笔试整理一
一、数字指针:如果一个指针指向了数组,我们就称它为数组指针
- 数组指针指向的是数组中的一个具体元素,而不是整个数组,所以数组指针的类型和数组元素的类型有关
- 在求数组的长度时不能使用sizeof(p) / sizeof(int),因为 p 只是一个指向 int 类型的指针,编译器只知道它指向的是一个整数但不知道是一个整数(数组)
一个指向数组的指针,例如:
int arr[] = { 99, 15, 100, 888, 252 };
int *p = arr;
二、指针数组:如果一个数组中的所有元素保存的都是指针,那么我们就称它为指针数组
括号里面说明arrayName是一个数组,包含了length个元素,括号外面说明每个元素的类型为dataType *即一个存放dataType类型数据的地址。
int *a[10];
三、一个函数总是占用一段连续的内存区域,函数名在表达式中有时也会被转换为该函数所在内存区域的首地址,这和数组名非常类似。我们可以把函数的这个首地址(或称入口地址)赋予一个指针变量,使指针变量指向函数所在的内存区域,然后通过指针变量就可以找到并调用该函数。这种指针就是函数指针
returnType (*pointerName)(param list);
int (*a)(int)
四、函数指针数组是一个其元素是函数指针的数组,明确这每一个数组元素是指向函数入口地址的指针
int (*a[10]) (int)
五、总结
指针(Pointer)就是内存的地址,C语言允许用一个变量来存放指针,这种变量称为指针变量。指针变量可以存放基本类型数据的地址,也可以存放数组、函数及其他指针变量的地址。
程序在运行过程中需要的是数据和指令的地址,变量名、函数名、字符串名和数组名在本质上是一样的,它们都是地址的助记符:在编写代码的过程中,我们认为变量名表示的是数据本身,而函数名、字符串名和数组名表示的是代码块或数据块的首地址;程序被编译和链接后,这些名字都会消失,取而代之的是它们对应的地址。
1) 指针变量可以进行加减运算,例如p++、p+i、p-=i。指针变量的加减运算并不是简单的加上或减去一个整数,而是跟指针指向的数据类型有关。
2) 给指针变量赋值时,要将一份数据的地址赋给它,不能直接赋给一个整数,例如int *p = 1000;是没有意义的,使用过程中一般会导致程序崩溃。
3) 使用指针变量之前一定要初始化,否则就不能确定指针指向哪里,如果它指向的内存没有使用权限,程序就崩溃了。对于暂时没有指向的指针,建议赋值NULL。
4) 两个指针变量可以相减。如果两个指针变量指向同一个数组中的某个元素,那么相减的结果就是两个指针之间的元素个数。
5) 数组也是有类型的,数组名的本意是表示一组类型相同的数据。在定义数组时,或者和 sizeof、& 运算符一起使用时数组名才表示整个数组,表达式中的数组名会被转换为一个指向数组首地址的指针。
六、C语言字节对齐
1. 什么是对齐?
现代计算机中内存空间都是按照字节(byte)划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定变量的时候经常在特定的内存地址访问,这就需要各类型数据按照一定的规则在空间上排列,而不是顺序地一个接一个地排放,这就是对齐。
2.计算机为什么要对齐?
各个硬件平台对存储空间的处理上有很大的不同。一些平台对某些特定类型的数据只能从某些特定地址开始存取,其他平台可能没有这种情况。但是最常见的是,如果不按照适合其平台的要求对数据存放进行对齐,会在存取效率上带来损失。比如有些平台每次读都是从偶地址开始,一个int型(假设为 32位)如果存放在偶地址开始的地方,那么一个读周期就可以读出,而如果存放在奇地址开始的地方,就可能会需要2个读周期,并对两次读出的结果的高低字节进行拼凑才能得到该int数据,显然在读取效率上下降很多。这也是空间和时间的博弈。在网络程序中,掌握这个概念可是很重要的:如果在不同平台之间(比如在Windows 和Linux之间)传递2进制流(比如结构体),那么在这两个平台间必须要定义相同的对齐方式,不然莫名其妙地出了一些错,可是很难排查的。
3.对齐的实现:
通常,我们写程序的时候,不需要考虑对齐问题,编译器会替我们选择适合目标平台的对齐策略。当然,我们也可以通知给编译器传递预编译指令而改变对指定数据的对齐方法,比如写入预编译指令#pragma pack(2),即告诉编译器按两字节对齐。
但是,正因为我们一般不需要关心这个问题,所以,如果编辑器对数据存放做了对齐,而我们不了解的话,常常会对一些问题感到迷惑。最常见的就是struct数据结构的sizeof结果,比如以下程序:
#include
int main(void)
{
struct A
{
char a;
short b;
int c;
};
printf("结构体类型A在内存中所占内存为:%d字节。\n",sizeof(struct A));
return 0;
}
输出结果为:8字节。
如果我们将结构体中的变量声明位置稍加改动(并不改变变量本身),请再看以下程序:
#include
int main(void)
{
struct A
{
short b;
int c;
char a;
};
printf("结构体类型A在内存中所占内存为:%d字节。\n",sizeof(struct A));
return 0;
}
输出结果为:12字节。
问题出来了,他们都是同一个结构体,为什么占用的内存大小不同呢?为此,我们需要对对齐算法有所了解。
4.对齐算法:
由于各个平台和编译器的不同,现以32位,vc++6.0系统为例,来讨论编译器对struct数据结构中的各成员如何进行对齐的。
首先,我们给出四个概念:
1)数据类型自身的对齐值:就是基本数据类型的自身对齐值,比如char类型的自身对齐值为1字节,int类型的自身对齐值为4字节。
2)指定对齐值:预编译命令#pragma pack (value)指定的对齐值value。
3)结构体或者类的自身对齐值:其成员中自身对齐值最大的那个值,比如以上的struct A的对齐值为4。
4)数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中较小的那个值。
设结构体如下定义:
struct A
{
char a;
short b;
int c;
};
a是char型数据,占用1字节内存;short型数据,占用2字节内存;int型数据,占用4字节内存。因此,结构体A的自身对齐值为4。于是,a和b要组成4个字节,以便与c的4个字节对齐。而a只有1个字节,a与b之间便空了一个字节。我们知道,结构体类型数据是按顺序存储结构一个接一个向后排列的,于是其存储方式为:
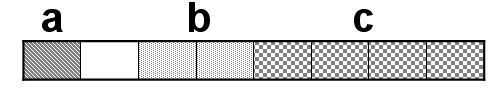
其中空白方格无数据,是浪费的内存空间,共占用8字节内存。
实际上,为了更加明显地表示“对齐”,我们可以将以上结构想象为以下的行排列:
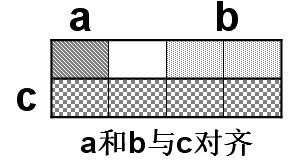
对于另一个结构体定义:
struct A
{
short b;
int c;
char a;
};
其内存存储方式为:

同样把它想象成行排列:
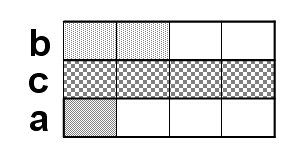
可见,浪费的空间更多。
其实,除了结构体之外,整个程序在给每个变量进行内存分配时都会遵循对齐机制,也都会产生内存空间的浪费。但我们要知道,这种浪费是值得的,因为它换来的是效率的提高。
以上分析都是建立在程序默认的对齐值基础之上的,我们可以通过添加预定义命令#pragma pack(value)来对对齐值进行自定义,比如#pragma pack(1),对齐值变为1,此时内存紧凑,不会出现内存浪费,但效率降低了。效率之所以降低,是因为:如果存在更大字节数的变量时(比1大),比如int类型,需要进行多次读周期才能将一个int数据拼凑起来。