JUC中创建的组件 && 多线程使用“哈希表”
JUC中创建的组件
JUC中创建的组件这些内容都不太常用,偶尔用到面试的时候,偶尔用到!到时候自行查找即可,本文主要来快速的过一下,留个印象即可~
JUC(java.util.concurrent)和多线程相关的工具类。
1.Callable的用法
非常类似于Runnable(描述了一个任务/一个线程要干啥),Runnable通过run方法描述,返回类型void,但是很多时候,是希望任务要有返回值的,有一个具体的结果产出的!!
call的方法有返回值
写一个代码,创建一个线程,用这个线程计算一下:1+2+3+4+……+1000
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class Main {
public static void main(String[] args) throws ExecutionException,InterruptedException {
//这只是创建个任务
Callable callable=new Callable() {
@Override
public Integer call() throws Exception {
//Integer 看返回值类型(看实际需要)
int sum=0;
for (int i = 1; i <= 1000; i++) {
sum=sum+i;
}
return sum;
}
};
//还需要找个人,来完成这个任务(线程)
//Thread不能直接传Callable,需要在包装一层
FutureTask futureTask=new FutureTask<>(callable);
Thread t=new Thread(futureTask);
t.start();
//取结果
System.out.println(futureTask.get());
}
}
上述代码的运行结果为:
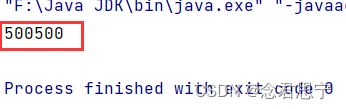
那么在上述代码中:如何保证调用get()的时候,t线程的call方法是执行完毕了呢??
其实get()和join()类似,都是会阻塞等待~
那么,到目前为止:我们有着以下四种方法来创建线程~
- 继承 Thread
- 实现Runnable
- 基于lambda
- 实现Callable
ReentrantLock的可重入:
synchronized关键字是基于代码块的方法来控制加锁解锁的!
ReentrantLock则是提供了lock和unlock两个独立的方法来进行加锁解锁的,虽然大部分情况下,使用synchronized就足够了,ReentrantLock也是一个重要的补充
体现在三个方面:
- synchronized只是加锁解锁,加锁的时候,如果发现锁被占用,只能阻塞等待,ReentrantLock还提供了一个trylock方法,如果加锁成功,没啥特殊的!如果加锁失败,不会阻塞,直接返回false(让程序员灵活的决定接下来做啥!)
- synchronized是一个非公平锁(概率均等,不遵循先来后到)ReentrantLock提供了公平和非公平两种工作模式(在构造方法中,使true——》公平锁)
- synchronized搭配wait(),notify()进行等待唤醒,如果多个线程wait()等待同一个对象,notify()的时候是随机唤醒一个!
ReentrantLock则是搭配Condition这个类,这个类也能起到等待通知,可以功能更加强大~
信号量(Semaphore)
停车场外面的一个牌子,显示剩余车位XXX(这就用到信号量)
信号量本质上是一个计数器,描述了当前“可用资源的个数”;
P操作:申请资源,计数器-1,V操作,释放资源,计数器+1
如果计数器已经是0了,继续申请资源,就会阻塞等待~
其实,所谓的“锁”,本质上是计数器为1的信号量
取值只有1和0两种,也叫二元信号量
信号量是更广义的锁,不光能管理非0既1的资源,也能管理多个资源!!
JUC的一些线程安全集合类~
常用的有:ArrayList,LinkList,HashMap,PriorityQueue……线程不安全
如果多线程环境下使用就可能出现问题:
- 最直接的方法:使用锁来手动保证!!多个线程去修改Array List此时就可能有问题,就可以给修改操作进行加锁操作!!
- 标准库还提供了一些线程安全版本的集合类,如果需要使用ArrayList,则可以使用Vector代替(不建议使用,古老级别)
CopyOnWeriteArrayList支持“写时拷贝”集合类
修改的时候就拷贝一份!!线程安全是多个线程修改不同变量(没加锁)
多线程使用“哈希表”
HaspMap线程不安全肯定不行!!
HashTable线程安全的,也是给关键方法加synchronized(加到方法上,相当于针对this加锁了!)
ConcurrentHashMap推荐方案:
高频面试题:HashTable和ConcurrentHashMap的区别!!(面试高频)
- 加锁粒度不同(触发锁冲突的频率)
HashTable是针对整个哈希表加锁,任何的增删改查操作,都会触发加锁,也就都会可能有锁竞争!实际上仔细思考,其实没必要加锁这么勤快!!
HashTable的底层是一个数组+链表
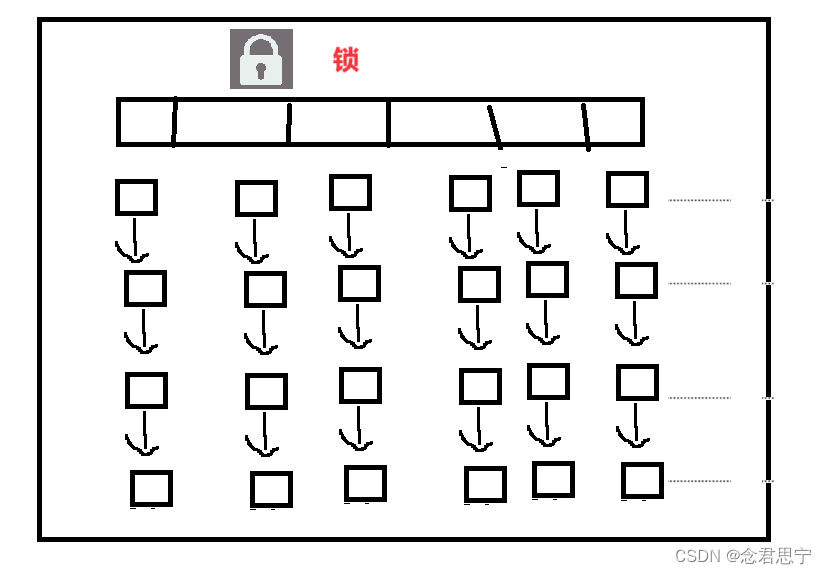
插入元素,根据Key计算hash值——》数组下标,把这个新的元素给挂到对应下标的链表上(Java Hash Map还会再链表太长的时候,把链表变为红黑树!
如果咱们是两个线程插入元素!
线程1插入的元素对应再下标为1的链表上~
线程2插入的元素对应再下标为2的链表上~
是否存在线程安全问题??两个线程修改不同变量,没啥事,没有线程安全问题!!此时虽然两个操作没有线程安全问题,但是由于synchronized是加到this上的,仍然会针对同一个对象产生锁竞争,产生阻塞等待!!
那么当不只有一把锁的时候:
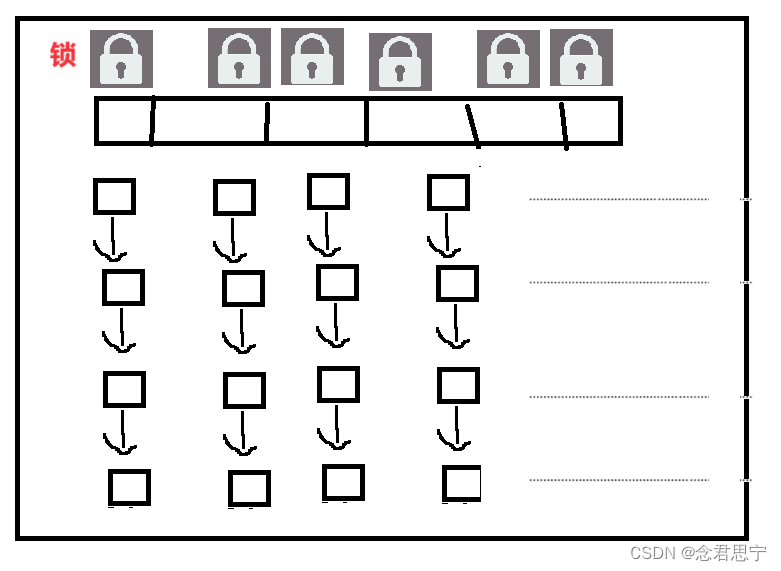
concurrentHashMap不是只有一把锁了,是每个链表(头节点)作为一把锁!!
每次进行操作,都是针对对应链表的锁进行加锁,操作不同链表就是针对不同的锁进行加锁,不会有竞争!!
该方法导致大部分加锁操作实际上没有锁冲突的,此时,这里的加锁操作的开销就微乎其微了!!
上述内容便是HashTable和ConcurrentHashMap的最大,最核心区别!!
concurrentHashMap是把每个链表的头节点放到synchronized
void put(String key,String value){
//先找到对应链表的头节点
int index=hashCode(key);
Node head=getHead(index);
synchronized (head){
//执行链表插入节点的操作
}
}上述的情况是从Java8开始的,在Java1.7及其之前,concurrentHashMap使用“分断锁”,目的和上述是类似的,相当于是好几个链表共用一把锁(这个设定是不科学的,效率不够高,代码写起来也很麻烦……)
其他方面的改进:
1.concurrentHashMap更重复的利用了CAS机制——》无锁编程!!
有的操作,比如获取/更新元素个数,就可以直接使用CAS完成,不必加锁了!!CAS也能保证线程安全,往往比锁更高效,但是这个东西咱们也不会经常使用!适用范围不像锁那么广泛!!
2.concurrentHashMap优化了扩容机制
HashTable如果元素过多,就会涉及到扩容——》负载因子0.75!!扩容需要重新申请空间,搬运元素(把元素从旧的哈希表上删除,插入到新的哈希表上),如果元素本身非常多,上亿个,搬运一次,成本就很高,就会导致这一次的put()操作就会非常卡顿!!而concurrentHashMap策略——》化整为零,并不会试图一次性的就把所有元素都搬运过去,而是每次只搬运一小部分 ,当put()触发扩容,此时就会直接创建更大的内存空间!!但是,不会直接把所有元素都搬运过去,而是只搬运一小部分(这样的速度还是比较快的!)此时相当于存在两份hash表了,此时插入元素直接往新表插入,删除元素:元素在哪个表的元素,查找:新表旧表都查看!并且每次操作都搬运一部分过去!
多线程比较复杂,应用非常广泛的东西,程序员必须要扎实掌握!