【三维重建】【深度学习】NeuS代码Pytorch实现--测试阶段代码解析(上)
【三维重建】【深度学习】NeuS代码Pytorch实现–测试阶段代码解析(上)
论文提出了一种新颖的神经表面重建方法,称为NeuS,用于从2D图像输入以高保真度重建对象和场景。在NeuS中建议将曲面表示为有符号距离函数(SDF)的零级集,并开发一种新的体绘制方法来训练神经SDF表示,因此即使没有掩模监督,也可以实现更准确的表面重建。NeuS在高质量的表面重建方面的性能优于现有技术,特别是对于具有复杂结构和自遮挡的对象和场景。本篇博文将根据代码执行流程解析测试阶段具体的功能模块代码。
文章目录
- 【三维重建】【深度学习】NeuS代码Pytorch实现--测试阶段代码解析(上)
- 前言
- save_checkpoint
- validate_image
- gen_rays_at
- validate_mesh
- extract_geometry
- extract_fields
- 总结
前言
在详细解析NeuS网络之前,首要任务是搭建NeuS【win10下参考教程】所需的运行环境,并完成模型的训练和测试,展开后续工作才有意义。
本博文将对NeuS测试阶段涉及的功能代码模块进行解析。
博主将各功能模块的代码在不同的博文中进行了详细的解析,点击【win10下参考教程】,博文的目录链接放在前言部分。
这里的代码段是exp_runner.py文件的train函数部分,它是在属于广义上的训练阶段的一部分,但是由于不参与NeuS网络的更新,只是对NeuS网络进行阶段性验证,因此博主放到该博文中进行详细讲解。
if self.iter_step % self.save_freq == 0:
self.save_checkpoint()
if self.iter_step % self.val_freq == 0:
self.validate_image()
if self.iter_step % self.val_mesh_freq == 0:
self.validate_mesh()
self.update_learning_rate()
if self.iter_step % len(image_perm) == 0:
image_perm = self.get_image_perm()
save_checkpoint
属于exp_runner.py文件的Runner类中的成员方法,目的是保存完成阶段训练的NeuS权重。
def save_checkpoint(self):
checkpoint = {
'nerf': self.nerf_outside.state_dict(), # 各深度学习网络参数权重
'sdf_network_fine': self.sdf_network.state_dict(),
'variance_network_fine': self.deviation_network.state_dict(),
'color_network_fine': self.color_network.state_dict(),
'optimizer': self.optimizer.state_dict(), # 优化器
'iter_step': self.iter_step, # 训练的次数
}
# 创建放置权重模型的文件夹
os.makedirs(os.path.join(self.base_exp_dir, 'checkpoints'), exist_ok=True)
# 保存
torch.save(checkpoint, os.path.join(self.base_exp_dir, 'checkpoints', 'ckpt_{:0>6d}.pth'.format(self.iter_step)))
validate_image
阶段性的完成NeuS模型训练后,需要渲染图片并与真实的训练图片进行比较从而验证模型训练的效果。
首先需要gen_rays_at函数生成整张图片(下采样后)的光线rays,然后获取rays光线上采样点(前景)的最远点和最近点,最后通过renderer函数获取所需的结果。
def validate_image(self, idx=-1, resolution_level=-1):
# 假设验证图像的序号小于0,随机获取一个图片序号
if idx < 0:
idx = np.random.randint(self.dataset.n_images)
print('Validate: iter: {}, camera: {}'.format(self.iter_step, idx))
if resolution_level < 0:
# 下采样倍数
resolution_level = self.validate_resolution_level
# [W, H, 3]
rays_o, rays_d = self.dataset.gen_rays_at(idx, resolution_level=resolution_level)
H, W, _ = rays_o.shape
# 按照batch_size切分,[W*H,3]=>tuple形式:W*H/batch_size个[batch_size, 3]
rays_o = rays_o.reshape(-1, 3).split(self.batch_size)
rays_d = rays_d.reshape(-1, 3).split(self.batch_size)
out_rgb_fine = []
out_normal_fine = []
for rays_o_batch, rays_d_batch in zip(rays_o, rays_d):
# 最近点和最远点
near, far = self.dataset.near_far_from_sphere(rays_o_batch, rays_d_batch)
# 背景颜色
background_rgb = torch.ones([1, 3]) if self.use_white_bkgd else None
render_out = self.renderer.render(rays_o_batch,
rays_d_batch,
near,
far,
cos_anneal_ratio=self.get_cos_anneal_ratio(),
background_rgb=background_rgb)
def feasible(key): return (key in render_out) and (render_out[key] is not None)
# 前景颜色
if feasible('color_fine'):
out_rgb_fine.append(render_out['color_fine'].detach().cpu().numpy())
# 梯度信息和采样点权重
if feasible('gradients') and feasible('weights'):
n_samples = self.renderer.n_samples + self.renderer.n_importance
# 梯度信息权重加成
normals = render_out['gradients'] * render_out['weights'][:, :n_samples, None] # [batch_size,n_samples,3]
# 采样点是否在球体内
if feasible('inside_sphere'):
# 只保留采样点在球体内的部分
normals = normals * render_out['inside_sphere'][..., None] # [batch_size,n_samples,3]
# normals是带有权重的有效梯度信息
normals = normals.sum(dim=1).detach().cpu().numpy() # [batch_size,3]
out_normal_fine.append(normals)
del render_out
gen_rays_at
Dataset数据管理器的定义的函数,在models/dataset.py文件下。博主【NeuS总览】的博文中,已经简单介绍过这个过程。
def gen_rays_at(self, img_idx, resolution_level=1):
"""
Generate rays at world space from one camera.
一个摄影机在世界空间中生成光线
"""
# 下采样倍数
l = resolution_level
# 获取2D图像上所有的像素点(下采样后的)
tx = torch.linspace(0, self.W - 1, self.W // l)
ty = torch.linspace(0, self.H - 1, self.H // l)
# 生成网格用于生成坐标
pixels_x, pixels_y = torch.meshgrid(tx, ty) # [W, H]
# 相机坐标系下的方向向量:内参(逆)×像素坐标系
p = torch.stack([pixels_x, pixels_y, torch.ones_like(pixels_y)], dim=-1) # [W, H, 3]
p = torch.matmul(self.intrinsics_all_inv[img_idx, None, None, :3, :3], p[:, :, :, None]).squeeze() # [W, H, 3]
# 单位方向向量:对方向向量做归一化处理
rays_v = p / torch.linalg.norm(p, ord=2, dim=-1, keepdim=True) # [W, H, 3]
# 世界坐标系下的方向向量:外参(逆)×相机坐标系
rays_v = torch.matmul(self.pose_all[img_idx, None, None, :3, :3], rays_v[:, :, :, None]).squeeze() # [W, H, 3]
# 世界坐标系下的光心位置(外参的逆对应的平移矩阵t)
rays_o = self.pose_all[img_idx, None, None, :3, 3].expand(rays_v.shape) # [W, H, 3]
return rays_o.transpose(0, 1), rays_v.transpose(0, 1) # [H, W, 3]
代码的执行示意图如下图所示,函数返回了rays_o(光心)和rays_v(单位方向向量)。
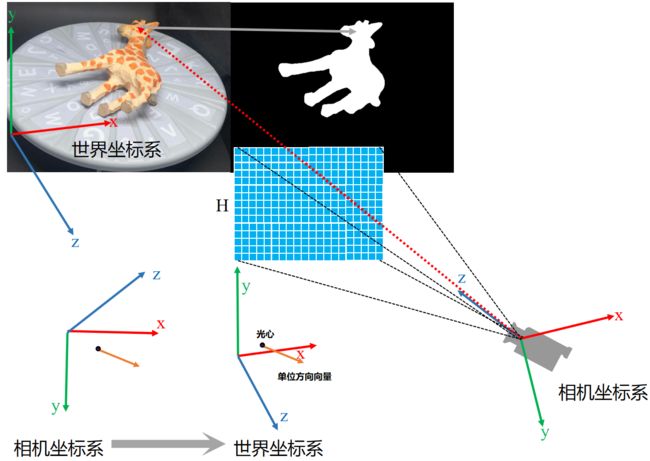
注意区分训练过程和验证过程生成光线rays的不同,训练过程中是随机选取batch_size个像素点从而生成穿过这些像素点的光线rays,而验证过程是需要选取整个图片的所有像素点从而生成穿过整个图片像素点的光线rays。
validate_mesh
阶段性的完成NeuS模型训练后,同样需要三维重建出实物模型从而验证模型训练的效果。
首先需要划定重建的空间范围,然后通过绘制算法获取顶点坐标和面索引,最后输出实际的三维模型文件。
def validate_mesh(self, world_space=False, resolution=64, threshold=0.0):
# 获取提取域(方体)的对角线顶点
bound_min = torch.tensor(self.dataset.object_bbox_min, dtype=torch.float32)
bound_max = torch.tensor(self.dataset.object_bbox_max, dtype=torch.float32)
# 面绘制算法获取vertices顶点坐标和triangles面索引
vertices, triangles =\
self.renderer.extract_geometry(bound_min, bound_max, resolution=resolution, threshold=threshold)
os.makedirs(os.path.join(self.base_exp_dir, 'meshes'), exist_ok=True)
if world_space:
# 再次缩放位移
vertices = vertices * self.dataset.scale_mats_np[0][0, 0] + self.dataset.scale_mats_np[0][:3, 3][None]
# 表示和操作三角网格模型
mesh = trimesh.Trimesh(vertices, triangles)
# 保存mesh模型
mesh.export(os.path.join(self.base_exp_dir, 'meshes', '{:0>8d}.ply'.format(self.iter_step)))
logging.info('End')
下图展示的是bound_min 和bound_max划定了三维重建范围。
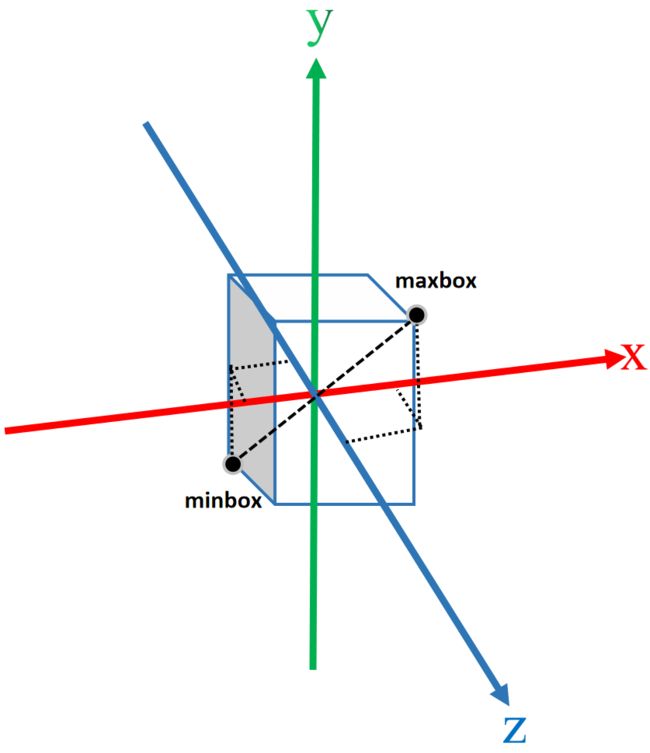
这里提醒一下,三维重建的范围和渲染成二维图片的范围是不一样的,都是各自有各自的设定,别搞混了。
extract_geometry
都在models/renderer.py文件下,这里源码作者做了个套娃,前一个extract_geometry是属于NeuSRenderer类的类成员方法,后一个是独立的函数。
def extract_geometry(self, bound_min, bound_max, resolution, threshold=0.0):
return extract_geometry(bound_min,
bound_max,
resolution=resolution,
threshold=threshold,
query_func=lambda pts: -self.sdf_network.sdf(pts))
marching_cubes面绘制算法参考,extract_fields是为了获得三维重建范围每个点的sdf值。
def extract_geometry(bound_min, bound_max, resolution, threshold, query_func):
print('threshold: {}'.format(threshold))
# 获取提取域多的sdf
u = extract_fields(bound_min, bound_max, resolution, query_func)
# 面绘制算法
# vertices 顶点坐标[N,3] N是根据具有情况而通过算法得出,与其他无关
# triangles 面索引[M,3] 索引指向顶点坐标数组中的对应顶点,3个顶点一个面
vertices, triangles = mcubes.marching_cubes(u, threshold)
# 提取域的对角顶点
b_max_np = bound_max.detach().cpu().numpy() # [3]
b_min_np = bound_min.detach().cpu().numpy() # [3]
# 缩小位移
vertices = vertices / (resolution - 1.0) * (b_max_np - b_min_np)[None, :] + b_min_np[None, :]
return vertices, triangles
extract_fields
该函数的作用是在三维重建范围内获取到合适的提取点(体素),并为每个提取点(体素)的计算出对应的sdf值。
def extract_fields(bound_min, bound_max, resolution, query_func):
N = 64
# 根据提取域(方体)的对角顶点,获取提取域在各xyz轴的范围(max-min)和单位刻度((max-min)/resolution)
X = torch.linspace(bound_min[0], bound_max[0], resolution).split(N)
Y = torch.linspace(bound_min[1], bound_max[1], resolution).split(N)
Z = torch.linspace(bound_min[2], bound_max[2], resolution).split(N)
# 初始化对应方体的sdf值
u = np.zeros([resolution, resolution, resolution], dtype=np.float32)
with torch.no_grad():
for xi, xs in enumerate(X):
for yi, ys in enumerate(Y):
for zi, zs in enumerate(Z):
# 网格化
xx, yy, zz = torch.meshgrid(xs, ys, zs) # [N,N,N]
# [N^3,3]
pts = torch.cat([xx.reshape(-1, 1), yy.reshape(-1, 1), zz.reshape(-1, 1)], dim=-1)
# 找到对应点的sdf
val = query_func(pts).reshape(len(xs), len(ys), len(zs)).detach().cpu().numpy()
# 为方体正确的赋sdf值
u[xi * N: xi * N + len(xs), yi * N: yi * N + len(ys), zi * N: zi * N + len(zs)] = val
return u
代码的执行示意图如下图所示,橙色方块就是提取点(体素),可以根据划分要求更细致的划分出更小的提取点(体素)。

总结
尽可能简单、详细的介绍NeuS测试阶段部分代码:validate_image渲染图片和validate_mesh重建模型的过程。后续会讲解测试阶段的剩余代码。