卷积网络中的通道、特征图、过滤器和卷积核
卷积网络中的通道、特征图、过滤器和卷积核
1.feature map
1 feature map
在cnn的每个卷积层,数据都是以三维形式存在的。你可以把它看成许多个二维图片叠在一起(像豆腐皮一样),其中每一个称为一个feature map。
2 feature map怎么生成的?
输入层:在输入层,如果是灰度图片,那就只有一个feature map;若是彩色图片,一般是三个feature map(红绿蓝)。
其它层:层与层之间会有若干个卷积核(kernel),也成为过滤器,上一层每个feature map 跟卷积核做卷积,都会产生下一层的一个feature map,有N个卷积核,下层就会产生N个feature map。
3 多个feature map 的作用是什么?
在卷积神经网络中,我们希望用一个网络模拟视觉通路的特性,分层的概念是自底向上构造简单到复杂的神经元。楼主关心的是同一层,那就说说同一层。
我们希望构造一组基,这组基能够形成对于一个事物完备的描述,例如描述一个人时我们通过描述身高/体重/相貌等,在卷积网中也是如此。在同一层,我们希望得到对于一张图片多种角度的描述,具体来讲就是用多种不同的卷积核对图像进行卷,得到不同核(这里的核可以理解为描述)上的响应,作为图像的特征。他们的联系在于形成图像在同一层次不同基上的描述。
下层的核主要是一些简单的边缘检测器(也可以理解为生理学上的simple cell)。
上层的核主要是一些简单核的叠加(或者用其他词更贴切),可以理解为complex cell。
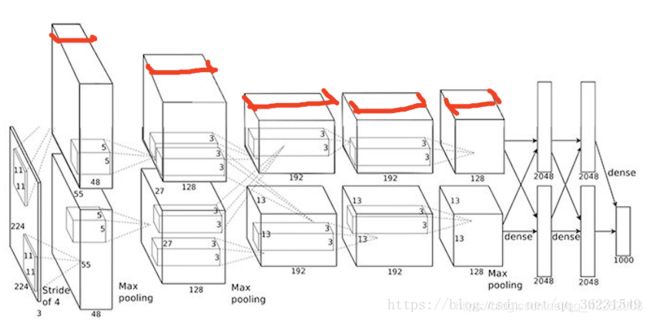
多少个Feature Map?真的不好说,简单问题少,复杂问题多,但是自底向上一般是核的数量在逐渐变多(当然也有例外,如Alexnet),主要靠经验。
2.卷积核
2.1 定义
卷积核在有的文档里也称为过滤器(filter):
每个卷积核具有长宽深三个维度;
在某个卷积层中,可以有多个卷积核;下一层需要多少个feature map,本层就需要多少个卷积核。
2.2 形状
每个卷积核具有长、宽、深三个维度。在CNN的一个卷积层中:
卷积核的长、宽都是人为指定的,长X宽也被称为卷积核的尺寸,常用的尺寸为3X3,5X5等;
卷积核的深度与当前图像的深度(feather map的张数)相同,所以指定卷积核时,只需指定其长和宽 两个参数。例如,在原始图像层 (输入层),如果图像是灰度图像,其feather map数量为1,则卷积核的深度也就是1;如果图像是grb图像,其feather map数量为3,则卷积核的深度也就是3.
2.3卷积核个数的理解
如下图红线所示:该层卷积核的个数,有多少个卷积核,经过卷积就会产生多少个feature map,也就是下图中 豆腐皮儿的层数、同时也是下图豆腐块的深度(宽度)!!这个宽度可以手动指定,一般网络越深的地方这个值越大,因为随着网络的加深,feature map的长宽尺寸缩小,本卷积层的每个map提取的特征越具有代表性(精华部分),所以后一层卷积层需要增加feature map的数量,才能更充分的提取出前一层的特征,一般是成倍增加(不过具体论文会根据实验情况具体设置)!

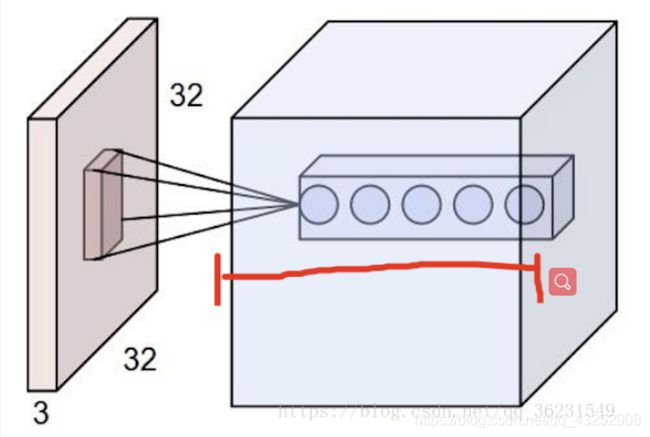
卷积核的运算过程
例如输入224x224x3(rgb三通道),输出是32位深度,卷积核尺寸为5x5。
那么我们需要32个卷积核,每一个的尺寸为5x5x3(最后的3就是原图的rgb位深3),每一个卷积核的每一层是5x5(共3层)分别与原图的每层224x224卷积,然后将得到的三张新图叠加(算术求和),变成一张新的feature map。 每一个卷积核都这样操作,就可以得到32张新的feature map了。 也就是说:
不管输入图像的深度为多少,经过一个卷积核(filter),最后都通过下面的公式变成一个深度为1的特征图。不同的filter可以卷积得到不同的特征,也就是得到不同的feature map。。。
3.filter
filter有两种理解:在有的文档中,一个filter等同于一个卷积核:只是指定了卷积核的长宽深;
而有的情况(例如tensorflow等框架中,filter参数通常指定了卷积核的长、宽、深、个数四个参数),filter包含了卷积核形状和卷积核数量的概念:即filter既指定了卷积核的长宽深,也指定了卷积核的数量。
4.channel
4.1 定义
卷积神经网络中的通道(channel)也叫特征图(featrue map)。
卷积网络中主要有两个操作,一个卷积(Convolution),一个池化(Pooling)。其中,池化层并不会对通道之间的交互有影响,只是在各个通道中进行操作;而卷积层则可以在通道与通道之间进行交互,之后再下一层生成新的通道,最显著的是Incept-Net里大量用到的1*1卷积操作,它基本上完全就是在通道与通道之间进行交互,而不关心同一个通道中的交互。
一般大家说通道指的是图片的色彩通道,而特征图是卷积过滤器的输出结果。但实际上,两者本质上是相同的,都是表示之前输入上某个特征分布的数据。
数码相机中的“卷积”
通道这个概念最初指的是电子图片中RGB通道,或者CMYK通道这样的配色方案,比如说一张RGB的64x64的图片,可以用一个64x64x3的张量来表示。这里的3指的就是通道,分别为红色(Red)、绿色(Green)、蓝色(Blue)三个通道。
因为这三种颜色是三原色,所以基本上可以合成任何人眼可分辨的颜色。而三个通道的图片也基本上可以表示所有图片了。
在计算机视觉处理中,一般图片数据除了是单通道的灰度图片外,就是RGB通道的彩色图片了。
对RGB图片进行卷积操作后,根据过滤器的数量就可以产生更多的通道。事实上,多数情况还是叫后面的卷积层中的通道为,特征图。但实际上在张量表示下,特征图和前面提到的通道差不多,有时候后面的也都叫通道了。我是被吴教授带歪的(警察叔叔,就是他!)。
当把通道和特征图当成是一个东西,然后来看RGB图片中的通道是怎么获得的就会非常有意思了。
首先通道需要卷积操作来完成,也就是说我们需要三个过滤器来生成RGB通道。那么这个过滤器是什么呢,又是以什么为输入呢。这时候如果来看数码相机的原理就明白了。数码相机中最核心的部分是CCD,也叫电子耦合组件。
数码相机成像最关键的部分是CCD中的感光层。CCD中在感光层前面一般会有一个“分层滤色片”,如果是RGB原色分色法的话,就是通过红绿蓝三种颜色的滤色片,射进来的光转换成三原色光,之后在感光层将穿过滤色片的光源转换成电子信号,信号传送到处理芯片,就可以还原成我们所获得的电子图片了。
拿以上数码相机成像过程来类比卷积的话,就会发现,这里的红绿蓝三色的滤光片,正好可以类比成卷积中的过滤器,外界射进来的光就是输入,通过这三个特征过滤器,获得了一个三通道的输出。
那么卷积核大小是多大呢,这里可以说是感光元件上一个像素大小,而原始的射入的光的精度则是光子级别的,对这个光的一个像素大小的范围进行卷积,获得这个范围当前过滤器捕捉特征的强度。也就是绿光、红光、蓝光的强度。
4.2 分类
最初输入的图片样本的 channels ,取决于图片类型,比如RGB,灰度图像的channel值为1,彩色图像的channel值为3;;
卷积核中的 in_channels ,就是要操作的图像数据的feather map张数,也就是卷积核的深度。(刚刚2中已经说了,就是上一次卷积的 out_channels ,如果是第一次做卷积,就是1中样本图片的 channels) ;
卷积操作完成后输出的 out_channels ,取决于卷积核的数量(下层将产生的feather map数量)。此时的 out_channels 也会作为下一次卷积时的卷积核的 in_channels。
4.3 通道与特征
这样看来,图片中的通道就是某种意义上的特征图。一个通道是对某个特征的检测,通道中某一处数值的强弱就是对当前特征强弱的反应。
如一个蓝色通道中,如果是256级的话,那么一个像素如果是255的话那么就表示蓝色度很大。从这个角度来看灰度图片的话,就会发现其实灰度图片就是一个白色过滤器生成的特征图。
于是卷积网络中的特征图,也能够很直接地理解为通道了。
之后通过对一定范围的特征图进行卷积,可以将多个特征组合出来的模式抽取成一个特征,获得下一个特征图。之后再继续,对特征图进行卷积,特征之间继续组合,获得更复杂的特征图。
又因为池化层的存在,会不断提取一定范围内最强烈的特征,并且缩小张量的大小,使得大范围内的特征组合也能够捕捉到。
对单个特征图进行视觉化的话,会发现它是在对什么特征进行捕捉。最近一个很有意思的Blog文章就展示了这方面的结果,很有意思。
通过特征角度来看卷积网络的话,那么1x1卷积也就很好理解了。即使1x1卷积前后的张量大小完全不变,比如说16x16x64 -> 16x16x64这样的卷积,看上去好像是没有变化。但实际上,可能通过特征之间的互动,已经由之前的64个特征图组成了新的64个特征图。
有时候我理解一个这样的1x1卷积操作,就会把它当成是一次对之前特征的整理。
4.4 通道的终点
这样子不停卷积下去,直到最后一层,剩下一个一维向量时,每个标量代表着一个通道,捕捉到的特征又是什么呢。
如果是物体分类任务的话,就正是我们需要输出判别的一个个物体类别。
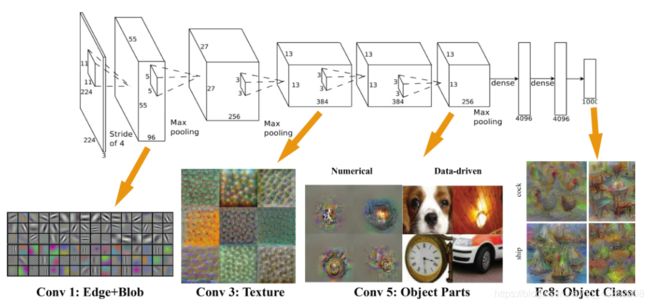
比如说第一个数是代表猫特征,第二个数代表狗特征,第三个代表人… 这个时候去从里面选数值最大那个当做分类的种类就好了。
到这里可能仔细的人会注意,最后几层不是没卷积操作吗,而是全连接网络。
一个概念上需要澄清的是,虽然说1x1卷积,而且也从融合特征角度,给了它特殊的理解。但如果再仔细看看的话,就会发现实际上1x1卷积就是全连接网络。所以我们可以把最后的1x1网络当成某种程度上的1x1卷积。
上面的网络最后几层,将张量展平然后输入全连接网络。因为剩下的特征图中都保留了很重要的信息,为了利用所有的信息,并且让它们获得足够的交互,所以直接输入全连接网络,获得最后的特征向量。
这个特征向量能够用来干什么呢。一个很有趣的应用案例是Siamese网络。输入一张脸,输出一个128的特征向量,于是这个向量就类似于ID号码。
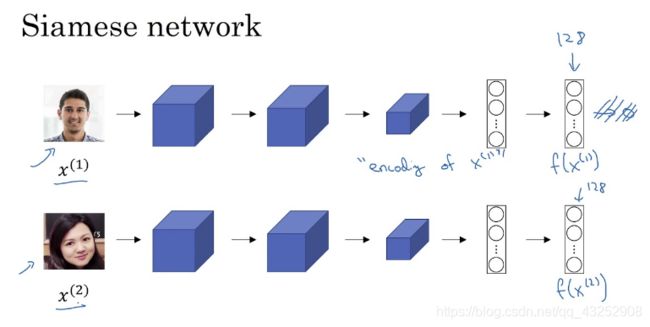
之后再输入一张脸,得到一个特征向量,这时候只需要比较一下获得的两个特征向量就能够知道这两张脸是不是同一个人。如果将最后的特征向量视觉化,或许我们还能发现,向量中每个标量所代表的特征,比如说眼睛之间的间距,肤色…用本文的通道来说的话,最后获得了一个128个通道向量表示。
参考来源
添加链接描述