二分类任务:确定一个人是否年收入超过5万美元
文章目录
- 一、 问题描述
- 二、 设计简要描述
- 三、 程序清单
- 四、 结果分析
- 五、 调试报告
- 六、 实验总结
一、 问题描述
学会使用学习到的概率生成模型相关的知识,找出各类别最佳的高斯分布,从而达到通过输入测试,完成二分类任务,成功预测是否该用户年薪达到50k美元。
二、 设计简要描述
机器学习的三个基本步骤——
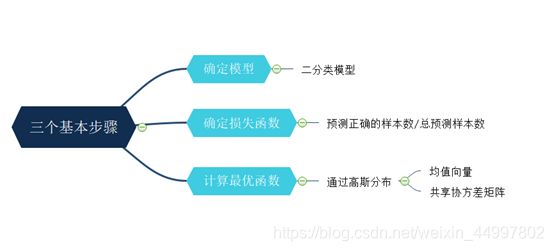
程序设计思路——

三、 程序清单
# 基于概率生成模型的二分类任务——确定一个人的年收入是否超过50k美元
import pandas as pd
import numpy as np
import csv
# 1. 数据预处理
# 1.1 读取数据
train_data = pd.read_csv("./train.csv")
test_data = pd.read_csv("./test.csv")
# 1.2 输入数据格式化处理
# 1.2.1 去除字符串数值前面的空格
str_cols = [1, 3, 5, 6, 7, 8, 9, 13, 14] # 这些列的属性值是字符串
for col in str_cols:
# iloc()是根据行号索引,参数中逗号前表示所有行,逗号后表示col所在列
# train_data.iloc[:, col] = train_data.iloc[:, col].map(lambda x: x.stripe())
pass
# 训练集共有15列,测试集共有14列
if col != 14:
#test_data.iloc[:, col] = test_data.iloc[:, col].map(lambda x: x.stripe())
pass
# map() 会根据提供的函数对指定序列做映射
# lambda x:表示是一个匿名函数
# .stripe()表示去除首尾的空格
# 1.2.2 将问号替换
# “workclass”的“?”修改为“Private”
train_data['workclass'][train_data['workclass'] == "?"] = 'Private'
test_data['workclass'][train_data['workclass'] == "?"] = 'Private'
# “occupation”的“?”修改为“other”
train_data['occupation'][train_data['occupation'] == "?"] = 'other'
test_data['occupation'][test_data['occupation'] == "?"] = 'other'
# 1.2.3 对字符数据进行编码
'''对原始数据进行编码处理,将所有数据信息均使用数字来表示,
方便使用于本次实验中训练。其中采用的编码方式为标签编码'''
# 训练集处理
# 放置每一列的encoder
from sklearn.preprocessing import LabelEncoder # 该类的作用是将离散型的数据转换成 0 到 n − 1 之间的数
train_label_encoder = []
train_encoded_set = np.empty(train_data.shape) # .shape用于读出矩阵的形状,empty()用于返回形状一样的多维数组,元素为随机产生的数字
# 对于每一列
for col in range(train_data.shape[1]):
encoder = None
# 对于该列的每一行
# 字符型数据
if train_data.iloc[:, col].dtype == object:
encoder = LabelEncoder()
train_encoded_set[:, col] = encoder.fit_transform(train_data.iloc[:, col])
# 数值型数据
# 连续的特征属性直接采用原值
else:
train_encoded_set[:, col] = train_data.iloc[:, col]
train_label_encoder.append(encoder)
train_encoded_data = train_encoded_set # 编码后的训练集,和原数据形状一样
# 测试集处理(完全同训练集)
# 放置每一列的encoder
test_label_encoder = []
test_encoded_set = np.empty(test_data.shape)
for col in range(test_data.shape[1]):
encoder = None
# 字符型数据
if test_data.iloc[:, col].dtype == object:
encoder = LabelEncoder()
test_encoded_set[:, col] = encoder.fit_transform(test_data.iloc[:, col])
# 数值型数据
else:
test_encoded_set[:, col] = test_data.iloc[:, col]
test_label_encoder.append(encoder)
test_encoded_data = test_encoded_set
# 1.3 划分训练集为训练集和验证集
from sklearn.model_selection import train_test_split # train_test_split()函数是用来随机划分样本数据为训练集和测试集的,优点是减少人为因素
# y为处理好的训练集的最后一列,X为训练集除去y的部分
X, y = train_encoded_data[:, :-1], train_encoded_data[:, -1]
# 完整模板:train_X,test_X,train_y,test_y = train_test_split(train_data,train_target,test_size=0.3,random_state=5)
# train_data:待划分样本数据
# train_target:待划分样本数据的结果(标签)
# test_size:测试数据占样本数据的比例,若整数则样本数量
# random_state:设置随机数种子,保证每次都是同一个随机数。若为0或不填,则每次得到数据都不一样
# X_train, X_val, y_train, y_val分别为训练集参数、验证集参数、训练集结果、测试集结果
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.1, random_state=50)
# 2. 将预处理好数据的加载到模型中,然后将其标准化
# mean()函数功能:求取均值
# axis = 0:压缩行,对各列求均值,返回 1* n 矩阵
# reshape(1, -1)使得数据集变成一列,-1为任意正整数的通配符
train_mean = np.mean(X_train, axis=0).reshape(1, -1)
# std()函数的功能是计算标准差
train_std = np.std(X_train, axis=0).reshape(1, -1)
train_data = X_train
# 3. 实现后验概率模型
'''分别求得后验概率中两类别的均值,以及共享的协方差,
计算出model的一些参数之后,化简公式就可以得到其属于某一类的概率计算公式'''
class_0_id = [] # 存放标签为0的训练集行数
class_1_id = [] # 存放标签为1的训练集行数
for i in range(len(y_train)):
if y_train[i] == 0:
class_0_id.append(i)
else:
class_1_id.append(i)
# 训练集按照标签不同被分成两部分
class_0 = train_data[class_0_id]
class_1 = train_data[class_1_id]
# n是属性的维数,均值为一个n维的向量,协方差矩阵为n*n
n = class_0.shape[1]
cov_0 = np.zeros((n, n))
cov_1 = np.zeros((n, n))
# 求两类别的均值
mean_0 = np.mean(class_0, axis=0).reshape(1, -1) # mean_0 是一个n为的列向量,每一维都是一个属性的均值
mean_1 = np.mean(class_1, axis=0).reshape(1, -1)
# 分别求各自的协方差
for i in range(class_0.shape[0]):
# dot()函数求的是矩阵的点积或一维数组的内积
# transpose()函数的作用是调换行和列的索引值
cov_0 += np.dot(np.transpose(class_0[i] - mean_0), (class_0[i] - mean_0)) / class_0.shape[0]
for i in range(class_1.shape[0]):
cov_1 += np.dot(np.transpose(class_1[i] - mean_1), (class_1[i] - mean_1)) / class_1.shape[0]
# 共享的协方差
cov = (cov_0 * class_0.shape[0] + cov_1 * class_1.shape[0]) / (class_0.shape[0] + class_1.shape[0])
from numpy.linalg import inv # 矩阵求逆
w = np.transpose(((mean_0 - mean_1)).dot(inv(cov)))
b = (-0.5) * (mean_0).dot(inv(cov)).dot(mean_0.T) + 0.5 * (mean_1).dot(inv(cov)).dot(mean_1.T) + np.log(
float(class_0.shape[0]) / class_1.shape[0])
# 4. 利用模型对验证集预测
'''利用训练集训练得到的模型也就是概率计算公式对验证集的测试数据进行计算,
然后根据验证集的真实结果进行对比,得到模型的精确率'''
val_array = np.empty([X_val.shape[0], 1], dtype=float)
for i in range(X_val.shape[0]):
z = X_val[i, :].dot(w) + b
z *= (-1)
val_array[i][0] = 1 / (1 + np.exp(z))
val_result = np.clip(val_array, 1e-8, 1 - (1e-8))
# 将预测结果转换为0、1
val_answser = np.ones([val_result.shape[0], 1], dtype=int)
for i in range(val_result.shape[0]):
# 概率大于0.5的,划分为类别0
if val_result[i] > 0.5:
val_answser[i] = 0
# 计算验证集的精确度
right_num = 0
for i in range(len(val_answser)):
if val_answser[i] == y_val[i]:
right_num += 1
# 精确度为预测正确的个数除以总个数
print("验证集上的准确率为:",right_num / len(val_answser))
# 5. 对测试集进行预测
test_array = np.empty([test_encoded_data.shape[0], 1], dtype=float)
for i in range(test_encoded_data.shape[0]):
z = test_encoded_data[i, :].dot(w) + b
z *= (-1)
test_array[i][0] = 1 / (1 + np.exp(z))
test_result = np.clip(test_array, 1e-8, 1 - (1e-8))
test_answer = np.ones([test_result.shape[0], 1], dtype=int)
for i in range(test_result.shape[0]):
if test_result[i] > 0.5:
test_answer[i] = 0
# 6. 保存预测结果到文件中
# 6.1 仅保存结果
predict_result_file = open('./predict_result.csv', 'w', newline='')
writer = csv.writer(predict_result_file)
writer.writerow(('id', 'label'))
for i in range(test_answer.shape[0]):
writer.writerow([i + 1, test_answer[i][0]])
predict_result_file.close()
# 6.2 保存预测结果到原测试文件中
# 修改0、1值为<=50K、>50K
predict_answer = []
for i in range(len(test_answer)):
if test_answer[i] == 0:
predict_answer.append(' <=50K')
else:
predict_answer.append(' >50K')
# 保存预测结果到文件中
source_file = './test.csv' # person.csv包括id,name,age三个列
predict_file = pd.read_csv(source_file, low_memory=False) # 读取csv,设置low_memory=False防止内存不够时报警告
predict_file['income'] = predict_answer # 增加新的列company
# 以下保存指定的列到新的csv文件,index=0表示不为每一行自动编号,header=1表示行首有字段名称
predict_file.to_csv('./predict.csv', index=0, header=1)
四、 结果分析
- 验证集上的准确率
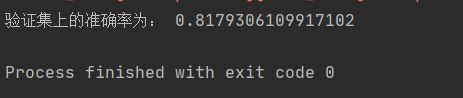
- 结果
- 更直观的结果
分析:结果符合预期
五、 调试报告
- 报错:AttributeError: ‘str’ object has no attribute ‘stripe’
定位:train_data.iloc[:, col] = train_data.iloc[:, col].map(lambda x: x.stripe())
分析:这一行的作用是,对指定列的所有行的数据进行处理,去掉字符串数值前后的空格
解决:换一种去除空格的方法
replace主要用于字符串的替换replace(old, new, count)
六、 实验总结
- 收获了很多数据处理相关知识
① 对于一个矩阵,shape[0]表示行数,shape[1]表示列数
② 对于[:, col]这种表达,以逗号为界,前面表示行信息,后面表示列信息
③ map()函数表示根据提供的函数对指定序列做映射
④ map()函数有lambda x:表示是一个匿名函数
⑤ Python提供了非常好用的矩阵替换信息,如
train_data['workclass'][train_data['workclass'] == "?"] = 'Private'
表示对于’workclass’这一栏凡是值为"?"都替换为’Private’
⑥ from sklearn.preprocessing import LabelEncoder
该类的作用是将离散型的数据转换成 0 到 n-1 之间的数
⑦ np.mean(class_0, axis=0)中class_0表示被求均值的矩阵,axis=0表示对矩阵的每一列求均值,最终得到一个行向量
⑧ reshape(1, -1)使得数据集变成一列,-1为任意正整数的通配符
⑨ 学会了使用csv.writer给数据添加一行
- 进一步加深了对理论知识的理解
在做实验之前只知道生成模型用到了高斯分布,但不是特别理解。实验中理解高斯分布在这里是一种假设,基于这种假设加上最大似然估计的思想,方才求得模型的参数,用于验证集和测试集的预测。