GICv3学习
GICv3学习
参考文档:
-
《corelink_gic600_generic_interrupt_controller_technical_reference_manual_100336_0106_00_en》
-
《IHI0069H_gic_architecture_specification》
-
《ECM0495013B_GIC_Stream_Protocol》
一、GICv3寄存器接口
接口如下图所示:

通常,Distributor和Redistributor用于配置中断,CPU interface用于处理中断
1. Distributor interface
Distributor的寄存器是内存映射的(memory-mapped),用于配置spi:
| 功能 |
|---|
| 中断优先级和SPI的分发 |
| 启用和禁用SPI(GICD_CTLR、GICD_ISENABLER) |
| 设置每个SPI的优先级 |
每个SPI的路由信息(SGI和PPI是每个核独立的)  |
| SPI中断触发方式设置:水平触发或边缘触发 |
| 生成消息信号SPI |
| 控制SPI的active和pending state(active、inactive、pending、active and pending) |
| interrupt group的设定。设置每个中断的 Group,其中 Group0 用于安全中断,支持 FIQ 和 IRQ,Group1 用于非安全中断,只支持 IRQ |
2. Redistributor interface
每个core都连接一个redistributor
| 功能 |
|---|
| 启用和禁用SGI和PPI(Banked per PE) |
| 设置SGI和PPI的优先级 |
| 将每个PPI设置为水平触发或边缘触发(SGI都是边缘触发) |
| 将每个SGI和PPI分配给一个中断组 |
| 控制SGI和PPI的状态(active、inactive、pending、active and pending) |
| 控制内存中支持相关中断属性和LPI挂起状态的数据结构的基址 |
| 为连接的PE提供电源管理支持 |
3. CPU interface
每个core包含一个CPU interface,这是在中断处理期间使用的系统寄存器:
| 功能 |
|---|
| 提供通用控制和配置以启用中断处理 |
| 将中断请求发送给cpu |
| 中断认可(Acknowledge an interrupt) |
| 执行优先级降权(priority drop)和中断无效(deactivation) |
| 配置PE的中断优先级掩码 |
| 定义PE的中断抢占策略 |
| 确定PE的最高优先级挂起中断(Determine the highest priority pending interrupt for the PE) |
二、中断状态机
对于每一个中断而言,有以下4个状态:
-
inactive:中断处于无效状态,既没有新的信号产生,也没有在处理中的信号
-
pending:中断处于有效状态,但是cpu没有响应该中断
-
active:cpu在响应该中断,但是还没有处理完成
-
active and pending:cpu在响应该中断,但是该中断源又发送中断过来(只有边缘触发型的中断才有这个状态)
PS:LPI中断没有active和active and pending两个状态

Transition A1 or A2:这种转换发生在中断变为挂起的时候,可能是由于外设产生了中断,也可能是由于软件产生了中断
- 对于SGI,有2种方法:写GICD_SGIR寄存器(产生1个中断),或者写GICD_SPENDSGIR寄存器(将状态设置成pending)
- 对于SPI 和PPI,也是2种方法:硬件产生,或者写GICD_ISPENDR寄存器
Transition B1 or B2:中断被外设无效(deasserted),中断是level-sensitive(水平触发),或者当软件改变了挂起状态时,就会发生这种转换
- 对于SGI,设置GICD_CPENDSGIR寄存器
- 对于SPI 和 PPI:对于电平触发的中断,电平改变后,Pending状态会移除;对于边沿触发以及写GICD_ISPENDR产生的中断,需要写GICD_ICPENDR寄存器来移除Pendding状态
Transition C:这种转换发生在PE对边缘触发的spi、sgi和ppi的中断确认时;对于spi、sgi和ppi,当软件从 ICC_IAR0_EL1 或 ICC_IAR1_EL1 读取INTID值时,就会发生这种转换
Transition D:这种转换发生在PE对水平触发的spi、sgi和ppi的中断确认时
Transition E1 or E2:当软件停用spi、sgi和ppi的中断时,就会发生这种转换
状态变迁:
- 中断信号被触发时,Inactive —> Pending
- 中断服务程序响应该信号时(中断服务程序读取 ICC_IAR0_EL1 或者 GICC_IAR 寄存器) Pending —> Active
- 中断服务程序完成处理 (中断服务程序写入ICC_EOIR0_EL1 或者 GICC_EOIR寄存器) Active —> Inactive
- 当处于Active状态时,gic会解除对该中断源的屏蔽,也就是说,如果之后该中断源上有第二个中断到来,那么cpu是可以接收到的。从新来的中断的角度,该中断源应该处于Pending状态,而从上一个还没处理完的中断的角度,该中断源又应该处于Active状态,所以这个特殊时期的状态被叫做Active and Pending
三、中断认可(Acknowledge an interrupt)
中断认可,是指cpu响应该中断。此时中断状态从pending状态,变为active状态。通过访问ICC_IAR0_EL1或者GICC_IAR寄存器,来对中断进行认可。
-
ICC_IAR0_EL1、GICC_IAR:认可group0的中断
-
ICC_IAR1_EL1、GICC_AIAR:认可group1的中断
cpu interface会将该中断的优先级作为运行中的优先级,任何低于该优先级的中断都无法抢占该中断的处理过程。可以通过ICC_RPR_EL1查看该优先级
四、中断完成
中断完成,是指cpu处理完中断。此时中断状态从active状态,变为inactive状态。gic中,对中断完成,定义了以下两个stage:
- 优先级降权(priority drop):将当前中断屏蔽的最高优先级进行重置,以便能够响应低优先级中断。group0中断,通过写 ICC_EOIR0_EL1 或者 GICC_EOIR寄存器,来实现优先级降权;group1中断,通过写 ICC_EOIR1_EL1 或者 GICC_AEOIR 寄存器,来实现优先级降权。
- 中断无效(interrupt deactivation):将中断的状态,设置为INACTIVE状态。处于ACTIVE状态的中断无法再次进入PENDING(边缘触发除外),需要通过DEACTIVATION将ACTIVE变成INACTIVE。通过写 ICC_DIR_EL1或者 GICC_DIR 寄存器,来实现中断无效。
这里为什么要分两个阶段呢,其实是有考虑的:对于中断来说,我们是希望中断处理程序越短越好,但是有些中断处理程序,就是比较长,在这种情况下,就会使其他中断得到响应的时间变长,从而影响实时性。
比如当前cpu在响应优先级为4的中断A,但是这个中断A的中断处理程序比较长,此时如果有优先级为5的中断B到来,那么cpu是不会响应这个中断的。
在linux中,会将中断处理程序分为两部分,分为上半部分和下半部分。
在上半部分,完成中断最紧急的任务,然后就可以通知GIC,降低当前的中断处理优先级,以便其他中断能够得到响应。
在下半部分,处理该中断的其他事情。
在这种机制下,低优先级的中断,不用等待高优先级的中断完全执行完中断处理程序后,就可以被cpu所响应,提高实时性。(低优先级已经处在pending状态,就可以立马转为active)
为了实现上述机制,就将中断完成分成了2步。
还是刚刚的例子,cpu在响应优先级为4的中断A,当中断A的上半部分完成后,通知GIC,优先级降权(priority drop),GIC将当前的最高优先级中断重置,重置到响应中断A之前的优先级,比如优先级6,那么此时优先级为5的中断B,就可以被cpu响应。
最后中断A的下半部分完成后,通知GIC,将该中断A的状态,设置为inactive状态,此时中断A就真正的完成了。 当然,也可以不将中断完成分成2步,就1步。通过控制 ICC_CTLR_EL1或者GICC_CTLR寄存器的EOImode位,来决定是否将中断完成分成2步。
END OF INTERRUPT 有两种方式,由GIC DISTRIBUTOR的CTLR存器EOIMODE位决定:
- EOIMODE == 0,写入ICC_EOIRN_EL1完成优先级降权(priority drop)和中断无效(interrupt deactivation)
- EOIMODE == 1,写入ICC_EOIRN_EL1 只会完成优先级降权(priority drop),写入ICC_DIR_EL1 才会完成中断无效(interrupt deactivation)
五、中断处理流程
中断处理流程,包含了以下几步:
- GIC决定每个中断的使能状态,不使能的中断,是不能发送中断的
- 如果某个中断的中断源有效,GIC将该中断的状态设置为pending状态,然后判断该中断的目标core
- 对于每一个core,GIC将当前处于pending状态的优先级最高的中断,发送给该core的cpu interface
- cpu interface接收GIC发送的中断请求,判断优先级是否满足要求,如果满足,就将中断通过nFIQ或nIRQ管脚,发送给core。
- core响应该中断,通过读取 ICC_IAR0_EL1 或者 GICC_IAR 寄存器,来认可该中断。读取该寄存器,如果是软中断,返回源处理器ID,否则返回中断号。
- 当core认可该中断后,GIC将该中断的状态,修改为active状态(Pending —> Active)
- 当core完成该中断后,通过写 EOIR (end of interrupt register)来实现优先级降权,写 ICC_DIR_EL1 或者 GICC_DIR 寄存器(这里描述的是EOIMODE == 0的情况),来无效该中断(Active —> Inactive)
六、中断周期
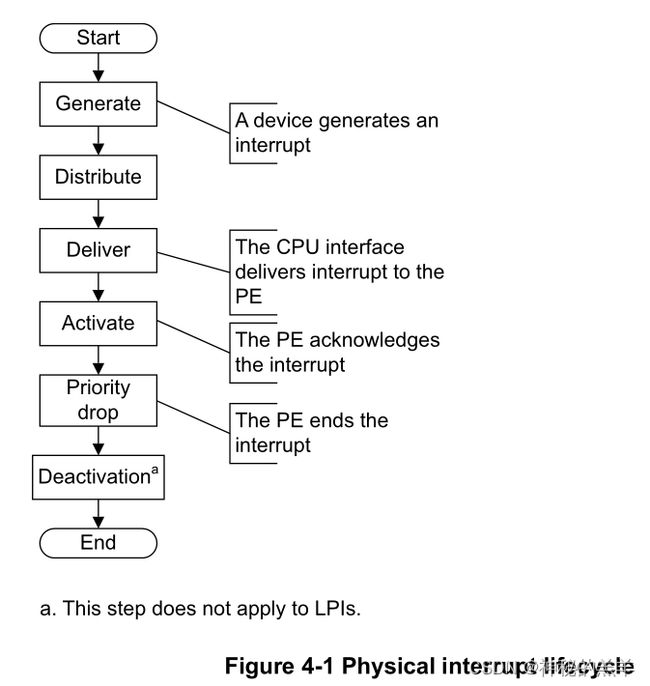
- generate:外设或者软件发起一个中断
- distribute:distributor对收到的中断源进行仲裁,然后发送给对应的cpu interface
- deliver:cpu interface将中断发送给core
- activate:core通过读取 ICC_IAR0_EL1 或者 GICC_IAR 寄存器,来对中断进行认可
- priority drop: core通过写 ICC_EOIR0_EL1 或者 GICC_EOIR 寄存器,来实现优先级降权
- deactivation:core通过写 ICC_DIR_EL1 或者 GICC_DIR 寄存器,来无效该中断
七、寄存器
gicv3中,多了很多寄存器。而且对寄存器,提供了2种访问方式,一种是memory-mapped的访问,一种是系统寄存器访问
| memory-mapped访问的寄存器 |
|---|
| GICC:cpu interface寄存器 |
| GICD:distributor寄存器 |
| GICH:virtual interface控制寄存器,在hypervisor模式访问 |
| GICR:redistributor寄存器 |
| GICV:virtual cpu interface寄存器 |
| GITS:ITS寄存器 |
| 系统寄存器访问的寄存器 |
|---|
| ICC:物理 cpu interface 系统寄存器 |
| ICV:虚拟 cpu interface 系统寄存器 |
| ICH:虚拟 cpu interface 控制系统寄存器 |
对于系统寄存器访问方式的gic寄存器,是实现在core内部的。而memory-mapped访问方式的gic寄存器,是在gic内部的。
gicv3架构中,没有强制,系统寄存器访问方式的寄存器,是不能通过memory-mapped方式访问的。也就是ICC, ICV, ICH寄存器,也是可以实现在gic内部,通过memory-mapped方式去访问。但是一般的实现中,是没有这样的实现的。
下图是gicv3中,各个寄存器所在的位置:

下图是系统寄存器和memory-mepped方式寄存器的对应关系:

思考:
- GICv3中,为什么选择将cpu interface,从gic中抽离,实现在core内部?
- 为什么要将cpu interface的寄存器,增加系统寄存器的访问方式,实现在core的内部?
答:上述两个问题,总接起来的原因是这两点:为了软件编写能够简单,通用;为了让中断响应能够更快。
cpu interface的寄存器,是会频繁被core所访问的,因为core需要访问cpu interface的寄存器,来认可中断,来中断完成,来无效中断。而其他的寄存器,是配置中断的,只有在core需要去配置中断的时候,才会去访问。
在gicv2中,cpu interface的寄存器,是实现在gic内部的,因此当core收到一个中断时,会通过axi总线(假设memory总线是axi总线),去访问cpu interface的寄存器。而中断在一个soc系统中,是会频繁的产生的,这就意味着,core会频繁地去访问gic的寄存器,这样会占用axi总线的带宽,从而影响中断的实时响应。而且core通过axi总线去访问cpu interface寄存器,延迟也比较大。
在gicv3中,将cpu interface从gic中抽离出来,实现在core内部,而不实现在gic中。core对cpu interface的访问,通过系统寄存器方式访问,也就是使用msr,mrs访问,那么core对cpu interface的寄存器访问就加速了,而且还不占用axi总线带宽。这样core对中断的处理就加速了。
cpu interface与gic之间,是通过专用的AXI4-Stream总线来传输信息的,这样也不会占用AXI总线的带宽。
八、GIC流协议(GIC Stream Protocol)
GIC Stream Protocol接口基于单向的AXI4-Stream接口。因此,为了支持双向通信,GIC流协议接口在每个方向上都包含一个AXI4-Stream协议接口。
它用于gic的IRI组件(interrupt routing infrastructure)和cpu interface之间传输信息。 distributor,redistributor和ITS,统称为IRI组件。 gic stream协议,包含以下2个接口:
- 下行AXI-stream接口:用于IRI向cpu interface传递信息,连接
- 上行AXI-stream接口:用于cpu interface向IRI传递信息

IRI组件与cpu interface通过gic stream协议传输信息,传输的信息是以包(packet)为单位,分为两类:
- 命令包,分为redistributor命令包,cpu interface命令包
- 响应包,分为redistributor响应包,cpu interface响应包
AXI-stream协议,每次传输2个字节,多次传输,组成一个包。不同的包,大小是不一样的,比如有的是16个字节,有的是8个字节。包传输的第一个16bit数据,表示包的类型。 如果一个组件,发送命令包,那么另一个,需要回应响应包。
1. redistributor命令包

2. redistributor响应包

3. cpu interface命令包
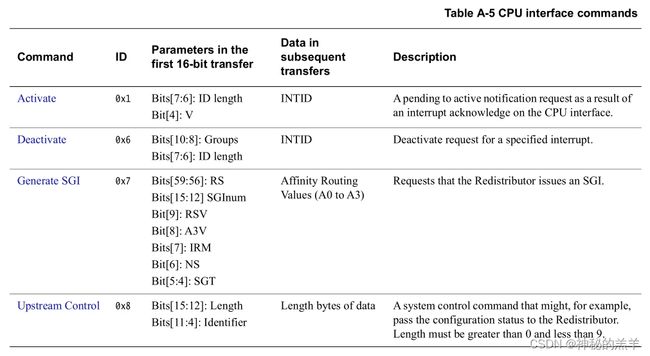
4. cpu interface响应包

5. 包(packet)传输流程
①中断发送

- redistributor使用Set命令向其连接的cpu interface发送一个挂起的中断(pending interrupt)。该命令包括中断的INTID、优先级和中断组。Set命令有些特殊,因为它没有专用的确认命令。相反,当cpu interface发出Release或Activate命令时,Set被认为是已确认的。
- 当cpu interface接收到Set命令时,它会检查该中断是否有足够的优先级可以下发到PE。如果是,cpu interface通过IRQ/FIQ给PE发送中断从而导致PE异常,通常会导致对应的中断服务函数运行。
- PE响应cpu interface发送的中断,于是去读取ICC_IAR寄存器来确认中断,得到中断号。之后cpu interface给redistributor发送activate响应。然后把IRQ/FIQ给取消掉。
- 当中断被处理后,软件通过写入中断结束寄存器(EOIR)或停止中断寄存器(DIR)中的一个来停止中断。这将导致cpu interface向redistributor发送一个Deactivate命令。
②中断取消

- redistributor给cpu interface发送set命令,cpu interface接收到该命令后,通过IRQ/FIQ给cpu发送中断。
- redistributor给cpu interface发送clear命令,清除该中断,cpu interface将IRQ/FIQ拉低。然后发送release命令响应。
- cpu interface给redistributor发送clear acknowledge响应。
- 如果此时,cpu读取IAR寄存器,PE会获取到一个假的中断号(1023)。
③中断抢占
redistributor给cpu interface发送2个中断,第二个中断抢占第一个中断。包的流程如下:

- redistributor首先发送Set X命令,发送中断X。cpu interface接收该命令,将IRQ/FIQ拉高,向PE发送中断请求。
- 在cpu读取ICC_IAR寄存器之前,redistributor又给cpu interface发送了Set Y命令,发送中断Y。并且Y的优先级比X高。
- cpu interface给redistributor发送Release X响应,表示cpu interface暂时不处理中断X,中断X将在后续重新发送。
- PE读取ICC_IAR寄存器,认可中断Y。cpu interface给redistributor发送Activate Y响应,然后把IRQ/FIQ给取消掉。
九、SGI中断
SGI通常用于核间通信,通过写入cpu interface中的以下SGI寄存器之一来生成:(只支持边缘触发)

-
软件写ICC_SGI0R_EL1产生secure状态的group0软中断
-
软件写ICC_SGI1R_EL1产生对应当前secure状态的group1软中断
-
软件写ICC_ASGI1R_EL1产生secure状态的group1软中断
注意点:

十、虚拟中断
GICv3对虚拟化的支持增加了以下功能:
-
cpu interface 寄存器的硬件虚拟化
-
生成虚拟中断并发出信号的能力
-
维护中断,将虚拟机中的特定事件通知hypervisor
cpu interface 寄存器分为三组:
- ICC: Physical CPU interface registers
- ICH: Virtualization control registers
- ICV: Virtual CPU interface registers

可以看到,原来的cpu interface再次细分,分成了物理cpu interface以及虚拟cpu interface,两者的功能是类似的。
细节:开启虚拟化时,当OS运行在虚拟机内部时ICC会自动映射成ICV。
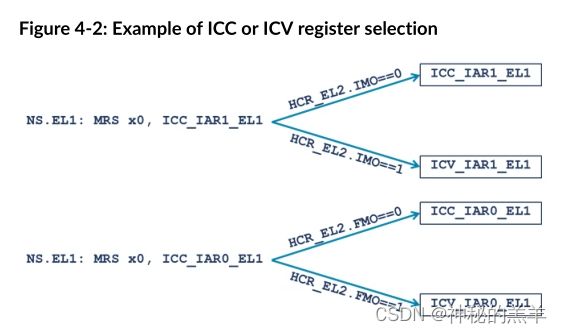
为什么要这么处理呢?个人认为是为了方便虚拟化的实施,这样就可以不需要修改原来的GIC驱动代码,也不需要在代码里准备两套驱动逻辑。
物理中断如何被发送到vPE?

- 物理中断从Redistributor转发到物理cpu interface
- 物理cpu interface检查物理中断是否可以转发到PE。若可以,就会asserted一个物理异常
- 中断被传送到EL2。hypervisor读取IAR,返回pINTID,pINTID现在处于Active状态。hypervisor决定将中断转发到当前运行的vPE,与此同时,hypervisor将pINTID写入ICC_EOIR1_EL1{ 当 ICC_CTLR_EL1.EOImode==1时,这只执行优先级降权(priority drop),而不停用(deactivating)物理中断。}
- hypervisor找到一个空闲的List寄存器进行写入,从而表示一个虚拟中断被挂起(pending)。List寄存器项指明了要发送的vINTID和原始pINTID的关系。hypervisor然后执行异常返回,将执行返回给vPE
- 虚拟cpu interface检查虚拟中断是否可以转发到vPE。除了使用ICV寄存器之外,这些检查与物理中断相同。若可以,就会asserted一个虚拟异常
- 虚拟异常被带到EL1。当软件读取IAR时,返回vINTID,虚拟中断现在处于Active状态
- Guest OS处理中断。当它处理完中断后,它会写入EOIR来执行优先级降权和停用。由于List寄存器记录了pINTID,这将同时禁用vINTID和pINTID。
虚拟中断的包传输流程和物理中断的类似,只是使用的命令变成了虚拟中断专用的。例如,下面的是中断发送的流程,使用的是VSet命令而不是Set命令:
st寄存器项指明了要发送的vINTID和原始pINTID的关系。hypervisor然后执行异常返回,将执行返回给vPE
5. 虚拟cpu interface检查虚拟中断是否可以转发到vPE。除了使用ICV寄存器之外,这些检查与物理中断相同。若可以,就会asserted一个虚拟异常
6. 虚拟异常被带到EL1。当软件读取IAR时,返回vINTID,虚拟中断现在处于Active状态
7. Guest OS处理中断。当它处理完中断后,它会写入EOIR来执行优先级降权和停用。由于List寄存器记录了pINTID,这将同时禁用vINTID和pINTID。
虚拟中断的包传输流程和物理中断的类似,只是使用的命令变成了虚拟中断专用的。例如,下面的是中断发送的流程,使用的是VSet命令而不是Set命令:
