Flink
flink应用场景
 maven依赖
maven依赖
1.17.0
org.apache.flink
flink-streaming-java
${flink.version}
provided
org.apache.flink
flink-clients
${flink.version}
provided
有界流

流处理
来一条计算一条,输出一次
package com.atguigu.wc;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* TODO DataStream实现Wordcount:读文件(有界流)
*
* @author cjp
* @version 1.0
*/
public class WordCountStreamDemo {
public static void main(String[] args) throws Exception {
// TODO 1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// TODO 2.读取数据:从文件读
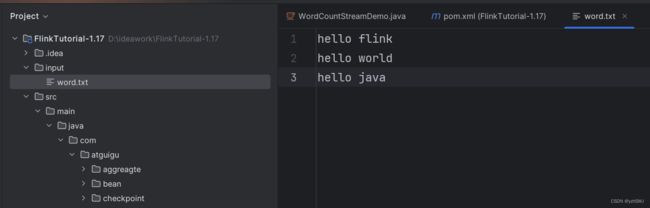
DataStreamSource lineDS = env.readTextFile("input/word.txt");
// TODO 3.处理数据: 切分、转换、分组、聚合
// TODO 3.1 切分、转换
SingleOutputStreamOperator> wordAndOneDS = lineDS
.flatMap(new FlatMapFunction>() {
@Override
public void flatMap(String value, Collector> out) throws Exception {
// 按照 空格 切分
String[] words = value.split(" ");
for (String word : words) {
// 转换成 二元组 (word,1)
Tuple2 wordsAndOne = Tuple2.of(word, 1);
// 通过 采集器 向下游发送数据
out.collect(wordsAndOne);
}
}
});
// TODO 3.2 分组
KeyedStream, String> wordAndOneKS = wordAndOneDS.keyBy(
new KeySelector, String>() {
@Override
public String getKey(Tuple2 value) throws Exception {
//取出 二元组 (word,1) 第一个元素
return value.f0;
}
}
);
// TODO 3.3 聚合 二元组 (word,1) 根据第二个元素聚合 索引 1
SingleOutputStreamOperator> sumDS = wordAndOneKS.sum(1);
// TODO 4.输出数据
sumDS.print();
// TODO 5.执行:类似 sparkstreaming最后 ssc.start()
env.execute();
}
}
/**
* 接口 A,里面有一个方法a()
* 1、正常实现接口步骤:
*
* 1.1 定义一个class B 实现 接口A、方法a()
* 1.2 创建B的对象: B b = new B()
*
*
* 2、接口的匿名实现类:
* new A(){
* a(){
*
* }
* }
*/

无界流
package com.atguigu.wc;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* TODO DataStream实现Wordcount:读socket(无界流)
*
* @author cjp
* @version 1.0
*/
public class WordCountStreamUnboundedDemo {
public static void main(String[] args) throws Exception {
// TODO 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// IDEA运行时,也可以看到webui,一般用于本地测试
// 需要引入一个依赖 flink-runtime-web
// 在idea运行,不指定并行度,默认就是 电脑的 线程数
// StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setParallelism(3);
// TODO 2. 读取数据: socket
DataStreamSource socketDS = env.socketTextStream("hadoop102", 7777);
// TODO 3. 处理数据: 切换、转换、分组、聚合
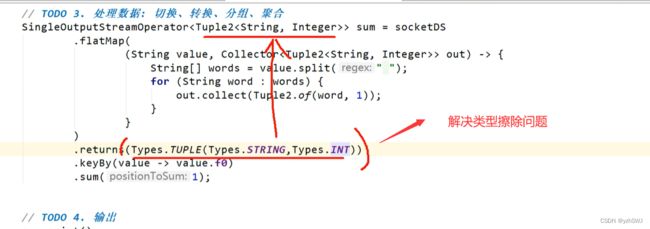
SingleOutputStreamOperator> sum = socketDS
.flatMap(
(String value, Collector> out) -> {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
)
.setParallelism(2)
.returns(Types.TUPLE(Types.STRING,Types.INT))
// .returns(new TypeHint>() {})
.keyBy(value -> value.f0)
.sum(1);
// TODO 4. 输出
sum.print();
// TODO 5. 执行
env.execute();
}
}
/**
并行度的优先级:
代码:算子 > 代码:env > 提交时指定 > 配置文件
*/ 
socket 发送数据

Flink部署





3)分发安装目录
(1)配置修改完毕后,将Flink安装目录发给另外两个节点服务器。
[atguigu@hadoop102 module]$ xsync flink-1.17.0/
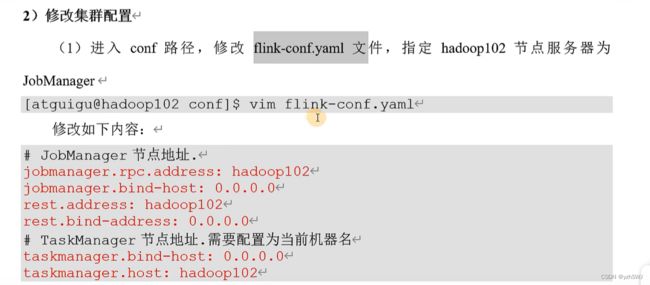
(2)修改hadoop103的 taskmanager.host
[atguigu@hadoop103 conf]$ vim flink-conf.yaml
修改如下内容:
# TaskManager节点地址.需要配置为当前机器名
taskmanager.host: hadoop103
(3)修改hadoop104的 taskmanager.host
[atguigu@hadoop104 conf]$ vim flink-conf.yaml
修改如下内容:
# TaskManager节点地址.需要配置为当前机器名
taskmanager.host: hadoop104
(4)另外,在flink-conf.yaml文件中还可以对集群中的JobManager和TaskManager组件进行优化配置,主要配置项如下:
- jobmanager.memory.process.size:对JobManager进程可使用到的全部内存进行配置,包括JVM元空间和其他开销,默认为1600M,可以根据集群规模进行适当调整。
- taskmanager.memory.process.size:对TaskManager进程可使用到的全部内存进行配置,包括JVM元空间和其他开销,默认为1728M,可以根据集群规模进行适当调整。
- taskmanager.numberOfTaskSlots:对每个TaskManager能够分配的Slot数量进行配置,默认为1,可根据TaskManager所在的机器能够提供给Flink的CPU数量决定。所谓Slot就是TaskManager中具体运行一个任务所分配的计算资源。
- parallelism.default:Flink任务执行的并行度,默认为1。优先级低于代码中进行的并行度配置和任务提交时使用参数指定的并行度数量。
关于Slot和并行度的概念,我们会在下一章做详细讲解。
4)启动集群
(1)在hadoop102节点服务器上执行start-cluster.sh启动Flink集群:
[atguigu@hadoop102 flink-1.17.0]$ bin/start-cluster.sh
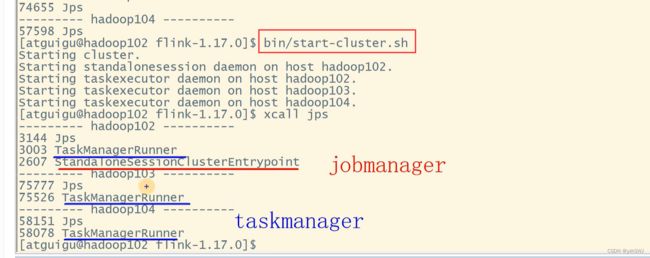
(2)查看进程情况:
[atguigu@hadoop102 flink-1.17.0]$ jpsall
=============== hadoop102 ===============
4453 StandaloneSessionClusterEntrypoint
4458 TaskManagerRunner
4533 Jps
=============== hadoop103 ===============
2872 TaskManagerRunner
2941 Jps
=============== hadoop104 ===============
2948 Jps
2876 TaskManagerRunner
5)访问Web UI
启动成功后,同样可以访问http://hadoop102:8081对flink集群和任务进行监控管理。
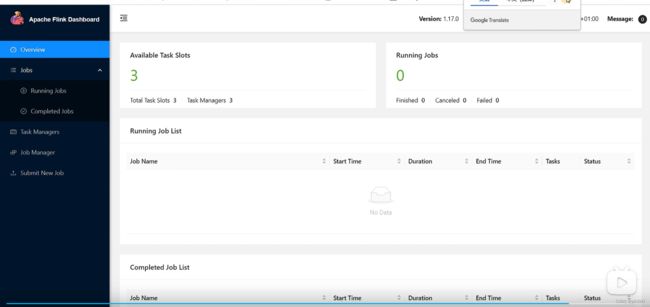
这里可以明显看到,当前集群的TaskManager数量为3;由于默认每个TaskManager的Slot数量为1,所以总Slot数和可用Slot数都为3。
3.2.2 向集群提交作业
在上一章中,我们已经编写读取socket发送的单词并统计单词的个数程序案例。本节我们将以该程序为例,演示如何将任务提交到集群中进行执行。具体步骤如下。
1)环境准备
在hadoop102中执行以下命令启动netcat。(scoket发送消息)
[atguigu@hadoop102 flink-1.17.0]$ nc -lk 7777
2)程序打包
(1)在我们编写的Flink入门程序的pom.xml文件中添加打包插件的配置,具体如下:
org.apache.maven.plugins
maven-shade-plugin
3.2.4
package
shade
com.google.code.findbugs:jsr305
org.slf4j:*
log4j:*
*:*
META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
(2)插件配置完毕后,可以使用IDEA的Maven工具执行package命令,出现如下提示即表示打包成功。
打包完成后,在target目录下即可找到所需JAR包,JAR包会有两个,FlinkTutorial-1.0-SNAPSHOT.jar和FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar,因为集群中已经具备任务运行所需的所有依赖,所以建议使用FlinkTutorial-1.0-SNAPSHOT.jar。
3)在Web UI上提交作业
(1)任务打包完成后,我们打开Flink的WEB UI页面,在右侧导航栏点击“Submit New
Job”,然后点击按钮“+ Add New”,选择要上传运行的JAR包,如下图所示。
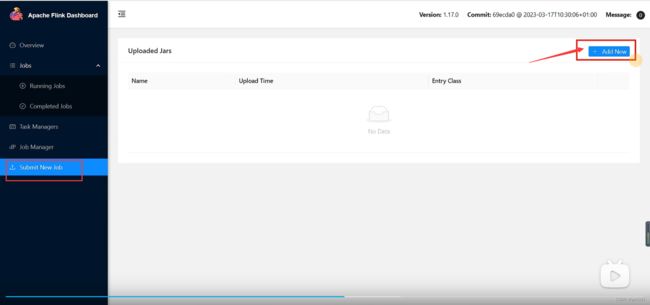
JAR包上传完成,如下图所示:

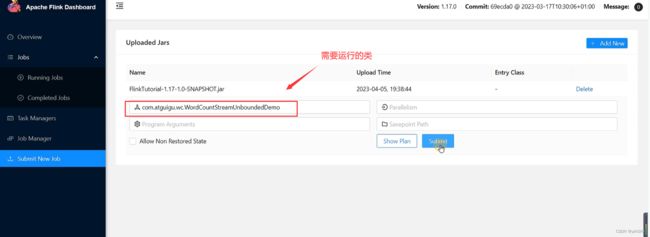
(2)点击该JAR包,出现任务配置页面,进行相应配置。
主要配置程序入口主类的全类名,任务运行的并行度,任务运行所需的配置参数和保存点路径等,如下图所示,配置完成后,即可点击按钮“Submit”,将任务提交到集群运行。
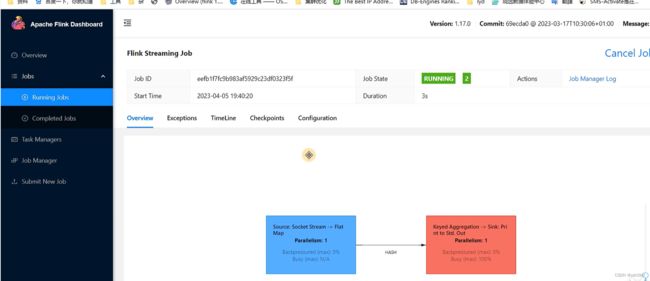
(3)任务提交成功之后,可点击左侧导航栏的“Running Jobs”查看程序运行列表情况。
(4)测试
①在socket端口中输入hello
[atguigu@hadoop102 flink-1.17.0]$ nc -lk 7777
hello
②先点击Task Manager,然后点击右侧的192.168.10.104服务器节点
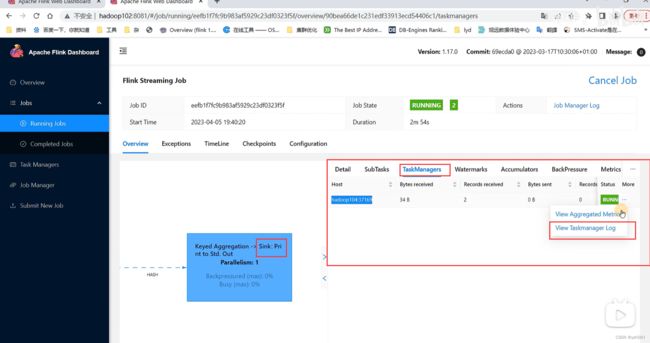
③点击Stdout,就可以看到hello单词的统计
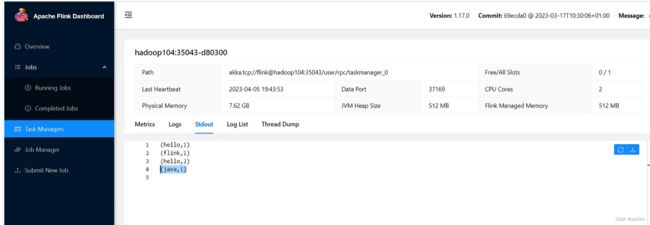
注意:如果hadoop104节点没有统计单词数据,可以去其他TaskManager节点查看。
(4)点击该任务,可以查看任务运行的具体情况,也可以通过点击“Cancel Job”结束任务运行。

4)命令行提交作业
除了通过WEB UI界面提交任务之外,也可以直接通过命令行来提交任务。这里为方便起见,我们可以先把jar包直接上传到目录flink-1.17.0下
(1)首先需要启动集群。
[atguigu@hadoop102 flink-1.17.0]$ bin/start-cluster.sh
(2)在hadoop102中执行以下命令启动netcat。
[atguigu@hadoop102 flink-1.17.0]$ nc -lk 7777
(3)将flink程序运行jar包上传到/opt/module/flink-1.17.0路径。
(4)进入到flink的安装路径下,在命令行使用flink run命令提交作业。
[atguigu@hadoop102 flink-1.17.0]$ bin/flink run -m hadoop102:8081 -c com.atguigu.wc.SocketStreamWordCount ./FlinkTutorial-1.0-SNAPSHOT.jar
这里的参数 -m指定了提交到的JobManager,-c指定了入口类。
(5)在浏览器中打开Web UI,http://hadoop102:8081查看应用执行情况。
用netcat输入数据,可以在TaskManager的标准输出(Stdout)看到对应的统计结果。
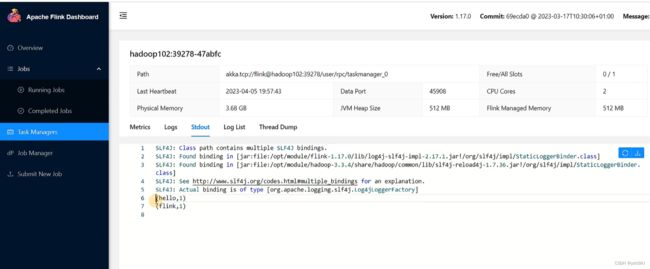
(6)在/opt/module/flink-1.17.0/log路径中,可以查看TaskManager节点。
[atguigu@hadoop102 log]$ cat flink-atguigu-standalonesession-0-hadoop102.out
(hello,1)
(hello,2)
(flink,1)
(hello,3)
(scala,1)
部署模式
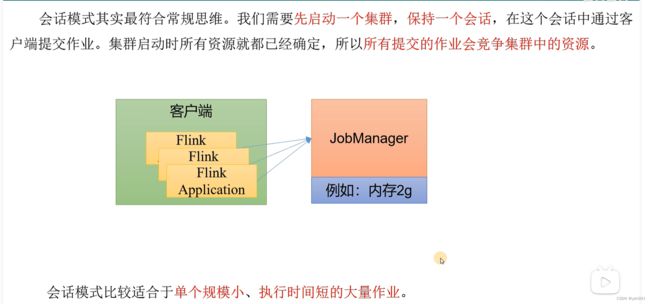
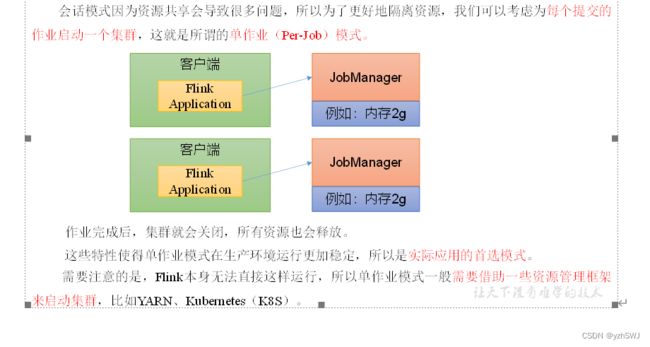
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。Flink为各种场景提供了不同的部署模式,主要有以下三种:会话模式(Session Mode)、单作业模式(Per-Job Mode)、应用模式(Application Mode)。
它们的区别主要在于:集群的生命周期以及资源的分配方式;以及应用的main方法到底在哪里执行——客户端(Client)还是JobManager。
3.3.1 会话模式(Session Mode)
3.3.2 单作业模式(Per-Job Mode)
3.3.3 应用模式(Application Mode)