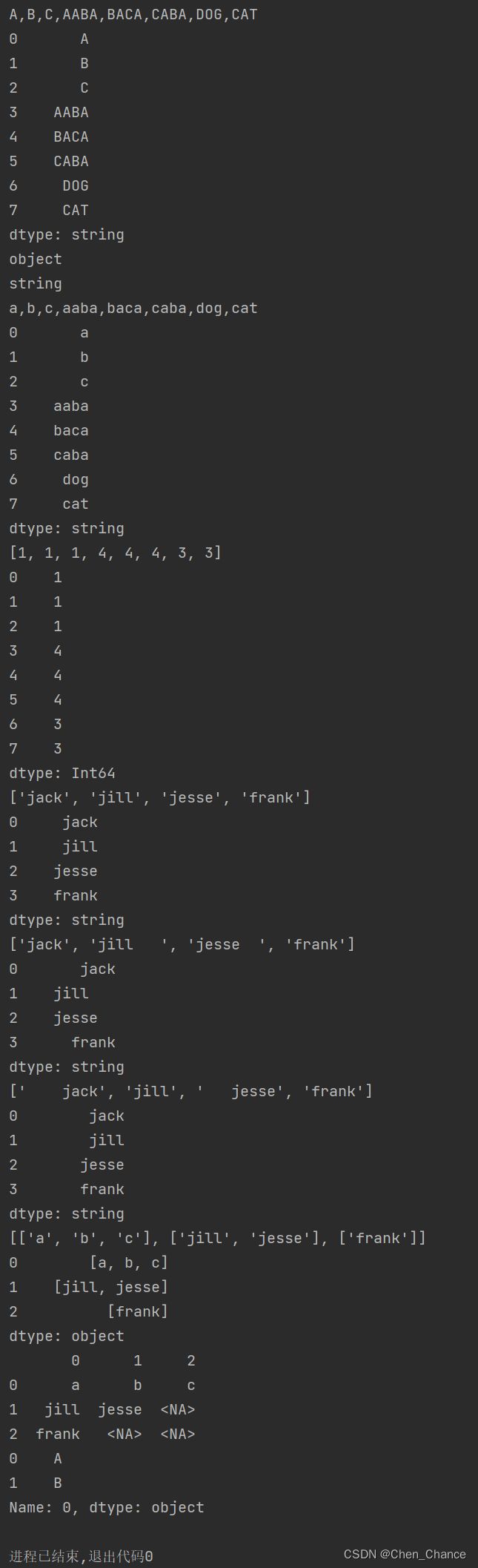
print(pd_df.iloc[0,:].str.upper())
正则方案
先跳过
拼接
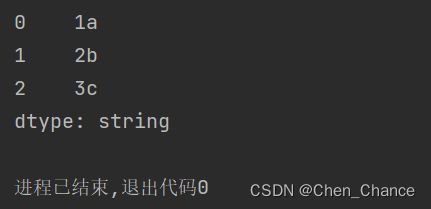
# 拼接
s1=pd.Series([1,2,3],dtype="string")
s2=pd.Series(["a","b","c"],dtype="string")
print(s1.str.cat(s2))
更专业的更多的方法会在后续段落写出,实在太多了
异常数据处理
找到NaN数据
我们先生成一份带NaN的数据
import pandas as pd
import numpy as np
a=pd.DataFrame([[1,None],[np.nan,4]])
print(a)

#找哪些是NaN
print(a.isna())
#找哪些不是NaN
print(a.notna())

NaN的影响
a=pd.DataFrame({"a":[1,None,1],
"b":[np.nan,4,4]
})
print(a.mean(axis=0))
print(a.mean(axis=0,skipna=False))

移除NaN
# 选择要施加的 axis 比如 axis=0 的时候,
# 如果某一 row 有 NaN,就会丢弃这一 row。
# 同理 axis=1 的时候, column 有 NaN 丢弃 column,
a=pd.DataFrame({"a":[1,None,3],
"b":[4,5,6]})
print(a.dropna(axis=0))
print(a.dropna(axis=1))

填充NaN
a=pd.DataFrame({
"a":[1,None,3],
"b":[4,5,6]
})
a_mean=a["a"].mean()
new_col=a["a"].fillna(a_mean)
a["a"]=new_col
print(a)
# a column 和 b column 是有一定关系的,
# 用b的值去替代a的值
a=pd.DataFrame({
"a":[1,None,3,None],
"b":[4,8,12,12]
})
a_nan=a["a"].isna()
a_new_value=a["b"][a_nan]/4
print(a_new_value)
new_col=a["a"].fillna(a_new_value)
a["a"]=new_col
print(a)
# 也可以这样子
a.loc[a_nan,"a"]=a["b"][a_nan]/4
print(a)

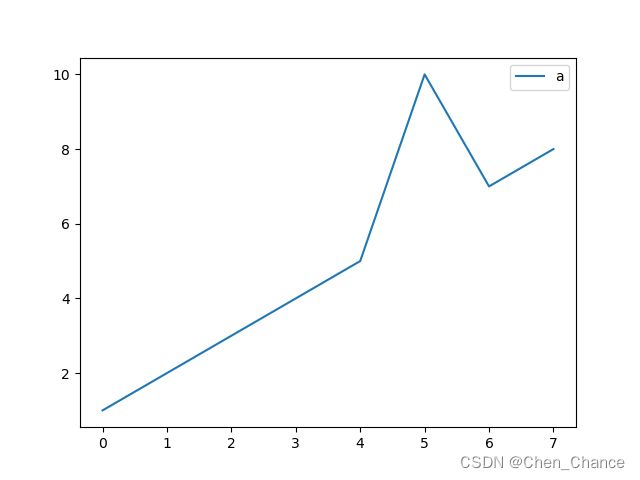
不符合范围的值
import matplotlib.pyplot as plt
a=pd.DataFrame({
"a":[1,2,3,4,5,100,7,8]
})
a.plot()
plt.show()
a["a"]=a["a"].clip(lower=0,upper=10)
a.plot()
plt.show()

时间数据
读时间序列数据
import pandas as pd
a=pd.DataFrame({
"time":["2022/03/12","2022/03/13","2022/03/14"],
"valte":[1,2,3]
})
print(a)
print(a["time"])
# 现在,Pandas 是不知道 time 这个 column 是时间序列的(现在认为它是 object),
# 我们需要告诉 Pandas 把这个 time 套上时间序列的标识。
print(pd.to_datetime(a["time"]))
# 还可以自己创造区分规则
a=pd.to_datetime(
[
"1@21@2022%%11|11|32",
"12@01@2022%%44|02|2",
"4@01@2022%%14|22|2"
],
format="%m@%d@%Y%%%%%S|%H|%M"
)
print(a)

| 命令 | 含义 |
|---|---|
| %m | 月 |
| %d | 日 |
| %Y | 年 |
| %% | |
| %S | 秒 |
| %H | 时 |
| %M | 分 |
自建时间序列
import datetime
start=datetime.datetime(2022,3,12)
end=datetime.datetime(2022,3,18)
# 类似列表的range
index=pd.date_range(start,end)
print(index)
print(pd.date_range(start,end,freq="48h"))
# 类似列表的linespace
print(pd.date_range(start,end,periods=5))

选取时间
import datetime
import matplotlib.pyplot as plt
start=datetime.datetime(2022,3,1)
end=datetime.datetime(2022,5,3)
rng=pd.date_range(start,end)
# 这一行代码使用numpy库生成与时间范围长度相同的随机数,并将这些随机数创建成一个pandas时间序列(Series)。
# 时间序列的索引使用了前面创建的时间范围rng,并且每个日期都对应一个随机数值。
ts=pd.Series(np.random.rand(len(rng)),index=rng)
print(ts)
# 画图展示
ts.plot()
plt.show()
# 画图展示少量数据
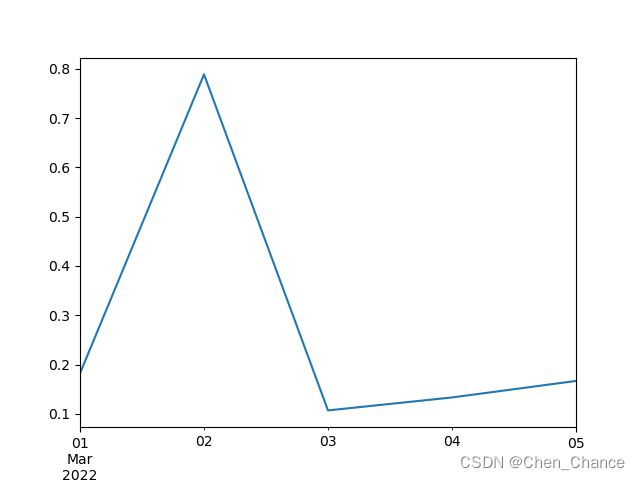
ts[:5].plot()
plt.show()
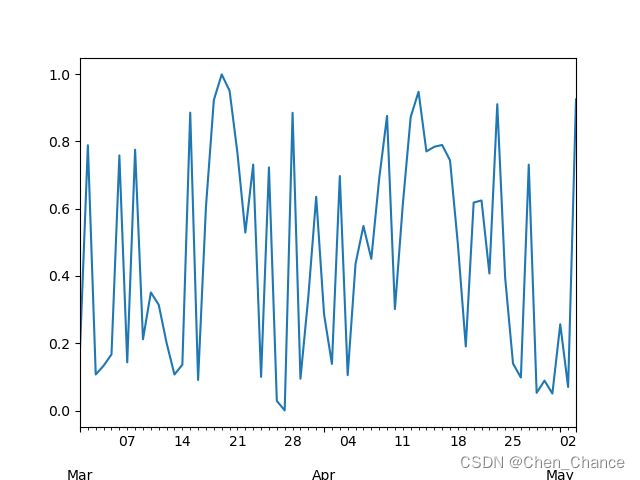
# 用index切片不知道对应的日期,我们试试用时间切片
t1=datetime.datetime(2022,3,1)
t2=datetime.datetime(2022,3,18)
ts[t1:t2].plot()
plt.show()
# 还可以直接写日期
ts["2022-03-12":"2022-03-18"].plot()
plt.show()
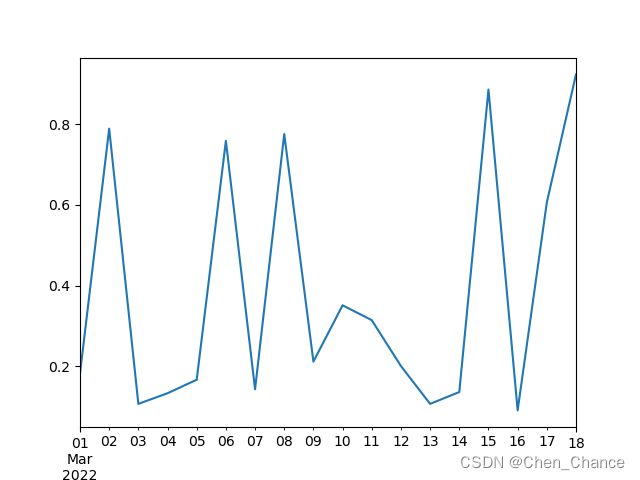
# 还可以只看某个月的
ts["2022-03"].plot()
plt.show()



时间运算
# 日期加上一个时间
rng=pd.date_range("2022-01-01","2022-01-07")
print(rng+pd.Timedelta(weeks=1))
# Timedelta可以乘除
print(rng+2*pd.Timedelta(weeks=1))
rng=pd.date_range("2022-02-08","2022-02-11")
# 这一行代码打印了rng中每个日期的年内第几天。dayofyear是DatetimeIndex对象的属性,
# 用于获取每个日期在年内的天数。结果将显示每个日期在年内的第几天。
print(rng.dayofyear)
# 按制定规则输出日期形式
print(rng.strftime("%m/%d/%Y"))
时区
rng=pd.date_range("2022-01-08","2022-01-11")
# 默认生成的时候,是不带时区的。
# tz属性用于获取DatetimeIndex对象的时区信息。如果tz属性为None,则表示该日期范围不具有时区信息。
print(rng.tz)
s=pd.to_datetime(["2022/03/12 22:11","2022/03/13 12:11","2022/03/14 2:11"])
s_us=s.tz_localize("America/New_York")
print(s_us)
s_cn=s_us.tz_convert("Asia/Shanghai")
print(s_cn)
# 你要获取对应的时区名称,你可以用 pytz 这个库来看
import pytz
print(pytz.country_timezones("CN"))
rng=pd.date_range("2022-01-08","2022-01-11",tz="America/New_York")
print(rng)
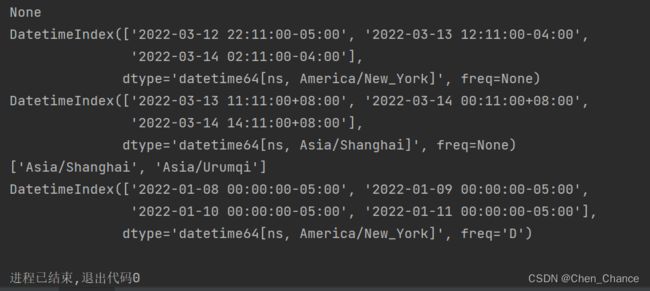
这里有人会发现美国一会儿-4,一会儿-5,这是为什么?
DatetimeIndex(['2022-03-12 22:11:00-05:00', '2022-03-13 12:11:00-04:00',
'2022-03-14 02:11:00-04:00'],
dtype='datetime64[ns, America/New_York]', freq=None)
这是一个DatetimeIndex对象,其中包含了三个日期时间值,这些日期时间已经本地化到美国纽约时区(Eastern Standard Time,EST,或Eastern Daylight Time,EDT)。
-
第一个日期时间是"2022-03-12 22:11:00-05:00",表示2022年3月12日晚上22:11(EST)。
-
第二个日期时间是"2022-03-13 12:11:00-04:00",表示2022年3月13日中午12:11(EDT)。
-
第三个日期时间是"2022-03-14 02:11:00-04:00",表示2022年3月14日凌晨02:11(EDT)。
这些日期时间都带有时区信息,因此显示了与美国纽约时区相关的偏移量(-05:00 或 -04:00),取决于是否处于夏令时(Daylight Saving Time,DST)期间。这些日期时间对象的数据类型是datetime64[ns, America/New_York],指示它们的时区信息为"America/New_York"。
数据管理
融合数据
拼接Concat
import pandas as pd
df1 = pd.DataFrame({
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
}, index=[0, 1, 2, 3],)
df2 = pd.DataFrame({
"A": ["A4", "A5", "A6", "A7"],
"B": ["B4", "B5", "B6", "B7"],
"C": ["C4", "C5", "C6", "C7"],
"D": ["D4", "D5", "D6", "D7"],
}, index=[4, 5, 6, 7],)
df3 = pd.DataFrame({
"A": ["A8", "A9", "A10", "A11"],
"B": ["B8", "B9", "B10", "B11"],
"C": ["C8", "C9", "C10", "C11"],
"D": ["D8", "D9", "D10", "D11"],
}, index=[8, 9, 10, 11],)
print(df1,"\n",df2,"\n",df3)
print(pd.concat([df1,df2,df3]))
a=pd.concat([df1,df2,df3],
keys=["x","y","z"])
print(a)
print(a.loc["y"])
# pd.concat 的默认是上下拼接的,我们也可以指定进行左右拼接。这种模式叫做 join="outer" 的方式(默认方式)
df4 = pd.DataFrame({
"B": ["B2", "B3", "B6", "B7"],
"D": ["D2", "D3", "D6", "D7"],
"F": ["F2", "F3", "F6", "F7"],
}, index=[2, 3, 6, 7],)
print(pd.concat([df1,df4],axis=1))
# 我们还可以用内拼接 join="inner"
print(pd.concat([df1,df4],axis=1,join="inner"))
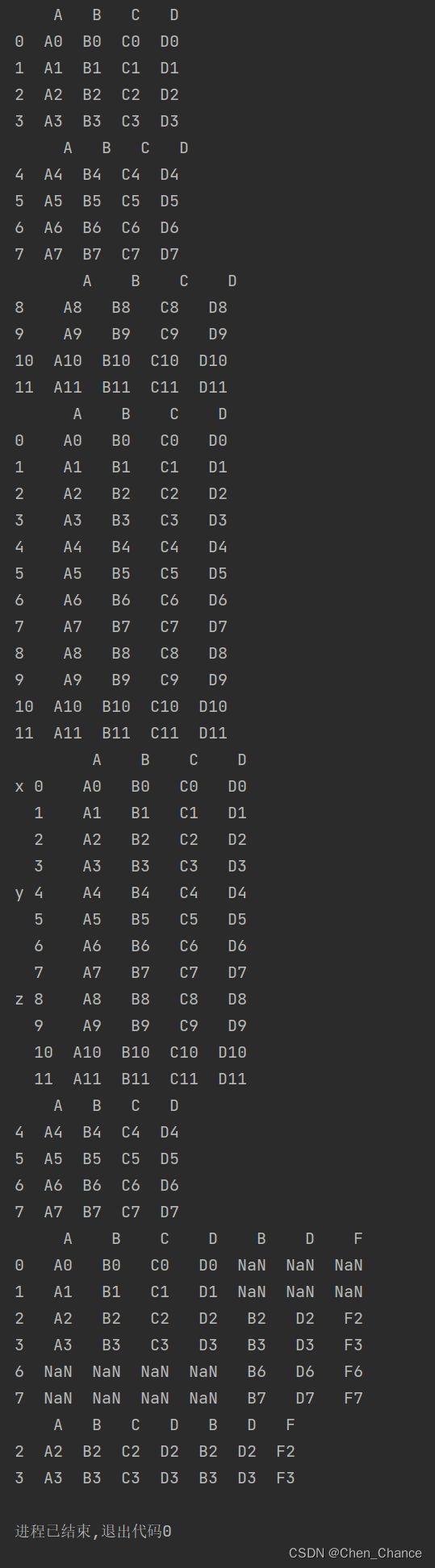
在 pandas 中,join="inner"和join="outer"是 DataFrame 上的两种不同类型的合并操作,通常用于将两个 DataFrame 进行合并。它们的主要区别在于如何处理合并操作中的缺失值以及保留哪些行和列。
-
join="inner":join="inner"表示内连接(inner join)。这种连接只会保留两个 DataFrame 中共有的行,即在连接键(通常是列)上存在匹配的行。- 只有当连接键在两个 DataFrame 中都存在时,才会保留该行。
- 结果中不包含任何来自输入 DataFrame 的缺失值。
-
join="outer":join="outer"表示外连接(outer join)。这种连接会保留两个 DataFrame 中的所有行,并在连接键上根据需要进行匹配。- 如果某一行在一个 DataFrame 中存在但在另一个 DataFrame 中不存在,仍然会保留。
- 结果中可能包含来自输入 DataFrame 的缺失值,因为不是所有行都会有匹配。
总之,join="inner"保留共有的行,而join="outer"保留所有行,填充缺失值。选择哪种连接方式取决于您的需求和数据的特点。
import pandas as pd
df1 = pd.DataFrame({
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
}, index=[0, 1, 2, 3],)
df4 = pd.DataFrame({
"B": ["B2", "B3", "B6", "B7"],
"D": ["D2", "D3", "D6", "D7"],
"F": ["F2", "F3", "F6", "F7"],
}, index=[2, 3, 6, 7],)
# ignore_index=True 表示在进行合并时忽略原来的索引,重新生成一个 RangeIndex。
# sort=False 表示在合并时不排序,保持原来的顺序。默认值就是False
a=pd.concat([df1,df4],
ignore_index=True,
sort=False)
print(a)
# 如何添加数据
new_col=pd.Series(
["X0","X1","X2","X3"],
name="X"
)
print(new_col)
print(pd.concat([df1,new_col],axis=1))
# 那如何向下添加呢
new_row=pd.Series(
["Y0","Y1","Y2","Y3"],
index=["A","B","C","D"]
)
# new_row.to_frame()会把这个Series转化为单列的DataFrame
# 这里有个问题就是为什么要转换成DataFrame呢,直接转置不是更方便吗?
# 应该是因为Series的数据转置是没有作用的
print(pd.concat([df1,new_row.to_frame().T],ignore_index=True))
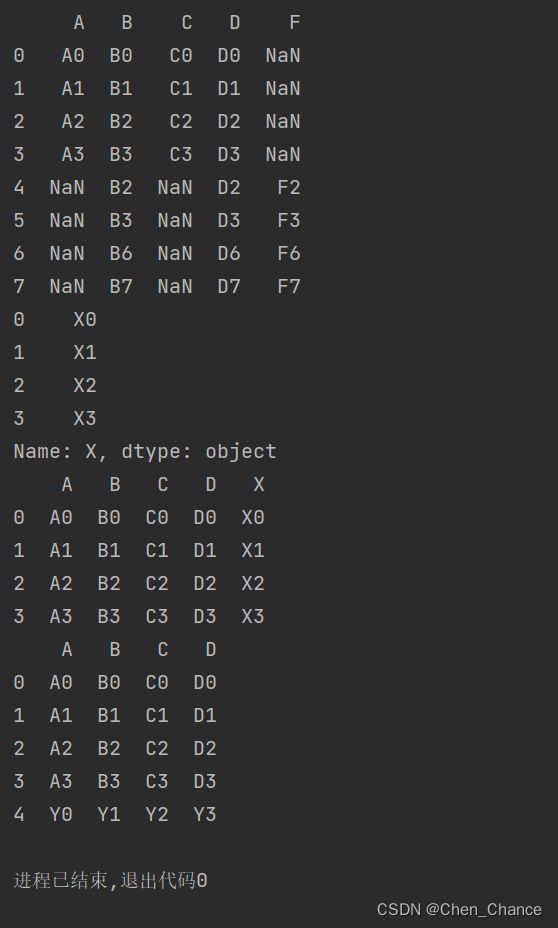
融合Merge
注意,concat 可以一次性合并多个 df,可以【左右】,也可以【上下】拼接, 但是 merge 是用来针对两张 df 做【左右】拼接的。 但是如果你真的懂 merge 的功能,也许你会更喜欢用 merge。
重要的事说三遍,merge 只做左右拼接。左右拼接。左右拼接。
import pandas as pd
left = pd.DataFrame({
"key": ["K0", "K1", "K2", "K3"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
})
right = pd.DataFrame({
"key": ["K0", "K1", "K2", "K3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
})
# merge() 只在你指定的 col 作为 index 来合并,所以有一个 on="key" 参数。
# 而 concat 只在 index/column 上寻找统一索引
print(pd.merge(left,right,on="key"))
left = pd.DataFrame({
"key1": ["K0", "K0", "K1", "K2"],
"key2": ["K0", "K1", "K0", "K1"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
})
right = pd.DataFrame({
"key1": ["K0", "K1", "K1", "K2"],
"key2": ["K0", "K0", "K0", "K0"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
})
print(left,"\n",right)
# 也可以基于2个key,注意这里可以是1对多的关系
print(pd.merge(left,right,on=["key1","key2"]))

| 命令 | 含义 | merge | concat |
|---|---|---|---|
| outer | 集合2个df所有的key | √ | √ |
| inner | 只集合2个df都有的key | √ | √ |
| left | 只考虑左边df的所有key | √ | |
| right | 只考虑右边df所有的key | √ | |
| cross | 两个df的key的笛卡尔积 | √ |
上述命令都可以通过how参数控制
import pandas as pd
left = pd.DataFrame({
"key1": ["K0", "K0", "K1", "K2"],
"key2": ["K0", "K1", "K0", "K1"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
})
right = pd.DataFrame({
"key1": ["K0", "K1", "K1", "K2"],
"key2": ["K0", "K0", "K0", "K0"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
})
print(left,"\n",right)
print(pd.merge(left,right,how="outer",on=["key1","key2"]))
print(pd.merge(left,right,how="inner",on=["key1","key2"]))
print(pd.merge(left,right,how="left",on=["key1","key2"]))
print(pd.merge(left,right,how="right",on=["key1","key2"]))
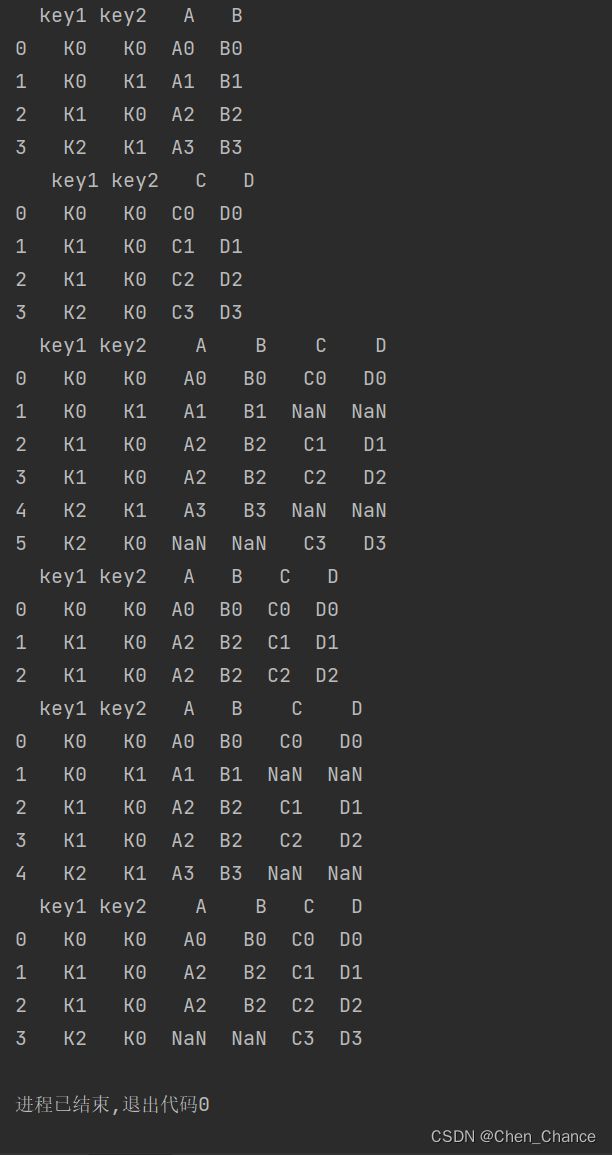
接入Join
明白了 merge,我就可以来说说 join 了。join 其实是 df.join()。 但是它其实更像是 merge 和 concat 的某种结合体,merge() 是基于给定的某个 on=“key” 来拼接, 而 df.join() 使用的 key 可以和 concat() 一样,都是 index,也可以像 merge() 带一个 on=“key” 去使用一个 column 作为索引。
import pandas as pd
left = pd.DataFrame({
"A": ["A0", "A1", "A2"],
"B": ["B0", "B1", "B2"]
}, index=["K0", "K1", "K2"])
right = pd.DataFrame({
"C": ["C0", "C2", "C3"],
"D": ["D0", "D2", "D3"]
}, index=["K0", "K2", "K3"])
# df.join() 的时候默认是使用 how="left" 的。你可以在上面尝试将 how 这个参数明确出来,写不同的 join 方式,
# 比如 ‘left’, ‘right’, ‘outer’, ‘inner’
print(left.join(right))
left = pd.DataFrame({
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"key": ["K0", "K1", "K0", "K1"],
})
right = pd.DataFrame({
"C": ["C0", "C1"],
"D": ["D0", "D1"]
}, index=["K0", "K1"])
print(left.join(right,on="key"))

数据分组
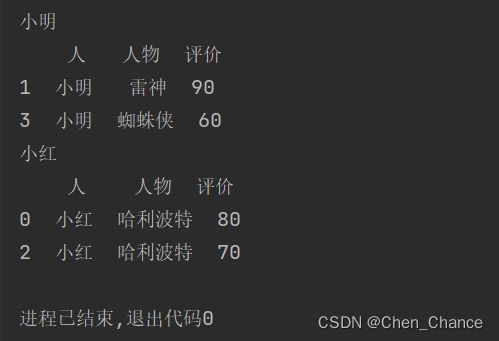
先建立数据
import pandas as pd
df=pd.DataFrame(
[
("小红","哈利波特",80),
("小明","雷神",90),
("小红","哈利波特",70),
("小明","蜘蛛侠",60),
],
columns=("人","人物","评价")
)
print(df)
# 获取了 Pandas 当中的 group 类
grouped=df.groupby("人")
# 看看这个 grouped 当中究竟是怎么组织我们的数据的
print(grouped.groups)

分组
print(df.iloc[grouped.groups["小红"]])
# 等价于
print(grouped.get_group("小红"))

调用分好的组
# 返回每一组的第一个数据
print(grouped.first())
# # 返回每一组的最后一个数据
print(grouped.last())
# 对每一组里面的数据进行sum操作
print(grouped.sum())
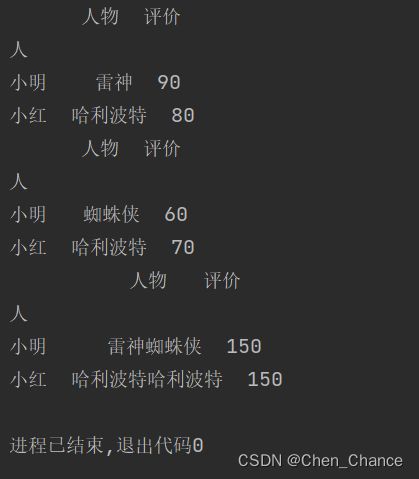
循环处理
# 会带着两个字段做循环。 一个是组名,一个是组数据
for name,group in grouped:
print(name)
print(group)
多从分组
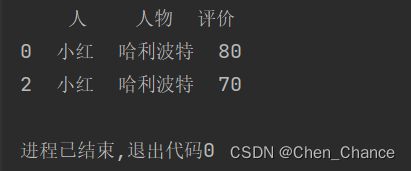
对不只一个 column 的值进行分组
df=pd.DataFrame(
[
("小红","哈利波特",80),
("小明","雷神",90),
("小红","哈利波特",70),
("小明","蜘蛛侠",60),
],
columns=("人","人物","评价")
)
print(df.groupby(["人","人物"]).get_group(("小红","哈利波特")))
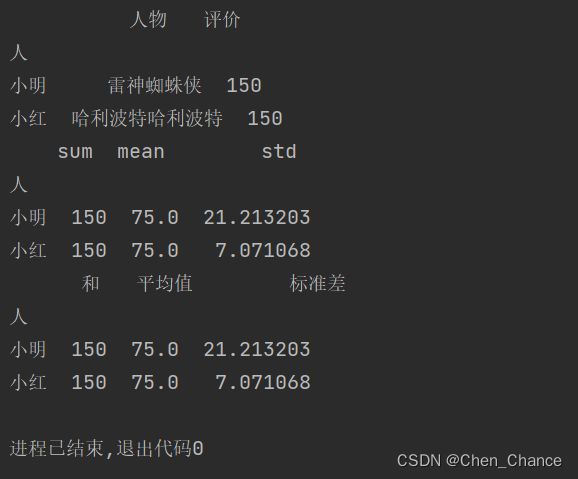
聚合计算
import numpy as np
grouped=df.groupby("人")
print(grouped.aggregate(np.sum))
# 做更多的聚合计算
# .agg() 是 .aggregate() 的缩写
print(grouped["评价"].agg([np.sum,np.mean,np.std]))
# 小技巧,用rename重新描述column
print(grouped["评价"].agg([np.sum,np.mean,np.std])
.rename(columns={
"sum":"和" ,
"mean":"平均值" ,
"std":"标准差"})
)
grouped.aggregate(np.sum)和grouped.sum()似乎作用是一样的,感觉第二种方法更方便,我们为什么还要用第一种方法呢?
grouped.aggregate(np.sum) 和 grouped.sum() 都是用于对分组后的数据进行求和操作的方法,但它们在使用方式和一些细节上有一些区别。
-
使用方式:
grouped.aggregate(np.sum):这种方式使用了显式的聚合函数,你需要传递一个聚合函数给aggregate方法。在这种情况下,你明确指定了要使用的聚合函数,可以是 NumPy 中的np.sum,也可以是其他自定义的聚合函数。grouped.sum():这种方式更为简洁,不需要明确指定聚合函数,因为 Pandas 已经内置了求和操作。你只需要调用.sum()方法,Pandas 会自动应用求和操作到每个分组中的数据。
-
结果:
- 两者的结果是相同的,都会对分组后的数据进行求和操作。每个分组将被独立地求和,然后返回一个包含每个分组求和结果的 DataFrame 或 Series。
-
可读性:
grouped.sum()更为简洁和易读,因为它是 Pandas 的内置方法,常见且容易理解。grouped.aggregate(np.sum)的方式可能在需要使用自定义聚合函数或进行更复杂的聚合操作时才会更有用。
总之,如果只是对分组后的数据进行求和操作,并且不需要自定义聚合函数,建议使用 grouped.sum() 方法,因为它更简洁和易读。如果需要进行其他自定义聚合操作,可以使用 grouped.aggregate() 并传递适当的聚合函数。
多索引数据
后面再补充
小练习
疫情数据分析
数据一览

import pandas as pd
df=pd.read_csv("covid19_day_wise.csv")
print(df.head())

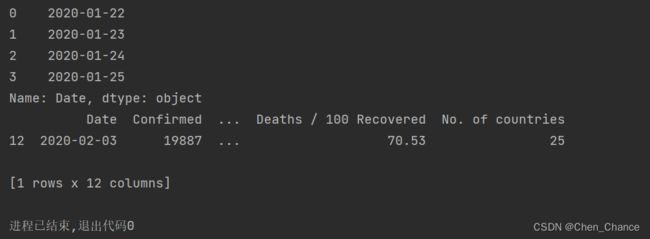
获取 2020 年 2 月 3 日的所有数据
print(df["Date"][:4])
print(df[df["Date"]=="2020-02-03"])
2020 年 1 月 24 日之前的累积确诊病例有多少个?
confirmed0124=df.loc[df["Date"]=="2020-01-24","Confirmed"]
print(confirmed0124)
print(confirmed0124.values)
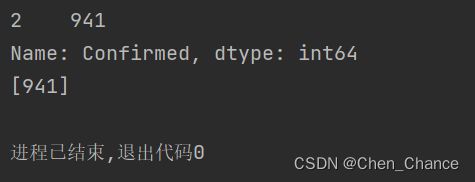
2020 年 7 月 23 日的新增死亡数是多少?
result=df.loc[df["Date"]=="2020-07-23","New deaths"]
print(result.values)

从 1 月 25 日到 7 月 22 日,一共增长了多少确诊病例?
date=pd.to_datetime(df["Date"])
print(date)
date_range=(date>="2020-01-25")&(date<="2020-07-22")
new_cases=df.loc[date_range,"New cases"]
overall =new_cases.sum()
print(overall)

每天新增确诊数和新恢复数的比例?平均比例,标准差各是多少?
ratio=df["New cases"]/df["New recovered"]
print(ratio[:5])

打印输出,看下NaN产生的原因
print(df.loc[0,"New cases"])
print(df.loc[0,"New recovered"])

原来是出现了0/0的情况,我们把 New recovered 为零的数都剔除掉
not_zero_mask=df["New recovered"]!=0
ratio=df.loc[not_zero_mask,"New cases"]/df.loc[not_zero_mask,"New recovered"]
ratio_mean=ratio.mean()
ratio_std=ratio.std()
print(ratio_mean,ratio_std)

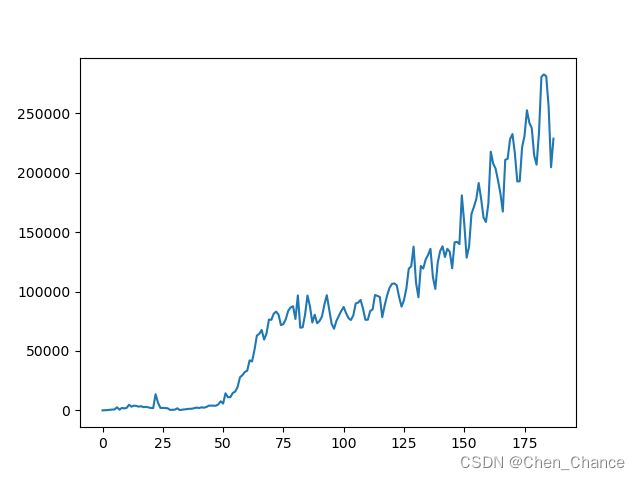
画图展示新增确诊的变化曲线,画图展示死亡率的变化曲线
import matplotlib.pyplot as plt
df["New cases"].plot()
plt.show()
df["Deaths / 100 Cases"].plot()
plt.show()

机器学习数据预处理
后续补充