Spark的常用概念总结
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、基本概念
-
- 1.RDD的生成
- 2.RDD的存储
- 3.Dependency
- 4.Transformation和Action
-
- 4.1 Transformation操作可以分为如下几种类型:
-
- 4.1.1 视RDD的元素为简单元素。
- 4.1.2 视RDD的元素为Key-Value对:
- 4.2 Action操作可以分为如下几种:
- 5.shuffle
- 6.Spark Application的结构
- 二、Spark SQL常用概念
-
- 1.Word Count
前言
Spark是分布式批处理框架,提供分析挖掘与迭代式内存计算能力,支持多种语言(Scala/Java/Python)的应用开发。
一、基本概念
RDD
(Resilient Distributed Dataset)只读,可分区的分布式数据集,缓存内存中计算:
1.RDD的生成
从HDFS输入创建,或从与Hadoop兼容的其他存储系统中输入创建。
从父RDD转换得到新RDD。
从数据集合转换而来,通过编码实现。
2.RDD的存储
用户可以选择不同的存储级别缓存RDD以便重用(RDD有11种存储级别)。
当前RDD默认是存储于内存,但当内存不足时,RDD会溢出到磁盘中。
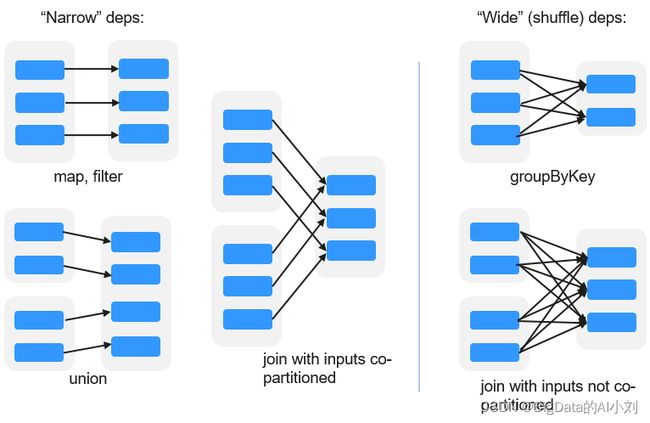
3.Dependency
窄依赖:指父RDD的每一个分区最多被一个子RDD的分区所用。
宽依赖:指子RDD的分区依赖于父RDD的所有分区。
4.Transformation和Action
对RDD的操作包含Transformation(返回值还是一个RDD)和Action(返回值不是一个RDD)两种.
Transformation操作是Lazy的,等Action的时候才会启动计算
4.1 Transformation操作可以分为如下几种类型:
4.1.1 视RDD的元素为简单元素。
输入输出一对一,且结果RDD的分区结构不变,主要是map。
输入输出一对多,且结果RDD的分区结构不变,如flatMap(map后由一个元素变为一个包含多个元素的序列,然后展平为一个个的元素)。
输入输出一对一,但结果RDD的分区结构发生了变化,如union(两个RDD合为一个,分区数变为两个RDD分区数之和)、coalesce(分区减少)。
从输入中选择部分元素的算子,如filter、distinct(去除重复元素)、subtract(本RDD有、其他RDD无的元素留下来)和sample(采样)。
4.1.2 视RDD的元素为Key-Value对:
对单个RDD做一对一运算,如mapValues(保持源RDD的分区方式,这与map不同);
以下三种涉及shuffer
对单个RDD重排,如sort、partitionBy(实现一致性的分区划分,这个对数据本地性优化很重要);
对单个RDD基于key进行重组和reduce,如groupByKey、reduceByKey;
对两个RDD基于key进行join和重组,如join、cogroup。
4.2 Action操作可以分为如下几种:
生成标量,如count(返回RDD中元素的个数)、reduce、fold/aggregate(返回几个标量)、take(返回前几个元素)。
生成Scala集合类型,如collect(把RDD中的所有元素倒入Scala集合类型)、lookup(查找对应key的所有值)。
写入存储,如与前文textFile对应的saveAsTextFile。
还有一个检查点算子checkpoint。当Lineage特别长时(这在图计算中时常发生),出错时重新执行整个序列要很长时间,可以主动调用checkpoint把当前数据写入稳定存储,作为检查点。
5.shuffle
Shuffle是MapReduce框架中的一个特定的phase,介于Map phase和Reduce phase之间,当Map的输出结果要被Reduce使用时,每一条输出结果需要按key哈希,并且分发到对应的Reducer上去,这个过程就是shuffle。由于shuffle涉及到了磁盘的读写和网络的传输,因此shuffle性能的高低直接影响到了整个程序的运行效率。
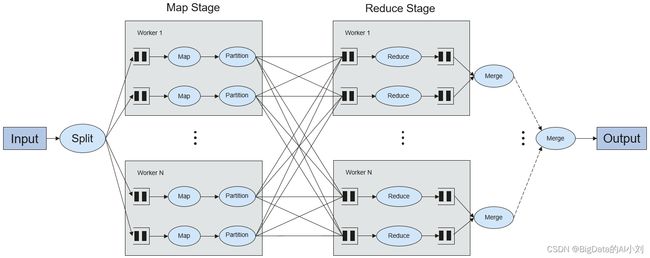
6.Spark Application的结构
Spark Application的结构可分为两部分:初始化SparkContext和主体程序。
初始化SparkContext:构建Spark Application的运行环境。
构建SparkContext对象,如:
new SparkContext(master, appName, [SparkHome], [jars])
参数介绍:
master:连接字符串,连接方式有local、yarn-cluster、yarn-client等。
appName:构建的Application名称。
SparkHome:集群中安装Spark的目录。
jars:应用程序代码和依赖包。
详细描述:https://spark.apache.org/docs/3.1.1/submitting-applications.html
二、Spark SQL常用概念
DataSet
DataSet是一个由特定域的对象组成的强类型集合,可通过功能或关系操作并行转换其中的对象。 每个Dataset还有一个非类型视图,即由多个列组成的DataSet,称为DataFrame。
DataFrame是一个由多个列组成的结构化的分布式数据集合,等同于关系数据库中的一张表,或者是R/Python中的data frame。DataFrame是Spark SQL中的最基本的概念,可以通过多种方式创建,例如结构化的数据集、Hive表、外部数据库或者是RDD。
1.Word Count
代码如下(示例):
def main(args:Array[String]):Unit={
//建立和框架的连接
val sparkConf=new SparkConf().setMaster("local").setAppName("WordCount")
val sc= new SparkContext(sparconf)
//读取文件,获取行数据
val lines:RDD[String]=sc.textFile("路径")
//分词
val words:RDD[String]=lines.flatMap(_.split(""))
//分组统计
val wordGroup:RDD[(String,Iterable[String])]words.groupBy(word=>word)
//对分组后的数据进行转换
val wordToCount=wordGroup.map{
case(word,list)=>{
(word,list.size)
}
}
//将结果采集打印
val array:Array[(String,Int)]=wordToCount,collrct()
array.foreach(println)
//关闭连接
sc.stop();
}