pytorch实现transformer
过了两个月,代码能力不见提升。在此立誓,2月里剩下的日子每天都要敲代码。本文是Transformer的PyTorch实现(超详细)一文的学习转载。作者关于Transformer的讲解:Transformer详解。作者真的好强,评论里关于提升代码能力的建议:“多写少看”,也让我醍醐灌顶。
数据预处理
手动输入了两对德语→英语的句子,手动编码了每个字的索引。
import torch
sentences = [
# enc_input dec_input dec_output
['ich mochte ein bier P', 'S i want a beer .', 'i want a beer . E'],
['ich mochte ein cola P', 'S i want a coke .', 'i want a coke . E']
]
# Padding Should be Zero
src_vocab = {'P' : 0, 'ich' : 1, 'mochte' : 2, 'ein' : 3, 'bier' : 4, 'cola' : 5}
src_vocab_size = len(src_vocab)
tgt_vocab = {'P' : 0, 'i' : 1, 'want' : 2, 'a' : 3, 'beer' : 4, 'coke' : 5, 'S' : 6, 'E' : 7, '.' : 8}
idx2word = {i: w for i, w in enumerate(tgt_vocab)}
# print(idx2word)
tgt_vocab_size = len(tgt_vocab)
src_len = 5 # enc_input max sequence length
tgt_len = 6 # dec_input(=dec_output) max sequence length
def make_data(sentences):
enc_inputs, dec_inputs, dec_outputs = [], [], []
for i in range(len(sentences)):
enc_input = [[src_vocab[n] for n in sentences[i][0].split()]]
# [[1, 2, 3, 4, 0], [1, 2, 3, 5, 0]]
dec_input = [[tgt_vocab[n] for n in sentences[i][1].split()]]
# [[6, 1, 2, 3, 4, 8], [6, 1, 2, 3, 5, 8]]
dec_output = [[tgt_vocab[n] for n in sentences[i][2].split()]]
# [[1, 2, 3, 4, 8, 7], [1, 2, 3, 5, 8, 7]]
enc_inputs.extend(enc_input)
dec_inputs.extend(dec_input)
dec_outputs.extend(dec_output)
return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)
enc_inputs, dec_inputs, dec_outputs = make_data(sentences)
from torch.utils import data
#定义MyDataset类继承Dataset,需要重写方法:__init__,__len__,__getitem__
class MyDataSet(data.Dataset):
def __init__(self, enc_inputs, dec_inputs, dec_outputs):
super(MyDataSet, self).__init__()
self.enc_inputs = enc_inputs
self.dec_inputs = dec_inputs
self.dec_outputs = dec_outputs
def __len__(self):
return self.enc_inputs.shape[0]
def __getitem__(self, idx):
return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx]
#封装到Dataloader中,利用迭代器每次训练时提供一个batch的数据
loader = data.DataLoader(MyDataSet(enc_inputs, dec_inputs, dec_outputs), batch_size=2, shuffle=True)
#打印
def show_batch():
for step, batch in enumerate(loader):
print("steop:{}, batch:{}".format(step, batch))
# show_batch()
# steop:0, batch:[tensor([[1, 2, 3, 5, 0],
# [1, 2, 3, 4, 0]]), tensor([[6, 1, 2, 3, 5, 8],
# [6, 1, 2, 3, 4, 8]]), tensor([[1, 2, 3, 5, 8, 7],
# [1, 2, 3, 4, 8, 7]])]
#batch_size设置为2,数据被分为1组模型参数
下面变量代表的含义依次是:
字嵌入&位置嵌入的维度,这俩值是相同的,因此用一个变量就行了
FeedForward层隐藏神经元个数
Q、K、V向量的维度,其中Q与K的维度必须相等,V的维度没有限制,不过为了方便起见,我都设为64
Encoder和Decoder的个数
多头注意力中head的数量
# Transformer Parameters
d_model = 512 # Embedding Size:字嵌入&位置嵌入的维度
d_ff = 2048 # FeedForward dimension,FeedForward层隐藏神经元的个数
d_k = d_v = 64 # dimension of K(=Q), V
n_layers = 6 # number of Encoder of Decoder Layer
n_heads = 8 # number of heads in Multi-Head Attention上面都比较简单,下面开始涉及到模型就比较复杂了,因此我会将模型拆分成以下几个部分进行讲解:
Positional Encoding
Pad Mask(针对句子不够长,加了pad,因此需要对pad进行mask)
Subsequence Mask(Decoder input不能看到未来时刻单词信息,因此需要mask)
ScaledDotProductAttention(计算context vector)
Multi-Head Attention
FeedForward Layer
Encoder Layer
Encoder
Decoder Layer
Decoder
Transformer
关于代码中的注释,如果值为src_len或者tgt_len的,我一定会写清楚,但是有些函数或者类,Encoder和Decoder都有可能调用,因此就不能确定究竟是src_len还是tgt_len,对于不确定的,我会记作seq_len,
Positional Encoding
论文中使用了 sin 和 cos 函数的线性变换来提供给模型位置信息:

上式中 pos 指的是一句话中某个字的位置,取值范围是 [0,max_sequence_length),i 指的是字向量的维度序号,取值范围是 [0,embedding_dimension/2),dmodel 指的是 embedding_dimension的值
def get_sinusoid_encoding_table(n_position, d_model):
#hid_idx是字向量的维度序号(字每个维度的计算公式)
def cal_angle(position, hid_idx):
return position / np.power(10000, 2 * (hid_idx // 2) / d_model)
#某个字的位置编码维度为d_model,和字向量维度相同(遍历字的每个维度)
def get_posi_angle_vec(position):
return [cal_angle(position, hid_j) for hid_j in range(d_model)]
#pos+i:一句话中某个字的位置(遍历每个字)
sinusoid_table = np.array([get_posi_angle_vec(pos_i) for pos_i in range(n_position)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
return torch.FloatTensor(sinusoid_table)上述注释应该从下往上看。“所谓的看不懂代码,其实是对论文的不熟悉”。果真如此。对于上述代码我一直比较模糊,知道是和上述公式相关,但是对于每一行代码的意思,每一行代码为什么这么写,并不清楚。今天再结合公式,仔细一看,非常清楚明白。所以说到底还是对公式、对论文的不够熟悉。
Pad Mask
def get_attn_pad_mask(seq_q, seq_k):
'''
seq_q: [batch_size, seq_len]
seq_k: [batch_size, seq_len]
seq_len could be src_len or it could be tgt_len
seq_len in seq_q and seq_len in seq_k maybe not equal
'''
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# eq(zero) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # [batch_size, 1, len_k], False is masked
return pad_attn_mask.expand(batch_size, len_q, len_k) # [batch_size, len_q, len_k]
# pad_attn_mask: tensor([[[False, False, False, False, True]],
# [[False, False, False, False, True]]])
# pad_attn_mask.expand(batch_size, len_q, len_k): tensor([[[False, False, False, False, True],
# [False, False, False, False, True],
# [False, False, False, False, True],
# [False, False, False, False, True],
# [False, False, False, False, True]],
#
# [[False, False, False, False, True],
# [False, False, False, False, True],
# [False, False, False, False, True],
# [False, False, False, False, True],
# [False, False, False, False, True]]])由于在Encoder和Decoder中都需要进行mask操作,因此就无法确定这个函数的参数中seq_len的值,如果是在Encoder中调用的,seq_len就等于src_len;如果是在Decoder中调用的,seq_len就有可能等于src_len,也有可能等于tgt_len(因为Decoder有两次mask)
这个函数最核心的一句代码是seq_k.data.eq(0),这句的作用是返回一个大小和seq_k一样的tensor,只不过里面的值只有True和False。如果seq_k某个位置的值等于0,那么对应位置就是True,否则即为False。举个例子,输入为seq_data = [1, 2, 3, 4, 0],seq_data.data.eq(0)就会返回[False, False, False, False, True]
剩下的代码主要是扩展维度,强烈建议读者打印出来,看看最终返回的数据是什么样子。
Subsequence Mask
def get_attn_subsequence_mask(seq):
'''
seq: [batch_size, tgt_len]
'''
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
subsequence_mask = np.triu(np.ones(attn_shape), k=1) # Upper triangular matrix
subsequence_mask = torch.from_numpy(subsequence_mask).byte()
return subsequence_mask首先通过np.ones()生成一个全1的方阵,然后通过np.triu()生成一个上三角矩阵。下图是np.triu()用法
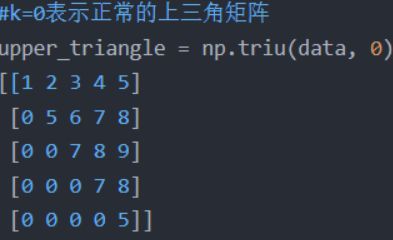
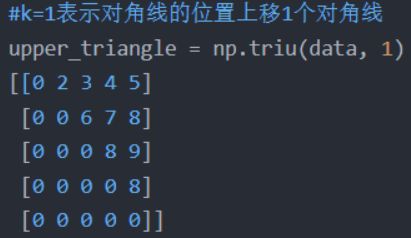
举个例子,Decoder 的 ground truth 为 " 。然后进行 self-attention 操作,首先通过
。然后进行 self-attention 操作,首先通过 得到 Scaled Scores,接下来非常关键,我们要对 Scaled Scores 进行 Mask,举个例子,当我们输入 "I" 时,模型目前仅知道包括 "I" 在内之前所有字的信息,即 "
得到 Scaled Scores,接下来非常关键,我们要对 Scaled Scores 进行 Mask,举个例子,当我们输入 "I" 时,模型目前仅知道包括 "I" 在内之前所有字的信息,即 "
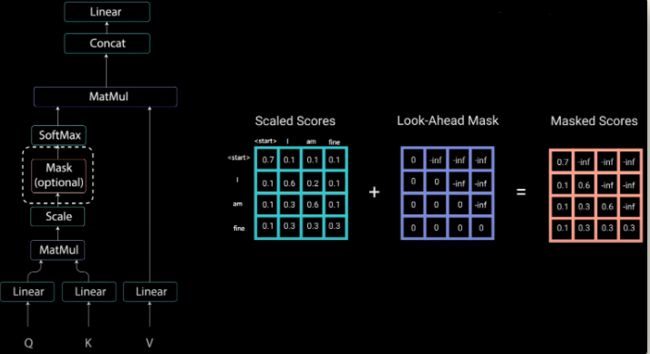
之后再做 softmax,就能将 - inf 变为 0,得到的这个矩阵即为每个字之间的权重。
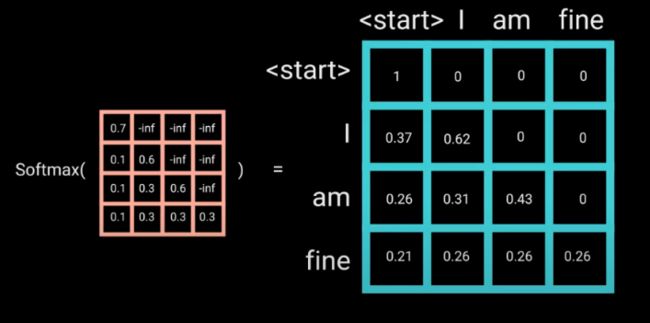
Multi-Head Self-Attention 无非就是并行的对上述步骤多做几次,前面 Encoder 也介绍了,这里就不多赘述了
ScaledDotProductAttention
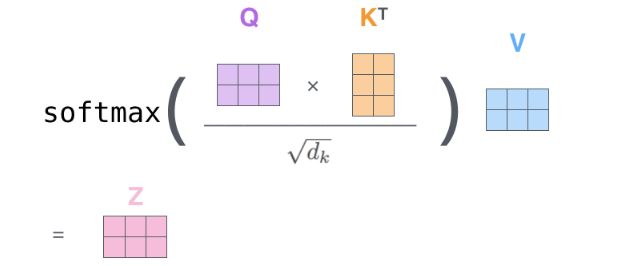
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
'''
Q: [batch_size, n_heads, len_q, d_k]
K: [batch_size, n_heads, len_k, d_k]
V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask: [batch_size, n_heads, seq_len, seq_len]
'''
# scores : [batch_size, n_heads, len_q, len_k]
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
#让pad为0的无效的区域不参与运算,给无效区域加一个很大的负数偏置
scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is True.
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V) # [batch_size, n_heads, len_q, d_v]
return context, attn这里要做的是,通过Q和K计算出scores,然后将scores和V相乘,得到每个单词的context vector
第一步是将Q和K的转置相乘没什么好说的,相乘之后得到的scores还不能立刻进行softmax,需要和attn_mask相加,把一些需要屏蔽的信息屏蔽掉,attn_mask是一个仅由True和False组成的tensor,并且一定会保证attn_mask和scores的维度四个值相同(不然无法做对应位置相加)
mask完了之后,就可以对scores进行softmax了。然后再与V相乘,得到context。
scores.masked_fill_(attn_mask, -1e9) Self Attention 的计算过程中,我们通常使用 mini-batch 来计算,也就是一次计算多句话,即 X 的维度是 [batch_size, sequence_length],sequence_length是句长,而一个 mini-batch 是由多个不等长的句子组成的,我们需要按照这个 mini-batch 中最大的句长对剩余的句子进行补齐,一般用 0 进行填充,这个过程叫做 padding。
但这时在进行 softmax 就会产生问题。回顾 softmax 函数  ,
, 是 1,是有值的,这样的话 softmax 中被 padding 的部分就参与了运算,相当于让无效的部分参与了运算,这可能会产生很大的隐患。因此需要做一个 mask 操作,让这些无效的区域不参与运算,一般是给无效区域加一个很大的负数偏置,即
是 1,是有值的,这样的话 softmax 中被 padding 的部分就参与了运算,相当于让无效的部分参与了运算,这可能会产生很大的隐患。因此需要做一个 mask 操作,让这些无效的区域不参与运算,一般是给无效区域加一个很大的负数偏置,即


MultiHeadAttention
#输入Q,K,V,得到z:context
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
def forward(self, input_Q, input_K, input_V, attn_mask):
'''
X_embedding: [batch_size,sequence_length,embedding dimension]
input_Q: [batch_size, len_q(=len_k), d_model]
input_K: [batch_size, len_k, d_model]
input_V: [batch_size, len_v, d_model]
attn_mask: [batch_size, seq_len, seq_len]
'''
residual, batch_size = input_Q, input_Q.size(0)
# (B, L, D) -proj-> (B, L, D_new) -split-> (B, L, H, W) -trans-> (B, H, L, W)
Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # Q: [batch_size, n_heads, len_q, d_k]
K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # K: [batch_size, n_heads, len_k, d_k]
V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # V: [batch_size, n_heads, len_v, d_v]
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size, n_heads, seq_len, seq_len]
# context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_k]
context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)
context = context.transpose(1, 2).reshape(batch_size, -1, n_heads * d_v) # context: [batch_size, len_q, n_heads * d_v]
output = self.fc(context) # [batch_size, len_q, d_model]
return nn.LayerNorm(d_model)(output + residual), attnnn.Linear定义一个神经网络的线性层:
torch.nn.Linear(in_features, # 输入的神经元个数
out_features, # 输出神经元个数
bias=True # 是否包含偏置)nn.Linear其实就是对输入 执行了一个线性变换。即:
执行了一个线性变换。即:

其中W时模型要学的参数,维度为 ,b是o维的向量偏置。n 为输入向量的行数(例如,你想一次输入10个样本,即batch_size为10,则n = 10 ),i 为输入神经元的个数(例如你的样本特征数为5,则 i = 5),o为输出神经元的个数。
,b是o维的向量偏置。n 为输入向量的行数(例如,你想一次输入10个样本,即batch_size为10,则n = 10 ),i 为输入神经元的个数(例如你的样本特征数为5,则 i = 5),o为输出神经元的个数。
完整代码中一定会有三处地方调用MultiHeadAttention(),Encoder Layer调用一次,传入的input_Q、input_K、input_V全部都是enc_inputs;Decoder Layer中两次调用,第一次传入的全是dec_inputs,第二次传入的分别是dec_outputs,enc_outputs,enc_outputs。
FeedForward Layer
#FeedForwardLayer:做两次线性变换,残差连接后再跟一个LayerNorm
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.fc = nn.Sequential(
nn.Linear(d_model, d_ff, bias=False),
nn.ReLU(),
nn.Linear(d_ff, d_model, bias=False)
)
def forward(self, inputs):
'''
inputs: [batch_size, seq_len, d_model]
'''
residual = inputs
output = self.fc(inputs)
return nn.LayerNorm(d_model)(output + residual) # [batch_size, seq_len, d_model]Encoder Layer
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, enc_inputs, enc_self_attn_mask):
'''
enc_inputs: [batch_size, src_len, d_model]
enc_self_attn_mask: [batch_size, src_len, src_len]
'''
# enc_outputs: [batch_size, src_len, d_model], attn: [batch_size, n_heads, src_len, src_len]
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) # enc_inputs to same Q,K,V
enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size, src_len, d_model]
return enc_outputs, attn将上述组件拼起来,就是一个完整的Encoder Layer
Encoder
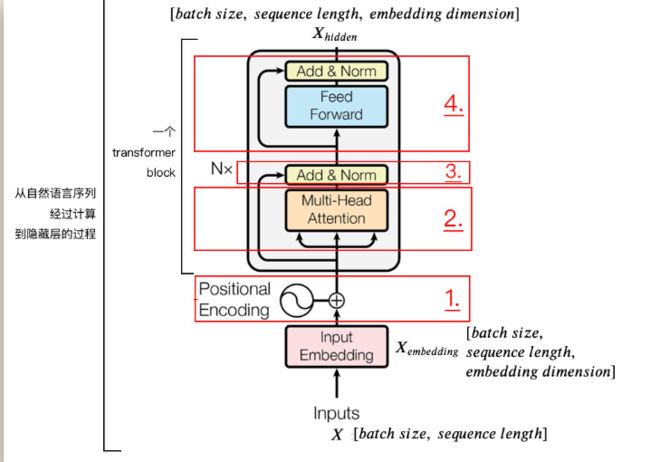
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
#对于嵌入层有两种方式初始化embedding向量,一种是直接随机初始化,另一种是使用预训练好的词向量初始化
self.src_emb = nn.Embedding(src_vocab_size, d_model)
self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(src_vocab_size, d_model),freeze=True) #freeze=True:训练过程中embedding权重不更新
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
def forward(self, enc_inputs):
'''
enc_inputs: [batch_size, src_len]
'''
word_emb = self.src_emb(enc_inputs) # [batch_size, src_len, d_model]
pos_emb = self.pos_emb(enc_inputs) # [batch_size, src_len, d_model]
enc_outputs = word_emb + pos_emb
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) # [batch_size, src_len, src_len]
enc_self_attns = []
for layer in self.layers:
# enc_outputs: [batch_size, src_len, d_model], enc_self_attn: [batch_size, n_heads, src_len, src_len]
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns使用nn.ModuleList()里面的参数是列表,列表里面存了n_layers个Encoder Layer
由于我们控制好了Encoder Layer的输入和输出维度相同,所以可以直接用个for循环以嵌套的方式,将上一次Encoder Layer的输出作为下一次Encoder Layer的输入。
Decoder Layer
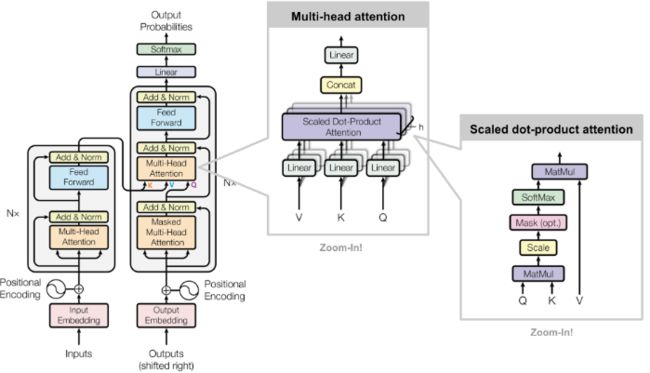
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
'''
dec_inputs: [batch_size, tgt_len, d_model]
enc_outputs: [batch_size, src_len, d_model]
dec_self_attn_mask: [batch_size, tgt_len, tgt_len]
dec_enc_attn_mask: [batch_size, tgt_len, src_len]
'''
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
# dec_outputs: [batch_size, tgt_len, d_model], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)
dec_outputs = self.pos_ffn(dec_outputs) # [batch_size, tgt_len, d_model]
return dec_outputs, dec_self_attn, dec_enc_attn在Decoder Layer中会调用两次MultiHeadAttention,第一次是计算Decoder Input的self-attention,得到输出dec_outputs。然后将dec_outputs作为生成Q的元素,enc_outputs作为生成K和V的元素,再调用一次MultiHeadAttention,得到的是Encoder和Decoder Layer之间的context vector。最后将dec_outptus做一次维度变换,然后返回。
Decoder
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(tgt_vocab_size, d_model),freeze=True)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
def forward(self, dec_inputs, enc_inputs, enc_outputs):
'''
dec_inputs: [batch_size, tgt_len]
enc_intpus: [batch_size, src_len]
enc_outputs: [batsh_size, src_len, d_model]
'''
word_emb = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]
pos_emb = self.pos_emb(dec_inputs) # [batch_size, tgt_len, d_model]
dec_outputs = word_emb + pos_emb
#Decoder中不仅要把"pad"mask掉,还要mask未来时刻的信息,因此有了以下三行代码。
#torch.gt(a,value)的意思是,将a中各位置上的元素与value比较,若大于value,则该位置取1,否则取0
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs) # [batch_size, tgt_len, tgt_len]
dec_self_attn_subsequent_mask = get_attn_subsequence_mask(dec_inputs) # [batch_size, tgt_len]
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0) # [batch_size, tgt_len, tgt_len]
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) # [batc_size, tgt_len, src_len]
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers:
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs, dec_self_attns, dec_enc_attnsDecoder中不仅要把"pad"mask掉,还要mask未来时刻的信息,因此就有了下面这三行代码,其中torch.gt(a, value)的意思是,将a中各个位置上的元素和value比较,若大于value,则该位置取1,否则取0。
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs)
# [batch_size, tgt_len, tgt_len]
dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs)
# [batch_size, tgt_len, tgt_len]
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask), 0) # [batch_size, tgt_len, tgt_len]Transformer
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder()
self.decoder = Decoder()
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False)
def forward(self, enc_inputs, dec_inputs):
'''
enc_inputs: [batch_size, src_len]
dec_inputs: [batch_size, tgt_len]
'''
# tensor to store decoder outputs
# outputs = torch.zeros(batch_size, tgt_len, tgt_vocab_size).to(self.device)
# enc_outputs: [batch_size, src_len, d_model], enc_self_attns: [n_layers, batch_size, n_heads, src_len, src_len]
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
# dec_outpus: [batch_size, tgt_len, d_model], dec_self_attns: [n_layers, batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [n_layers, batch_size, tgt_len, src_len]
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
dec_logits = self.projection(dec_outputs) # dec_logits: [batch_size, tgt_len, tgt_vocab_size]
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attnsTransformer主要就是调用Encoder和Decoder。最后返回dec_logits的维度是[batch_size * tgt_len, tgt_vocab_size],可以理解为,一个句子,这个句子有batch_size*tgt_len个单词,每个单词有tgt_vocab_size种情况,取概率最大者
model = Transformer()
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.99)这里的损失函数里面我设置了一个参数ignore_index=0,因为"pad"这个单词的索引为0,这样设置以后,就不会计算"pad"的损失(因为本来"pad"也没有意义,不需要计算),关于这个参数更详细的说明,可以看我这篇文章的最下面,稍微提了一下。
训练
for epoch in range(30):
for enc_inputs, dec_inputs, dec_outputs in loader:
'''
enc_inputs: [batch_size, src_len]
dec_inputs: [batch_size, tgt_len]
dec_outputs: [batch_size, tgt_len]
'''
# enc_inputs, dec_inputs, dec_outputs = enc_inputs.to(device), dec_inputs.to(device), dec_outputs.to(device)
# outputs: [batch_size * tgt_len, tgt_vocab_size]
outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)
loss = criterion(outputs, dec_outputs.view(-1))
print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()测试
enc_inputs, dec_inputs, _ = next(iter(loader))
predict, _, _, _ = model(enc_inputs[0].view(1, -1), dec_inputs[0].view(1, -1))
# model(enc_inputs[0].view(1, -1), greedy_dec_input)
# enc_inputs[0]: tensor([1, 2, 3, 5, 0])
# enc_inputs[0].view(1, -1): tensor([[1, 2, 3, 5, 0]])
#沿第1维选择最大值的下标 tensor([[1],[2],[3],[5],[8],[7]])
predict = predict.data.max(1, keepdim=True)[1]
#predict.squeeze() :减少一个维度,由二维变为列表 tensor([1, 2, 3, 5, 8, 7])
print(enc_inputs[0], '->', [idx2word[n.item()] for n in predict.squeeze()])最后给出完整代码链接(需要科学的力量)
Github 项目地址:nlp-tutorial