基于PyTorch搭建FasterRCNN实现目标检测
基于PyTorch搭建FasterRCNN实现目标检测
1. 图像分类 vs. 目标检测

图像分类是一个我们为输入图像分配类标签的问题。例如,给定猫的输入图像,图像分类算法的输出是标签“猫”。
在目标检测中,我们不仅对输入图像中存在的对象感兴趣。我们还对它们在输入图像中的位置感兴趣。从这个意义上说,目标检测超越了图像分类。
1.1 图像分类与目标检测:使用哪一个?
图像分类非常适合图像中只有一个对象的应用。可能有多个类(例如猫、狗等),但通常图像中只有该类的一个实例。
在大多数输入图像中有多个对象的应用中,我们需要找到对象的位置,然后对它们进行分类。在这种情况下,我们使用目标检测算法。
目标检测可能比图像分类慢数百倍。因此,在图像中对象的位置不重要的应用中,我们使用图像分类。
2. 目标检测
简单来说,目标检测是一个两步过程:
- 查找包含对象的边界框,使得每个边界框仅包含一个对象。
- 对每个边界框内的图像进行分类并为其分配标签。
在接下来的几节中,我们将介绍 Faster R-CNN 目标检测架构开发的步骤。
2.1 滑动窗口方法
大多数用于目标检测的经典计算机视觉技术(例如 HAAR 级联和 HOG + SVM)都使用滑动窗口方法来检测目标。
在这种方法中,滑动窗口在图像上移动。该滑动窗口内的所有像素都被裁剪掉并发送到图像分类器。
如果图像分类器识别出已知对象,则存储边界框和类标签。否则,将评估下一个窗口。
滑动窗口方法的计算量非常大。为了检测输入图像中的对象,需要在图像中的每个像素处评估不同尺度和纵横比的滑动窗口。
由于计算成本,仅当我们检测具有固定纵横比的单个对象类时才使用滑动窗口。例如,OpenCV 中基于 HOG + SVM 或 HAAR 的人脸检测器使用滑动窗口方法。有趣的是,著名的 Viola Jones 人脸检测使用滑动窗口。对于人脸检测器,复杂性是可控的,因为仅在不同尺度下评估方形边界框。
2.2 R-CNN目标检测
在基于 CNN 的方法赢得 2012 年 ImageNet 大规模视觉识别挑战赛 (ILSVRC) 后,基于卷积神经网络 (CNN) 的图像分类器开始流行。
由于每个目标检测器的核心都有一个图像分类器,因此基于 CNN 的目标检测器的发明就变得不可避免。
有两个挑战需要克服:
- 与 HOG + SVM 或 HAAR 级联等传统技术相比,基于 CNN 的图像分类器的计算成本非常昂贵。
- 计算机视觉社区变得越来越雄心勃勃。人们希望构建一个多类对象检测器,除了能够处理不同的尺度之外,还可以处理不同的纵横比。
研究人员开始研究训练机器学习模型的新想法,该模型可以提出包含对象的边界框的位置。这些边界框称为区域提议或对象提议。
Ross Girshick 等人提出的第一个使用区域提议的方法被称为 R-CNN(具有 CNN 特征的区域的缩写)。

他们使用一种称为“选择性搜索”的算法来检测 2000 个区域提案,并在这 2000 个边界框上运行基于 CNN + SVM 的图像分类器。
当时 R-CNN 的精度是最先进的,但速度仍然很慢(GPU 上每张图像 18-20 秒)
2.3 Fast R-CNN目标检测
在 R-CNN 中,每个边界框由图像分类器独立分类。有 2000 个区域提案,图像分类器为每个区域提案计算一个特征图。这个过程是昂贵的。
在 Ross Girshick 的后续工作中,他提出了一种名为 Fast R-CNN 的方法,可以显着加快目标检测速度。
这个想法是为整个图像计算单个特征图,而不是为 2000 个区域提案计算 2000 个特征图。对于每个候选区域,感兴趣区域(RoI)池化层从特征图中提取固定长度的特征向量。每个特征向量随后用于两个目的:
- 将区域分类为某一类(例如狗、猫、背景)。
- 使用边界框回归器提高原始边界框的准确性。
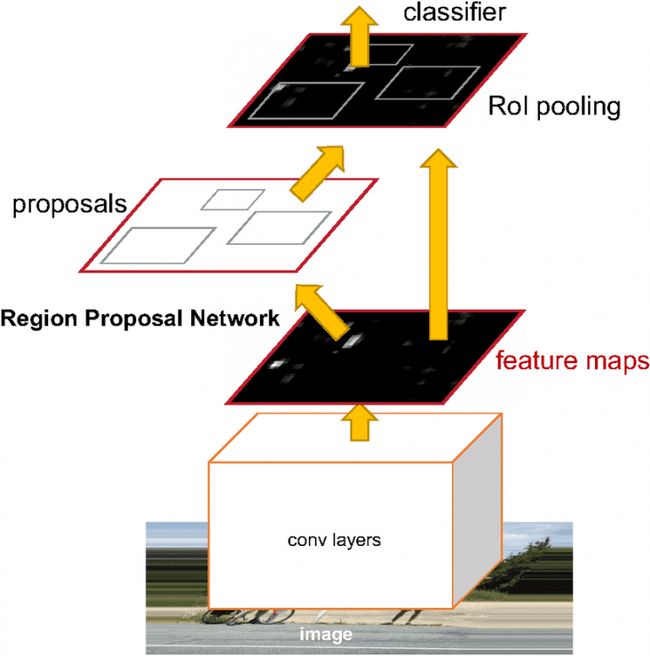
2.4 Faster R-CNN目标检测
在 Fast R-CNN 中,尽管共享了对 2000 个区域提案进行分类的计算,但生成区域提案的算法部分并未与执行图像分类的部分共享任何计算。
在名为 Faster R-CNN 的后续工作中,主要见解是计算区域提议和图像分类这两个部分可以使用相同的特征图,从而共享计算负载。
卷积神经网络用于生成图像的特征图,同时用于训练区域提议网络和图像分类器。由于这种共享计算,目标检测的速度有了显着的提高。
3. PyTorch实现目标检测
在本节中,我们将学习如何将 Faster R-CNN 目标检测器与 PyTorch 结合使用。我们将使用 torchvision 中包含的预训练模型。 PyTorch 中所有预训练模型的详细信息可以在 torchvision.models 中找到
3.1 输入和输出
我们将要使用的预训练 Faster R-CNN ResNet-50 模型期望输入图像张量采用 [n, c, h, w] 形式,最小尺寸为 800px,其中:
- n 是图像数量
- c 是通道数,对于 RGB 图像,其为 3
- h 是图像的高度
- w 是图像的宽度
模型将返回
- 边界框 [x0, y0, x1, y1] 形状为 (N,4) 的所有预测类别,其中 N 是模型预测的图像中存在的类别数量。
- 所有预测类别的标签。
- 每个预测标签的分数。
3.2 预训练模型
使用以下代码从 torchvision 下载预训练模型:
import torchvision
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
model.eval()
定义PyTorch官方文档给出的类名
COCO_INSTANCE_CATEGORY_NAMES = ['__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table', 'N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']
我们可以在列表中看到一些 N/A,因为后来的论文中删除了一些类。我们将使用 PyTorch 给出的列表。
3.3 模型预测
我们定义一个函数来获取图像路径并通过模型获得图像的预测。
from PIL import Image
from torchvision import transforms as T
def get_prediction(img_path, threshold):
"""
get_prediction
parameters:
- img_path - path of the input image
- threshold - threshold value for prediction score
"""
img = Image.open(img_path)
transform = T.Compose([T.ToTensor()])
img = transform(img)
pred = model([img])
pred_class = [COCO_INSTANCE_CATEGORY_NAMES[i] for i in list(pred[0]['labels'].numpy())]
pred_boxes = [[(int(i[0]), int(i[1])), (int(i[2]), int(i[3]))] for i in list(pred[0]['boxes'].detach().numpy())]
pred_score = list(pred[0]['scores'].detach().numpy())
pred_t = [pred_score.index(x) for x in pred_score if x > threshold][-1]
pred_boxes = pred_boxes[:pred_t + 1]
pred_class = pred_class[:pred_t + 1]
return pred_boxes, pred_class
- 从图像路径获取图像
- 使用 PyTorch 的 Transforms 将图像转换为图像张量
- 图像通过模型来获得预测
- 获得类、框坐标,但仅选择预测分数>阈值。
3.4 定义目标检测方法
接下来我们将定义一个方法来获取图像路径并获取输出图像。
import cv2
from matplotlib import pyplot as plt
def object_detection_api(img_path, threshold=0.5, rect_th=3, text_size=3, text_th=3):
boxes, pred_cls = get_prediction(img_path, threshold)
# Get predictions
img = cv2.imread(img_path)
# Read image with cv2
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Convert to RGB
for i in range(len(boxes)):
cv2.rectangle(img, boxes[i][0], boxes[i][1],color=(0, 255, 0), thickness=rect_th)
# Draw Rectangle with the coordinates
cv2.putText(img,pred_cls[i], boxes[i][0], cv2.FONT_HERSHEY_SIMPLEX, text_size, (0,255,0),thickness=text_th)
# Write the prediction class
plt.figure(figsize=(20,30))
# display the output image
plt.imshow(img)
plt.xticks([])
plt.yticks([])
plt.show()
- 预测是从 get_prediction 方法获得的
- 对于每个预测,都会绘制边界框并写入文本
与opencv - 显示最终图像
3.5 运行测试


