字符串函数的使用及模拟实现
字符串函数的使用及模拟实现
- 一:strstr函数的使用
-
- strstr的模拟实现
- 二:strncpy的使用及模拟使用
-
- strncpy的使用
- strncpy的模拟实现
- 三:strncat的使用及模拟实现
-
- strncat的使用
- strncat的模拟实现
- 四:strtok的使用
- 五:strerror函数的使用
一:strstr函数的使用
strstr是在一个字符串中寻找子字符串
功能:返回str2在str1第一次出现的位置
如果没出现,就返回NULL
#include strstr的模拟实现
设置一个指针cp,表示可能str1中找到str2的地址,便于打印
设置一个指针s2 ,表示每次寻找时str2的首字符地址。
设置一个指针s1,表示每次寻找时,str1的地址
#include 二:strncpy的使用及模拟使用
strncpy的使用
与strcpy最大的区别就是 规定了拷贝的长度,
#include strncpy的模拟实现
#include 可能有同学疑问,strncpy拷贝过程中并没有拷贝’\0’,为什么编译器没有报错,而是打印了我们想要的结果呢?
哈哈,我们想一块去了,虽然strncpy拷贝过程中并没有拷贝’\0’,但我们给a2初始化了10个’\0’.

三:strncat的使用及模拟实现
strncat的使用
与strcat函数相似,只是规定了追加的长度,可能不是追加了一个字符数组
#include strncat的模拟实现
#include 四:strtok的使用
今天是2023年9月10日,可以写成2023.9.10我们可以得到2023
9
10
吗?
strtok函数就可以实现
#include 上面的代码比较笨,如果分隔符多了,就会使代码变得非常繁琐,下面使用循环的方法,能达到更好的效果。
```c
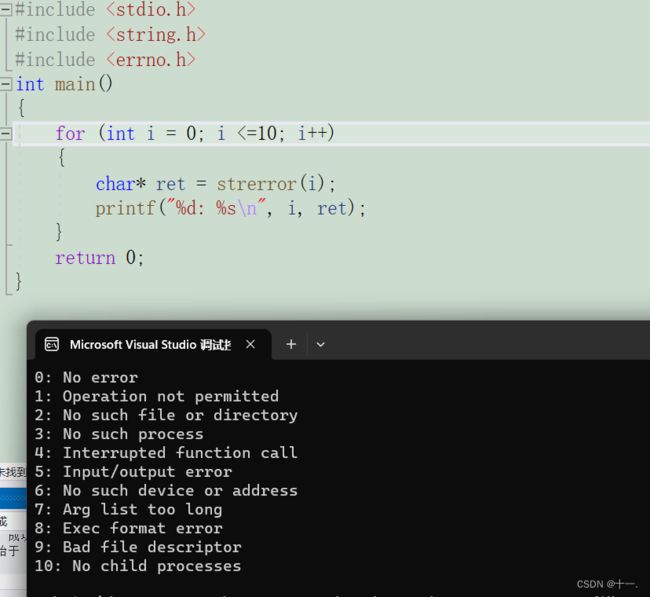
#include 五:strerror函数的使用
strerror可以把参数部分的错误码对应的错误信息的字符串地址返回来,strerror函数的使用需要头文件string.h
错误码一般放在errno.h这个头文件中说明的。
当库函数调用失败的时候,会讲错误码记录到errno这个变量中
errno是一个C语言的全局变量。