机器学习第六课--朴素贝叶斯
朴素贝叶斯广泛地应用在文本分类任务中,其中最为经典的场景为垃圾文本分类(如垃圾邮件分类:给定一个邮件,把它自动分类为垃圾或者正常邮件)。这个任务本身是属于文本分析任务,因为对应的数据均为文本类型,所以对于此类任务我们首先需要把文本转换成向量的形式,然后再带入到模型当中。
import pandas as pd
import numpy as np
import matplotlib.mlab as mlab
import matplotlib.pyplot as plt
# 读取spam.csv文件
df = pd.read_csv("/home/anaconda/data/Z_NLP/spam.csv", encoding='latin')
df.head()
# 重命名数据中的v1和v2列,使得拥有更好的可读性
df.rename(columns={'v1':'Label', 'v2':'Text'}, inplace=True)
df.head()
# 把'ham'和'spam'标签重新命名为数字0和1
df['numLabel'] = df['Label'].map({'ham':0, 'spam':1})
df.head()
# 统计有多少个ham,有多少个spam
print ("# of ham : ", len(df[df.numLabel == 0]), " # of spam: ", len(df[df.numLabel == 1]))
print ("# of total samples: ", len(df))
# 统计文本的长度信息,并画出一个histogram
text_lengths = [len(df.loc[i,'Text']) for i in range(len(df))]
plt.hist(text_lengths, 100, facecolor='blue', alpha=0.5)
plt.xlim([0,200])
plt.show()
# 导入英文的停用词库
from sklearn.feature_extraction.text import CountVectorizer
# 构建文本的向量 (基于词频的表示)
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(df.Text)
y = df.numLabel
# 把数据分成训练数据和测试数据
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=100)
print ("训练数据中的样本个数: ", X_train.shape[0], "测试数据中的样本个数: ", X_test.shape[0])
# 利用朴素贝叶斯做训练
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score
clf = MultinomialNB(alpha=1.0, fit_prior=True)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("accuracy on test data: ", accuracy_score(y_test, y_pred))
# 打印混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_pred, labels=[0, 1])
例题:垃圾邮件的分类
总体来讲,朴素贝叶斯分为两个阶段:
- 计算每个单词在不同分类中所出现的概率,这个概率是基于语料库(训练数据)来获得的。
- 利用已经计算好的概率,再结合贝叶斯定理就可以算出对于一个新的文本,它属于某一个类别的概率值,并通过这个结果做最后的分类决策。
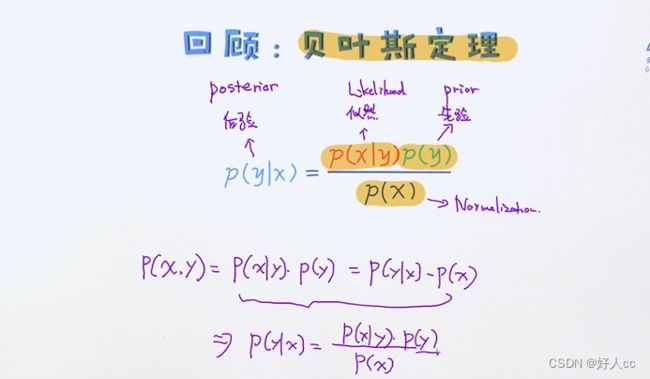
先验:
贝叶斯定理
平滑操作---防止也有概率是0,但是贝叶斯乘积永远是0(加1平滑)
另外,在上述过程中可以看到分子的计算过程涉及到了很多概率的乘积,一旦遇到这种情形,就要知道可能会有潜在的风险。比如其中一个概率值等于0,那不管其他概率值是多少,最后的结果一定为0,有点类似于“功亏一篑“的情况,明明出现了很多垃圾邮件相关的单词,就是因为其中的一个概率0,最后判定为属于垃圾邮件的概率为0,这显然是不合理的。为了处理这种情况,有一个关键性操作叫作平滑(smoothing),其中最为常见的平滑方法为加一平滑(add-one smoothing)。
例题:完整的例子:

分子加1,分母加词库的数量
朴素贝叶斯的最大似然估计:
生成模型和判别模型
生成模型是记住所有的特点,所以接下来可以生成新的图片
而判别模型只记得他们之间的区别,所以不能用来生成,只能用来区分
判别模型的初衷是用来解决判别问题,而且只做一件事情(不像生成模型即可以解决分类问题也可以解决生成数据的问题),所以在分类问题上它的效果通常要优于生成模型的。接下来试着从另外一个角度来理解它俩之间的区别。

