玩转堆排序以及Topk问题——【数据结构】

W...Y的主页
代码仓库分享
目录
堆排序
建堆
建堆的时间复杂度
Topk问题
学习了二叉树以及堆,今天我们来学习一下什么是堆排序以及经典二叉树问题——topk问题。
在学习开始我们先来回顾一下上篇博客中我们提到的堆,在实现堆时我们要进行向上调整或向下调整来继续保存堆的特性。具体代码如下:
向上调整函数:
void AdjustUp(HPDataType* a, int child) { int parent = (child - 1) / 2; while (child > 0) { if (a[child] < a[parent]) { Swap(&a[child], &a[parent]); child = parent; parent = (child - 1) / 2; } else { break; } } }向下调整函数:
void AdjustDown(HPDataType* a, int n, int parent) { int child = parent * 2 + 1; while (child < n) { if (child + 1 < n && a[child + 1] < a[child]) { child++; } if (a[child] < a[parent]) { Swap(&a[child], &a[parent]); parent = child; child = parent * 2 + 1; } else { break; } } }这是在堆的删除以及插入中我们要用到的。
堆排序
我们知道小堆就是其父节点的数小于等于子节点,而大堆就是父节点的数大于等于子节点的数。而根节点就是堆上最大或最小的数,在上篇博客中,我们实现了堆,并且完成了关于堆的插入、删除、取顶……一系列功能函数。我们只需要正确的使用,先取顶然后排序让其继续有堆的特性,再次重复这一个步骤,直到树为空树时我们就可以实现堆排序。
但是我们一般不会这样去使用堆排序,因为要实现堆排序接口太多,代码太复杂。而且一般常见的是直接给我们一长串数字让我们进行排序,如果要先一个个插入调整成堆,再进行排序时间复杂度也非常高。
那我们应该怎么办呢?
我们一般会先让整串数乱序放入数组,然后直接建堆,然后进行堆排序。
升序建大堆,降序建小堆。
那我们为什么要升序建大堆呢?建小堆不是更好吗?直接可以从中堆顶取出最小值。然后依次类推。这样是万万不能的,当取出最小值后,我们一般只能将数组中的其余数据往前挪动一位,但是挪动后就不是堆了关系全乱了,又得重新排列成堆继续取值,时间复杂度会高。
如果我们升序建大堆的话,我们就可以使用我们实现堆中的删除思想进行。
降序建小堆的原理也是删除思想,可以参考升序建大堆。

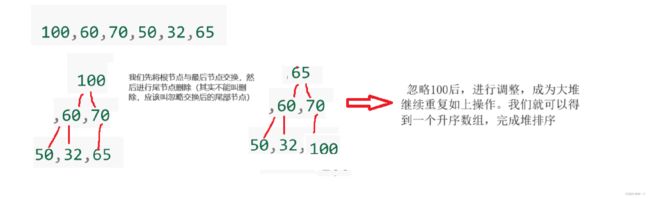

建堆
我们之前的方法是一个个插入然后向上调整,最后得到堆。但是如果遇到许多数据一起进行建堆,我们应该如何应对呢?
我们可以使用向下调整的方式建立堆,怎么建立呢?通过一组图片告诉大家: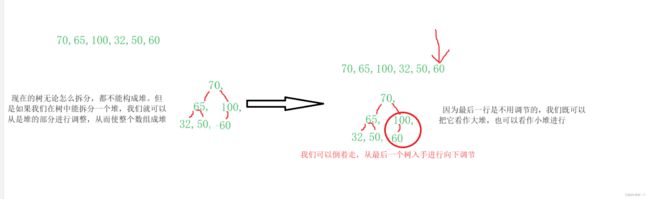
所以我们找倒数第一个非叶子节点即可。我们又知道最后一个叶子节点的下标为(k-1),那我们就可以推出parent父节点的下标为(k-2)/2。然后依次往上走就可以将堆建好。
for (int i = (k - 2) / 2; i >= 0; --i)
{
AdjustDown(minheap, k, i);
}上述代码即可建好堆。
那向上调整与向下调整哪个更好呢?我们下面来看一下它们的时间复杂度!!!
建堆的时间复杂度
向下调整:
向上调整:
我们发现还是向下调整的时间复杂度低,这是为什么呢?
因为向下调整,当在底层时遇到的数据多但是调整次数少,而向上调整在底层的节点多调整的次数也多(更通俗的讲就是多对多、少对少)所以时间复杂度高。

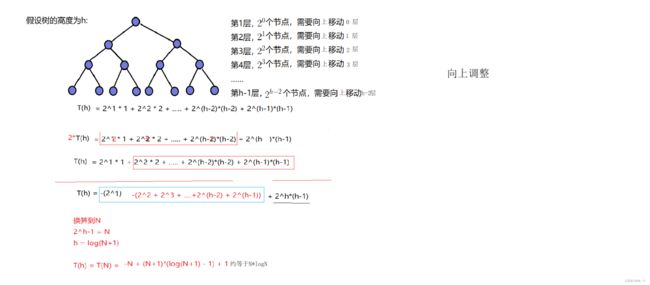
所以我们一般使用向下调整会让程序优化!
当我们建好堆后,然后使用删除思想向下调整就可以完成堆排序: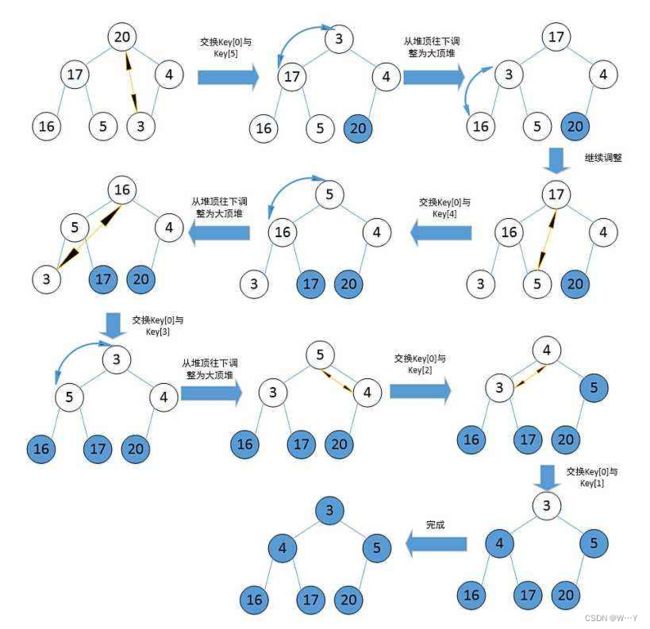
Topk问题
TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
一般情况下,我们先想到的就是暴力查找,在数据中找到需要的前k个数,但是时间复杂度非常高,第二个我们也可以将数据先进行排序qsort,然后再取前k个数内容。代码量会被优化,时间复杂度也会降低,但是也不是我们解决的最优办法。
对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能
数据都不能一下子全部加载到内存中)。最佳的方式就是用堆来解决,基本思路如下:
1. 用数据集合中前K个元素来建堆
前k个最大的元素,则建小堆
前k个最小的元素,则建大堆
2. 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素。
我们先在文件中生成10000个随机数:
void TestTopk()
{
int n = 10000;
int* a = (int*)malloc(sizeof(int) * n);
srand(time(0));
const char* file = "data.txt";
FILE* fp = fopen(file, "w");
if (fp == NULL)
{
perror("fopen error");
return;
}
for (int i = 0; i < n; ++i)
{
int x = rand() % 1000000;
fprintf(fp, "%d\n", x);
}
fclose(fp);
PrintTopK(file,10);
}然后再调用printtopk函数,传入文件名字与需要的k个数据。
读取文件中k个数据建成小堆,然后进入循环将剩下的数与根节点内容进行比较如果比根节点大就将根节点切换,然后向下调整继续形成小堆,继续循环直到文件读到末尾即可。
void PrintTopK(const char* filename, int k)
{
FILE* fp = fopen(filename, "r");
if (fp == NULL)
{
perror("fopen error");
return;
}
int* minheap = (int*)malloc(sizeof(int) * k);
if (minheap == NULL)
{
perror("malloc perror");
return;
}
for (int i = 0; i < k; i++)
{
fscanf(fp, "%d", &minheap[i]);
}
for (int i = (k - 2) / 2; i >= 0; --i)
{
AdjustDown(minheap, k, i);
}
int x = 0;
while (fscanf(fp, "%d", &x) != EOF)
{
if (x > minheap[0])
{
minheap[0] = x;
AdjustDown(minheap, k, 0);
}
}
for (int i = 0; i < k; i++)
{
printf("%d ", minheap[i]);
}
printf("\n");
fclose(fp);
}我们在程序中使用的依旧是向下调整建堆。
在此程序中,我们随机数的范围为0~999999,运行结果如下![]()
这就是我们随机生成的最大的前10个数据。
但是我们就会有疑问,万一数据不是最大的前10个呢该怎么办? 这里教大家一个测试方法:先确保运行过一次,然后屏蔽生成随机数写文件的一段程序,然后进入txt文件中。因为我们随机数范围为0~999999,所以我们在txt文件中生成比999999大的数,如果最后结果为自己改的数,则程序是正确的,反之程序就有问题需要修改。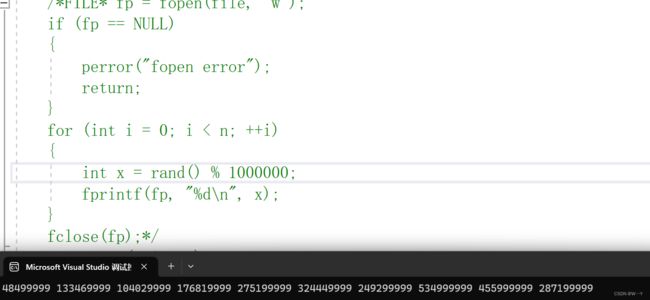
当我修改10个数后的运行结果全部是我修改的数据,说明我的程序没有问题。
最后在说明一下为什么要前k个最大元素要建小堆呢?
因为小堆可以找到树中最小的数,与文件中进行比较即可替换掉最小的数。如果使用大堆根节点为最大值,我们找到比根节点的大的数,这个数比堆中所有的数都大,我们找不出最大的k个内容,有可能将更小的数选中。
同理可得,要前k个最小元素要建大堆。
以上就是堆的两个经典问题,如果博客中讲解有误,请及时与博主。
感谢大家观看,留下一键三连再走吧!!!谢谢❤️❤️