【操作系统】进程,线程和协程的哪些事儿
进程,线程和协程的哪些事儿
-
- 进程
-
- 什么是进程?
- 进程的状态
- 进程的控制结构
- 线程
-
- 为什么使用线程?
- 什么是线程?
- 线程与进程的比较
- 线程的实现
-
- 用户级线程
- 内核级线程
- 轻量级进程
- 协程
-
- 协程是什么?
- 协程的优势
- 区别
-
- 进程与线程的区别
- 协程与线程的区别
进程
什么是进程?
我们编写的代码只是个存储在硬盘的静态文件,通过编译后就会生成二进制可执行文件,当我们运行这个可执行文件后,它会被装载到内存中,接着CPU会执行程序中的每一条指令,那么这个运行中的程序,就被称为进程。
进程的状态
在一个进程的活动期间至少具备三种基本状态,即运行状态、就绪状态、阻塞状态。

- 运行状态(Runing):该时刻进程占用CPU。
- 就绪状态(Ready):可运行,由于其他进程处于运行状态而暂时停止运行。
- 阻塞状态(Blocked):该进程正在等待某一事件发生(如等待输入/输出操作的完成)而暂时停止运行,这是,即使给它CPU控制权,它也无法运行;
当然,一个完整的进程状态还有创建状态(new)和结束状态(Exit):
- 创建状态(new):进程正在被创建时的状态。
- 结束状态(Exit):进程正在从系统中消失时的状态。
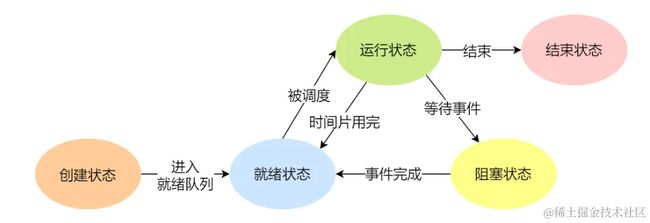
- NUll -> 创建状态:一个新进程被创建时的第一个状态;
- 创建状态 -> 就绪状态:当进程被创建完成并初始化后,一切就绪准备运行时,变为就绪状态,这个过程很快。
- 就绪状态 -> 运行状态:处于就绪状态的进程被操作系统的进程调度器选中后,就分配给CPU正式运行该进程;
- 运行状态 -> 结束状态:当进程已经运行完成或出错时,会被操作系统作结束状态处理;
- 运行状态 -> 就绪状态:处于运行状态的进程在运行过程中,由于分配给它的运行时间片用完,操作系统会把进程变为就绪态,接着从就绪态选中另外一个进程运行。
- 运行状态 -> 阻塞状态:当进程请求某个事件且必须等待时,例如请求I/O事件;
- 阻塞状态 -> 就绪状态:当进程要等待的事件完成时,它从阻塞状态变到就绪状态;
如果有大量处于阻塞状态的进程,进程可能会占用着物理内存空间,可是物理内存空间是有限的,被阻塞状态的进程占用着物理内存就是一种浪费物理内存的行为。
所以,在虚拟内存管理的操作系统中,通常会把阻塞状态的进程的物理内存空间换出到硬盘,等需要再次运行的时候,再从硬盘换入到物理内存。

挂起状态分为两种:
- 阻塞挂起状态:进程在外存(硬盘)并等待某个事件的出现
- 就绪挂起状态:进程在外存(硬盘),但只要进入内存,即刻立即运行;
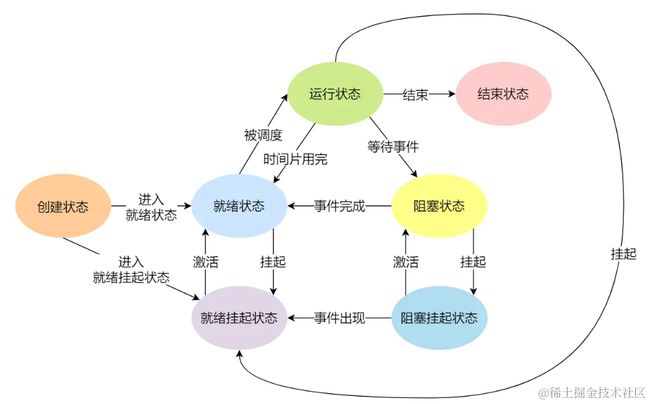
导致进程挂起的原因不只是因为进程所使用的内存空间不在物理内存,还包括如下情况:
- 通过
sleep让进程间歇性挂起,其工作原理是设置一个定时器,到期后唤醒进程。 - 用户希望挂起一个程序的执行,比如在Linux中用
Ctrl+Z挂起进程。
进程的控制结构
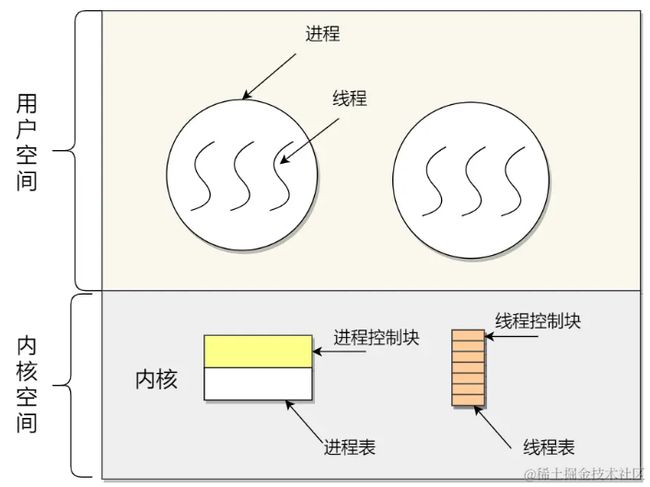
在操作系统中,是用进程控制块(process control block,PCB)数据结构来描述进程的。
PCB 是进程存在的唯一标识,这意味着一个进程的存在,必然会有一个 PCB,如果进程消失了,那么 PCB 也会随之消失。
PCB具体有进程描述信息、进程控制和管理信息、资源分配清单、CPU相关信息等信息。
那每个PCB是如何组织的呢?
PCB通常是通过链表的方式进行组织,把具有相同状态的进程链在一起,组成各种队列。
- 将所有处于就绪状态的进程链在一起,称为
就绪队列; - 把所有因等待某事件而处于等待状态的进程链在一起就组成各种
阻塞队列;
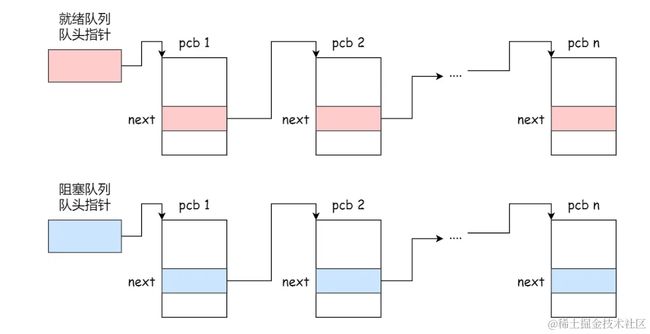
除了链接的组织方式,还有索引方式,它的工作原理:将同一状态的进程组织在一个索引表中,索引表项指向相应的 PCB,不同状态对应不同的索引表。
一般会选择链表,因为可能面临进程创建,销毁等调度导致进程状态发生变化,所以链表能够更加灵活的插入和删除。
线程
在早期的操作系统中都是以进程作为独立运行的基本单位,直到后面,计算机科学家们又提出了更小的能独立运行的基本单位,也就是线程。
为什么使用线程?
假设你要编写一个视频播放软件,那么该软件功能的核心模块有三个:
- 从视频文件当中读取数据
- 对读取的数据进行解压缩
- 把解压缩后的视频数据播放出来
单线程实现方式:
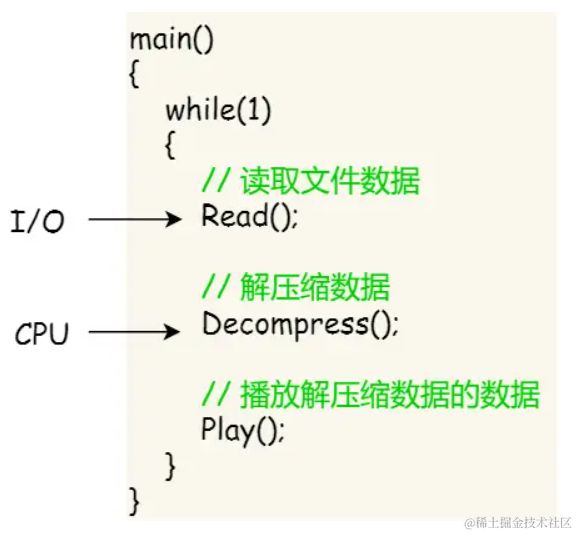
对于单线程的这种方式,存在以下问题:
- 播放出来的画面和声音会不连贯,因为当CPU能力不够强的时候,
Read的时候可能进程就等在这了,这样就会导致等半天才进行数据解压和播放。 - 各个函数之间不是并发执行,影响资源的使用效率;
多进程的实现方式:

对于多进程的这种方式,依然会存在问题:
- 进程之间如何通信,共享数据?
- 维护进程的系统开销较大,如创建进程时,分配资源、建立PCB;终止进程时,回收资源、撤销PCB;进程切换时,保存当前进程的状态信息;
那怎么解决呢?需要有一种新的实体,满足以下特性:
- 实体之间可以并发运行;
- 实体之间共享相同的地址空间;
这个新的实体,就是线程( Thread ) ,线程之间可以并发运行且共享相同的地址空间。
什么是线程?
线程是进程当中的一条执行流程。
同一个进程内多个线程之间可以共享代码段、数据段、打开的文件等资源,但每个线程各自都有一套独立的寄存器和栈,这样可以确保线程的控制流是相对独立的。
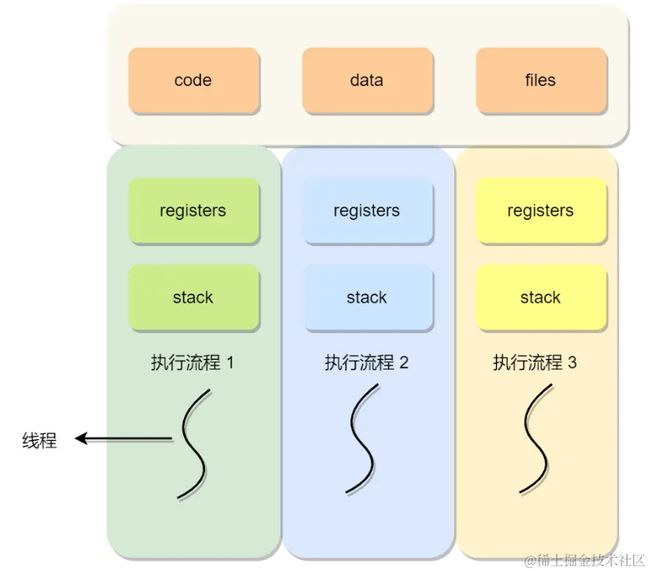
线程的优缺点
线程的优点:
- 一个进程中可以存在多个线程;
- 各个线程之间可以并发执行;
- 各个线程之间可以共享地址空间和文件等资源。
线程的缺点:
- 当进程中的一个线程崩溃时,会导致其所属进程的所有线程崩溃。
线程与进程的比较
线程和进程的比较如下:
- 调度:进程是资源管理的基本单位,线程是程序执行的基本单位。
- 切换:线程上下文切换比进程上下文切换要快的多。(
当两个线程是属于同一个进程,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据)- 拥有资源:进程是拥有资源的一个独立单位,线程不拥有系统资源,但是可以访问隶属于进程的资源。
- 系统开销:创建或撤销进程时,系统都要为之分配或回收系统资源,如内存空间,I/O设备等,OS所付出的开销显著大于在创建或撤销线程时的开销,进程切换的开销也远大于线程切换的开销。
线程的实现
用户线程(User Thread):在用户空间实现的线程,不是由内核管理的线程,是由用户态的线程库来完成线程的管理。内核线程(Kernel Thread):在内核中实现的线程,是由内核管理的线程;轻量级进程(LightWeight Process):在内核中来支持用户线程;
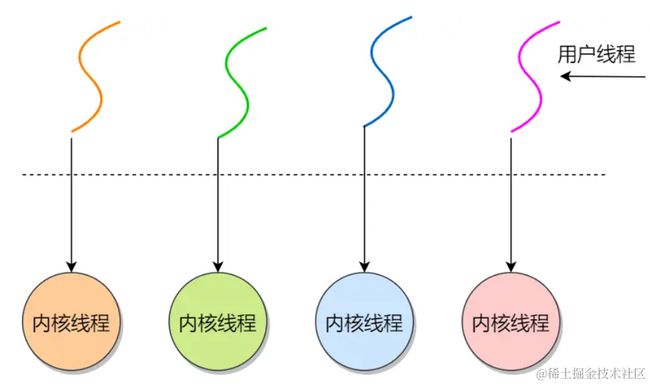
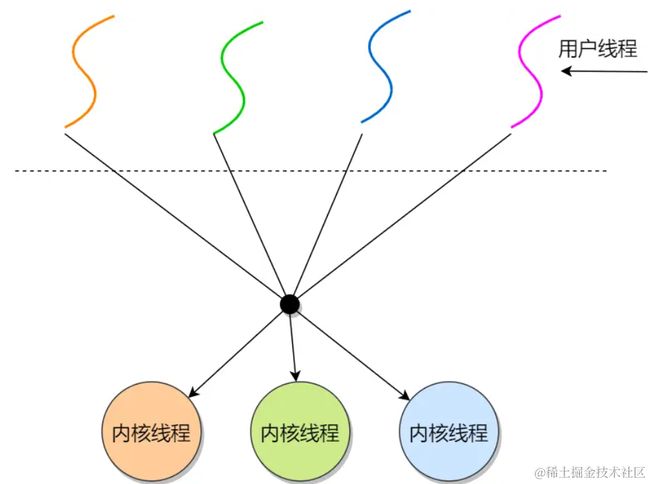
用户线程和内核线程的对应关系是什么呢?
多对一:多个用户线程对应一个内核线程;

一对一:一个用户线程对应一个内核线程:
多对多:多个用户线程对应到多个内核线程:
用户级线程
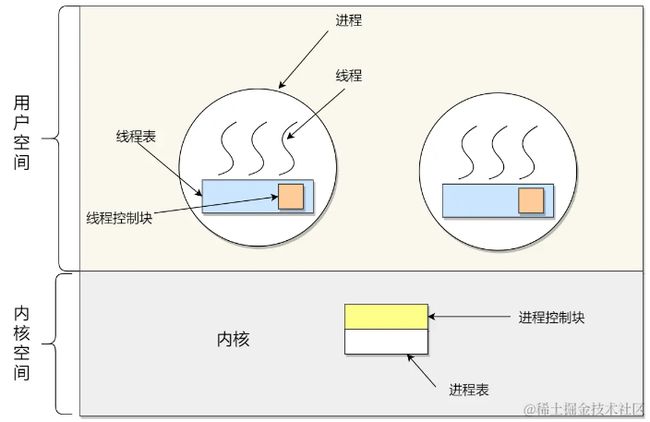
用户级线程是基于用户态的线程管理库来实现的,那么线程控制块(Thread Control Block,TCB)也是在库里面来实现的,对于操作系统而言是看不到这个TCB的,它只看到整个进程的PCB。
所以,用户线程的整个线程管理和调度,操作系统是不直接参与的,而是由用户级线程库函数来完成线程的管理,包括线程的创建、终止、同步和调度等。
用户级线程的模型,也就类似前面提到的多对一的关系
用户线程的优点:
- 每个进程都需要有它私有的线程控制块(TCB)列表,用来跟踪记录它各个线程状态信息(PC、栈指针、寄存器),TCB 由用户级线程库函数来维护,可用于不支持线程技术的操作系统;
- 用户线程的切换也是由线程库函数来完成的,无需用户态与内核态的切换,所以速度特别快;
用户线程的缺点:
- 由于操作系统不参与线程的调度,如果一个线程发起了系统调用而阻塞,那进程所包含的用户线程都不能执行了。
- 当一个线程开始运行后,除非它主动地交出 CPU 的使用权,否则它所在的进程当中的其他线程无法运行,因为用户态的线程没法打断当前运行中的线程,它没有这个特权,只有操作系统才有,但是用户线程不是由操作系统管理的。
- 由于时间片分配给进程,故与其他进程比,在多线程执行时,每个线程得到的时间片较少,执行会比较慢;
内核级线程
内核级线程是由操作系统管理的,线程对应的TCB自然是放在操作系统里的,这样线程的创建、终止和管理都是由操作系统负责。
内核级线程模型为一对一
内核线程的优点:
- 在一个进程当中,如果某个内核线程发起系统调用而被阻塞,并不会影响其他内核线程的运行;
- 分配给线程,多线程的进程获得更多的 CPU 运行时间;
内核线程的缺点:
- 在支持内核线程的操作系统中,由内核来维护进程和线程的上下文信息,如 PCB 和 TCB;
- 线程的创建、终止和切换都是通过系统调用的方式来进行,因此对于系统来说,系统开销比较大;
轻量级进程
轻量级进程(Light-weight-process,LWP)是内核支持的用户线程,一个进程可有一个或多个LWP,每个LWP是跟内核线程一对一映射的,也就是LWP都是由一个内核线程支持的,而且LWP是由内核管理并像普通进程一样被调度。
一般来说,一个进程代表程序的一个实例,而 LWP 代表程序的执行线程,因为一个执行线程不像进程那样需要那么多状态信息,所以 LWP 也不带有这样的信息。
在 LWP 之上也是可以使用用户线程的,那么 LWP 与用户线程的对应关系就有三种:
1 : 1,即一个 LWP 对应 一个用户线程;N : 1,即一个 LWP 对应多个用户线程;M : N,即多个 LWP 对应多个用户线程;
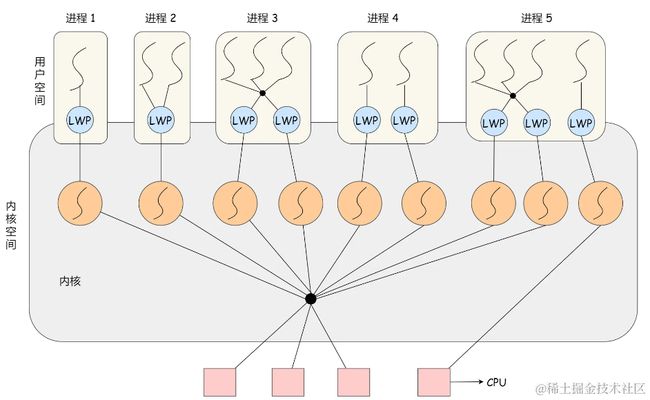
1 : 1 模式
一个线程对应到一个 LWP 再对应到一个内核线程,如上图的进程 4,属于此模型。
- 优点:实现并行,当一个 LWP 阻塞,不会影响其他 LWP;
- 缺点:每一个用户线程,就产生一个内核线程,创建线程的开销较大。
N : 1 模式
多个用户线程对应一个 LWP 再对应一个内核线程,如上图的进程 2,线程管理是在用户空间完成的,此模式中用户的线程对操作系统不可见。
- 优点:用户线程要开几个都没问题,且上下文切换发生用户空间,切换的效率较高;
- 缺点:一个用户线程如果阻塞了,则整个进程都将会阻塞,另外在多核 CPU 中,是没办法充分利用 CPU 的。
M : N 模式
根据前面的两个模型混搭一起,就形成 M:N 模型,该模型提供了两级控制,首先多个用户线程对应到多个 LWP,LWP 再一一对应到内核线程,如上图的进程 3。
- 优点:综合了前两种优点,大部分的线程上下文发生在用户空间,且多个线程又可以充分利用多核 CPU 的资源。
组合模式
如上图的进程 5,此进程结合 1:1 模型和 M:N 模型。开发人员可以针对不同的应用特点调节内核线程的数目来达到物理并行性和逻辑并行性的最佳方案。
协程
协程是什么?
协程(Coroutine)就是用户态的线程。通常创建协程时,会从进程的堆中分配一段内存作为协程的栈。
线程的栈大小通常默认为MB级别的,(在Windows操作系统中,默认的线程栈大小通常为1MB。而在Linux操作系统中,默认的线程栈大小可以是2MB或更大)而协程栈的大小通常只有KB,而Go语言的协程更夸张,通常只有4-5KB,非常的轻巧。
协程的优势
- 节省CPU:避免系统内核级的线程频繁切换,造成的CPU资源浪费。而协程是用户态的线程,用户可以自行控制协程的创建与销毁,极大程度上避免了系统级线程上下文切换造成的资源浪费。
- 节约内存:系统内存的制约导致我们无法开启更多线程实现高并发。而在协程编程模式下,可以轻松有几十万协程,这是线程无法比拟的。
- 开发效率:使用协程在开发程序之中,可以很方便的将一些耗时的IO操作异步化,例如写文件、耗时 IO 请求等。
协程本质上就是用户态下的线程,所以也有人说协程是“轻线程”。
区别
进程与线程的区别
- 调度:进程是资源管理的基本单位,线程是程序执行的基本单位。
- 切换:线程上下文切换比进程上下文切换要快的多。(当两个线程是属于同一个进程,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据)
- 拥有资源:进程是拥有资源的一个独立单位,线程不拥有系统资源,但是可以访问隶属于进程的资源。
- 系统开销:创建或撤销进程时,系统都要为之分配或回收系统资源,如内存空间,I/O设备等,OS所付出的开销显著大于在创建或撤销线程时的开销,进程切换的开销也远大于线程切换的开销。
协程与线程的区别
-
线程和进程都是同步机制,而协程是异步机制。
-
线程是抢占式,而协程是非抢占式的,需要用户释放使用权切换到其他协程,因此同一时间其实只有一个协程拥有运行权,相当于单线程的能力。
-
协程不被操作系统内核管理,而完全是由程序控制,线程是被分割的CPU资源,协程是组织好的代码流程,线程是被分割的CPU资源,协程是组织好的代码流程,线程是协程的资源,但协程不会直接使用线程,协程直接利用的是执行器关联任意线程或线程池。
参考链接:
小林coding
https://blog.csdn.net/EDDYCJY/article/details/116141654