CHAPTER 4: DESIGN A RATE LIMITER
Step 1 - Understand the problem and establish design scope
Rate limiting can be implemented using different algorithms
client-side rate limiter or
server-side API rate limiter
Does the rate limiter throttle API requests based on IP, the user ID, or other properties?
What is the scale of the system?
Will the system work in a distributed environment?
Is the rate limiter a separate service or should it be implemented in application code?
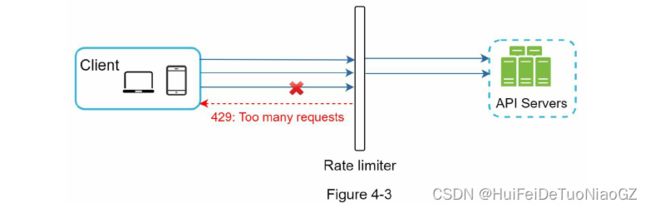
Do we need to inform users who are throttled?
• Accurately limit excessive requests.
• Low latency. The rate limiter should not slow down HTTP response time.
• Use as little memory as possible.
• Distributed rate limiting. The rate limiter can be shared across multiple servers or
processes.
• Exception handling. Show clear exceptions to users when their requests are throttled.
• High fault tolerance. If there are any problems with the rate limiter (for example, a cache
server goes offline), it does not affect the entire system.
Step 2 - Propose high-level design and get buy-in
Where to put the rate limiter?
• Client-side implementation. Generally speaking, client is an unreliable place to enforce
rate limiting because client requests can easily be forged by malicious actors. Moreover,
we might not have control over the client implementation.
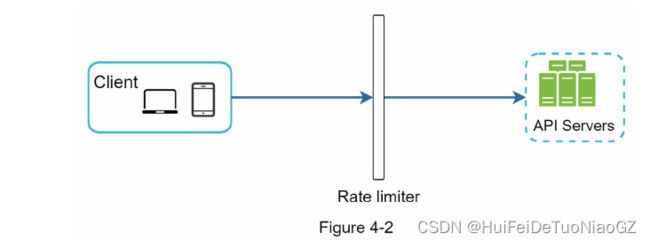
• Server-side implementation. Figure 4-1 shows a rate limiter that is placed on the serverside.

API gateway
supports rate limiting, SSL termination, authentication, IP whitelisting, servicing static content, etc
It depends on your company’s current technology stack, engineering resources, priorities, goals, etc. Here are a few general guidelines:
technology stack,
Identify the rate limiting algorithm that fits your business needs.(on server side we can change as we want)
If you have already used microservice architecture and included an API gateway in the design to perform authentication, IP whitelisting, etc., you may add a rate limiter to the API gateway.
Building your own rate limiting service takes time.
Algorithms for rate limiting
• Token bucket
• Leaking bucket
• Fixed window counter
• Sliding window log
• Sliding window counter
Token bucket algorithm
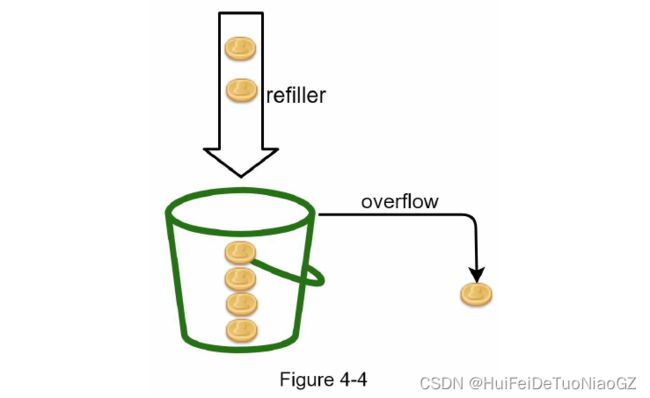
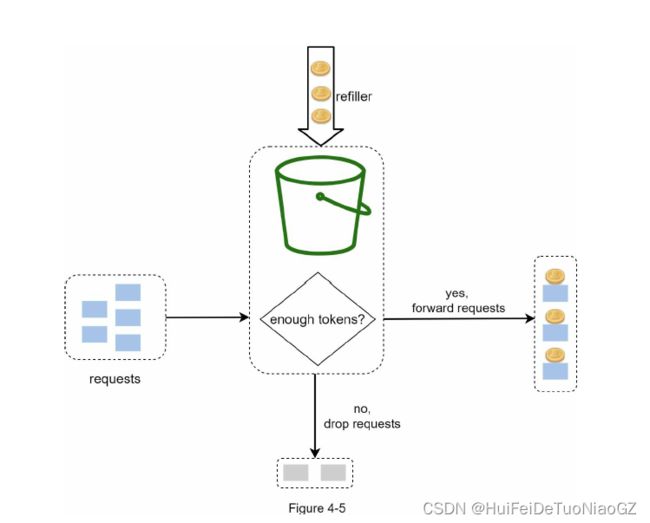
In this example, the token bucket size is 4, and the refill rate is 4 per 1 minute.
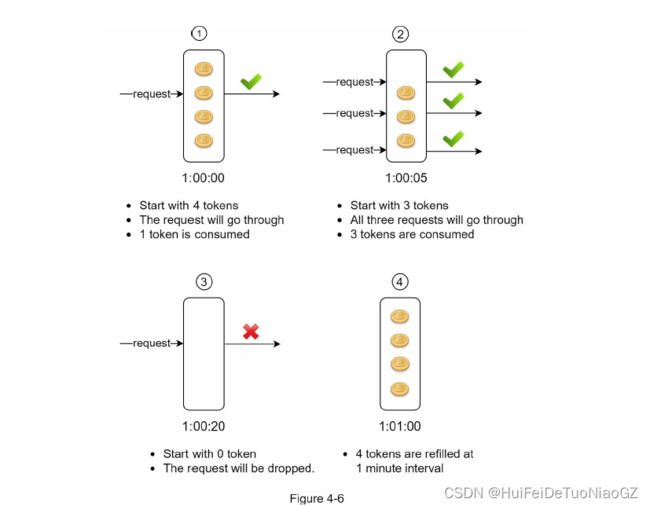
The token bucket algorithm takes two parameters:
Bucket size
Refill rate
How many buckets do we need?
It is usually necessary to have different buckets for different API endpoints.
If we need to throttle requests based on IP addresses, each IP address requires a bucket.
If the system allows a maximum of 10,000 requests per second, it makes sense to have a global bucket shared by all requests.
Pros:
• The algorithm is easy to implement.
• Memory efficient.
• Token bucket allows a burst of traffic for short periods. A request can go through as long
as there are tokens left.
Cons:
• Two parameters in the algorithm are bucket size and token refill rate. However, it might
be challenging to tune them properly.
Leaking bucket algorithm

Leaking bucket algorithm takes the following two parameters
• Bucket size: it is equal to the queue size. The queue holds the requests to be processed at
a fixed rate.
• Outflow rate: it defines how many requests can be processed at a fixed rate, usually in
seconds.
Pros:
• Memory efficient given the limited queue size.
• Requests are processed at a fixed rate therefore it is suitable for use cases that a stable
outflow rate is needed.
Cons:
• A burst of traffic fills up the queue with old requests, and if they are not processed in
time, recent requests will be rate limited.
• There are two parameters in the algorithm. It might not be easy to tune them properly.
Fixed window counter algorithm

A major problem with this algorithm is that a burst of traffic at the edges of time windows could cause more requests than allowed quota to go through.
Pros:
• Memory efficient.
• Easy to understand.
• Resetting available quota at the end of a unit time window fits certain use cases.
Cons:
• Spike in traffic at the edges of a window could cause more requests than the allowed quota to go through.
Sliding window log algorithm
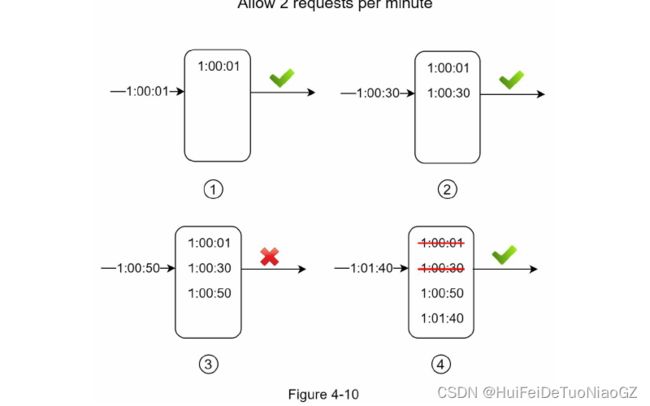
Pros:
• Rate limiting implemented by this algorithm is very accurate. In any rolling window,
requests will not exceed the rate limit.
Cons:
• The algorithm consumes a lot of memory because even if a request is rejected, its
timestamp might still be stored in memory.
Sliding window counter algorithm
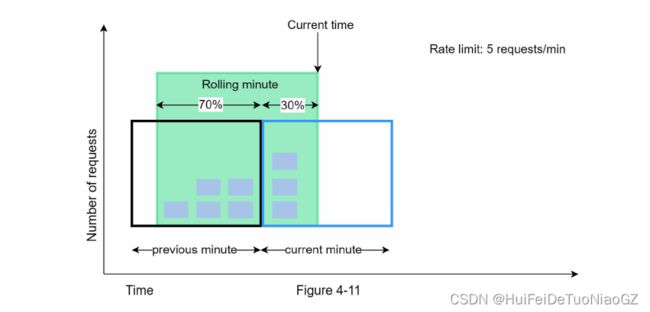
Pros
• It smooths out spikes in traffic because the rate is based on the average rate of the
previous window.
• Memory efficient.
Cons
• It only works for not-so-strict look back window. It is an approximation of the actual rate
because it assumes requests in the previous window are evenly distributed. However, this
problem may not be as bad as it seems. According to experiments done by Cloudflare [10],
only 0.003% of requests are wrongly allowed or rate limited among 400 million requests.
High-level architecture
In-memory cache is chosen because it is fast and supports time-based expiration strategy.
Redis [11] is a popular option to implement rate limiting. It is an inmemory store that offers two commands: INCR and EXPIRE.
• INCR: It increases the stored counter by 1.
• EXPIRE: It sets a timeout for the counter. If the timeout expires, the counter is automatically deleted.

Step 3 - Design deep dive
• How are rate limiting rules created? Where are the rules stored?
• How to handle requests that are rate limited?
Rate limiting rules
Rules are generally written in configuration files and saved on disk.
Exceeding the rate limit
Depending on the use cases, we may enqueue the rate-limited requests to be processed later.
Rate limiter headers
The rate limiter returns the following HTTP headers to clients:
X-Ratelimit-Remaining: The remaining number of allowed requests within the window.
X-Ratelimit-Limit: It indicates how many calls the client can make per time window.
X-Ratelimit-Retry-After: The number of seconds to wait until you can make a request again
without being throttled.
Detailed design
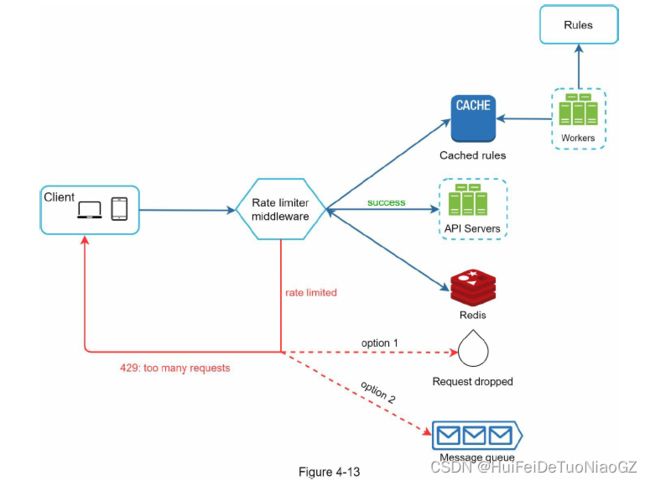
Rate limiter in a distributed environment
There are two challenges:
• Race condition
• Synchronization issue
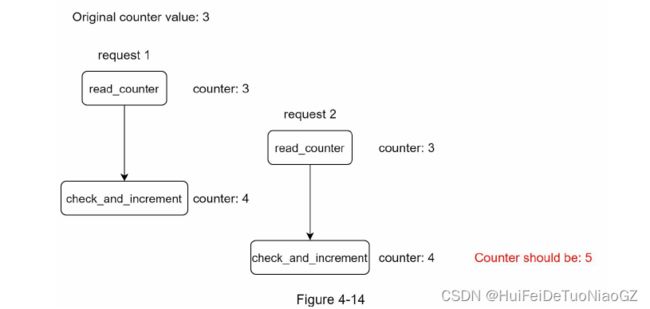
Locks are the most obvious solution for solving race condition. However, locks will significantly slow down the system
Lua script [13] and sorted sets data structure in Redis [8].

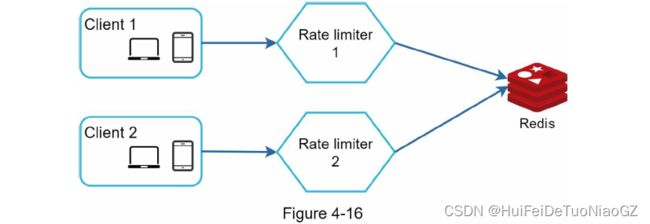
One possible solution is to use sticky sessions that allow a client to send traffic to the same
rate limiter. This solution is not advisable because it is neither scalable nor flexible. A better
approach is to use centralized data stores like Redis
Performance optimization
First, multi-data center setup is crucial for a rate limiter because latency is high for users located far away from the data center
Second, synchronize data with an eventual consistency model
Monitoring
we want to make sure:
• The rate limiting algorithm is effective.
• The rate limiting rules are effective.
Step 4 - Wrap up
• Hard vs soft rate limiting.
• Hard: The number of requests cannot exceed the threshold.
• Soft: Requests can exceed the threshold for a short period.
• Rate limiting at different levels.
Avoid being rate limited. Design your client with best practices:
• Use client cache to avoid making frequent API calls.
• Understand the limit and do not send too many requests in a short time frame.
• Include code to catch exceptions or errors so your client can gracefully recover from
exceptions.
• Add sufficient back off time to retry logic.