19 视图定义 union 是根据第一个 select 字段列表顺序,来进行 merge 的
前言
这个问题主要是 在之前存在这样的一个问题, 在生产环境上面
按照 我的直观理解, mysql 应该是根据 key 进行 merge, 所以 select 的顺序应该是 “不重要”??, 但是 结果我理解错了
然后 线上的查询也出现了问题, 发现很奇怪的问题, 明明 key01 列 是 id, 但是有一部分 key01 是 field1, 然后 进而 产生了业务上面的查询问题
这里从 mysql 的查询开始回溯这里的整个流程
select id as key01, field1 as key02 from tz_test
union
select field1 as key02, id as key01 from tz_test_02
测试表结构信息如下
CREATE TABLE `tz_test` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`field1` varchar(12) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=3333343 DEFAULT CHARSET=utf8
将数据从 rec 转换为 mysql_rec
这里的处理是将具体的 rec 中的给定的字段复制到 mysql_rec 中存储
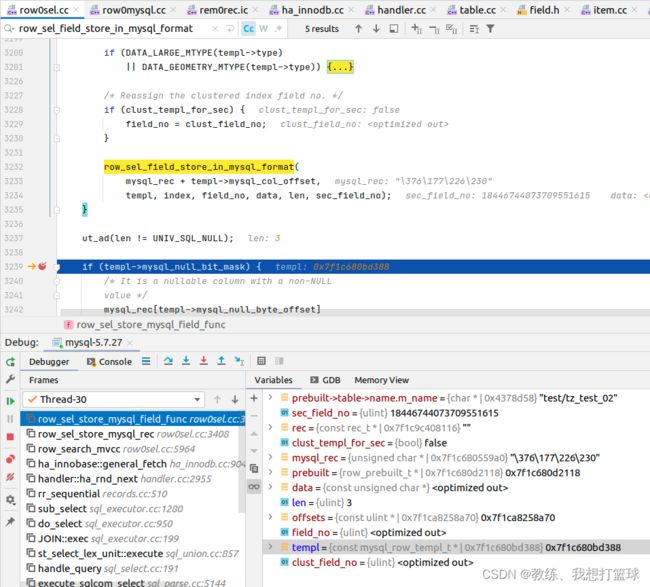
外层是遍历字段, 遍历完字段之后 需要的字段就已经转换到了 mysql_rec 中
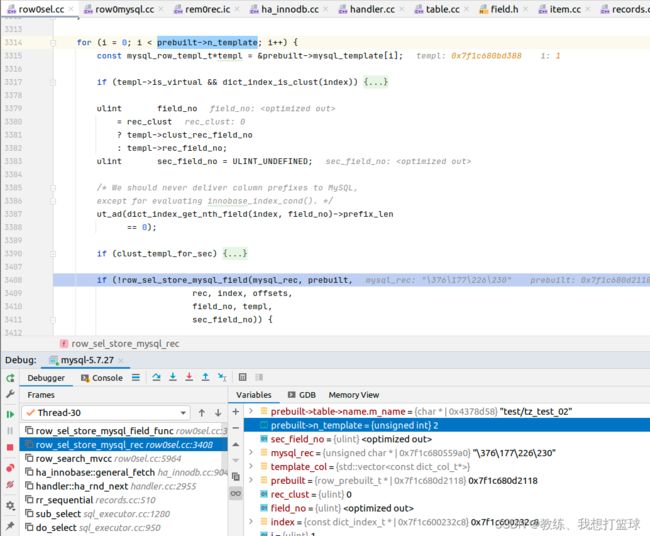
mysql_rec 中的顺序和 select 中的顺序无关
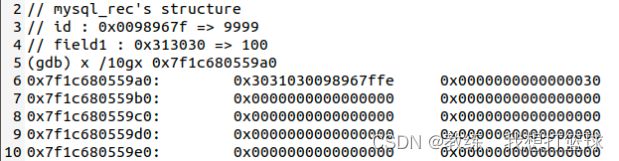
rec 的数据部分结构如下

mysql_rec 的结构如下, prebuilt->mysql_template[i] 中存储的是响应的字段的元数据
将数据更新到 Field->ptr 中
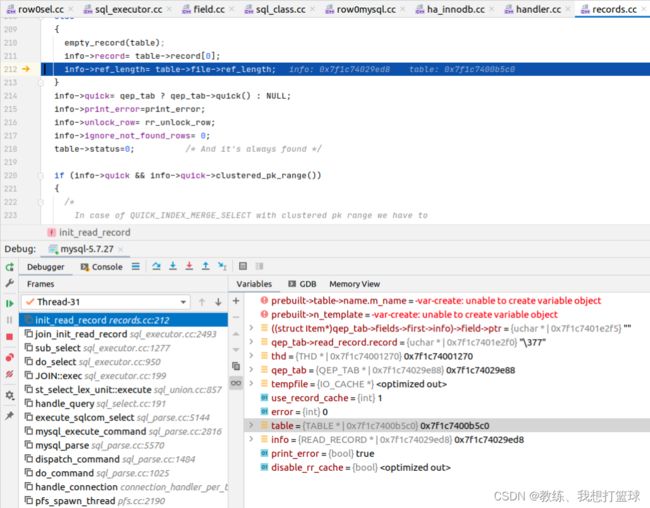
初始化 read_record 的地方
这里初始化的 record 为 table->record[0]
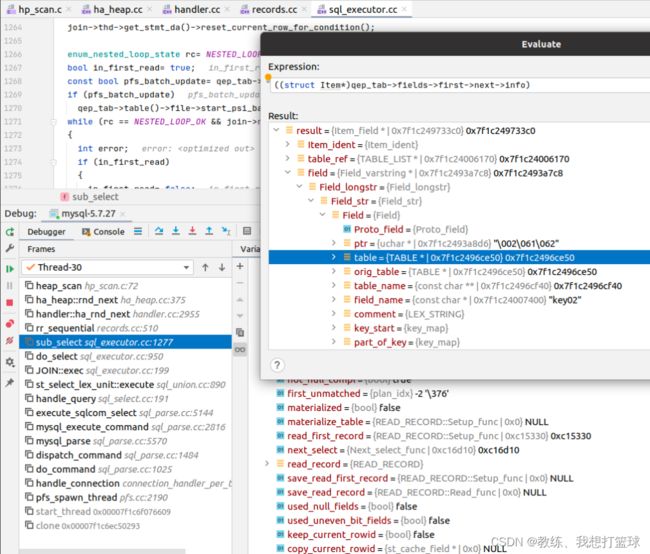
再看 qeb_tab->fields 中的信息可以看到 ptr 已经设置好了, 可以推断出 ptr 是在之前就已经更新好了的, 这需要回溯到 table->record 的初始化相关
qup_tab 中的 fields, all_fields 初始化如下 JOIN.fields_list, all_fields
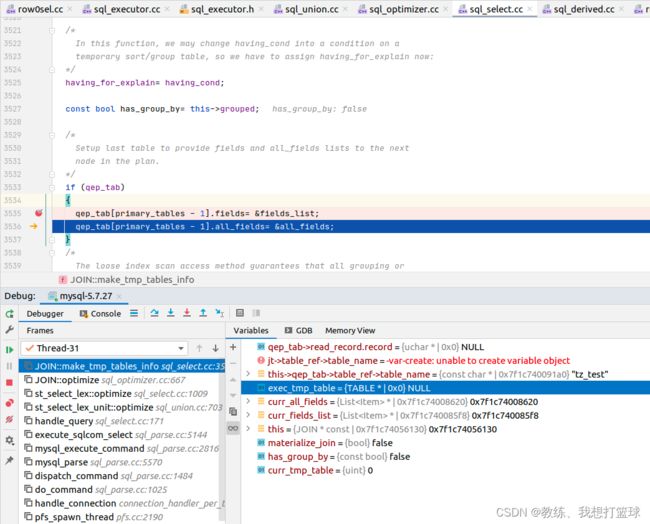
join 的 fields_list 来自于 select_lex
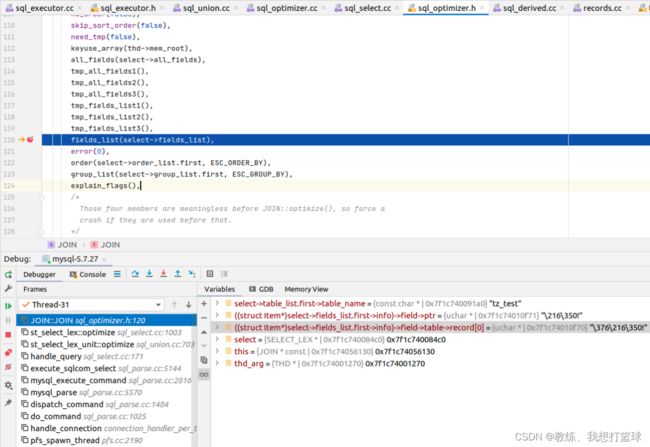
解析来源 sql 的时候从 sql 中解析出了 字段名称, 但是 尚未填充 TABLE, FIELD 等等相关结构
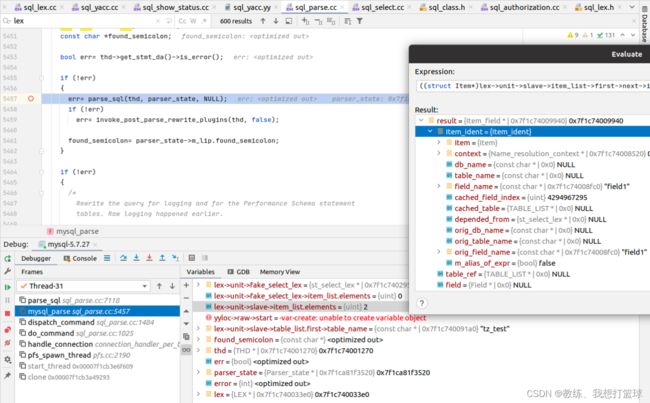
select_lex 中的各个字段初始化如下, 主要是通过 find_field_in_tables 中查询的
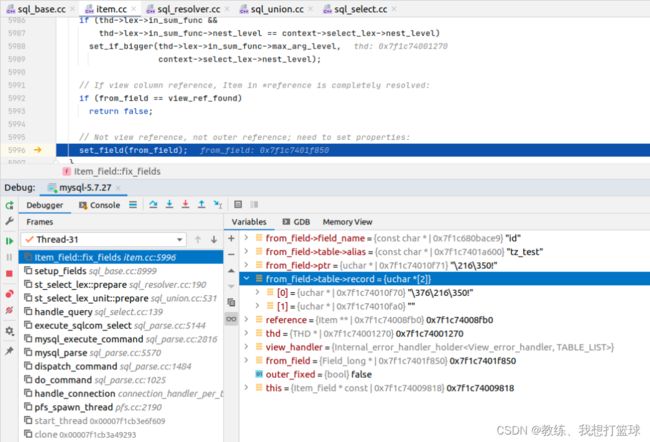
比如我们这里 tz_test 表, 字段的 lookup 是通过遍历字段 然后 比较字段名来确认的
其他的信息 我们不在赘述
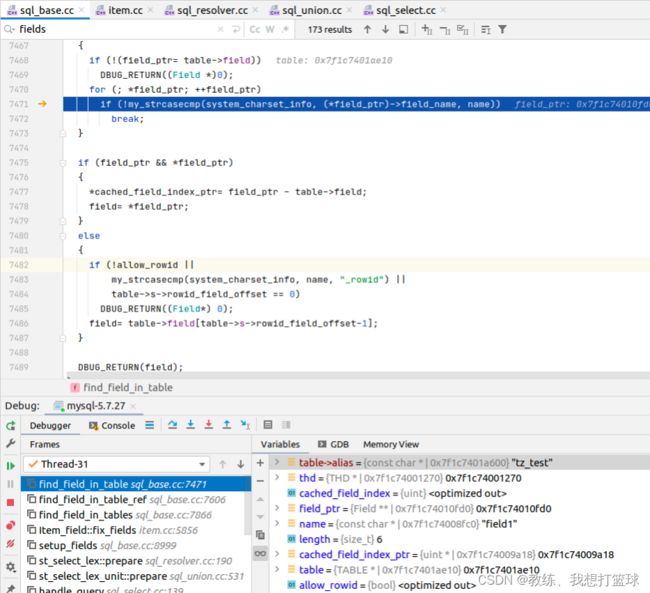
TABLE 的 record[0] 的初始化, 和相关的 Field 的初始化的流程了
默认情况下 mysql 目标表的加载是懒加载的
然后这里从 frm 中读取相关的元数据, 加载到 服务的内存中
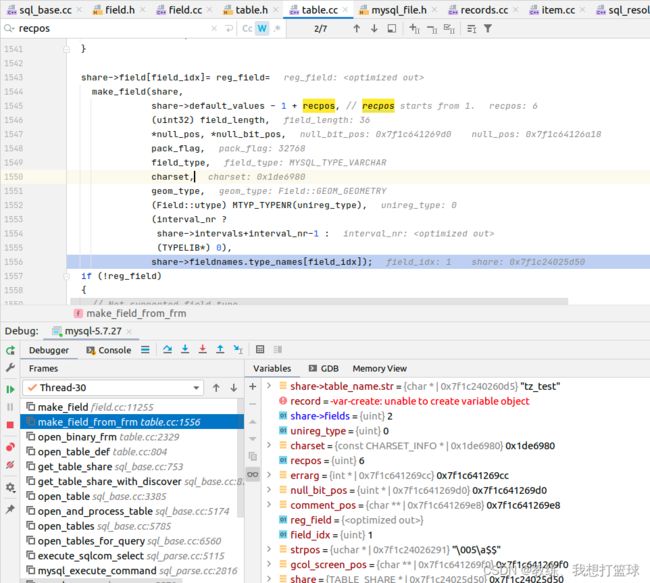
这里是创建各个 Field

然后给定的字段的 ptr 是初始化为 table->record[0] 加上一个字段偏移
所以说字段布局已经在创建表 的时候已经确定好了
这就是为什么 上面服务器将数据从 rec 中转换到 mysql_rec 中
然后后面基于 Item, Field 可以直接读取到给定的字段的值的原因了
union表 的结果查询
union 这边是通过一个临时表来进行的数据查询
子查询1 将查询结果 “写入” 临时表union
子查询2 将查询结果 “写入” 临时表union
然后 最终一起查询 临时表union, 然后再将相应的数据 响应给客户端
迭代具体的记录信息的地方如下
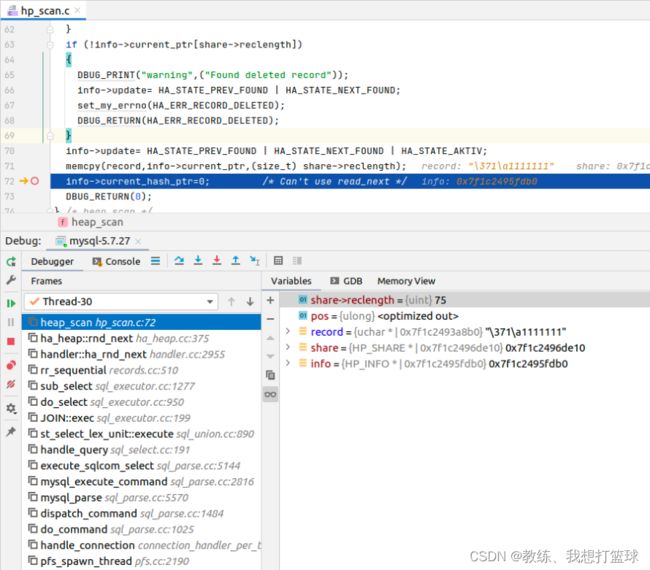
这里拷贝的 rec 记录信息如下, 这是 临时表 的 TABLE->record[0]
然后这里的存储方式是按照 mysql_rec 的方式来存储, 然后使用 Field_xxx::val_str 来读取给定的 buf 的数据, 然后之后通过
临时表union 的 key01 字段如下, 可以看到 ptr 是在 TABLE->record[0] 的区间内

临时表union 的 key02 字段如下, 可以看到 ptr 是在 TABLE->record[0] 的区间内
表中的数据通过 Field_varstring::val_str 来解析给定的 mysql_rec 的数据

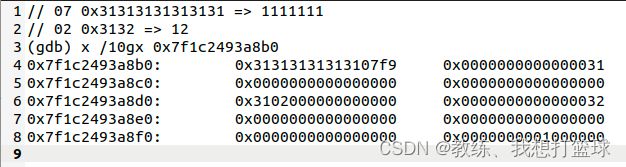
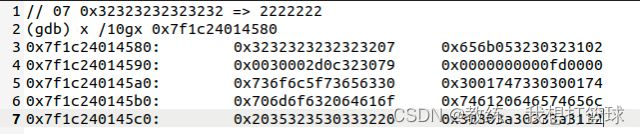
将待输出字符串输出到输出缓冲区, 这里记录了 长度 和 具体的字符信息
这里待输出字符串为 “7777777”, 输出一个字节长度 07, 接着七个字节为 ‘7’

输出缓冲区待写出数据如下, 一个字节长度 0x07, 七个字节字符信息 “0x32323232323232”
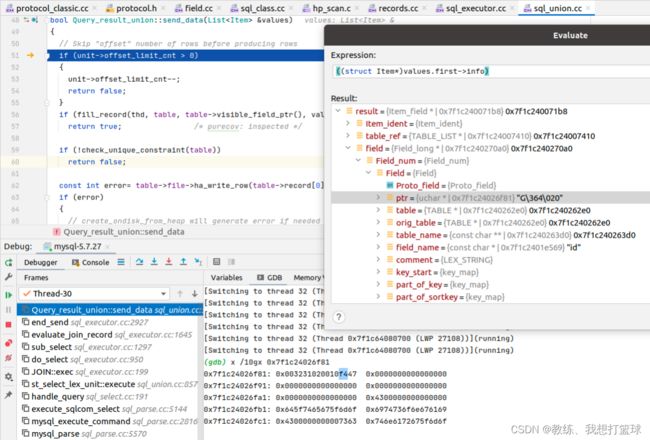
union表 的数据来源
这是从 “select id as key01, field1 as key02 from tz_test” 查询出来的第一条记录
然后 将其写出到 union表
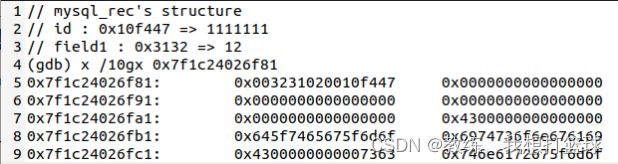
tz_test 查询出来的第一条记录 {id : 1111111, field1 : 12 }
将查询出来的第一条记录的 id 转换为 Field_str, 存储起来
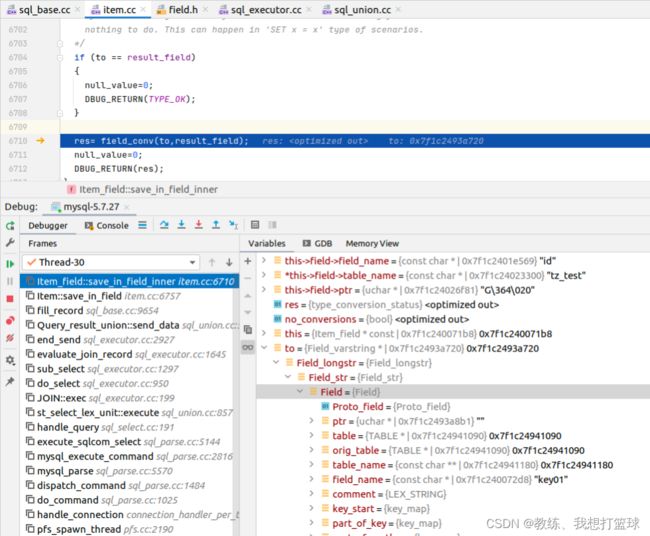
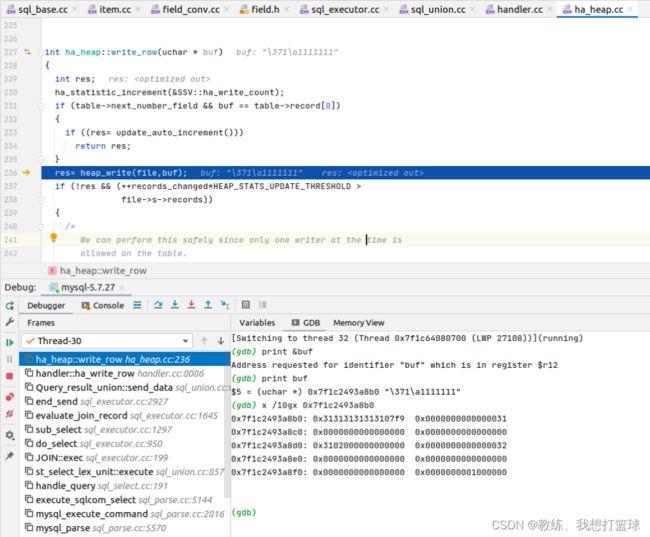
将 TABLE->record[0] 的数据 “持久化” 起来, 这里是放到 ha_heap 的固定的空间
tz_test_2 的查询结果做数据转换的时候, 可以看到的是 field1 存储到的是 key01 字段
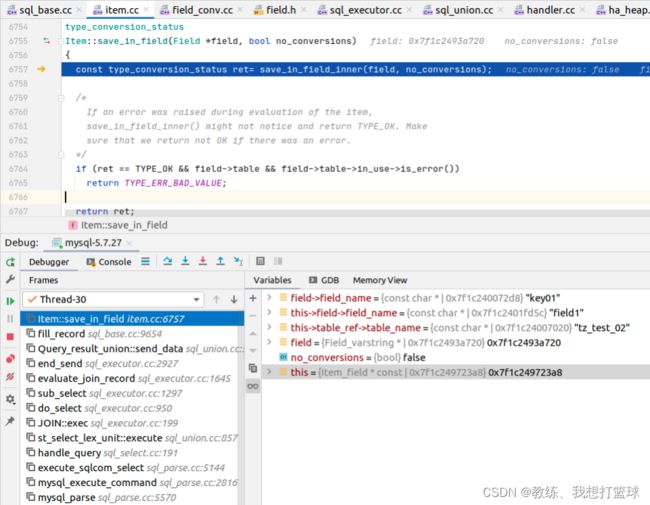
这个字段是顺序如下, key01, key02 是取自 union 的第一个查询, 根据这个字段列表创建的临时表
然后 “select field1 as key02, id as key01 from tz_test_02” 的查询结果按照 列的顺序 分别保存到对应的列, 然后 后面 table->file->ha_file_write 写出到 union表

union表 的创建
创建临时表的地方如下, 在 handle_query 的地方, 传入的 column_types 列表为 key01, key02

传入的 column_types 外部的初始化如下, 获取第一个查询 选择列 列表, 作为临时表的字段列表

在执行 join 之前, 创建了 结果的临时表
然后 后面查询迭代使用的字段列表, 都是使用的 这里创建的字段列表

完