Zookeeper+Hadoop+Spark+Flink+Kafka+Hbase+Hive 完全分布式高可用集群搭建(保姆级超详细含图文)
说明:
本篇将详细介绍用二进制安装包部署hadoop等组件,注意事项,各组件的使用,常用的一些命令,以及在部署中遇到的问题解决思路等等,都将详细介绍。
1.环境说明
1.1 ip规划
| ip | hostname |
|---|---|
| 192.168.1.11 | node1 |
| 192.168.1.12 | node2 |
| 192.168.1.13 | node3 |
1.2系统配置
1.2.1系统版本
[root@localhost ~]# cat /etc/redhat-release
CentOS Linux release 7.9.2009 (Core)
1.2.2内存建议最少4g、2cpu、50G以上的磁盘容量
[root@localhost ~]# free -h
total used free shared buff/cache available
Mem: 3.7G 282M 3.3G 11M 141M 3.2G
Swap: 3.9G 0B 3.9G
[root@localhost ~]# grep -c ^processor /proc/cpuinfo
2
[root@localhost ~]# df -h /
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-root 46G 11G 35G 25% /
2系统基础环境配置
2.1配置hostname、ip
hostnamectl set-hostname node1
nmcli connection modify ens33 ipv4.method manual ipv4.addresses "192.168.1.11/24" ipv4.gateway 192.168.1.254 ipv4.dns "8.8.8.8,114.114.114.114" connection.autoconnect yes
nmcli connection up ens33
hostnamectl set-hostname node2
nmcli connection modify ens33 ipv4.method manual ipv4.addresses "192.168.1.12/24" ipv4.gateway 192.168.1.254 ipv4.dns "8.8.8.8,114.114.114.114" connection.autoconnect yes
nmcli connection up ens33
hostnamectl set-hostname node3
nmcli connection modify ens33 ipv4.method manual ipv4.addresses "192.168.1.13/24" ipv4.gateway 192.168.1.254 ipv4.dns "8.8.8.8,114.114.114.114" connection.autoconnect yes
nmcli connection up ens33
说明
网关需要和自己VMware配置的对应,配置dns为了方便访问互联网
#测试能够ping同外网
ping www.baidu.com
PING www.a.shifen.com (36.152.44.96) 56(84) bytes of data.
64 bytes from 36.152.44.96 (36.152.44.96): icmp_seq=1 ttl=128 time=24.1 ms
64 bytes from 36.152.44.96 (36.152.44.96): icmp_seq=2 ttl=128 time=23.3 ms
2.2配置免密登录
#配置三台主机互相免密登录,node1和Hadoop2必须能免密登录,包括对自己进行免密登录
ssh-keygen -t rsa -P '' -f /root/.ssh/id_rsa
for i in {11..13}
do
ssh-copy-id 192.168.1.$i
done
2.3优化ssh连接
#优化ssh连接速度
vim /etc/ssh/sshd_config
UseDNS no
GSSAPIAuthentication no
#或者写成
sed -i 's/#UseDNS\ yes/UseDNS\ no/g; s/GSSAPIAuthentication\ yes/GSSAPIAuthentication\ no/g' /etc/ssh/sshd_config
systemctl restart sshd
2.4配置hosts
[root@node1 ~]# cat >> /etc/hosts << EOF
192.168.1.11 node1
192.168.1.12 node2
192.168.1.13 node3
EOF
[root@node1 ~]# for i in {12..13}
do
scp /etc/hosts 192.168.1.$i:/etc/hosts
done
2.5配置时间同步
#以node1为服务端
[root@node1 ~]# yum install chrony -y
[root@node1 ~]# grep -vE '^#|^$' /etc/chrony.conf
pool ntp.aliyun.com iburst
driftfile /var/lib/chrony/drift
makestep 1.0 3
rtcsync
allow 192.168.0.0/24
local stratum 10
logdir /var/log/chrony
[root@node1 ~]# systemctl enable --now chronyd
[root@node1 ~]# chronyc sources -v
210 Number of sources = 1
.-- Source mode '^' = server, '=' = peer, '#' = local clock.
/ .- Source state '*' = current synced, '+' = combined , '-' = not combined,
| / '?' = unreachable, 'x' = time may be in error, '~' = time too variable.
|| .- xxxx [ yyyy ] +/- zzzz
|| Reachability register (octal) -. | xxxx = adjusted offset,
|| Log2(Polling interval) --. | | yyyy = measured offset,
|| \ | | zzzz = estimated error.
|| | | \
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* 203.107.6.88 2 6 7 0 +54ms[ +69ms] +/- 193ms
#其他节点为客户端
#node2配置
[root@node2 ~]# yum install chrony -y
[root@node2 ~]# grep -vE '^#|^$' /etc/chrony.conf
pool 192.168.1.11 iburst
driftfile /var/lib/chrony/drift
makestep 1.0 3
rtcsync
logdir /var/log/chrony
[root@node2 ~]# systemctl enable --now chronyd
#验证
[root@node2 ~]# chronyc sources -v
210 Number of sources = 1
.-- Source mode '^' = server, '=' = peer, '#' = local clock.
/ .- Source state '*' = current synced, '+' = combined , '-' = not combined,
| / '?' = unreachable, 'x' = time may be in error, '~' = time too variable.
|| .- xxxx [ yyyy ] +/- zzzz
|| Reachability register (octal) -. | xxxx = adjusted offset,
|| Log2(Polling interval) --. | | yyyy = measured offset,
|| \ | | zzzz = estimated error.
|| | | \
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^? node1 0 6 0 - +0ns[ +0ns] +/- 0ns
#node3配置
[root@node3 ~]# yum install chrony -y
[root@node3 ~]# scp 192.168.1.12:/etc/chrony.conf /etc/chrony.conf
[root@node3 ~]# systemctl enable --now chronyd
#验证
[root@node3 ~]# chronyc sources -v
210 Number of sources = 1
.-- Source mode '^' = server, '=' = peer, '#' = local clock.
/ .- Source state '*' = current synced, '+' = combined , '-' = not combined,
| / '?' = unreachable, 'x' = time may be in error, '~' = time too variable.
|| .- xxxx [ yyyy ] +/- zzzz
|| Reachability register (octal) -. | xxxx = adjusted offset,
|| Log2(Polling interval) --. | | yyyy = measured offset,
|| \ | | zzzz = estimated error.
|| | | \
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^? node1 0 6 0 - +0ns[ +0ns] +/- 0ns
2.6关闭防火墙和selinux
#永久关闭防火墙
[root@node1 ~]# for i in {11..13}
do
ssh 192.168.1.$i "systemctl disable --now firewalld"
done
#永久关闭selinux
[root@node1 ~]# for i in {11..13}
do
ssh 192.168.1.$i "setenforce 0 && sed -i s/SELINUX=enforcing/SELINUX=disabled/g /etc/selinux/config"
done
2.7修改文件打开限制
[root@node1 ~]# vim /etc/security/limits.conf
#End of file
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
[root@node1 ~]# for i in {node2,node3}
do
scp /etc/security/limits.conf $i:/etc/security/limits.conf
done
2.8安装jdk
本次安装hadoop3.3.5,根据官网描述Apache Hadoop 3.3.5需要Java 8以上或Java 11才能运行,这里建议使用Java 8
查看habase与jdk对应版本,根据官方描述,建议安装使用 JDK8

#查看系统自带的jdk
[root@node1 ~]# rpm -qa | grep openjdk
#卸载系统自带的jdk
[root@node1 ~]# rpm -e --nodeps `rpm -qa | grep openjdk`
rpm:未给出要擦除的软件包
下载 jdk8 压缩包,选择对应操作系统的版本,下载地址如下:

如果你的CentOS 7系统是基于x86 64位架构的机器,应该下载jdk-8u371-linux-x64.tar.gz。如果你的CentOS 7系统是基于ARM 64位架构的机器,你应该下载jdk-8u371-linux-aarch64.tar.gz。
我们此处选择jdk-8u371-linux-x64.tar.gz 下载
#登录oracle账号下载
#如果官网下载太慢,我们可以选择国内镜像站加速下载
[root@node1 ~]# wget https://repo.huaweicloud.com/java/jdk/8u192-b12/jdk-8u192-linux-x64.tar.gz
#解压安装包
[root@node1 ~]# tar -xf jdk-8u371-linux-x64.tar.gz -C /usr/local/
#配置java环境变量
[root@node1 ~]# cat >> .bash_profile << 'EOF'
#Java环境变量
export JAVA_HOME=/usr/local/jdk1.8.0_371
export PATH=$PATH:$JAVA_HOME/bin
EOF
#让配置环境变量生效
[root@node1 ~]# source .bash_profile
#查看java版本
[root@node1 ~]# java -version
java version "1.8.0_371"
Java(TM) SE Runtime Environment (build 1.8.0_371-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.371-b11, mixed mode)
#其他节点重复上述步骤安装,或者直接发送过去
[root@node1 ~]# for i in {node2,node3}
do
scp -r /usr/local/jdk1.8.0_371/ $i:/usr/local/
scp /root/.bash_profile $i:/root/
done
#方法二,我们也可以通过配置yum源,通过yum安装
或者配置国内的阿里云在线镜像 (官网有配置方法) https://developer.aliyun.com/mirror/
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
#非阿里云ECS用户会出现 Couldn't resolve host 'mirrors.cloud.aliyuncs.com' 信息,不影响使用。用户也可自行修改相关配置: eg:
sed -i -e '/mirrors.cloud.aliyuncs.com/d' -e '/mirrors.aliyuncs.com/d' /etc/yum.repos.d/CentOS-Base.repo
3安装包选择
本篇文章将搭建基于 Hadoop3.3.5 ,并兼容其他软件的集群,我们其他软件尽量选择较新版本即可:
3.1Hadoop和HBase版本兼容关系
hadoop官网 https://hadoop.apache.org/
在HBase官网http://hbase.apache.org/book.html#basic.prerequisites 搜索Hadoop version support matrix定位到兼容表格位置,建议选择对号标识的版本,这种是官方测试过的。
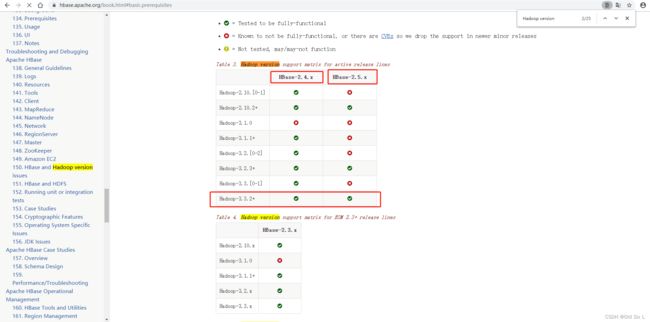
Hadoop-3.3.2+ 对应 HBase-2.4.x和HBase-2.5.x
3.2 Hadoop与Hive版本对应关系
http://hive.apache.org/downloads.html
打开Hive官网下载界面,上面有说明Hive和Hadoop版本对应的关系如下:

表示 Hive3.1.3 兼容 Hadoop3.x.y 版本
我们选择hive3.1.3
3.3HBase和Hive版本兼容
https://cwiki.apache.org/confluence/display/Hive/HBaseIntegration
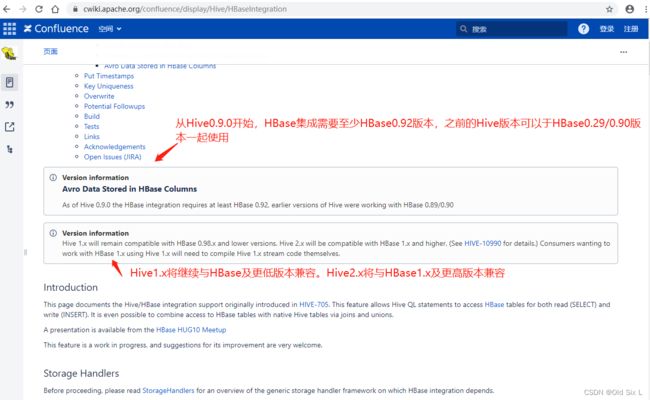
3.4HBase与zookeeper版本对应
http://hbase.apache.org/book.html#basic.prerequisites
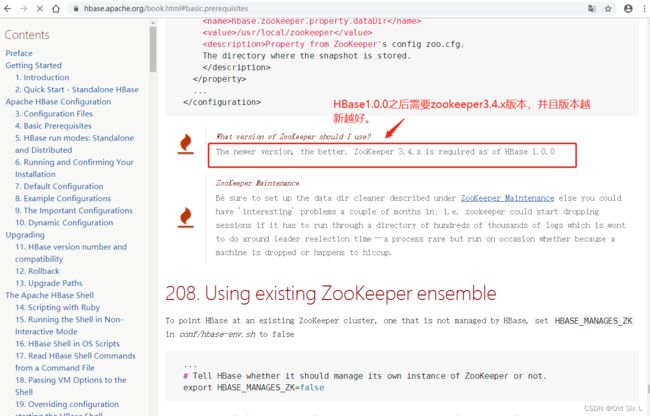
由此,我最终选择 Zookeeper3.7.1 +Hadoop3.3.5 + Spark-3.2.4 + Flink-1.16.1 + Kafka2.12-3.4.0 + HBase2.4.17 + Hive3.1.3
4 集群部署
4.1部署zookeeper集群
官网https://zookeeper.apache.org/
Apache ZooKeeper 3.7.1 (latest stable release)
下载地址Apache ZooKeeper 3.7.1(asc, sha512)
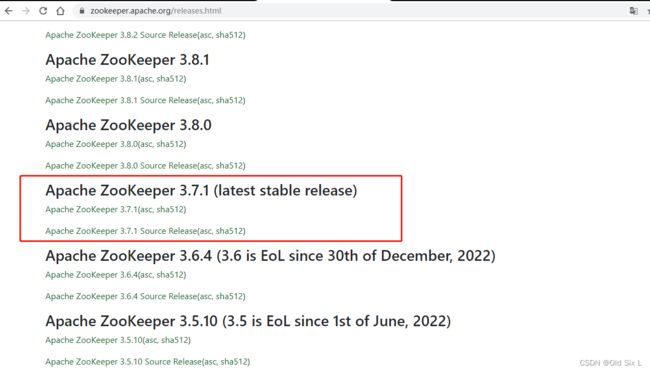
4.1.1zookeeper安装包下载
[root@node1 ~]# wget https://dlcdn.apache.org/zookeeper/zookeeper-3.7.1/apache-zookeeper-3.7.1-bin.tar.gz --no-check-certificate
#如果wget下载太慢,可以安装axel 下载安装包
[root@node1 ~]# wget http://alioth.debian.org/frs/download.php/3015/axel-2.17.11.tar.gz
[root@node1 ~]# yum -y install gcc gcc-c++ openssl-devel
[root@node1 ~]# tar -xvf axel-2.17.11.tar.gz -C /usr/local/
[root@node1 ~]# cd /usr/local/axel-2.17.11/
[root@node1 axel-2.17.11]# ./configure
[root@node1 axel-2.17.11]# make && make install
配置yum文件
[root@node1 axel-2.17.11]# cd /etc/yum/pluginconf.d/
[root@node1 pluginconf.d]# wget http://www.ha97.com/code/axelget.conf
[root@node1 lib]# cd /usr/lib/yum-plugins/
[root@node1 yum-plugins]# wget http://www.ha97.com/code/axelget.py
[root@node1 yum-plugins]# grep plugins /etc/yum.conf
plugins=1
更改默认线程数,默认是10,改成32提高下载速度
[root@node1 yum-plugins]# vim /usr/lib/yum-plugins/axelget.py
maxconn=64
使用参数如下:
一般使用:axel url(下载文件地址);
限速使用:加上 -s 参数,如 -s 10240,即每秒下载的字节数,这里是 10 Kb;
-k 忽略SSL证书错误
限制连接数:加上 -n 参数,如 -n 10,即打开10个连接。如下:
axel -a -n 10 http://xxx.com/1111.zip
4.1.2配置大数据目录并解压缩
#配置集群统一目录,方便管理
[root@node1 ~]# mkdir /opt/bigdata
#解压缩并重命名
[root@node1 ~]# tar -xf apache-zookeeper-3.7.1-bin.tar.gz -C /opt/bigdata/
[root@node1 ~]# cd /opt/bigdata/
[root@node1 bigdata]# mv apache-zookeeper-3.7.1-bin zookeeper
4.1.3 配置zookeeper
[root@node1 bigdata]# cd zookeeper/conf/
#zk配置文件是 zoo.cfg ,创建并配置
[root@node1 conf]# cp zoo_sample.cfg zoo.cfg
#修改完如下
[root@node1 conf]# grep -Ev '^#|^$' zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/bigdata/zookeeper/data
clientPort=2181
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
说明:Zookeeper 集群中有三种角色:Leader、Follower 和 Observer。在一个 Zookeeper 集群中,同一时刻只会有一个 Leader,其他都是 Follower 或 Observer。Zookeeper 的配置很简单,每个节点的配置文件(zoo.cfg)都是一样的,只有 myid 文件不一样 ,Observer 角色是在 Zookeeper 集群中的一种特殊角色,它的作用是在集群中提供一个只读服务,不参与 Leader 选举,不参与写操作,只是接收 Leader 发送的数据变更通知,并将这些变更通知转发给客户端
#创建配置文件中的目录,并配置myid
[root@node1 conf]# cd ..
[root@node1 zookeeper]# mkdir data
[root@node1 zookeeper]# echo 1 > data/myid
说明:
对于ZooKeeper集群来说,每个节点都需要配置一个唯一的myid。myid是一个文本文件,其中包含一个整数,表示当前节点的ID。这个ID在整个集群中必须是唯一的,并且与其他节点的myid不同。
配置myid的目的是为了确保每个节点都能被正确地识别和识别为集群的一部分。当启动ZooKeeper节点时,它将读取myid文件中的ID,并使用该ID来标识自己。如果节点的myid与集群中的其他节点不匹配,它将被视为一个独立的节点,无法与其他节点进行通信和同步数据。
因此,配置myid是ZooKeeper集群中的一个重要步骤,确保节点能够正确地加入和工作在集群中。
4.1.4 配置zk环境变量,方便我们命令的执行
[root@node1 zookeeper]# cd
[root@node1 ~]# cat >> .bash_profile << 'EOF'
#zookeeper环境变量
export ZOOKEEPER_HOME=/opt/bigdata/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
EOF
[root@node1 ~]# source .bash_profile
4.1.5分发文件到其他节点并配置
#将zookeeper文件夹发送到其他节点
[root@node1 ~]# for i in {node2,node3}
do
scp -r /opt/bigdata/ $i:/opt/
scp .bash_profile $i:/root/
done
#修改其他节点的myid
[root@node2 ~]# echo 2 > /opt/bigdata/zookeeper/data/myid
[root@node3 ~]# echo 3 > /opt/bigdata/zookeeper/data/myid
4.1.6启动,停止,重启服务
#所有节点启动,需要在每个节点执行
zkServer.sh start
#编写脚本对zookeeper集群实现批量启动,停止,重启
[root@node1 ~]# cat > zkserver_manage_all.sh << 'EOF'
#!/bin/bash
echo "$1 zkServer ..."
for i in node1 node2 node3
do
ssh $i "source /root/.bash_profile && zkServer.sh $1"
done
EOF
#添加可执行权限
[root@node1 ~]# chmod +x zkserver_manage_all.sh
#启动
[root@node1 ~]# ./zkserver_manage_all.sh start
#停止
[root@node1 ~]# ./zkserver_manage_all.sh stop
#重启
[root@node1 ~]# ./zkserver_manage_all.sh restart
[root@node1 ~]# mv zkserver_manage_all.sh /opt/bigdata/zookeeper/bin/
4.1.7查看状态
#查看服务状态,只能查看执行节点的zookeeper状态
zkServer.sh status
#通过编写脚本实现批量检查
[root@node1 ~]# cat > zkstatus_all.sh << 'EOF'
#!/bin/bash
for node in {node1,node2,node3}
do
status=$(ssh $node 'source /root/.bash_profile && zkServer.sh status 2>&1 | grep Mode')
if [[ $status == "Mode: follower" ]];then
echo "$node是从节点"
elif [[ $status == "Mode: leader" ]];then
echo "$node是主节点"
else
echo "未查询到$node节点zookeeper状态,请检查服务"
fi
done
EOF
#添加执行权限
[root@node1 ~]# chmod +x zkstatus_all.sh
#通过脚本查看主从
[root@node1 ~]# ./zkstatus_all.sh
node1是从节点
node2是主节点
node3是从节点
[root@node1 ~]# mv zkstatus_all.sh /opt/bigdata/zookeeper/bin/
4.2部署Hadoop集群
Apache Hadoop官网:https://hadoop.apache.org/
介绍:
Hadoop 是一个开源的分布式计算平台,其中包含了一个分布式文件系统 HDFS。在 HDFS 中,NameNode 和 DataNode 是两个重要的组件。NameNode 是 HDFS 的主服务器,负责管理文件系统的命名空间和客户端对文件的访问。DataNode 是存储实际数据块的服务器,负责存储和检索数据块。
具体来说,NameNode 负责维护整个文件系统的目录树和文件元数据信息,包括文件名、文件属性、文件块列表等。它还负责处理客户端的读写请求,并将这些请求转发给相应的 DataNode。DataNode 负责存储和检索数据块,并向 NameNode 定期汇报自己所持有的数据块列表。
NameNode 和 DataNode 的主要区别在于它们所管理的信息不同。NameNode 管理文件系统的元数据信息,而 DataNode 管理实际的数据块。
本次安装的Hadoop集群为3个节点,两个namenode,三个datanode,规划如下:
| ip | NameNode | DataNode | |
|---|---|---|---|
| 192.168.1.11 | node1 | √ | √ |
| 192.168.1.12 | node2 | √ | √ |
| 192.168.1.13 | node3 | × | √ |
4.2.1下载hadoop3.3.5安装包
下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.3.5/
#下载
[root@node1 ~]# wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.5/hadoop-3.3.5.tar.gz
4.2.2 解压缩并配置环境变量
#解压缩
[root@node1 ~]# tar -xf hadoop-3.3.5.tar.gz -C /opt/bigdata/
[root@node1 ~]# mv /opt/bigdata/hadoop-3.3.5/ /opt/bigdata/hadoop
#配置hadoop环境变量
[root@node1 ~]# cat >> /root/.bash_profile << 'EOF'
#Hadoop环境变量
export HADOOP_HOME=/opt/bigdata/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
EOF
[root@node1 ~]# source /root/.bash_profile
#验证
[root@node1 ~]# hadoop version
Hadoop 3.3.5
Source code repository https://github.com/apache/hadoop.git -r 706d88266abcee09ed78fbaa0ad5f74d818ab0e9
Compiled by stevel on 2023-03-15T15:56Z
Compiled with protoc 3.7.1
From source with checksum 6bbd9afcf4838a0eb12a5f189e9bd7
This command was run using /opt/bigdata/hadoop-3.3.5/share/hadoop/common/hadoop-common-3.3.5.jar
4.2.3 规划并创建hadoop需要用到的目录
#所有节点执行,不然启动服务会报错,可以根据自己hdfs-site.xml文件自行配置
[root@node1 ~]# mkdir -p /data/hadoop/tmp
[root@node1 ~]# mkdir -p /data/hadoop/hdfs/name
[root@node1 ~]# mkdir -p /data/hadoop/hdfs/data
[root@node1 ~]# mkdir -p /data/hadoop/hdfs/ha/jn
[root@node2 ~]# mkdir -p /data/hadoop/tmp
[root@node2 ~]# mkdir -p /data/hadoop/hdfs/name
[root@node2 ~]# mkdir -p /data/hadoop/hdfs/data
[root@node2 ~]# mkdir -p /data/hadoop/hdfs/ha/jn
[root@node3 ~]# mkdir -p /data/hadoop/tmp
[root@node3 ~]# mkdir -p /data/hadoop/hdfs/name
[root@node3 ~]# mkdir -p /data/hadoop/hdfs/data
[root@node3 ~]# mkdir -p /data/hadoop/hdfs/ha/jn
4.2.4配置集群节点
workers文件是用来指定Hadoop集群中所有的工作节点(即DataNode和NodeManager节点)的配置文件
[root@node1 ~]# cd /opt/bigdata/hadoop/etc/hadoop/
[root@node1 hadoop]# cat > workers << 'EOF'
node1
node2
node3
EOF
4.2.5修改核心配置文件
#三个节点配置一样
[root@node1 hadoop]# vim core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://myclustervalue>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/data/hadoop/tmpvalue>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>node1:2181,node2:2181,node3:2181value>
property>
<property>
<name>ipc.client.connect.max.retriesname>
<value>100value>
property>
<property>
<name>ipc.client.connect.retry.intervalname>
<value>10000value>
property>
<property>
<name>io.file.buffer.sizename>
<value>65536value>
property>
configuration>
4.2.6修改HDFS配置文件
#多master高可用配置,所有节点配置一样
#HA中的NameNode最少要有2个,也可以配置更多。建议不要超过5个,最好是3个,因为更多的NameNode意味着更多的通讯开销。
#fencing 和 edits 在实验中,如果你不想配置,可以去掉
[root@node1 hadoop]# vim hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservicesname>
<value>myclustervalue>
property>
<property>
<name>dfs.ha.namenodes.myclustername>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1name>
<value>node1:9000value>
property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1name>
<value>node1:50070value>
property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2name>
<value>node2:9000value>
property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2name>
<value>node2:50070value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>/data/hadoop/hdfs/namevalue>
<description>namenode上存储hdfs命名空间元数据 description>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/data/hadoop/hdfs/datavalue>
<description>datanode上数据块的物理存储位置description>
property>
<property>
<name>dfs.replicationname>
<value>3value>
<description>副本个数,默认是3,应小于datanode数量description>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.permissions.enabledname>
<value>falsevalue>
property>
<property>
<name>dfs.datanode.max.transfer.threadsname>
<value>4096value>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>sshfencevalue>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/root/.ssh/id_rsavalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://node1:8485;node2:8485/myclustervalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/data/hadoop/hdfs/ha/jnvalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.myclustername>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
configuration>
如果搭建的是单namenode节点,用以下配置即可
#单 namenode 节点配置hdfs-site.xml 所有节点配置一样
<configuration>
<property>
<name>dfs.namenode.rpc-addressname>
<value>node1:9000value>
property>
<property>
<name>dfs.namenode.http-addressname>
<value>node1:50070value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>node1:50090value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>/data/hadoop/hdfs/namevalue>
<description>namenode上存储hdfs名字空间元数据 description>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/data/hadoop/hdfs/datavalue>
<description>datanode上数据块的物理存储位置description>
property>
<property>
<name>dfs.replicationname>
<value>2value>
<description>副本个数,默认是3,应小于datanode数量description>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.permissions.enabledname>
<value>falsevalue>
property>
configuration>
#单节点配置 core-site.xml 所有节点配置一样
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://node1:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/data/hadoop/tmpvalue>
property>
<property>
<name>io.file.buffer.sizename>
<value>65536value>
property>
configuration>
4.2.7同步hadoop文件到其他节点
[root@node1 ~]# for i in {node2,node3}
> do
> scp -r /opt/bigdata/hadoop $i:/opt/bigdata/
> scp /root/.bash_profile $i:/root/
> done
4.2.8启动服务
#启动JN,格式化之前要优先启动JN,现在是两个nn,要通过JN传递数据。
[root@node1 ~]# hdfs --daemon start journalnode
[root@node2 ~]# hdfs --daemon start journalnode
#格式化NN,将node1作为主节点
[root@node1 ~]# hdfs namenode -format
#格式化NameNode会在指定的NameNode数据目录中创建一个名为current的子目录,用于存储NameNode的元数据和命名空间信息
[root@node1 ~]# ll /data/hadoop/hdfs/name/
总用量 0
drwx------ 2 root root 112 7月 21 21:51 current
#node2上的nn作为主备,在node2执行拷贝元数据之前,需要先启动node1上的namanode
[root@node1 ~]# hdfs --daemon start namenode
#拷贝元数据,在Hadoop HDFS中初始化一个备用的NameNode节点。当主要的NameNode节点出现故障时,备用的NameNode节点就可以快速启动并接管服务,而无需重新加载整个文件系统的元数据,提供高可用性。注意在node2上执行
[root@node2 ~]# hdfs namenode -bootstrapStandby
#启动node2上的namenode
[root@node2 ~]# hdfs --daemon start namenode
#格式化zk,用于监控和管理Hadoop HDFS中的主备NameNode节点切换的组件。此命令会创建一个ZooKeeper目录结构,并将初始的主备NameNode节点信息存储在ZooKeeper中。这样,ZKFC就可以使用ZooKeeper来进行主备节点的管理和切换。
#在设置Hadoop HDFS的高可用性环境时,需要先使用hdfs namenode -bootstrapStandby命令初始化备用的NameNode节点,然后使用hdfs zkfc -formatZK 命令初始化ZKFC。这两个命令的组合可以确保Hadoop HDFS的主备节点切换的可靠性和高可用性。
[root@node1 ~]# hdfs zkfc -formatZK
#启动zk客户端
zkCli.sh #可以通过ls查看目录结构
[zk: localhost:2181(CONNECTED) 0] ls /
[hadoop-ha, zookeeper]
#启动datanode,或者下面用集群命令 start-dfs.sh 一键启动所有服务
hdfs --daemon start datanode
#注意:以后启动hdfs就只需要先启动zookeeper,然后执行start-dfs.sh就可以了
#停止所有节点
[root@node1 ~]# stop-dfs.sh
Stopping namenodes on [node1 node2]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Stopping datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Stopping journal nodes [node2 node1]
ERROR: Attempting to operate on hdfs journalnode as root
ERROR: but there is no HDFS_JOURNALNODE_USER defined. Aborting operation.
Stopping ZK Failover Controllers on NN hosts [node1 node2]
ERROR: Attempting to operate on hdfs zkfc as root
ERROR: but there is no HDFS_ZKFC_USER defined. Aborting operation.
#上述报错解决办法
[root@node1 ~]# cat >> /root/.bash_profile << 'EOF'
#设置hdfs集群启动时,允许root用户启动
HDFS_NAMENODE_USER=root
export HDFS_NAMENODE_USER
HDFS_DATANODE_USER=root
export HDFS_DATANODE_USER
HDFS_JOURNALNODE_USER=root
export HDFS_JOURNALNODE_USER
HDFS_ZKFC_USER=root
export HDFS_ZKFC_USER
EOF
[root@node1 ~]# source .bash_profile
#同步环境变量文件到其他节点
[root@node1 ~]# for i in {node2,node3}
do
scp /root/.bash_profile $i:/etc/
done
#再次执行
[root@node1 ~]# stop-dfs.sh
Stopping namenodes on [node1 node2]
node2: ERROR: JAVA_HOME is not set and could not be found.
node1: ERROR: JAVA_HOME is not set and could not be found.
Stopping datanodes
node1: ERROR: JAVA_HOME is not set and could not be found.
node3: ERROR: JAVA_HOME is not set and could not be found.
node2: ERROR: JAVA_HOME is not set and could not be found.
Stopping journal nodes [node2 node1]
node2: ERROR: JAVA_HOME is not set and could not be found.
node1: ERROR: JAVA_HOME is not set and could not be found.
Stopping ZK Failover Controllers on NN hosts [node1 node2]
node1: ERROR: JAVA_HOME is not set and could not be found.
node2: ERROR: JAVA_HOME is not set and could not be found.
#上述报错解决办法
[root@node1 ~]# cd /opt/bigdata/hadoop/etc/hadoop/
[root@node1 hadoop]# vim hadoop-env.sh
JAVA_HOME=/usr/local/jdk1.8.0_371
#同步文件到其他节点
[root@node1 hadoop]# for i in {node2,node3}
do
scp hadoop-env.sh $i:/opt/bigdata/hadoop/etc/hadoop/
done
[root@node1 hadoop]# stop-dfs.sh
Stopping namenodes on [node1 node2]
Stopping datanodes
Stopping journal nodes [node2 node1]
Stopping ZK Failover Controllers on NN hosts [node1 node2]
#启动所有节点
[root@node1 hadoop]# start-dfs.sh
Starting namenodes on [node1 node2]
Starting datanodes
node3: WARNING: /opt/bigdata/hadoop/logs does not exist. Creating.
Starting journal nodes [node2 node1]
Starting ZK Failover Controllers on NN hosts [node1 node2]
#验证高可用
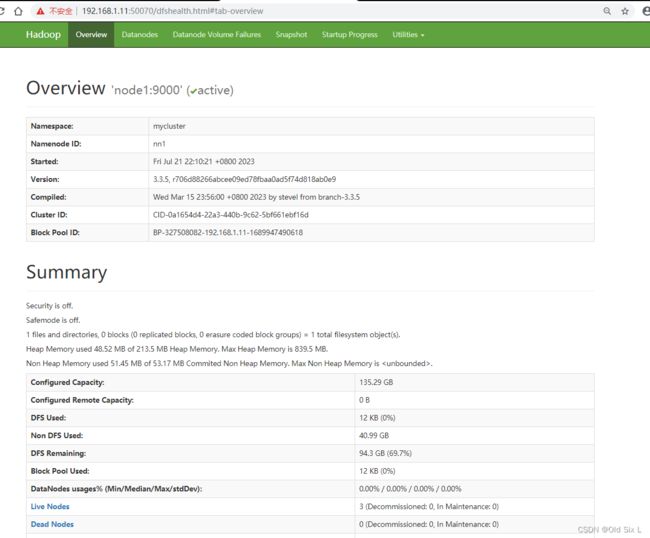
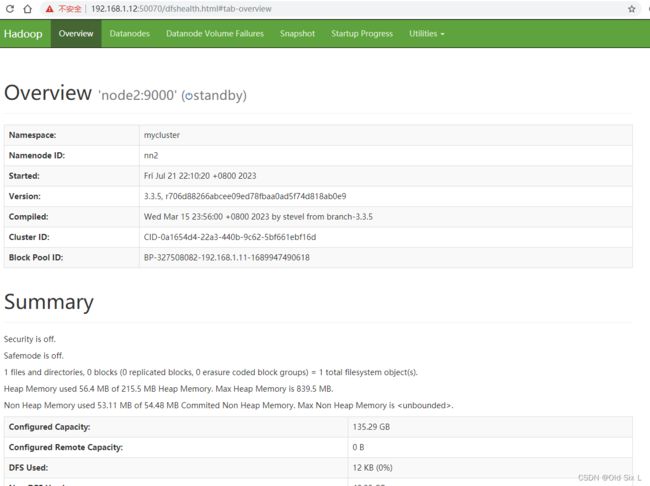
[root@node1 hadoop]# hdfs haadmin -getServiceState nn1
active
[root@node1 hadoop]# hdfs haadmin -getServiceState nn2
standby
#如果两台都是standby,可以通过 hdfs haadmin -transitionToActive --forcemanual nn1 命令强制将nn1转换为为active
#访问页面验证
到浏览器访问,192.168.1.11:50070 和 192.168.1.12:50070 验证
4.2.9配置yarn和MapReduce
介绍:
yarn(yet another resource negotiator)是一个通用分布式资源管理系统和调度平台,为上层应用提供统一的资源管理和调度。在集群利用率、资源统一管理和数据共享等方面带来巨大好处。
-
资源管理系统:集群的硬件资源,如内存、CPU等。
-
调度平台:多个程序同时申请计算资源如何分配,调度的规则(算法)。
-
通用:不仅仅支持mapreduce程序,理论上支持各种计算程序。yarn不关心你干什么,只关心你要资源,在有的情况下给你,用完之后还我。
-
MapReduce和YARN是Apache Hadoop生态系统中的两个重要组件。
MapReduce是一种计算模型,用于处理大规模数据集的并行计算。它将计算任务分解为两个主要阶段:Map阶段和Reduce阶段。在Map阶段,数据被分割为一系列的键值对,然后通过一系列的映射函数进行处理,生成中间结果。在Reduce阶段,中间结果根据键进行分组,然后通过一系列的归约函数进行处理,生成最终的结果。MapReduce模型具有高度的可扩展性和容错性,适用于处理大规模的数据集。
YARN(Yet Another Resource Negotiator)是Hadoop的资源管理器,用于管理和分配集群中的计算资源。YARN的核心思想是将资源管理和作业调度分离开来,以提高集群的利用率和灵活性。YARN由两个主要组件组成:资源管理器(ResourceManager)和节点管理器(NodeManager)。资源管理器负责整个集群的资源分配和调度,而节点管理器负责在每个节点上管理和监控计算资源。通过YARN,Hadoop集群可以同时运行多个计算框架(如MapReduce、Spark等),并有效地管理和利用集群资源。
总结起来,MapReduce是一种计算模型,用于处理大规模数据集的并行计算,而YARN是Hadoop的资源管理器,用于管理和分配集群中的计算资源。它们共同构成了Hadoop生态系统中的核心组件,为大规模数据处理提供了强大的计算和资源管理能力。
修改mapred-site.xml
[root@node1 hadoop]# pwd
/opt/bigdata/hadoop/etc/hadoop
[root@node1 hadoop]# vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
<description>指定mapreduce使用yarn框架description>
property>
configuration>
修改yarn-site.xml
[root@node1 hadoop]# vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
<description>是否开启高可用description>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>yrcvalue>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>node1value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>node2value>
property>
<property>
<name>yarn.resourcemanager.address.rm1name>
<value>node1:8032value>
property>
<property>
<name>yarn.resourcemanager.address.rm2name>
<value>node2:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1name>
<value>node1:8030value>
property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2name>
<value>node2:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1name>
<value>node1:8031value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2name>
<value>node2:8031value>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>node1:2181,node2:2181,node3:2181value>
property>
<property>
<name>yarn.resourcemanager.recovery.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.store.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStorevalue>
property>
<property>
<name>yarn.nodemanager.env-whitelistname>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLAS SPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOMEvalue>
property>
configuration>
同步配置文件到其他节点
[root@node1 hadoop]# for i in {node2,node3}
do
scp mapred-site.xml yarn-site.xml $i:/opt/bigdata/hadoop/etc/hadoop/
done
启动yarn服务
#启动服务
[root@node1 hadoop]# start-yarn.sh
Starting resourcemanagers on [ node1 node2]
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
#解决办法,和hdfs一样
[root@node1 hadoop]# cat >> /root/.bash_profile << 'EOF'
#允许root用户启动yarn集群服务
YARN_RESOURCEMANAGER_USER=root
export YARN_RESOURCEMANAGER_USER
YARN_NODEMANAGER_USER=root
export YARN_NODEMANAGER_USER
EOF
[root@node1 hadoop]# source /root/.bash_profile
#同步文件到其他节点
[root@node1 hadoop]# for i in {node2,node3}
do
scp /root/.bash_profile $i:/root/
done
[root@node1 hadoop]# start-yarn.sh
Starting resourcemanagers on [ node1 node2]
Starting nodemanagers
#查看resourcemanagers主从
[root@node1 hadoop]# yarn rmadmin -getServiceState rm1
active
[root@node1 hadoop]# yarn rmadmin -getServiceState rm2
standby
#如果某些原因yarn没有启动成功,可以单独启动
yarn-daemon.sh start resourcemanager
验证
浏览器访问 192.168.1.11:8088

浏览器访问 192.168.1.12:8088
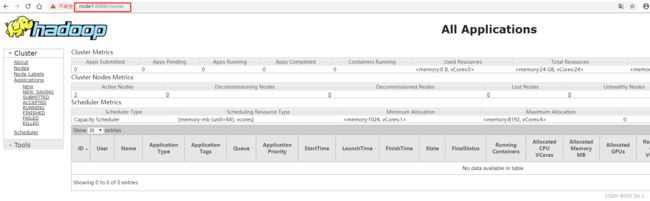
可以看到自动跳转到http://node1:8088/cluster,前提需要在电脑的hosts里配置上如下信息,不然ip变成node1时访问会失败
#配置电脑文件路径
C:\Windows\System32\drivers\etc\hosts
192.168.1.11 node1
192.168.1.12 node2
点击图上的Active Nodes可以看到节点信息,如果有节点 datanode没起来 可以用hdfs --daemon start datanode单独启动, 或查看日志排查
#jps命令查看服务,可看到各个节点上的服务
[root@node1 hadoop]# jps
5265 DFSZKFailoverController
4835 DataNode
2133 QuorumPeerMain
4693 NameNode
5079 JournalNode
6167 ResourceManager
6775 Jps
6319 NodeManager
[root@node2 ~]# jps
2752 DataNode
1873 QuorumPeerMain
3505 Jps
2851 JournalNode
3316 NodeManager
3221 ResourceManager
2937 DFSZKFailoverController
2670 NameNode
[root@node3 ~]# jps
2114 DataNode
1860 QuorumPeerMain
2390 Jps
2263 NodeManager
至此,hadoop高可用集群部署完成。
#服务启动
start-dfs.sh
start-yarn.sh
#服务停止
stop-dfs.sh
stop-yarn.sh
#访问hdfs目录,查看是否正常
[root@node3 ~]# hdfs dfs -ls /
#hdfs相关命令
hdfs dfsadmin -report #获取HDFS集群的详细报告信息:数据节点状态,容量和使用情况,块数量,网络拓扑信息
hdfs dfsadmin -safemode get #查看hdfs是否为安全模式
hdfs haadmin -getServiceState nn1 #nn1 为配置文件中设置的namenode的id
hdfs haadmin -getServiceState nn2
#hdfs相关命令
hdfs dfs -mkdir -p /a/b/c
hdfs dfs -ls /a/b/
touch mytest.txt
hdfs dfs -put mytest.txt /a/b/c
hdfs dfs -get /a/b/c/mytest.txt
hdfs dfs -cp /a/b/c/mytest.txt /home/
hdfs dfs -cat /a/b/c/mytest.txt
hdfs dfs -mv /a/b/c/mytest.txt /a/
hdfs dfs -du [-s] [-h] /a
hdfs dfs -rm /a/mytest.txt
hdfs dfs -chown oldsixl /a/b/c
hdfs dfs -chomd 777 /a/b/c
4.3部署Spark集群(yarn实现企业级部署)
官网https://spark.apache.org/
集群节点规划,双master实现高可用,所有节点也可以同时配置成master和worker
| 节点 | 角色 |
|---|---|
| node1 | Master |
| node2 | Master,slave |
| node3 | slave |
4.3.1下载spark安装包
官网https://spark.apache.org/

[root@node1 ~]# axel -k -n 64 https://dlcdn.apache.org/spark/spark-3.2.4/spark-3.2.4-bin-hadoop3.2-scala2.13.tgz
4.3.2解压缩并配置环境变量
#解压缩
[root@node1 ~]# tar -xf spark-3.2.4-bin-hadoop3.2-scala2.13.tgz -C /opt/bigdata/
[root@node1 ~]# mv /opt/bigdata/spark-3.2.4-bin-hadoop3.2-scala2.13/ /opt/bigdata/spark
#配置环境变量
[root@node1 ~]# cat >> .bash_profile << 'EOF'
#Spark环境变量
export SPARK_HOME=/opt/bigdata/spark
export PATH=$PATH:$SPARK_HOME/bin
EOF
[root@node1 ~]# source .bash_profile
4.3.3配置spark文件
[root@node1 ~]# cd /opt/bigdata/spark/conf/
[root@node1 conf]# cp spark-env.sh.template spark-env.sh
#修改spark-env.sh
[root@node1 conf]# grep -v ^# spark-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_371/
export HADOOP_CONF_DIR=/opt/bigdata/hadoop/etc/hadoop/
export YARN_CONF_DIR=/opt/bigdata/hadoop/etc/hadoop/
export SPARK_MASTER_IP=node1
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8090
export SPARK_WORKER_WEBUI_PORT=8091
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/opt/bigdata/zookeeper"
说明:
JAVA_HOEM:设置Java安装目录的路径
HADOOP_CONF_DIR:设置Hadoop的配置目录路径
YARN_CONF_DIR:设置YARN的配置目录路径,YARN是Hadoop的资源管理器
SPARK_MASTER_IP:设置Spark主节点的IP地址或主机名。Spark主节点负责协调集群中的各个工作节点。
SPARK_MASTER_PORT:设置Spark主节点的端口号。通过该端口,工作节点可以与Spark主节点进行通信。
SPARK_MASTER_WEBUI_PORT:设置Spark主节点的Web界面端口号。可以通过该端口访问Spark主节点的Web界面。
SPARK_WORKER_WEBUI_PORT:设置Spark工作节点的Web界面端口号。可以通过该端口访问Spark工作节点的Web界面。
[root@node1 conf]# cp workers.template workers
#修改workers文件
[root@node1 conf]# cat > workers << EOF
node2
node3
EOF
4.3.4复制hadoop配置到spark配置目录下
[root@node1 conf]# cd /opt/bigdata/hadoop/etc/hadoop/
[root@node1 hadoop]# cp core-site.xml hdfs-site.xml /opt/bigdata/spark/conf/
4.3.5将spark文件分发到其他节点
[root@node1 hadoop]# for i in {node2,node3}
do
scp -r /opt/bigdata/spark $i:/opt/bigdata/
scp /root/.bash_profile $i:/root/
done
#在node2上配置备用master节点
[root@node2 ~]# vim /opt/bigdata/spark/conf/spark-env.sh
#将 export SPARK_MASTER_IP=node1 改为
export SPARK_MASTER_IP=node2
4.3.6启动spark
#由于启动命令和hadoop下的命令文件名一样,我们需要cd到spark目录下执行
[root@node1 hadoop]# cd /opt/bigdata/spark/sbin/
[root@node1 sbin]# ./start-all.sh
#启动备master
[root@node2 ~]# cd /opt/bigdata/spark/sbin
[root@node2 sbin]# ./start-master.sh
#jps查看主节点都有Master,node3节点有Worker
页面访问查看主备
浏览器访问 192.168.1.11:8090 可以看到上面状态 Status: ALIVE
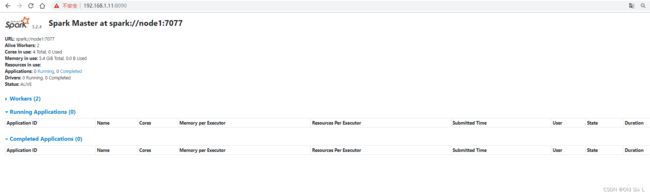
浏览器访问 192.168.1.12:8090 可以看到上面状态 Status: STANDBY

可以看到两个master,node1节点alive为主,node2节点standby为备用master
我们关闭node1上的master
[root@node1 sbin]# jps
5265 DFSZKFailoverController
4835 DataNode
2133 QuorumPeerMain
4693 NameNode
6901 Master
5079 JournalNode
6167 ResourceManager
7191 Jps
6319 NodeManager
[root@node1 sbin]# kill -9 6901
刷新页面,192.168.1.11:8090 已经访问不到了,我们在访问node2,多刷新几次,可以看到master已经切换到node2
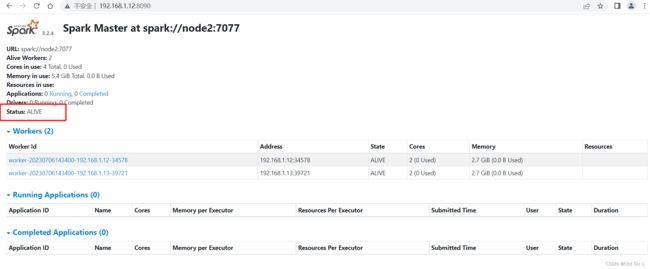
再次启动node1上的master,关闭node2 可以看到,master切换回了node1,状态为alive
4.3.7运行测试
[root@node1 sbin]# spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster /opt/bigdata/spark/examples/jars/spark-examples_2.13-3.2.4.jar
/bin/bash: /bin/java: No such file or directory
#解决办法
[root@node1 sbin]# ln -s /usr/local/jdk1.8.0_371/bin/java /bin/java
[root@node2 ~]# ln -s /usr/local/jdk1.8.0_371/bin/java /bin/java
[root@node3 ~]# ln -s /usr/local/jdk1.8.0_371/bin/java /bin/java
#再次测试,没有报错了
[root@node1 sbin]# spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster /opt/bigdata/spark/examples/jars/spark-examples_2.13-3.2.4.jar
client token: N/A
diagnostics: N/A
ApplicationMaster host: node2
ApplicationMaster RPC port: 44945
queue: default
start time: 1689952278098
final status: SUCCEEDED
tracking URL: http://node1:8088/proxy/application_1689949756263_0002/
user: root
查看yarn
浏览器访问 http://192.168.1.11:8088
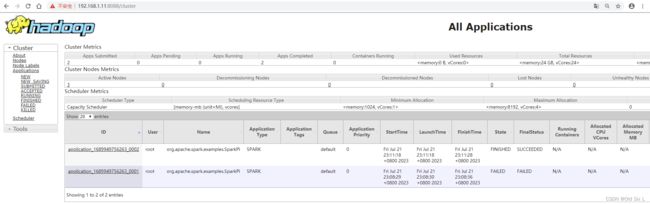
可以看到执行的任务,第一次失败,第二次成功
4.3.8配置历史服务器
4.3.8.1配置yarn历史服务器
#修改Hdfs配置
[root@node1 ~]# cd /opt/bigdata/hadoop/etc/hadoop/
# vim mapred-site.xml 编辑 添加以下内容
<!--Spark on Yarn-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
#修改yarn配置文件
# vim yarn-site.xml 编辑添加以下内容
<!--Spark on Yarn-->
<!-- 是否开启聚合日志 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 配置日志服务器的地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs/</value>
</property>
<!-- 配置日志过期时间,单位秒 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
#同步配置到其他节点以及saprk目录下
[root@node1 ~]# cd /opt/bigdata/hadoop/etc/hadoop/
[root@node1 hadoop]# for i in {node1,node2,node3}
do
scp mapred-site.xml yarn-site.xml $i:/opt/bigdata/hadoop/etc/hadoop/
scp mapred-site.xml yarn-site.xml $i:/opt/bigdata/spark/conf/
done
4.3.8.2配置spark历史服务器
#修改配置文件
[root@node1 sbin]# cd ../conf/
[root@node1 conf]# cp spark-defaults.conf.template spark-defaults.conf
[root@node1 conf]# vim spark-defaults.conf
#添加或者放开注释并修改
spark.eventLog.enabled true
spark.eventLog.compress true
spark.eventLog.dir hdfs://mycluster/spark-logs
spark.yarn.historyServer.address node1:18080,node2:18080
spark.history.ui.port 18080
spark.history.fs.logDirectory hdfs://mycluster/spark-logs
spark.history.retainedApplications 30
#说明:
spark.eventLog.enabled 设置为 true 表示启用Spark事件日志记录功能。
spark.eventLog.compress 指定Spark事件日志是否需要进行压缩
spark.eventLog.dir 指定了事件日志的存储路径
spark.yarn.historyServer.address 指定了YARN历史服务器的地址
spark.history.ui.port 指定了Spark历史服务器UI的端口号
spark.history.fs.logDirectory 指定了历史记录文件在文件系统中的存储路径
spark.history.retainedApplications 指定了历史服务器要保留的应用程序数量,设置为 30,表示历史服务器将保留最近提交的30个应用程序的历史记录。
#同步上述文件至其他节点
[root@node1 conf]# scp spark-defaults.conf node2:/opt/bigdata/spark/conf/
[root@node1 conf]# scp spark-defaults.conf node3:/opt/bigdata/spark/conf/
#创建时间日志的存储路径,需要在启动历史服务器之前创建,不然报错找不到路径或文件
[root@node1 conf]# hdfs dfs -mkdir /spark-logs
4.3.8.3重启服务并验证
#重启hdfs,yarn,spark
#停止spark服务
[root@node1 ~]# $SPARK_HOME/sbin/stop-all.sh
#停止yarn,hdfs
[root@node1 ~]# $HADOOP_HOME/sbin/stop-all.sh
#启动hadoop服务
[root@node1 ~]# which start-all.sh
/opt/bigdata/hadoop/sbin/start-all.sh
[root@node1 ~]# start-all.sh
#启动yarn历史服务器
[root@node1 ~]# mapred --daemon start historyserver
#启动spark
[root@node1 ~]# $SPARK_HOME/sbin/start-all.sh
#启动spark历史服务器
[root@node1 ~]# $SPARK_HOME/sbin/start-history-server.sh
[root@node2 ~]# $SPARK_HOME/sbin/start-history-server.sh
#停止spark历史服务器
# $SPARK_HOME/sbin/stop-history-server.sh
浏览器访问查看
配置 C:\Windows\System32\drivers\etc\hosts 添加
192.168.1.11 node1
192.168.1.12 node2
192.168.1.13 node3
访问 http://192.168.1.11:19888
访问 http://192.168.1.11:18080
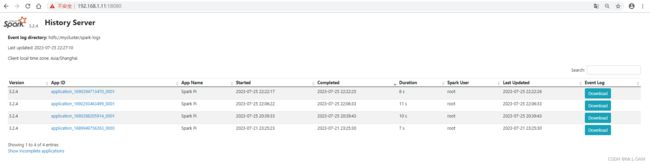
查看日志



至此,spark集群部署完成
4.4部署Flink集群(yarn实现企业级部署)
集群资源由yarn集群统一调度和管理,提高利用率,flink中jobmanager的高可用操作就由yarn集群来管理实现。
官网https://flink.apache.org/
4.4.1下载安装包

flink-1.16.1-bin-scala_2.12.tgz 是 Apache Flink 1.16.1 的二进制版本,已经编译好了,可以直接使用,而 flink-1.16.1-src.tgz 是 Apache Flink 1.16.1 的源代码版本,需要自行编译后才能使用。
[root@node1 ~]# axel -k -n 64 https://dlcdn.apache.org/flink/flink-1.16.1/flink-1.16.1-bin-scala_2.12.tgz
4.4.2解压缩并配置环境变量
#解压安装包
[root@node1 ~]# tar -xf flink-1.16.1-bin-scala_2.12.tgz -C /opt/bigdata/
[root@node1 ~]# mv /opt/bigdata/flink-1.16.1/ /opt/bigdata/flink
#配置环境变量
[root@node1 ~]# cat >> .bash_profile << 'EOF'
#Flink环境变量
export FLINK_HOME=/opt/bigdata/flink
export PATH=$PATH:$FLINK_HOME/bin
EOF
#让环境变量生效
[root@node1 ~]# source .bash_profile
4.4.3配置FLINK
#查看并修改flink的配置文件
[root@node1 ~]# cd /opt/bigdata/flink/conf/
#修改masters文件
[root@node1 conf]# cat > masters << 'EOF'
node1:8081
node2:8081
EOF
#修改workers文件
[root@node1 conf]# cat > workers << 'EOF'
node1
node2
node3
EOF
#修改flink-conf.yaml文件,如下
[root@node1 conf]# grep -Ev '^#|^$' flink-conf.yaml
jobmanager.rpc.address: localhost
jobmanager.rpc.port: 6123
jobmanager.bind-host: 0.0.0.0
jobmanager.memory.process.size: 1600m
taskmanager.bind-host: 0.0.0.0
taskmanager.host: node1 #node2节点改成node2,node3节点改成node3
taskmanager.memory.process.size: 1728m
taskmanager.numberOfTaskSlots: 1
parallelism.default: 1
high-availability: zookeeper
high-availability.storageDir: hdfs://mycluster/flink/ha/
high-availability.zookeeper.quorum: node1:2181,node2:2181,node3:2181
high-availability.zookeeper.client.acl: open
state.backend: filesystem
state.checkpoints.dir: hdfs://mycluster/flink/checkpoints
state.savepoints.dir: hdfs://mycluster/flink/savepoints
state.backend.incremental: false
jobmanager.execution.failover-strategy: region
rest.address: localhost
rest.bind-address: 0.0.0.0
web.submit.enable: true
说明
#jobmanager.rpc.address: localhost #指定JobManager的RPC地址
#jobmanager.rpc.port: 6123: #指定JobManager的RPC端口号
#jobmanager.bind-host: 0.0.0.0 #JobManager绑定的主机为0.0.0.0,表示可以接受来自任何主机的连接。
#jobmanager.memory.process.size: 1600m #每个JobManager的可用内存大小
#taskmanager.bind-host: 0.0.0.0 #TaskManager绑定的主机为0.0.0.0,表示可以接受来自任何主机的连接。
#taskmanager.host: localhost #指定TaskManager的主机名
#taskmanager.memory.process.size: 1728m #每个TaskManager的可用内存大小
#taskmanager.numberOfTaskSlots: 2 #指定每个TaskManager的任务槽数量
#parallelism.default: 1 #指定默认的并行度,即每个任务的并行执行线程数
#high-availability: zookeeper #指定高可用性模式,这里设置为 zookeeper。表示Flink将使用Zookeeper来进行高可用性管理。
#high-availability.storageDir: hdfs:///flink/ha/ #指定高可用性存储目录的路径
#high-availability.zookeeper.quorum: node1:2181,node2:2181,node3:2181 #指定Zookeeper集群的地址列表
#high-availability.zookeeper.client.acl: open #指定Zookeeper客户端的访问控制列表(ACL),默认是 open,如果 zookeeper security 启用了更改成 creator
#state.backend: filesystem #指定状态后端,即Flink任务的状态数据存储方式,这里设置为 filesystem,表示使用文件系统进行状态存储。
#state.checkpoints.dir: hdfs:///flink/checkpoints #指定检查点数据的存储路径
#state.savepoints.dir: hdfs:///flink/savepoints #指定保存点数据的存储路径
#state.backend.incremental: false #指定是否启用增量检查点。设置为 false 表示禁用增量检查点,而是使用全量检查点。
#jobmanager.execution.failover-strategy: region #指定作业管理器的故障转移策略,full: 当作业管理器发生故障时,使用全量故障转移策略。全量故障转移会将作业状态和所有任务的状态从故障的作业管理器迁移到另一个作业管理器。这是默认的故障转移策略。;region: 当作业管理器发生故障时,使用区域故障转移策略。区域故障转移会将作业状态和一部分任务的状态从故障的作业管理器迁移到另一个作业管理器,而不是全部迁移;none: 当作业管理器发生故障时,不进行故障转移。这意味着作业将终止,并且需要手动重新启动。
#rest.address: 0.0.0.0 #指定REST接口的地址,表示可以接受来自任何主机的连接。
#rest.bind-address: localhost #指定REST绑定的地址
#web.submit.enable: true #指定是否启用Web提交界面
#修改zoo.cfg
[root@node1 conf]# cp /opt/bigdata/zookeeper/conf/zoo.cfg .
#复制hadoop配置到flink目录下
[root@node1 conf]# cd /opt/bigdata/hadoop/etc/hadoop/
[root@node1 hadoop]# cp core-site.xml hdfs-site.xml /opt/bigdata/flink/conf/
4.4.4将flink目录发送到其他节点
[root@node1 hadoop]# for i in {node2,node3}
do
scp -r /opt/bigdata/flink/ $i:/opt/bigdata/
scp /root/.bash_profile $i:/root/
done
4.4.5修改其他节点的flink-conf.yaml
[root@node2 ~]# grep -Ev '^#|^$' /opt/bigdata/flink/conf/flink-conf.yaml
jobmanager.rpc.address: localhost
jobmanager.rpc.port: 6123
jobmanager.bind-host: 0.0.0.0
jobmanager.memory.process.size: 1600m
taskmanager.bind-host: 0.0.0.0
taskmanager.host: node2 ##修改此行
taskmanager.memory.process.size: 1728m
taskmanager.numberOfTaskSlots: 1
parallelism.default: 1
high-availability: zookeeper
high-availability.storageDir: hdfs://mycluster/flink/ha/
high-availability.zookeeper.quorum: node1:2181,node2:2181,node3:2181
high-availability.zookeeper.client.acl: open
state.backend: filesystem
state.checkpoints.dir: hdfs://mycluster/flink/checkpoints
state.savepoints.dir: hdfs://mycluster/flink/savepoints
state.backend.incremental: false
jobmanager.execution.failover-strategy: region
rest.address: localhost
rest.bind-address: 0.0.0.0
web.submit.enable: true
[root@node3 ~]# grep -Ev '^#|^$' /opt/bigdata/flink/conf/flink-conf.yaml
jobmanager.rpc.address: localhost
jobmanager.rpc.port: 6123
jobmanager.bind-host: 0.0.0.0
jobmanager.memory.process.size: 1600m
taskmanager.bind-host: 0.0.0.0
taskmanager.host: node3 #修改此行
taskmanager.memory.process.size: 1728m
taskmanager.numberOfTaskSlots: 1
parallelism.default: 1
high-availability: zookeeper
high-availability.storageDir: hdfs://mycluster/flink/ha/
high-availability.zookeeper.quorum: node1:2181,node2:2181,node3:2181
high-availability.zookeeper.client.acl: open
state.backend: filesystem
state.checkpoints.dir: hdfs://mycluster/flink/checkpoints
state.savepoints.dir: hdfs://mycluster/flink/savepoints
state.backend.incremental: false
jobmanager.execution.failover-strategy: region
rest.address: localhost
rest.bind-address: 0.0.0.0
web.submit.enable: true
4.4.6启动flink集群
[root@node1 hadoop]# cd /opt/bigdata/flink/bin/
[root@node1 bin]# ./start-cluster.sh
Starting HA cluster with 2 masters.
Starting standalonesession daemon on host node1.
Starting standalonesession daemon on host node2.
Starting taskexecutor daemon on host node1.
Starting taskexecutor daemon on host node2.
Starting taskexecutor daemon on host node3.
#jps查看进程,如果启动成功会有 StandaloneSessionClusterEntrypoint 和 TaskManagerRunner 进程,没有就查看日志报错,参考后面排查步骤
[root@node1 bin]# jps
5265 DFSZKFailoverController
4835 DataNode
9140 Jps
2133 QuorumPeerMain
4693 NameNode
6901 Master
5079 JournalNode
6167 ResourceManager
7624 HistoryServer
6319 NodeManager
#查看日志报错信息
[root@node1 bin]# less ../log/flink-root-standalonesession-0-node1.log
Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Could not find a file system implementation for scheme 'hdfs'. The scheme is not directly supported by Flink and no Hadoop file system to support this scheme could be loaded.
#这个错误通常是由于缺少 Hadoop 的依赖引起的。Flink 需要 Hadoop 的相关库文件才能与 HDFS 进行交互。
#确保 Flink 的 lib 目录中包含了所需的 Hadoop 相关的 JAR 文件。这些文件通常位于 Hadoop 的安装目录下的 share/hadoop/common 目录中。将这些文件复制到 Flink 的 lib 目录中
[root@node1 bin]# cd /opt/bigdata/hadoop/share/hadoop/common/
[root@node1 common]# ls -1
hadoop-common-3.3.5.jar #Hadoop的通用库文件,包含了与文件系统交互和访问HDFS需要的功能
hadoop-common-3.3.5-tests.jar
hadoop-kms-3.3.5.jar #Hadoop KMS的库文件,用于管理和访问加密密钥
hadoop-nfs-3.3.5.jar #Hadoop的NFS(Network File System)库文件,用于访问和操作基于NFS的文件系统
hadoop-registry-3.3.5.jar #Hadoop的注册表库文件,用于管理和访问注册表服务。
jdiff
lib
sources
webapps
#所有节点放入
[root@node1 common]# for i in {node1,node2,node3}
do
scp hadoop-common-3.3.5.jar hadoop-kms-3.3.5.jar hadoop-nfs-3.3.5.jar hadoop-registry-3.3.5.jar $i:/opt/bigdata/flink/lib/
done
#再次启动
[root@node1 common]# $FLINK_HOME/bin/start-cluster.sh
[root@node1 common]# jps #仍然没有
5265 DFSZKFailoverController
4835 DataNode
2133 QuorumPeerMain
4693 NameNode
6901 Master
5079 JournalNode
6167 ResourceManager
7624 HistoryServer
10139 Jps
6319 NodeManager
#登录flink官网
https://flink.apache.org/zh/downloads/ ctrl+f 搜索hadoop
找到Pre-bundled Hadoop 2.8.3 Source Release (asc, sha512) 点击下载
#完整下载路径如下:
https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.8.3-10.0/flink-shaded-hadoop-2-uber-2.8.3-10.0.jar
[root@node1 ~]# wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.8.3-10.0/flink-shaded-hadoop-2-uber-2.8.3-10.0.jar
#将jar包放入 /opt/bigdata/flink/lib 目录下,所有节点都要放入
[root@node1 ~]# for i in {node1,node2,node3}
do
scp flink-shaded-hadoop-2-uber-2.8.3-10.0.jar $i:/opt/bigdata/flink/lib/
done
#再次启动查看进程
[root@node1 ~]# $FLINK_HOME/bin/start-cluster.sh
[root@node1 ~]# jps
5265 DFSZKFailoverController
4835 DataNode
10643 StandaloneSessionClusterEntrypoint ##
10948 TaskManagerRunner ##
2133 QuorumPeerMain
4693 NameNode
6901 Master
11093 Jps
5079 JournalNode
6167 ResourceManager
7624 HistoryServer
6319 NodeManager
[root@node2 ~]# jps
2752 DataNode
7106 TaskManagerRunner ##
2851 JournalNode
2670 NameNode
3822 Worker
1873 QuorumPeerMain
4433 HistoryServer
6802 StandaloneSessionClusterEntrypoint ##
3316 NodeManager
3221 ResourceManager
3928 Master
2937 DFSZKFailoverController
7231 Jps
[root@node3 ~]# jps
2114 DataNode
1860 QuorumPeerMain
2884 Worker
2263 NodeManager
4395 TaskManagerRunner ##
4350 Jps
#可以看到有StandaloneSessionClusterEntrypoint和TaskManagerRunner进程
#master角色进程: StandaloneSessionClusterEntrypoint; slave角色进程: TaskManagerRunner
#停止集群 ./stop-cluster.sh
#单独启动
./jobmanager.sh start/stop
./taskmanager.sh start/stop
4.4.7页面访问验证
浏览器访问 http://192.168.1.11:8081/

4.4.8提交任务测试
#使用官方example 运行测试看看
[root@node3 ~]# cd /opt/bigdata/flink/bin/
[root@node3 bin]# flink run -m yarn-cluster ../examples/batch/WordCount.jar

这就是代表运行成功了,我们访问yarn查看applicationId
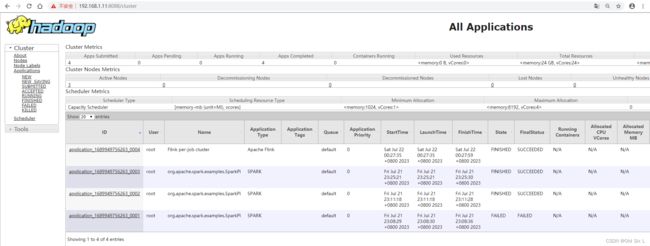
4.4.9其他常用操作命令
#使用yarn-session.sh命令(yarn-session.sh命令在flink的bin下)
#启动一个Flink YARN session。其中,-n 3表示启动3个TaskManager,-jm 500表示JobManager的内存为500MB,-tm 500表示每个TaskManager的内存为500MB,-d表示在后台运行
[root@node3 bin]# yarn-session.sh -n 3 -jm 500 -tm 500 -d
...
JobManager Web Interface: http://192.168.1.11:33563
访问日志上的网址可以访问此任务的flink dashboard
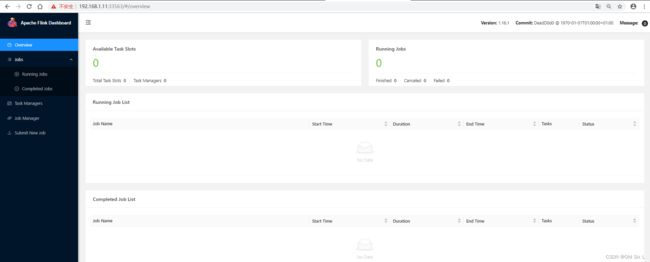
#命令行查询命令
[root@node1 ~]# yarn application -list
Total number of applications (application-types: [], states: [SUBMITTED, ACCEPTED, RUNNING] and tags: []):1
Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL
application_1689949756263_0005 Flink session cluster Apache Flink root default RUNNING UNDEFINED 100% http://192.168.1.11:33563
#查看日志命令
[root@node1 ~]# yarn logs -applicationId application_1689949756263_0005
#结束杀掉任务
[root@node1 ~]# yarn application -kill application_1689949756263_0005
至此,flink on yarn 高可用集群部署完成
4.5部署kafka集群
kafka官网https://kafka.apache.org/
下载地址 Scala 2.12 - kafka_2.12-3.4.0.tgz
4.5.1下载安装包
[root@node1 ~]# wget https://downloads.apache.org/kafka/3.4.0/kafka_2.12-3.4.0.tgz
4.5.2解压缩并配置环境变量
#解压缩
[root@node1 ~]# tar -xf kafka_2.12-3.4.0.tgz -C /opt/bigdata/
[root@node1 ~]# mv /opt/bigdata/kafka_2.12-3.4.0/ /opt/bigdata/kafka
#配置环境变量
[root@node1 ~]# cat >> .bash_profile << 'EOF'
#Kafka环境变量
export KAFKA_HOME=/opt/bigdata/kafka
export PATH=$PATH:$KAFKA_HOME/bin
EOF
[root@node1 ~]# source .bash_profile
4.5.3配置kafka
[root@node1 ~]# cd /opt/bigdata/kafka/config/
#主要配置文件为server.properties,vim 编辑修改,最后如下
[root@node1 config]# grep -Ev '^$|^#' server.properties
#broker的全局唯一编号,不能重复,只能是数字。每个节点唯一,不能重复
broker.id=11
#修改为当前节点的ip
listeners = PLAINTEXT://node1:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
#运行日志存放的路径,不需提前创建,kafka会自动创建
log.dirs=/opt/bigdata/kafka/logs
#默认分区数
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
#日志保留时间
log.retention.hours=168
log.retention.check.interval.ms=300000
#连接zookeeper集群地址
zookeeper.connect=node1:2181,node2:2181,node3:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
4.5.4分发文件到其他节点并配置
[root@node1 config]# cd
[root@node1 ~]# for i in {node2,node3}
do
scp -r /opt/bigdata/kafka/ $i:/opt/bigdata/
scp .bash_profile $i:/root/
done
#修改node2和nide3的配置文件,如下
[root@node2 ~]# grep -Ev '^$|^#' /opt/bigdata/kafka/config/server.properties
##修改此处id值
broker.id=12
#修改当前节点名
listeners = PLAINTEXT://node2:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/bigdata/kafka/logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.retention.check.interval.ms=300000
zookeeper.connect=node1:2181,node2:2181,node3:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
[root@node3 ~]# grep -Ev '^$|^#' /opt/bigdata/kafka/config/server.properties
##修改此处id值
broker.id=13
#修改当前节点名
listeners = PLAINTEXT://node3:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/bigdata/kafka/logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.retention.check.interval.ms=300000
zookeeper.connect=node1:2181,node2:2181,node3:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0
4.5.5启动kafka集群
#每个节点都要启动
[root@node1 ~]# cd /opt/bigdata/kafka/bin
[root@node1 bin]# ./kafka-server-start.sh -daemon ../config/server.properties
[root@node2 ~]# cd /opt/bigdata/kafka/bin
[root@node2 bin]# ./kafka-server-start.sh -daemon ../config/server.properties
[root@node3 ~]# cd /opt/bigdata/kafka/bin
[root@node3 bin]# ./kafka-server-start.sh -daemon ../config/server.properties
4.5.6集群测试以及常用kafka命令
#创建topic,1分区,1副本,topic名字 Mytopic_test
[root@node3 ~]# kafka-topics.sh --create --topic Mytopic_test --partitions 1 --replication-factor 1 --bootstrap-server node1:9092,node2:9092,node3:9092
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic mytopic_test.
#查看topic列表
[root@node3 ~]# kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --list
Mytopic_test
#更改topic分区为3
[root@node3 ~]# kafka-topics.sh --alter --bootstrap-server node1:9092,node2:9092,node3:9092 --topic Mytopic_test --partitions 3
#添加配置,当producer发送了100条消息后,就会强制将缓存中的消息刷新到磁盘上
[root@node3 ~]# kafka-configs.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --entity-type topics --entity-name Mytopic_test --alter --add-config flush.messages=100
Completed updating config for topic Mytopic_test.
#查看Topic描述
[root@node3 ~]# kafka-topics.sh --describe --bootstrap-server node1:9092,node2:9092,node3:9092 --topic Mytopic_test
Topic: Mytopic_test TopicId: L1V4yI1UQy6_ZMkwgMHUmA PartitionCount: 3 ReplicationFactor: 1 Configs: flush.messages=100
Topic: Mytopic_test Partition: 0 Leader: 11 Replicas: 11 Isr: 11
Topic: Mytopic_test Partition: 1 Leader: 12 Replicas: 12 Isr: 12
Topic: Mytopic_test Partition: 2 Leader: 13 Replicas: 13 Isr: 13
#启动生产者
#在任意Kafka节点上启动Producer生产数据
[root@node3 ~]# kafka-console-producer.sh --broker-list node1:9092,node2:9092,node3:9092 --topic Mytopic_test
>abcd
#在任意kafka节点上启动消费者
[root@node3 ~]# kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic Mytopic_test
abcd
#消费多主题
#新建topic名为topic_test2
[root@node3 ~]# kafka-topics.sh --create --topic topic_test2 --partitions 1 --replication-factor 1 --bootstrap-server node1:9092,node2:9092,node3:9092
#同时消费Mytopic_test和topic_test2
[root@node3 ~]# kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --consumer-property group.id=grouptest --consumer-property consumer.id=old-consumer-cl --whiteli
st "Mytopic_test|topic_test2"
#创建消费组
[root@node3 ~]# kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic Mytopic_test --group mygroup_test
#查看消费组列表
[root@node3 ~]# kafka-consumer-groups.sh --list --bootstrap-server node1:9092,node2:9092,node3:9092
mygroup_test
grouptest
console-consumer-18469
#查看消费组详细信息,LOG-END-OFFSET下一条将要被加入到日志的消息的位移,CURRENT-OFFSET当前消费的位移,LAG 消息堆积量
[root@node3 ~]# kafka-consumer-groups.sh --describe --bootstrap-server node1:9092,node2:9092,node3:9092 --group mygroup_test
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
mygroup_test Mytopic_test 0 0 0 0 console-consumer-66df351d-4457-4278-9900-b3d0c95b4e69 /192.168.1.12 console-consumer
mygroup_test Mytopic_test 1 5 5 0 console-consumer-66df351d-4457-4278-9900-b3d0c95b4e69 /192.168.1.12 console-consumer
mygroup_test Mytopic_test 2 0 0 0 console-consumer-66df351d-4457-4278-9900-b3d0c95b4e69 /192.168.1.12 console-consumer
#移动消费组偏移到某个位置
#最早处
[root@node3 ~]# kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --group mygroup_test --reset-offsets --all-topics --to-earliest --execute
#最新处
[root@node3 ~]# kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --group mygroup_test --reset-offsets --all-topics --to-latest --execute
#某个位置
[root@node3 ~]# kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --group mygroup_test --reset-offsets --all-topics --to-offset 2000 --execute
#删除topic
[root@node3 ~]# kafka-topics.sh --delete --topic topic_test2 --bootstrap-server node1:9092,node2:9092,node3:9092
#删除消费组
[root@node3 ~]# kafka-consumer-groups.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --group mygroup_test --delete
4.6部署HBase集群
简介:HBase是一个开源的分布式、面向列的NoSQL数据库,它是构建在Hadoop分布式文件系统(HDFS)上的。HBase的设计目标是提供高可靠性、高性能的随机读写能力,以适应大规模数据存储和处理的需求。
HBase的特点包括:
- 列存储:HBase将数据按列存储,而不是按行存储,这样可以提高读写效率。同时,HBase支持动态添加列,使得数据模型更加灵活。
- 分布式架构:HBase采用分布式架构,数据可以水平分片存储在多个服务器上,实现了数据的高可靠性和可扩展性。HBase使用ZooKeeper作为分布式协调服务,确保集群的一致性。
- 高性能:HBase支持快速的随机读写操作,可以处理海量数据的高并发访问。HBase使用了基于内存的索引和块缓存等技术来加速数据的访问。
- 强一致性:HBase保证数据的强一致性,即读取操作会返回最新的数据,写入操作会等待数据的一致性确认。这使得HBase适用于需要实时数据访问和更新的应用场景。
- 扩展性:HBase可以方便地扩展到上千台服务器,支持PB级别的数据存储。它可以根据数据量的增长自动进行数据分片和负载均衡。
总之,HBase是一个适用于大规模数据存储和处理的分布式NoSQL数据库,具有高可靠性、高性能和可扩展性的特点。
集群节点规划:
| 节点名 | HMaster | HRegionServer |
|---|---|---|
| node1 | √ | √ |
| node2 | √ | √ |
| node | × | √ |
官网https://hbase.apache.org/
4.6.1下载HBase安装包
[root@node1 bin]# cd
[root@node1 ~]# wget https://dlcdn.apache.org/hbase/2.4.17/hbase-2.4.17-bin.tar.gz --no-check-certificate
4.6.2解压缩并配置环境变量
#解压软件包
[root@node1 ~]# tar -xf hbase-2.4.17-bin.tar.gz -C /opt/bigdata/
[root@node1 ~]# mv /opt/bigdata/hbase-2.4.17/ /opt/bigdata/hbase
#配置环境变量
[root@node1 ~]# cat >> .bash_profile << 'EOF'
#HBase环境变量
export HBASE_HOME=/opt/bigdata/hbase
export PATH=$PATH:$HBASE_HOME/bin
EOF
#让环境变量生效
[root@node1 ~]# source .bash_profile
4.6.3配置HBase
[root@node1 ~]# cd /opt/bigdata/hbase/conf/
#修改hbase配置文件
[root@node1 conf]# vim hbase-env.sh #去掉#注释并修改
export JAVA_HOME=/usr/local/jdk1.8.0_371
#export HBASE_SSH_OPTS="-p 12122" #实际生产环境中,一般ssh端口会修改为其他端口,则需要配置此处
export HBASE_PID_DIR=/opt/bigdata/hbase/pids #保存pid文件
export HBASE_MANAGES_ZK=false #禁用HBase自带的Zookeeper,因为我们是使用独立的Zookeeper
#配置hbase-site.xml
[root@node1 conf]# vim hbase-site.xml
<configuration>
<property>
<name>hbase.rootdirname>
<value>hdfs://mycluster/hbasevalue>
property>
<property>
<name>hbase.master.info.portname>
<value>60010value>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>node1:2181,node2:2181,node3:2181value>
property>
<property>
<name>hbase.zookeeper.property.dataDirname>
<value>/opt/bigdata/zookeeper/datavalue>
property>
<property>
<name>hbase.zookeeper.property.clientPortname>
<value>2181value>
property>
<property>
<name>hbase.tmp.dirname>
<value>/opt/bigdata/hbase/tmpvalue>
property>
<property>
<name>hbase.unsafe.stream.capability.enforcename>
<value>falsevalue>
property>
<property>
<name>hbase.wal.providername>
<value>filesystemvalue>
property>
configuration>
#配置regionserver节点
[root@node1 conf]# cat > regionservers << EOF
node1
node2
node3
EOF
4.6.4将hadoop的相关配置文件放到hbase目录下
[root@node1 conf]# cd /opt/bigdata/hadoop/etc/hadoop/
[root@node1 hadoop]# cp core-site.xml hdfs-site.xml /opt/bigdata/hbase/conf/
4.6.5拷贝hbase相关文件到其他节点
[root@node1 hadoop]# cd
[root@node1 ~]# for i in {node2,node3}
do
scp -r /opt/bigdata/hbase/ $i:/opt/bigdata/
scp /root/.bash_profile $i:/root/
done
4.6.6启动HBase
在主节点启动,主节点是namenode为active状态的节点
可通过命令hdfs haadmin -getServiceState nn1 , hdfs haadmin -getServiceState nn2 查看
[root@node1 ~]# hdfs haadmin -getServiceState nn1
active
[root@node1 ~]# hdfs haadmin -getServiceState nn2
standby
#启动hbase,此时的zookeeper和hadoop集群为启动状态
[root@node1 ~]# start-hbase.sh
#备用主节点需要单独启动,一定记得执行
[root@node2 ~]# hbase-daemon.sh start master
#启动成功后主节点有HMaster、Regionserver进程,node3上有Regionserver进程
[root@node1 ~]# jps
4835 DataNode
10948 TaskManagerRunner
15173 HRegionServer
7624 HistoryServer
6319 NodeManager
15632 Jps
5265 DFSZKFailoverController
10643 StandaloneSessionClusterEntrypoint
14964 HMaster
2133 QuorumPeerMain
4693 NameNode
6901 Master
5079 JournalNode
6167 ResourceManager
11837 TaskManagerRunner
14495 Kafka
[root@node2 ~]# jps
2752 DataNode
7106 TaskManagerRunner
9986 Jps
2851 JournalNode
9738 HMaster
9197 Kafka
2670 NameNode
3822 Worker
1873 QuorumPeerMain
4433 HistoryServer
6802 StandaloneSessionClusterEntrypoint
9458 HRegionServer
3316 NodeManager
3221 ResourceManager
3928 Master
2937 DFSZKFailoverController
7836 TaskManagerRunner
[root@node3 ~]# jps
2114 DataNode
1860 QuorumPeerMain
2884 Worker
6246 Kafka
2263 NodeManager
7049 HRegionServer
4395 TaskManagerRunner
7295 Jps
4.6.7浏览器访问HBase
http://192.168.1.11:60010
http://192.168.1.12:60010
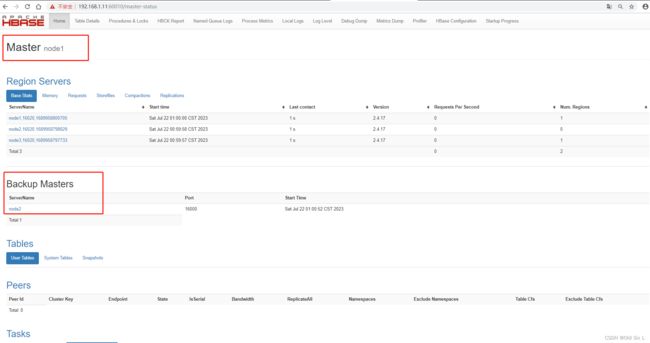

可以看到 node1上显示 Master node1 ,在node2上显示Backup Master node2
Current Active Master: node1
4.6.8高可用测试
kill 掉node1上的 HMaster ,在浏览器中查看备用主节点node2上的HBase是否切换为active
再次启动node1 , hbase-daemon.sh start master ,访问node1页面显示 node2为active
再次kill 到node2 的 HMaster ,再次查看,又切换了回去,在启动node2查看。hbase-daemon.sh start master
再次查看node2 的页面 显示node1为active,测试成功。
4.6.9 hbase的常用命令
#随便找个节点,进入hbase
[root@node3 ~]# hbase shell #进入hbase
hbase:003:0> version #查看hbase版本
2.4.17, r7fd096f39b4284da9a71da3ce67c48d259ffa79a, Fri Mar 31 18:10:45 UTC 2023
Took 0.0004 seconds
hbase:004:0> help #帮助命令,所有的帮助
hbase:005:0> help 'create' #指定命令的帮助
hbase:006:0> create_namespace 'oldsixl' #创建命名空间
Took 0.1468 seconds
hbase:007:0> list_namespace #查看所有命名空间
NAMESPACE
default
hbase
oldsixl
3 row(s)
Took 0.0433 seconds
hbase:011:0> status #查看集群状态
1 active master, 1 backup masters, 3 servers, 0 dead, 0.6667 average load
Took 0.0833 seconds
hbase:012:0> drop_namespace 'oldsixl' #删除命名空间,该命名空间必须为空,否则系统不让删除。
Took 0.1446 seconds
hbase:013:0> create_namespace 'oldsixlns'
Took 0.1256 seconds
hbase:016:0> create 'oldsixlns:test_table','cf' #创建表test_table,这个表只有一个 列族 为 cf
Created table oldsixlns:test_table
Took 0.6492 seconds
=> Hbase::Table - oldsixlns:test_table
hbase:017:0> list #列出所有表
TABLE
oldsixlns:test_table
1 row(s)
Took 0.0044 seconds
=> ["oldsixlns:test_table"]
hbase:019:0> put 'oldsixlns:test_table','row1','cf:a','value1' #表中插入数据
Took 0.1267 seconds
hbase:020:0> put 'oldsixlns:test_table','row2','cf:b','value2'
Took 0.5323 seconds
hbase:021:0> put 'oldsixlns:test_table','row3','cf:c','value3'
Took 0.0086 seconds
hbase:022:0> scan 'oldsixlns:test_table' #查看表中所有数据
ROW COLUMN+CELL
row1 column=cf:a, timestamp=2023-07-19T23:30:01.368, value=value1
row2 column=cf:b, timestamp=2023-07-19T23:30:12.444, value=value2
row3 column=cf:c, timestamp=2023-07-19T23:30:21.700, value=value3
3 row(s)
hbase:024:0> get 'oldsixlns:test_table','row1' #精确查询某行数据
COLUMN CELL
cf:a timestamp=2023-07-19T23:30:01.368, value=value1
1 row(s)
Took 0.0217 seconds
hbase:025:0> scan 'oldsixlns:test_table',{ROWPREFIXFILTER=>'row1'} #查看roukey前面是row1,可以写成前面的任意n为字符
ROW COLUMN+CELL
row1 column=cf:a, timestamp=2023-07-19T23:30:01.368, value=value1
1 row(s)
Took 0.0081 seconds
hbase:026:0> scan 'oldsixlns:test_table',{ROWPREFIXFILTER=>'row',LIMIT=>2}
ROW COLUMN+CELL
row1 column=cf:a, timestamp=2023-07-19T23:30:01.368, value=value1
row2 column=cf:b, timestamp=2023-07-19T23:30:12.444, value=value2
2 row(s)
Took 0.0064 second
hbase:036:0> scan 'oldsixlns:test_table',{FILTER=>"PrefixFilter('row')",LIMIT =>10} #查看表中包含row的数据
ROW COLUMN+CELL
row1 column=cf:a, timestamp=2023-07-19T23:30:01.368, value=value1
row2 column=cf:b, timestamp=2023-07-19T23:30:12.444, value=value2
row3 column=cf:c, timestamp=2023-07-19T23:30:21.700, value=value3
3 row(s)
Took 0.0118 seconds
hbase:038:0> scan 'oldsixlns:test_table',{TIMERANGE=>[1689779520000,1689783120000],LIMIT=>1} #获取指定时间的时间戳 date -d '2023-06-08 16:12:00' +%s%3N ,当前服务器的时间的时间戳:date +%s%3N
ROW COLUMN+CELL
row1 column=cf:a, timestamp=2023-07-19T23:30:01.368, value=value1
1 row(s)
Took 0.0071 seconds
hbase:045:0> scan 'oldsixlns:test_table',{FILTER=>"ValueFilter(=,'substring:va') AND ValueFilter(=,'substring:1')",LIMIT=>10} #查询数据中既有va,又有1的数据
ROW COLUMN+CELL
row1 column=cf:a, timestamp=2023-07-19T23:30:01.368, value=value1
1 row(s)
Took 0.0075 seconds
hbase:046:0> describe 'oldsixlns:test_table' #查看表结构
Table oldsixlns:test_table is ENABLED
oldsixlns:test_table
COLUMN FAMILIES DESCRIPTION
{NAME => 'cf', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS =>
'0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
1 row(s)
Quota is disabled
Took 0.0392 seconds
hbase:057:0> alter 'namespace:table',{NAME=>'cf',COMPRESSION=>'SNAPPY'} #开启压缩
hbase:058:0> alter 'oldsixlns:test_table',NAME=>'cf',TTL=>'86400' #修改ttl,单位秒,数据保存的时间
hbase:059:0> count 'oldsixlns:test_table'
3 row(s)
hbase:060:0> deleteall 'oldsixlns:test_table','row1' #删除rowkey为row1的所有数据
Took 0.0075 seconds
hbase:063:0> delete 'oldsixlns:test_table','row2','cf:b' #删除row2,cf:b的数据
Took 0.0089 seconds
hbase:064:0> scan 'oldsixlns:test_table'
ROW COLUMN+CELL
row3 column=cf:c, timestamp=2023-07-19T23:30:21.700, value=value3
1 row(s)
Took 0.0053 seconds
hbase:070:0> is_disabled 'oldsixlns:test_table' #查看表是否被禁用
false
Took 0.0103 seconds
=> false
hbase:071:0> truncate 'oldsixlns:test_table' #清空表数据
Truncating 'oldsixlns:test_table' table (it may take a while):
Disabling table...
Truncating table...
Took 1.4789 seconds
hbase:076:0> disable 'oldsixlns:test_table' #禁用表,如果要删除表,必须先禁用表
Took 0.3266 seconds
hbase:077:0> drop 'oldsixlns:test_table' #删除表
#在终端导出hbase库的数据到本地,不要进入hbase,直接执行。有特殊字符报错的话,加上\ 转义符就好了
[root@node3 ~]# echo "scan 'oldsixlns:test_table',{FILTER=>\"ValueFilter(=,'substring:value1')\"}" | hbase shell > test.txt
hbase表结构形式
创建下面的一张表

create_namespace 'MrLOAM'
create 'MrLOAM:employee_info', 'info', 'detail', 'address'
第一行
put 'MrLOAM:employee_info', 'xiaoming', 'info:id', '1'
put 'MrLOAM:employee_info', 'xiaoming', 'info:name', '小明'
put 'MrLOAM:employee_info', 'xiaoming', 'info:age', '25'
put 'MrLOAM:employee_info', 'xiaoming', 'detail:birth', '1997-03-06'
put 'MrLOAM:employee_info', 'xiaoming', 'detail:w_time', '2023-07-01 13:00:00'
put 'MrLOAM:employee_info', 'xiaoming', 'detail:email', '[email protected]'
put 'MrLOAM:employee_info', 'xiaoming', 'address', '上海'
第二行
put 'MrLOAM:employee_info', 'xiaohong', 'info:id', '2'
put 'MrLOAM:employee_info', 'xiaohong', 'info:name', '小红'
put 'MrLOAM:employee_info', 'xiaohong', 'info:age', '26'
put 'MrLOAM:employee_info', 'xiaohong', 'detail:birth', '1998-06-05'
put 'MrLOAM:employee_info', 'xiaohong', 'detail:w_time', '2023-07-01 13:05:00'
put 'MrLOAM:employee_info', 'xiaohong', 'detail:email', '[email protected]'
put 'MrLOAM:employee_info', 'xiaohong', 'address', '北京'
第二行
put 'MrLOAM:employee_info', 'xiaohei', 'info:id', '3'
put 'MrLOAM:employee_info', 'xiaohei', 'info:name', '小黑'
put 'MrLOAM:employee_info', 'xiaohei', 'info:age', '28'
put 'MrLOAM:employee_info', 'xiaohei', 'detail:birth', '2000-01-01'
put 'MrLOAM:employee_info', 'xiaohei', 'detail:w_time', '2023-07-01 13:10:30'
put 'MrLOAM:employee_info', 'xiaohei', 'detail:email', '[email protected]'
put 'MrLOAM:employee_info', 'xiaohei', 'address', '广州'
查看表数据

4.7部署hive高可用集群
官网https://hive.apache.org/

介绍:
Hive是一个基于Hadoop的数据仓库工具,用于处理大规模数据集。它提供了类似于SQL的查询语言(HiveQL),提供了数据存储、查询和分析等功能,允许用户通过类似于关系型数据库的方式查询和分析数据。Hive通过HiveQL查询语言进行数据查询和分析,类似于关系型数据库的SQL语言,Hive可以作为一个独立的服务部署在Hadoop集群中,也可以与其他工具(如Spark)进行集成。
HiveServer2是Hive的服务接口,允许远程客户端通过网络连接到Hive,并执行查询。它是Hive的一个服务端组件,提供了一种与Hive交互的方式。HiveServer2通过网络连接提供服务,允许客户端通过编程语言(如Java、Python)与Hive进行交互。HiveServer2通常作为Hive的一个组件部署在Hadoop集群中,用于提供远程访问接口。
Hive是基于 Hadoop的一个数据仓库工具,Hive使用HDFS进行存储,使用MapReduce进行计算。Hive支持 MapReduce、 Spark、Tez这三种分布式计算引擎
计算引擎
// MapReduce
将计算分为两个阶段,分别为 Map 和 Reduce。对于应用来说,需要想方设法将应用拆分成多个map、reduce的作业,以完成一个完整的算法。
MapReduce整个计算过程会不断重复地往磁盘里读写中间结果,导致计算速度比较慢,效率比较低
// Tez
Tez把Map/Reduce过程拆分成若干个子过程,同时可以把多个Map/Reduce任务组合成一个较大的DAG任务,减少了Map/Reduce之间的文件存储。
// Spark
Apache Spark是一个快速的, 多用途的集群计算系统, 相对于 Hadoop MapReduce 将中间结果保存在磁盘中, Spark 使用了内存保存中间结果, 能在数据尚未写入硬盘时在内存中进行运算,同时Spark提供SQL 支持。
Spark 实现了一种叫做 RDDs 的 DAG 执行引擎, 其数据缓存在内存中可以进行迭代处理。
组件以及角色规划规划
| 节点 | hive-metastore | hive-hiveserver2 | mysql |
|---|---|---|---|
| node1 | √ | × | √ |
| node2 | √ | √ | × |
| node3 | × | √ | × |

4.7.1下载安装包
下载地址:https://dlcdn.apache.org/hive/hive-3.1.3
#下载hive安装包
[root@node1 ~]# wget https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
Hive需要使用其他关系型数据作为其元数据存储,如mysql、Oracle、PostgreSQL等。Hive与其他类型的数据库(如Oracle、PostgreSQL等)的集成有限,主要是通过自定义配置和JDBC驱动程序进行实现。
MySQL是Hive的推荐数据库之一,有以下几个优点:
-
成熟稳定:MySQL是一种成熟、稳定且广泛使用的关系型数据库管理系统。它经过了多年的发展和测试,并且在各种生产环境中得到了广泛应用。这使得MySQL在可靠性和稳定性方面表现优秀。
-
兼容性:Hive与MySQL的集成非常紧密,它提供了与MySQL数据库的无缝连接和交互。Hive提供了专门的MySQL存储处理程序,可以直接使用MySQL作为其元数据存储。这种紧密的集成使得Hive能够有效地管理和查询大规模的数据。
-
易用性:MySQL具有简单易用的特点,它提供了直观的命令行和图形界面工具,使得用户可以方便地管理和操作数据库。这使得MySQL成为了许多开发者和数据工程师的首选数据库。
-
社区支持:MySQL拥有庞大的开源社区支持,这意味着你可以轻松地找到关于MySQL的文档、教程、示例代码以及问题解答。这种社区支持为用户提供了丰富的资源和帮助,使得使用和维护MySQL变得更加容易。
此处将使用MySQL作为hive的元数据存储
在安装 Hive 之前,需要先确定 Hive 所需的 MySQL 版本。一般来说,Hive 2.x 版本需要 MySQL 5.6 或更高版本,而 Hive 3.x 版本需要 MySQL 5.7 或更高版本。
Apache Hive 3.1.3 需要 MySQL 5.7 或更高版本。具体来说,需要使用 MySQL 5.7.17 或更高版本,因为 Hive 3.1.3 使用了 MySQL 5.7.17 中引入的一些功能。如果使用的是 MySQL 8.x 版本,则需要将 Hive 的 JDBC 驱动程序升级到 MySQL 8.x 版本的驱动程序。
MySQL官网: http://www.mysql.com
此处选择5.7最稳定版本 5.7.35
#下载Mysql安装包
[root@node1 ~]# wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.35-el7-x86_64.tar.gz
4.7.2安装mysql
4.7.2.1卸载系统自带的mariadb
#查看并卸载系统的mariadb软件
[root@node1 ~]# rpm -qa | grep mariadb
mariadb-libs-5.5.68-1.el7.x86_64
#卸载mariadb
[root@node1 ~]# rpm -e --nodeps mariadb-libs-5.5.68-1.el7.x86_64
#查看系统是否有mysql
[root@node1 ~]# rpm -qa | grep mysql
#创建mysql用户并禁止登录
[root@node1 ~]# useradd mysql -s /sbin/nologin
4.7.2.2解压mysql安装包并安装
[root@node1 ~]# tar -xf mysql-5.7.35-el7-x86_64.tar.gz -C /opt/bigdata/
[root@node1 ~]# cd /opt/bigdata/
[root@node1 bigdata]# mv mysql-5.7.35-el7-x86_64/ mysql
#创建mysql数据目录以及配置目录
[root@node1 bigdata]# mkdir mysql/{data,conf,logs,binlog}
#添加mysql环境变量
[root@node1 ~]# cat >> .bash_profile << 'EOF'
#MySQL环境变量
export MYSQL_HOME=/opt/bigdata/mysql
export PATH=$PATH:$MYSQL_HOME/bin
EOF
[root@node1 ~]# source .bash_profile
4.7.2.3配置mysql
#创建mysql配置文件
[root@node1 bigdata]# cd mysql/conf/
[root@node1 conf]# cat > my.cnf << 'EOF'
#客户端配置,包括客户端连接mysql服务器的相关配置
[client]
port = 3306
socket = /opt/bigdata/mysql/mysqld.sock
default-character-set = utf8mb4
#MySQL命令行客户端的配置
[mysql]
#指定MySQL命令行提示符的格式。
prompt="\u@mysqldb \R:\m:\s [\d]> "
#禁用自动补全功能
no-auto-rehash
#指定MySQL命令行客户端的默认字符集
default-character-set = utf8mb4
#MySQL服务器的配置
[mysqld]
#指定MySQL服务器运行的用户 (一般设置为mysql,需要提前创建mysql用户)
user = mysql
#指定MySQL服务器监听的端口号
port = 3306
socket = /opt/bigdata/mysql/mysqld.sock
#禁用DNS反向解析
skip-name-resolve
# 设置字符编码
character-set-server = utf8
collation-server = utf8_general_ci
# 设置默认时区
#default-time_zone='+8:00'
#指定MySQL服务器的唯一标识
server-id = 1
# Directory
#安装目录
basedir = /opt/bigdata/mysql
#数据存储目录
datadir = /opt/bigdata/mysql/data
#安全文件目录
secure_file_priv = /opt/bigdata/mysql/data
#PID文件的路径
pid-file = /opt/bigdata/mysql/mysql.pid
#MySQL服务器的最大连接数
max_connections = 1024
#最大连接错误数
max_connect_errors = 100
#连接超时时间
wait_timeout = 100
#最大允许数据包大小
max_allowed_packet = 128M
#表缓存数量
table_open_cache = 2048
#连接请求队列长度
back_log = 600
#指定MySQL服务器的默认存储引擎
default-storage-engine = innodb
#允许二进制日志中包含函数创建语句
log_bin_trust_function_creators = 1
# Log
#关闭通用查询日志
general_log=off
#general_log_file = /opt/bigdata/mysql/logs/mysql.log
#错误日志的路径
log-error = /opt/bigdata/mysql/logs/error.log
# binlog
#指定二进制日志的路径和格式
log-bin = /opt/bigdata/mysql/binlog/mysql-binlog
binlog_format=mixed
#slowlog慢查询日志
slow_query_log = 1
slow_query_log_file = /opt/bigdata/mysql/logs/slow.log
long_query_time = 2
log_output = FILE
log_queries_not_using_indexes = 0
#global_buffers
innodb_buffer_pool_size = 2G
innodb_log_buffer_size = 16M
innodb_flush_log_at_trx_commit = 2
key_buffer_size = 64M
innodb_log_file_size = 512M
innodb_log_file_size = 2G
innodb_log_files_in_group = 2
innodb_data_file_path = ibdata1:20M:autoextend
sql_mode = STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION
[mysqldump]
#指定mysqldump工具使用快速导出模式
quick
#指定mysqldump工具允许的最大数据包大小为32M
max_allowed_packet = 32M
EOF
4.7.2.4初始化MySQL并启动
[root@node1 conf]# ln my.cnf /etc/my.cnf
#将mysql文件下的文件归属设置为mysql
[root@node1 conf]# chown -R mysql.mysql /opt/bigdata/mysql/
#初始化mysql
[root@node1 conf]# cd ..
[root@node1 mysql]# ./bin/mysqld --initialize --user=mysql --datadir=/opt/bigdata/mysql/data/ --basedir=/opt/bigdata/mysql
#配置mysql快捷启动
[root@node1 mysql]# cp support-files/mysql.server /etc/init.d/mysqld
[root@node1 mysql]# chmod +x /etc/init.d/mysqld
#启动mysql
[root@node1 mysql]# /etc/init.d/mysqld start
Starting MySQL. SUCCESS!
#设置mysql开机自启
[root@node1 mysql]# chkconfig --level 35 mysqld on
[root@node1 mysql]# chkconfig --list mysqld
[root@node1 mysql]# chmod +x /etc/rc.d/init.d/mysqld
[root@node1 mysql]# chkconfig --add mysqld
[root@node1 mysql]# chkconfig --list mysqld
[root@node1 mysql]# service mysqld status
[root@node1 mysql]# reboot
[root@node1 ~]# ss -ntulp | grep mysql
tcp LISTEN 0 128 [::]:3306 [::]:* users:(("mysqld",pid=1712,fd=32))
4.7.2.5 创建Hive使用的相关用户并授权
#登录mysql
#查看mysql初始化密码
[root@node1 ~]# grep password /opt/bigdata/mysql/logs/error.log
A temporary password is generated for root@localhost: rk#SdSy6&BB1
#修改mysql密码方法1
[root@node1 ~]# mysqladmin -uroot -p'rk#SdSy6&BB1' password 123456
[root@node1 ~]# mysql -uroot -p123456
root@mysqldb 22:50: [(none)]> set PASSWORD = PASSWORD('123'); #修改密码方法2
root@mysqldb 22:55: [(none)]> flush privileges;
#添加远程访问权限
root@mysqldb 22:55: [(none)]> grant all privileges on *.* to 'root'@'%' identified by '123' with grant option;
#创建hive库并授权
root@mysqldb 22:58: [(none)]> create database hive;
root@mysqldb 22:58: [(none)]> create user "hive"@"%" identified by "123";
root@mysqldb 22:59: [(none)]> grant all privileges on hive.* to "hive"@"%";
root@mysqldb 23:00: [(none)]> flush privileges;
4.7.3部署hive
4.7.3.1 解压hive安装包并配置环境变量
[root@node1 ~]# tar -xf apache-hive-3.1.3-bin.tar.gz -C /opt/bigdata/
[root@node1 ~]# mv /opt/bigdata/apache-hive-3.1.3-bin/ /opt/bigdata/hive
#配置环境变量
[root@node1 ~]# cat >> .bash_profile << 'EOF'
#Hive环境变量
export HIVE_HOME=/opt/bigdata/hive
export PATH=$PATH:$HIVE_HOME/bin
EOF
[root@node1 ~]# source .bash_profile
4.7.3.2修改hive配置
[root@node1 ~]# cd /opt/bigdata/hive/conf/
#配置hive日志文件
[root@node1 conf]# cp hive-log4j2.properties.template hive-log4j2.properties
[root@node1 conf]# vim hive-log4j2.properties
property.hive.log.dir = /opt/bigdata/hive/logs
[root@node1 conf]# cp hive-env.sh.template hive-env.sh
#用vim修改hive-env.sh,最后修改如下:
[root@node1 conf]# grep -vE '^$|^#' hive-env.sh
HADOOP_HOME=/opt/bigdata/hadoop
export HIVE_CONF_DIR=/opt/bigdata/hive/conf
export HIVE_AUX_JARS_PATH=/opt/bigdata/hive/lib
4.7.3.3 配置metastore
Metastore是Hive用于管理库表元数据的服务,它存储了Hive中的元数据信息。元数据信息包括表的结构、列、分区等信息,以及表的索引、约束、视图等。有了Metastore服务,Hive的客户端应用程序可以通过连接Metastore服务来获取这些元数据信息,而无需直接访问底层的文件系统。这使得客户端可以基于结构化的库表信息构建计算框架,简化了数据访问和管理。
在hive-metastore节点上操作,即node1和node2上
#创建hdfs相关目录,记得启动zk、hdfs和yarn,上面我重启过系统
[root@node1 conf]# hdfs dfs -mkdir -p /user/hive/{warehouse,tmp,logs}
[root@node1 conf]# hdfs dfs -chmod -R 775 /user/hive/
#创建配置文件metastore-site.xml,是Hive的元数据存储配置文件,用于指定Hive元数据存储的位置和相关配置。创建metastore-site.xml文件后,可以在其中配置Hive元数据存储的数据库类型、连接信息、用户名、密码等信息。
[root@node1 conf]# cat > metastore-site.xml << 'EOF'
<configuration>
<property>
<name>hive.metastore.localname>
<value>truevalue>
property>
<property>
<name>hive.exec.scratchdirname>
<value>/user/hive/tmpvalue>
property>
<property>
<name>hive.scratch.dir.permissionname>
<value>775value>
property>
<property>
<name>hive.metastore.warehouse.dirname>
<value>/user/hive/warehousevalue>
property>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://node1:3306/hive?createDatabaseIfNotExist=truevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>hivevalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>123value>
property>
<property>
<name>hive.metastore.urisname>
<value>thrift://node1:9083,thrift://node2:9083value>
property>
configuration>
EOF
4.7.3.4分发文件到其他节点
[root@node1 conf]# for i in {node2,node3}
do
scp -r /opt/bigdata/hive/ $i:/opt/bigdata/
scp /root/.bash_profile $i:/root/
done
4.7.3.5初始化MYSQL
下载mysql驱动包到Hive的lib目录下
地址:https://mvnrepository.com/artifact/mysql/mysql-connector-java

#下载mysql驱动
[root@node1 conf]# wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.49/mysql-connector-java-5.1.49.jar -P /opt/bigdata/hive/lib/
#分发mysql驱动到其他节点
[root@node1 conf]# scp ../lib/mysql-connector-java-5.1.49.jar node2:/opt/bigdata/hive/lib/
[root@node1 conf]# scp ../lib/mysql-connector-java-5.1.49.jar node3:/opt/bigdata/hive/lib/
#删除hive下的log4j-slf4j-impl-2.17.1.jar,会与hadoop下的slf4j-reload4j-1.7.36.jar 冲突
[root@node1 ~]# for i in {node1,node2,node3}
do
ssh $i "rm -f /opt/bigdata/hive/lib/log4j-slf4j-impl-2.17.1.jar"
done
#初始化MYSQL
[root@node1 conf]# schematool -dbType mysql -initSchema
Metastore connection URL: jdbc:mysql://node1:3306/hive?createDatabaseIfNotExist=true
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: hive
...
Initialization script completed
...
schemaTool completed
4.7.3.6启动metastore
[root@node1 conf]# mkdir /opt/bigdata/hive/logs
[root@node1 conf]# nohup hive --service metastore >> /opt/bigdata/hive/logs/metastore.log 2>&1 &
[root@node2 ~]# mkdir /opt/bigdata/hive/logs
[root@node2 ~]# nohup hive --service metastore >> /opt/bigdata/hive/logs/metastore.log 2>&1 &
#查看启动的服务,验证
[root@node2 ~]# ss -ntulp | grep 9083
tcp LISTEN 0 50 [::]:9083 [::]:* users:(("java",pid=8602,fd=635))
4.7.3.7 配置hiveserver2
node2和node3上操作 注意修改hive.server2.thrift.bind.host为本机的hostname
[root@node2 ~]# cd /opt/bigdata/hive/conf/
[root@node2 conf]# cat > hiveserver2-site.xml << 'EOF'
<configuration>
<property>
<name>hive.metastore.urisname>
<value>thrift://node1:9083,thrift://node2:9083value>
property>
<property>
<name>hive.server2.support.dynamic.service.discoveryname>
<value>truevalue>
<description>当启用时,Hive Server 2会注册到ZooKeeper,并通过ZooKeeper进行服务发现。这可以支持Hive Server 2的高可用和负载均衡配置description>
property>
<property>
<name>hive.server2.active.passive.ha.enablename>
<value>truevalue>
property>
<property>
<name>hive.server2.zookeeper.namespacename>
<value>hiveserver2_zkvalue>
property>
<property>
<name>hive.zookeeper.quorumname>
<value>node1:2181,node2:2181,node3:2181value>
property>
<property>
<name>hive.zookeeper.client.portname>
<value>2181value>
property>
<property>
<name>hive.server2.thrift.portname>
<value>10001value>
property>
<property>
<name>hive.server2.thrift.bind.hostname>
<value>node2value>
property>
<property>
<name>hive.querylog.locationname>
<value>/user/hive/logsvalue>
property>
configuration>
EOF
#分发配置文件到node3,并修改hive.server2.thrift.bind.host 的值
[root@node2 conf]# scp hiveserver2-site.xml node3:/opt/bigdata/hive/conf/
#修改为node3
[root@node3 ~]# vim /opt/bigdata/hive/conf/hiveserver2-site.xml
...
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node3</value>
</property>
...
4.7.3.8启动hiveserver2
#启动
[root@node2 ~]# nohup hive --service hiveserver2 >> /opt/bigdata/hive/logs/hiveserver2.log 2>&1 &
[root@node3 ~]# mkdir /opt/bigdata/hive/logs
[root@node3 ~]# nohup hive --service hiveserver2 >> /opt/bigdata/hive/logs/hiveserver2.log 2>&1 &
#查看端口,没有启动起来,连接不上10001
[root@node2 ~]# ss -ntulp | grep 10001
#查看日志报错信息
[root@node2 ~]# less /opt/bigdata/hive/logs/hiveserver2.log
...
WARN [main] metastore.RetryingMetaStoreClient: MetaStoreClient lost connection. Attempting to reconnect (1 of 1) after 1s. getCurrentNotificationEventId
org.apache.thrift.TApplicationException: Internal error processing get_current_notificationEventId
#解决办法,修改hadoop配置
#停止hadoop集群
[root@node1 ~]# stop-yarn.sh
[root@node1 ~]# stop-dfs.sh
#修改core-site.xml文件
[root@node1 ~]# cd /opt/bigdata/hadoop/etc/hadoop/
#在core-site.xml中加入以下配置
[root@node1 hadoop]# vim core-site.xml
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
#hadoop.proxyuser.xxx.hosts和hadoop.proxyuser.xxx.groups,其中xxx为启动HiveServer2的用户
#将hadoop核心配置文件也放入hive,防止在后面的使用中出现hdfs://mycluster/ 不能识别mycluster的情况出现
[root@node1 hadoop]# for i in {node1,node2,node3}
do
scp core-site.xml hdfs-site.xml $i:/opt/bigdata/hive/conf/
done
#启动hdfs和yarn,等待启动完成
[root@node1 ~]# start-dfs.sh
[root@node1 ~]# start-yarn.sh
#再次启动hiveserver2
[root@node2 ~]# nohup hive --service hiveserver2 >> /opt/bigdata/hive/logs/hiveserver2.log 2>&1 &
[root@node3 ~]# nohup hive --service hiveserver2 >> /opt/bigdata/hive/logs/hiveserver2.log 2>&1 &
[root@node3 ~]# ss -ntulp | grep 10001
tcp LISTEN 0 50 [::]:10001 [::]:* users:(("java",pid=3090,fd=629))
4.7.3.9连接测试
[root@node3 ~]# beeline -u jdbc:hive2://node2:10001
0: jdbc:hive2://node2:10001>
[root@node3 ~]# beeline -u jdbc:hive2://node3:10001
0: jdbc:hive2://node3:10001>
4.7.3.10问访问
http://192.168.1.12:10002/

http://192.168.1.13:10002/

4.7.3.11 hive的使用测试
[root@node3 ~]# beeline
Beeline version 2.3.9 by Apache Hive
beeline> !connect jdbc:hive2://192.168.1.12:10001
Connecting to jdbc:hive2://192.168.1.12:10001
Enter username for jdbc:hive2://192.168.1.12:10001: #回车
Enter password for jdbc:hive2://192.168.1.12:10001: #回车
2023-07-23 18:32:38,251 INFO jdbc.Utils: Supplied authorities: 192.168.1.12:10001
2023-07-23 18:32:38,251 INFO jdbc.Utils: Resolved authority: 192.168.1.12:10001
Connected to: Apache Hive (version 3.1.3)
Driver: Hive JDBC (version 2.3.9)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://192.168.1.12:10001> create database if not exists mytestdb;
No rows affected (1.198 seconds)
0: jdbc:hive2://192.168.1.12:10001> use mytestdb;
No rows affected (0.043 seconds)
0: jdbc:hive2://192.168.1.12:10001> show tables;
+-----------+
| tab_name |
+-----------+
+-----------+
No rows selected (0.213 seconds)
0: jdbc:hive2://192.168.1.12:10001> describe database mytestdb;
+-----------+----------+---------------------------------------------------+-------------+-------------+-------------+
| db_name | comment | location | owner_name | owner_type | parameters |
+-----------+----------+---------------------------------------------------+-------------+-------------+-------------+
| mytestdb | | hdfs://mycluster/user/hive/warehouse/mytestdb.db | anonymous | USER | |
+-----------+----------+---------------------------------------------------+-------------+-------------+-------------+
1 row selected (0.115 seconds)
0: jdbc:hive2://192.168.1.12:10001> CREATE EXTERNAL TABLE IF NOT EXISTS mytesttable (
. . . . . . . . . . . . . . . . . > name string,
. . . . . . . . . . . . . . . . . > age string,
. . . . . . . . . . . . . . . . . > workplace ARRAY<STRING>
. . . . . . . . . . . . . . . . . > )
. . . . . . . . . . . . . . . . . > COMMENT 'This is an text table';
No rows affected (0.265 seconds)
0: jdbc:hive2://192.168.1.12:10001> show tables;
+--------------+
| tab_name |
+--------------+
| mytesttable |
+--------------+
1 row selected (0.049 seconds)
0: jdbc:hive2://192.168.1.12:10001> desc mytesttable;
+------------+----------------+----------+
| col_name | data_type | comment |
+------------+----------------+----------+
| name | string | |
| age | string | |
| workplace | array<string> | |
+------------+----------------+----------+
3 rows selected (0.067 seconds)
4.7.3.12 hive客户端配置
#新加的虚拟机192.168.1.14
cd $HIVE_HOME/conf
cat > hive-site.xml << 'EOF'
hive.metastore.uris
thrift://node1:9083,thrift://node2:9083
hive.cli.print.header
true
hive.cli.print.current.db
true
EOF
#解决guava版本不一致问题
#删除hive下的低版本guava
rm -f /opt/bigdata/hive/lib/guava-19.0.jar
#复制hadoop下的高版本guava到hive
cp /opt/bigdata/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /opt/bigdata/hive/lib/