数据科学的文本技术 Text Technology(IR信息检索、搜索引擎)
一、文章摘要
1. 内容
* Introduction to IR and text processing, system components
* Zipf, Heaps, and other text laws
* Pre-processing: tokenization, normalisation, stemming, stopping.
* Indexing: inverted index, boolean and proximity search
* Evaluation methods and measures (e.g., precision, recall, MAP, significance testing).
* Query expansion
* IR toolkits and applications
* Ranked retrieval and learning to rank
* Text classification: feature extraction, baselines, evaluation
* Web search
2. 术语
- Inverted index
- Vector space model
- Retrieval models: TFIDF, BM25, LM
- Page rank
- Learning to rank (L2R)
- MAP, MRR, nDCG
- Mutual information, information gain, Chi-square
- binary/multiclass classification, ranking, regression
正文
二、Information Retrieval(信息检索)
1. 定义
- 信息检索是从大规模非结构化数据(通常是文本)的集合(通常保存于计算机上)中找出满足用户信息需求的的资料(通常是文本)的过程。
- 信息检索 (Information Retrieval) 是帮助用户从海量信息快速找到有用信息的技术,数据挖掘 (Data Mining) 则是用于从大数据中提取出隐含的、先前未知的并有潜在意义的信息。
- 信息检索(IR)是基于用于查询检索信息的任务。流行的信息检索模型包括布尔模型、向量空间模型、概率模型和语言模型。信息检索最典型和最常见的应用是搜索引擎。
我们可以用一个更简单的形式来看待信息检索。所谓的信息检索 (Information Retrieval) 就是给定一个查询 Q(Query),从文档集 C(Collection or Corpus)中计算每篇文档 D(Document) 与 Q 的相关度 (Relevance) 并排序 (Ranking)。这里的相关度 (Relevance) 可以看做一个函数 R ,该函数的输入为查询 Q,文档集 C 和文档 D,输出为一个实值:R = f(Q, C, D). 因此,确定文档和查询之间的相关度是信息检索 (Information Retrieval) 的核心问题。
那么我们如何进行信息的检索呢?
《莎士比亚全集》一书中,有着很多部作品,假如此时我们想要知道哪些作品包含 Brutus 和 Caesar 但是不包含 Calpurnia,该怎么做呢? 首先,最简单朴素的方法就是遍历。我们遍历这本书的每一部作品,去看它是否包含 Brutus 和 Caesar 但不包含 Calpurnia,并将之记录下来。这个过程也被称为 grepping,源自 Unix 下的一个文本扫描命令 grep。 但是这样简单的线性扫描明显是存在缺陷的,它难以应对以下几种情况:
- 大规模文档集条件下的快速查找。 数据量的增长速度远高于计算机性能的增长速度,当对规模极为庞大的数据进行遍历/线性扫描时,花费的成本显然会很高
- 有时需要更灵活的匹配方式。 在 grep 命令下,不能支持诸如 Romans NEAR countrymen 之类的查询(这里的 NEAR 操作符可能指的是“countrymen的周围5个词以内有Romans”,或者是“countrymen 和 Romains 在同一个句子中”)
- 优选结果。 有时我们需要从所有返回的结果中采用最优答案
针对这样一个文档集,我们想要开发一个能处理 ad hoc 检索(ad hoc retrieval)任务的系统。所谓的 ad hoc 检索任务指的是任一用户的信息需求(Information Need)通过由用户提交的一次性查询(Query)传递给系统,让该系统从文档集中返回与之相关的文档。 这里的信息需求(Information Need)指的是用户想要查找的信息主题,而查询(Query)则是由用户提交给系统以表示其信息需求,因此,对于同样的信息需求 (Information Need),不同用户在不同时候可能会构造出不同的查询 (Query)。
信息检索 (Information Retrieval) 的两种模式,即 pull 和 push:
- Pull:用户主动发起请求,在一个相对稳定的数据集上进行查询,就是我们这里所说的 ad hoc,即 信息需求动态变化,而文档集则相对静止
- Push:用户事先定义自己的兴趣,系统在不断到来的数据流上进行操作,将满足用户兴趣的数据推送给用户,也就是进行过滤 (Filtering),即 信息需求在一段时间内保持不变,而文档集则变化频繁
系统会将与用户信息需求相关(Relevant)的文档返回。而衡量检索系统质量(Effectiveness)的方法和机器学习以及其他数据科学的方法一样,仍选择使用召回率(Recall)和准确率(Precission)来进行:
- 召回率(Recall):所有和信息需求真正相关的文档中,被检索系统返回的百分比 = TP / (TP + FN)
- 准确率(Precission):返回结果中,真正与信息需求相关的文档所占的百分比 = TP / (TP + FP)
2. 布尔检索(Boolean Retrieval)
一种典型的非线性扫描方式就是建立索引(Index)。我们首先统计《莎士比亚全集》这本书中一共使用了32000个不同的单词(这就是本书的Vocabulary),之后我们根据此书中的每部作品是否包含某个单词,构建一个由布尔值(0/1)构成的词项-文档矩阵(Incidence Matrix):

在这个矩阵中,词项(Term)是索引的单位(注意,词项不一定是单词,在其他情况下,也可能是序号或者某个地点)。根据我们看待的角度不同,可以得到不同的向量:
- 从行(Row)来看:得到每个词项的文档向量,表示词项在每个文档中出现或不出现
- 从列(Column)来看:得到每个文档的词项向量,表示每个文档中出现了哪些词项
在这里查询 “包含 Brutus 和 Caesar 但是不包含 Calpurnia” 时,实际上可将其看做一个逻辑表达式 “Brutus AND Caesar AND NOT Calpurnia”。因此,为了响应该查询,我们只需要关注词项Brutus, Caesar 和 Calpurnia 的行向量:
Brutus = 110100
Caesar = 110111
Calpurnia = 010000 之后对 Calpurnia 向量取反:¬ Calpurnia = 101111
最后在对 Brutus, Caesar 和 ¬ Calpurnia 三个向量进行逐位与(AND)运算即可,最后的结果为:
110100 AND 110111 AND 101111 = 100100
该结果表示只有第一个作品《Antony and Cleopatra》和第四个作品《Hamlet》满足查询的条件。
所以布尔检索模型接受布尔/逻辑表达式查询,也就是通过AND, OR 及 NOT 等逻辑运算符连接起来的查询。
但词项-文档矩阵(Incidence Matrix)有着高稀疏性,即取1的值相比取0的值要少很多,因此我们只需要关注矩阵中取值为1的位置即可。根据这种思想,可以使用倒排索引(Inverted Index)来解决。
3. 倒排索引(Inverted Index)
这里的“倒排”只是相对于数据科学在最开始处理类似问题时的方法,那时会采用从“文档”映射到“词项”的索引方式(类似于之前提到的“列向量”)。现在看来会有些多余,因为现在的我们只要在类似问题中提到的索引,都是从“词项”反映射到“文档”,这已成为主流的索引方式。
倒排索引(Inverted Index)的思想用一张图很好地理解:

在上图中的左边,就是我们所说的词典(Dictionary,也被称为Vocabulary/Lexicon)表示整个“文档集”中出现的所有“词项”。而对每一个词项,都有一个记录出现该“词项”的“文档”的 ID 列表,该列表中的每个元素就被成为“倒排记录(Posting)”,而该列表就是“倒排记录表(Posting List)”,同时,我们一般会对该列表中的 ID 进行排序。
那么倒排索引是如何建立的呢?
- 收集需要建立索引的文档(即收集数据集)
- 将每篇文档转换为词列表,这一步通常称为词条化(Tokenization)
- 进行语言学预处理,产生归一化的词条来作为词项。所谓的归一化/标准化,指的是在这一步中,一般会将文档中的词条恢复成最原始的形式,比如复数形式的词条转换为单数形式、过去式转换为一般式等,并且统一大小写
- 对所有文档按其中出现的词项来建立倒排索引,按照词条排序,再按照文件 ID 排序,最终合并结果
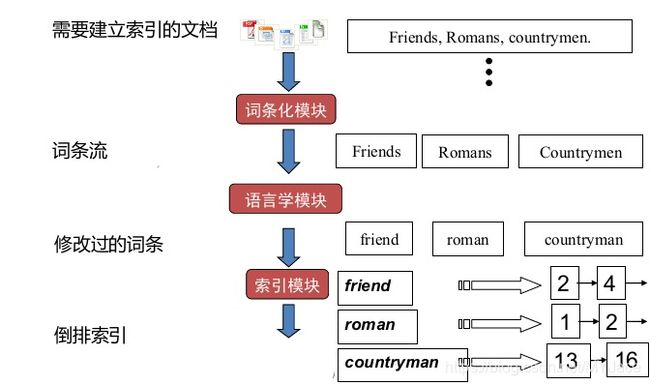

对于关键的第四步:

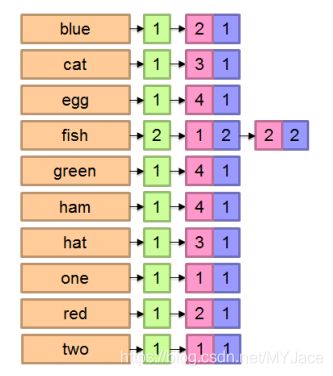
左边很显然就是词项词典(Dictionary);中间的绿色表示 DF (Document Frequency),即出现某词项的文档的数量,这里也就是词项对应的倒排记录表(Posting List)的长度;红色表示文档的 ID ,蓝色则是 TF (Term Frequency),即当前文档中出现该词项的次数。我们要注意的是 DF 和 TF 对于一个基本的布尔搜索引擎不是必须的,只是它们的存在可以再处理查询时提高效率。
最终得到的倒排索引中,词典(Dictionary)和倒排记录表(Posting List)都有存储开销,前者往往存储在内存中,后者开销较大,一般存放在磁盘中。 而对于倒排记录表,有多种存储方法可以选择,比较长用的两种就是单链表(Single Linked List)和变长数组(Variable Length Array)。前者通过增加指针可以自然地进行扩展,而后者一方面可节省指针的存储开销,另一方面由于使用连续的空间存储,可利用缓存(Cache)提高访问速度。
Laws of text (Zipf ….)
- Zipf’s Law
- Benford’s Law
- Heap’s Law
1. Heap's Law
我们可以大致估计一下文档集中不同的词项的总数 M。有人或许会以牛津英语词典(Oxford English Dictionary)作为一个标准的尺度,它里面的单词数目前超过了600,000,但是对于大部分大规模的文档集来说,其词汇量会远远大于这个数目,因为词典不会包含人名之类的特殊词汇。 因此,一般我们会采用 Heaps 定律 (Heaps’ Law) 来估计词项数目 M。该定律将词项数目估计为一个与文档集 (Collection) 大小相关的函数:
![]()
这里,T 是文档集中的词条 (Token) 总数。参数 k 和 b 的典型取值为:30 ≤ k ≤ 100,b ≈ 0.5。 Heaps 定律的核心思想在于,它认为文档集 (Collection) 大小和词汇量 (Vocabulary) 之间最简单的关系就是它们在对数空间 (log-log Space) 中存在线性关系。再简单一点说,在对数空间中,词汇量 M 和文档集尺寸 (词条数量) T 组成一条直线,斜率 (slope) 约为 1/2。
文本处理 Preprocessing
- Tokenisation:将给定的字符序列拆分成一系列子序列的过程,其中的每个子序列被称为词条 (Token)。 当然,在这个过程中,可能会同时去掉一些特殊字符(如标点符号等)
- Stopping:去除停用词,某些情况下,一些常见词在文档和用户需求进行匹配时价值并不大,需要彻底从词汇表中去除
- Normalisation:词条归一化,将看起来不完全一致的多个词条归纳成一个等价类,以便在它们之间进行匹配的过程
- Stemming:词干还原,很粗略的去除单词两端词缀的启发式过程,并且希望大部分时间它都能达到这个正确目的,这个过程也常常包括去除派生词缀
- Lemmatization:词形归并,利用词汇表和词形分析来去除屈折词缀,从而返回词的原形或词典中的词的过程,返回的结果称为词元(lemma)
搜索引擎(Search Engine)和 搜索算法
- Link analysis (PageRank)
- Anchor text
References
Information Retrieval(信息检索)笔记01:Boolean Retrieval(布尔检索)-CSDN博客
信息检索入门1 - KoU2N‘s BLOG
基于深度学习的文本检索&匹配算法 - 知乎
Text Technologies for Data Science Course Homepage