pytorch零基础入门学习
目录
1.两个重要函数
2.pytorch加载数据初认识
2.Dataset类代码实战
3.tensorboard的使用
3.1安装环境
3.2使用tensorboard绘制一次函数
3.3使用writer.add_image加载图像
4.transform
4.1什么是transform
4.2transform的简单使用
4.3transform和tensorboard结合
4.4transform常用函数
4.4.1 Totensor和Normalize
4.4.2Resize和compose
4.4.3RandomCrop和ToPLImage
4.5.torchvision中的cifar数据集使用
4.5.1.下载数据集
4.5.2查看数据
4.5.3利用tensorabord查看数据
4.5.4Dataloader的使用
5.神经网络的架构
5.1神经网络的基本架构
5.1.1nn.functional
5.2卷积层
5.2.1Conv2d
5.3池化层
5.3.1MaxPool2d
5.4非线性变换
5.4.1relu sigmod tanh
5.5.1linear
5.6sequential搭建一个CIFAR10网络模型
5.6.1CIF10网络模型分析
5.6.2sequential实现
5.6.3tensorboard可视化
5.7损失函数和反向传播
5.7.1基本损失函数
5.7.2神经网络模型结合损失函数
5.7.3反向传播
5.8优化器
5.8.1torch.optim.SGD
6.调用及修改官方模型
6.1vgg16
6.1.1官方模型
6.1.2修改官方模型
7.保存官方和自定义模型及其使用
7.1保存官方模型
7.1.1方法一
7.1.2方法二
7.2保存自定义模型
8.完整模型训练
8.1训练模型
8.1.1数据集准备
8.1.2数据集提取准备
8.1.3网络模型准备
8.1.4损失函数准备
8.1.5优化器准备
8.1.6网络训练参数准备
8.1.7开始训练
8.2测试模型
8.2.1总loss测试
8.2.2总准确率测试
8.2.3添加到tensorboard
8.2.4保存模型
8.3注意事项
8.3.1网络模型模式
9.利用GPU训练模型
9.1方法一
9.2方法二
10.完整模型测试
10.1准备数据和模型
10.1.1准备数据
10.1.2准备模型
10.2验证
1.两个重要函数
打开这个包,查看包下面有什么
dir()查看包下面的一个工具如何使用
help()
2.pytorch加载数据初认识
这里主要是两个重要工具
Dataset:用来提取我们需要的数据以及给数据打上标签
Dataloadr:对弄好的数据和标签进行打包
2.Dataset类代码实战
实现对ants和bees数据集进行数据的读取。
1.利用os.path.join(self.root_dir,self.label_dir)
实现了对于文件夹的组合拼接
2.利用Image.open(img_item_path)
实现了对()里面地址数据的读取
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self,root_dir,label_dir):
self.root_dir=root_dir
self.label_dir=label_dir
//实现文件夹之间的拼接
self.path=os.path.join(self.root_dir,self.label_dir)
self.img_path=os.listdir(self.path)
def __getitem__(self, idx):
img_name=self.img_path[idx]
//实现每一个图片的位置都可以找到
img_item_path=os.path.join(self.root_dir,self.label_dir,img_name)
//读取图片
img=Image.open(img_item_path)
//读取标签
label=self.label_dir
return img,label
def __len__(self):
return len(self.img_path)
if __name__ == '__main__':
root_dir = "E:\\2021_Project_YanYiXia\\pytorch\\p4\\hymenoptera_data\\train"
# root_dir = "data/train"
ants_label_dir = "ants_image"
bees_label_dir = "bees_image"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)
train_dataset = ants_dataset + bees_dataset
3.tensorboard的使用
3.1安装环境
pip install tensorboad3.2使用tensorboard绘制一次函数
代码如下
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("E:\\2021_Project_YanYiXia\pytorch\\p8\\1_Project_YanYiXia\pytorch\\p8\\logs")
# writer.add_image()
for i in range(100):
writer.add_scalar("y=2x",2*i,i)
writer.close()运行该代码后,在pycharm终端输入下面命令
tensorboard --logdir=E:\2021_Project_YanYiXia\pytorch\p8\
#注意,后面的是你生成文件存放的地址注意:后面那个是你生成那个events前缀文件的位置
然后在终端得到下面信息,点击那个网址,即可自动打开网页并生成信息

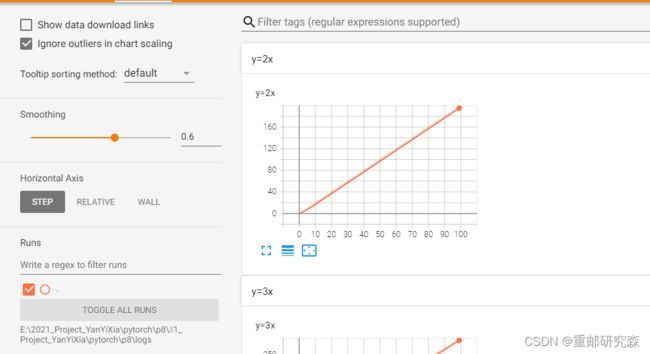
如果想一次性多生成两幅图,那么可以在原始代码之上进行修改,然后运行,然后刷新网页即可得到数据,但要注意,如果没有改名字的话,那么两次修改的内容会在一幅图上面。当然,你也可以删除那些文件,重新生成获得新图像
3.3使用writer.add_image加载图像
利用该模块可以进行图片数据的查看,这里要注意add_image函数传入参数的类型是有要求的,包括类型以及通道类型等等
注意:对于一个”test“下可以修改步骤数从而使得能够显示多个图片,如果想要图片不同地方显示就修改名字
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer=SummaryWriter("logs")
image_path="E:\\2021_Project_YanYiXia\\pytorch\\p8\hymenoptera_data\\train\\ants_image\\6240329_72c01e663e.jpg"
img_PIL=Image.open(image_path)
img_array=np.array(img_PIL)
writer.add_image("train",img_array,1,dataformats='HWC')
# for i in range(100):
# writer.add_scalar("y=2x",2*i,i)
writer.close()
4.transform
4.1什么是transform
transform是什么呢?其实就是一个大工具箱,利用这个工具箱我们可以对输入进行转换得到想要的输出,举个例子,一个类型为PIL的图片,通过transform转为tensor类型图片,而之所以要转类型是因为tensor类型支持我们后面的数据训练
4.2transform的简单使用
我们要实现的功能是把一个PIL格式的图片转换为tensor格式的图片
from PIL import Image
from torchvision import transforms
imag_path="hymenoptera_data/train/ants_image/0013035.jpg"
img=Image.open(imag_path)
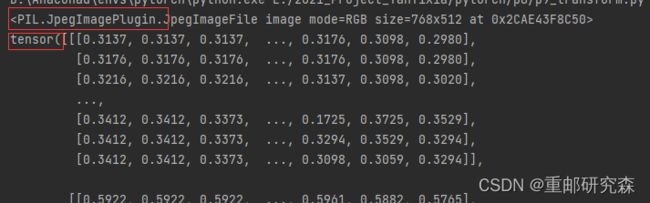
print(img)
tensot_trans=transforms.ToTensor()
tensor_img=tensot_trans(img)
print(tensor_img)
结果:
通过结果可以看出,数据类型已经改变
4.3transform和tensorboard结合
利用transform把图片格式转换后,利用tensorboard进行显示
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import cv2 as cv
imag_path="hymenoptera_data/train/ants_image/0013035.jpg"
img=Image.open(imag_path)
wrieter=SummaryWriter("logs")
tensot_trans=transforms.ToTensor()
tensor_img=tensot_trans(img)
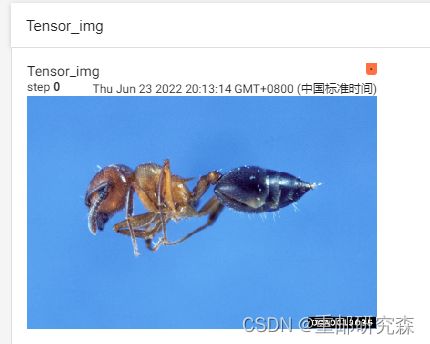
wrieter.add_image("Tensor_img",tensor_img)
wrieter.close()
结果:
4.4transform常用函数
4.4.1 Totensor和Normalize
Totensor:输入一个nimpy或者PIL类型数据图片,转为tensor类型
Normalize:输入一个tensor类型图片和均值和标准差,得到归一化的tensor类型图片
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import cv2 as cv
writer = SummaryWriter("logs")
img=Image.open("hymenoptera_data/train/ants_image/0013035.jpg")
print(img)
#totensor
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
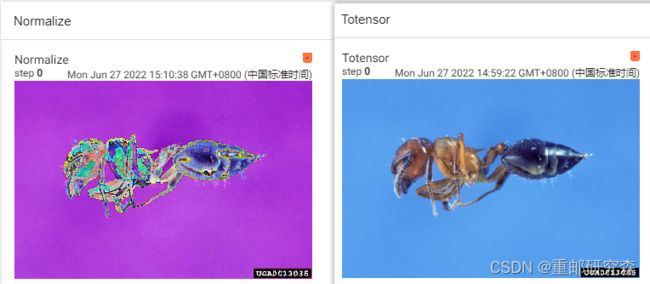
writer.add_image("Totensor",img_tensor)
#normalize
print(img_tensor[0][0][0])
trans_norm=transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm)
writer.close()
4.4.2Resize和compose
Resize:修改一个图片的尺寸
compose:可以对一个图片进行组合修改(同时修改尺寸和类型)
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import cv2 as cv
writer = SummaryWriter("logs")
img=Image.open("hymenoptera_data/train/ants_image/0013035.jpg")
print(img)
#Resize
print(img.size)
trans_Resize=transforms.Resize((512,512))
img_Resize=trans_Resize(img)
img_Resize=trans_totensor(img_Resize)
writer.add_image("Resize",img_Resize)
print(img_Resize)
#compose
trans_resize_2=transforms.Resize((25,250))
trans_compose = transforms.Compose([trans_resize_2,trans_totensor])
img_compose= trans_compose(img)
writer.add_image("compose",img_compose)
write.close()4.4.3RandomCrop和ToPLImage
RandomCrop:随机对一个图片进行尺寸修改
ToPLImage:把tensor或者numpy格式图片转为PLI类型
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import cv2 as cv
writer = SummaryWriter("logs")
img=Image.open("hymenoptera_data/train/ants_image/0013035.jpg")
print(img)
#randomcrop
trans_random = transforms.RandomCrop((200,300))
trans_compose_2=transforms.Compose([trans_random,trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("crop",img_crop,i)
#ToPILImage
trans_pil= transforms.ToPILImage()
img_pil=trans_pil(img_tensor)
print(img_pil)
write.close()
4.5.torchvision中的cifar数据集使用
4.5.1.下载数据集
方法一:在pycharm输入命令进行下载
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)方法二:通过网址在迅雷下载(下载完成后不用解压,移过去就行)
4.5.2查看数据
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True)
print(test_set[0])
print(test_set.classes)
img,target = test_set[0]
print(img)
print(target)
print(test_set.classes[target])
img.show()
4.5.3利用tensorabord查看数据
由于数据集类型本身是PLI格式,所以要进行格式转换为tensor,我们在开始加入下面这句话:
transform=dataset_transform所以整个代码就是:
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform,download=True)
writer = SummaryWriter("p10")
for i in range(10):
img,target = test_set[i]
writer.add_image("test_set",img,i)
writer.close()结果:

4.5.4Dataloader的使用
DataLoader主要是为了在数据集中拿到我们想要的数据,例如一副扑克牌是一个数据集,而我们可以通过DataLoader来一次取10张牌或者5张牌,是按顺序取还是乱序取牌都是根据DataLoader。
主要设置如下:
test_loadr = DataLoader(dataset=test_data,batch_size=64,shuffle=False,num_workers=0,drop_last=False)| dataset | 数据源 |
| batch_size | 一次取几个 |
| shuffle | 是否乱序 |
| num_workers | 几个进程 |
| drop_last | 是否保留最后(总数÷batch)的余数 |
这里我们利用DataLoader来调用数据集的数据,并且通过tensorboard显示
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
test_loadr = DataLoader(dataset=test_data,batch_size=64,shuffle=False,num_workers=0,drop_last=False)
img ,target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
step=0
for data in test_loadr:
imgs,targets = data
# print(imgs.shape)
# print(targets)
writer.add_images("test_data_drop_last",imgs,step)
step =step +1
writer.close()5.神经网络的架构
5.1神经网络的基本架构
定义一个简单的神经网络的架构,完成输入x,输出为x+1.其中,第一个def是初始化官方提供的父类,第二个def是定义我们自己的架构
import torch
from torch import nn
class Jason(nn.Module):
def __init__(self):
super().__init__()
def forward(self,input):
output=input+1
return output
jason=Jason()
x=torch.tensor(1.0)
output=jason(x)
print(output)5.1.1nn.functional
这里介绍functional的基本使用

| input | 输入 |
| weight | 卷积核 |
| stride | 步长 |
| padding | 填充 |
import torch
import torch.nn.functional as F
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
kernel = torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
#修改尺寸
input = torch.reshape(input,(1,1,5,5,))
kernel = torch.reshape(kernel,(1,1,3,3,))
print(input.shape)
print(kernel.shape)
output = F.conv2d(input,kernel,stride=1)
print(output)
output = F.conv2d(input,kernel,stride=2)
print(output)
output=F.conv2d(input,kernel,stride=1,padding=1)
print(output)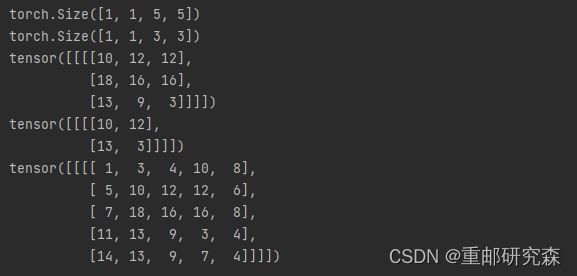
5.2卷积层
来自于Conv2d中,通过设置输入图片的通道,输出图片的通道,卷积核大小,stride,padding等值,进行输入图片卷积得到输出图片
5.2.1Conv2d
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
dataloadr = DataLoader(dataset,batch_size=64)
class Jason(nn.Module):
def __init__(self):
super(Jason, self).__init__()
self.conv1=Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self,x):
x=self.conv1(x)
return x
jason =Jason()
print(jason)
writer=SummaryWriter("dataloader")
step=0
for data in dataloadr:
imgs,targets=data
output = jason(imgs)
# print(imgs.shape)
# print(output.shape)
writer.add_images("input",imgs,step)
output=torch.reshape(output,(-1,3,30,30))
writer.add_images("output",output,step)
step=step+1
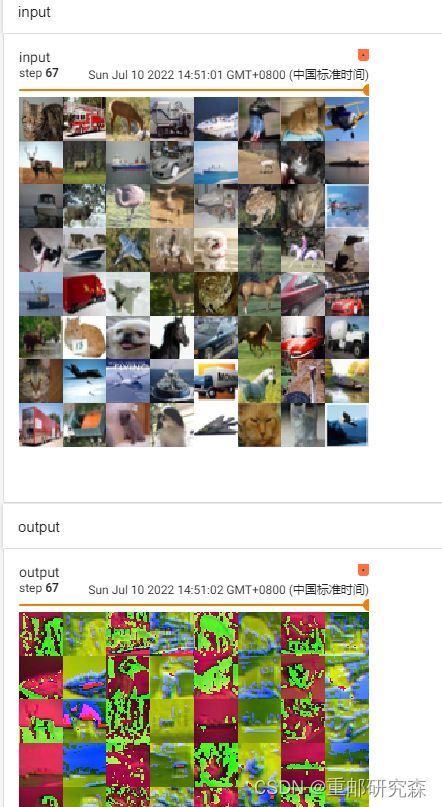
5.3池化层
池化的作用是来解决由于原始数据过多,为了让网络更快从而对原始数据进行特征保留。
5.3.1MaxPool2d
import torch
import torchvision.datasets
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10("./dataset",transform=torchvision.transforms.ToTensor(),download=True)
dataloadr=DataLoader(dataset,batch_size=64)
# input=torch.tensor([[1,2,0,3,1],
# [0,1,2,3,1],
# [1,2,1,0,0],
# [5,2,3,1,1,],
# [2,1,0,1,1]],dtype=torch.float32)
#
# input = torch.reshape(input,(-1,1,5,5))
# print(input.shape)
class Jason(nn.Module):
def __init__(self):
super(Jason, self).__init__()
self.maxpool=MaxPool2d(kernel_size=3,ceil_mode=False)
def forward(self,input):
output=self.maxpool(input)
return output
jason=Jason()
# output = jason(input)
# print(output)
writer=SummaryWriter("dataloader")
step=0
for data in dataloadr:
imgs,targets=data
output=jason(imgs)
writer.add_images("input",imgs,step)
writer.add_images("output",output,step)
step=step+1
writer.close()
5.4非线性变换
也叫做激活函数,用来对数据的处理
5.4.1relu sigmod tanh
import torch
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoader
from torch.nn import ReLU, Sigmoid
# input=torch.tensor([[1,-0.5],
# [-1,3]])
# output=torch.reshape(input,(-1,1,2,2))
#
# print(output.shape)
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10("./dataset",transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset,batch_size=64)
class Jason(nn.Module):
def __init__(self):
super(Jason,self).__init__()
self.relu1=ReLU()
self.sigmod1=Sigmoid()
def forward(self,input):
output=self.sigmod1(input)
return output
writer=SummaryWriter("dataloader")
step=0
jason=Jason()
for data in dataloader:
imgs,targets=data
writer.add_images("input",imgs,step)
output=jason(imgs)
writer.add_images("output",output,step)
step=step+1
writer.close()
# Jason=Jason()
# output=Jason(input)
# print(output)
5.5线性层
包括全连接层这些
5.5.1linear
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
dataset=torchvision.datasets.CIFAR10("./dataset",transform=torchvision.transforms.ToTensor(),download=True)
dataloader=DataLoader(dataset,batch_size=64,drop_last=True)
class Jason(nn.Module):
def __init__(self):
super(Jason,self).__init__()
self.inear1=Linear(196608,10)
def forward(self,input):
output=self.inear1(input)
return output
jason=Jason()
for data in dataloader:
imgs,targets=data
print(imgs.shape)
#output=torch.reshape(imgs,(1,1,1,-1))
output=torch.flatten(imgs)
print(output.shape)
output=jason(output)
print(output.shape)
5.6sequential搭建一个CIFAR10网络模型
本次部分主要分为三个:
第一是搭建CIF10模型。
第二个利用sequential实现模型。
第三个利用tensorboard实现可视化。
5.6.1CIF10网络模型分析
 从图中可以看出,该网络结构为:卷积-池化-卷积-池化-卷积-池化-拉直-全连接-全连接
从图中可以看出,该网络结构为:卷积-池化-卷积-池化-卷积-池化-拉直-全连接-全连接
因此网络结构代码如下:
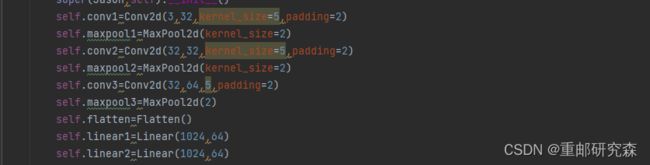
5.6.2sequential实现
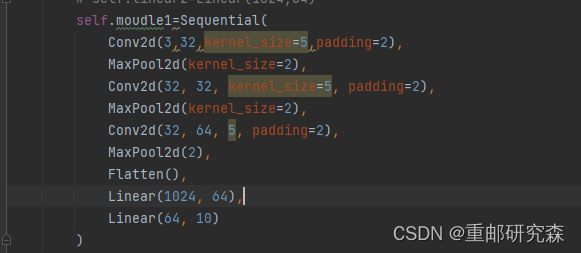
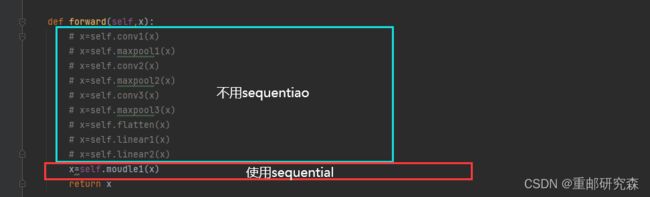
5.6.3tensorboard可视化
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class Jason(nn.Module):
def __init__(self):
super(Jason,self).__init__()
# self.conv1=Conv2d(3,32,kernel_size=5,padding=2)
# self.maxpool1=MaxPool2d(kernel_size=2)
# self.conv2=Conv2d(32,32,kernel_size=5,padding=2)
# self.maxpool2=MaxPool2d(kernel_size=2)
# self.conv3=Conv2d(32,64,5,padding=2)
# self.maxpool3=MaxPool2d(2)
# self.flatten=Flatten()
# self.linear1=Linear(1024,64)
# self.linear2=Linear(1024,64)
self.moudle1=Sequential(
Conv2d(3,32,kernel_size=5,padding=2),
MaxPool2d(kernel_size=2),
Conv2d(32, 32, kernel_size=5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
# x=self.conv1(x)
# x=self.maxpool1(x)
# x=self.conv2(x)
# x=self.maxpool2(x)
# x=self.conv3(x)
# x=self.maxpool3(x)
# x=self.flatten(x)
# x=self.linear1(x)
# x=self.linear2(x)
x=self.moudle1(x)
return x
jason=Jason()
print(jason)
input=torch.ones(64,3,32,32)
output=jason(input)
print(output.shape)
writer=SummaryWriter("dataloader")
writer.add_graph(jason,input)
writer.close()
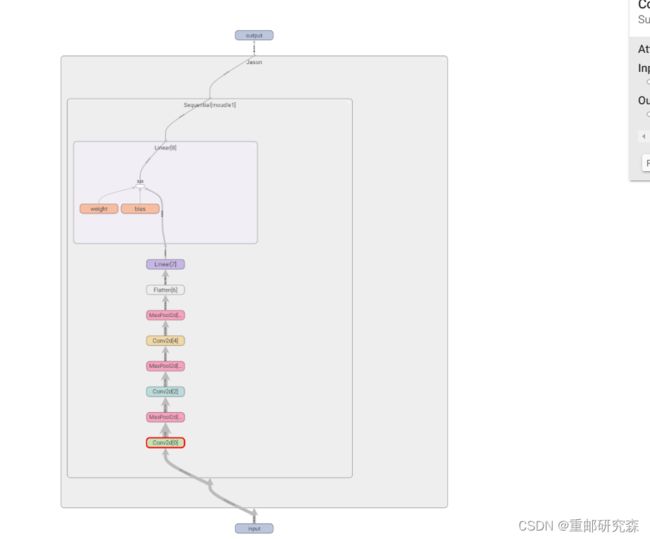
5.7损失函数和反向传播
5.7.1基本损失函数
本节损失函数包括: L1Loss MSELoss CrossEntropyLoss
import torch
from torch.nn import L1Loss, MSELoss, CrossEntropyLoss
inputs=torch.tensor([1,2,3],dtype=torch.float32)
outputs=torch.tensor([1,2,5],dtype=torch.float32)
inputs=torch.reshape(inputs,(1,1,1,3))
outputs=torch.reshape(outputs,(1,1,1,3))
loss=L1Loss(reduction="sum")
result=loss(inputs,outputs)
loss_mse=MSELoss()
result_mse=loss_mse(inputs,outputs)
print(result)
print(result_mse)
x=torch.tensor([0.1,0.2,0.3])
y=torch.tensor([1])
x=torch.reshape(x,(1,3))
loss_cross=CrossEntropyLoss()
result_cross=loss_cross(x,y)
print(result_cross)5.7.2神经网络模型结合损失函数
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10("./dataset",train=True,download=True,transform=torchvision.transforms.ToTensor())
dataloader=DataLoader(dataset,batch_size=1)
class Jason(nn.Module):
def __init__(self):
super(Jason,self).__init__()
self.moudle1=Sequential(
Conv2d(3,32,kernel_size=5,padding=2),
MaxPool2d(kernel_size=2),
Conv2d(32, 32, kernel_size=5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.moudle1(x)
return x
loss=nn.CrossEntropyLoss()
jason=Jason()
for data in dataloader:
imgs,targets=data
outputs=jason(imgs)
# print(outputs)
#print(targets)
result_loss=loss(outputs,targets)
print(result_loss)
5.7.3反向传播
对于神经网络模型训练的结果,对于该结果可以利用 backward 函数进行梯度计算

5.8优化器
根据每次的梯度变化进行数据优化,使得损失函数越来越小
5.8.1torch.optim.SGD
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset=torchvision.datasets.CIFAR10("./dataset",train=True,download=True,transform=torchvision.transforms.ToTensor())
dataloader=DataLoader(dataset,batch_size=1)
class Jason(nn.Module):
def __init__(self):
super(Jason,self).__init__()
self.moudle1=Sequential(
Conv2d(3,32,kernel_size=5,padding=2),
MaxPool2d(kernel_size=2),
Conv2d(32, 32, kernel_size=5, padding=2),
MaxPool2d(kernel_size=2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.moudle1(x)
return x
jason=Jason()
loss=nn.CrossEntropyLoss()
optim =torch.optim.SGD(jason.parameters(),lr=0.01)
for epoch in range(20):
running_loss=0.0
for data in dataloader:
imgs,targets=data
outputs=jason(imgs)
# print(outputs)
#print(targets)
result_loss=loss(outputs,targets)
#优化置0
optim.zero_grad()
result_loss.backward()
optim.step()
running_loss=running_loss+result_loss
print(running_loss)
6.调用及修改官方模型
6.1vgg16
6.1.1官方模型
import torchvision.datasets
# train_data=torchvision.datasets.ImageNet("./data_image_net",split='train',download=True,transform=torchvision.transforms.ToTensor())
from torch import nn
vgg16_false=torchvision.models.vgg16(pretrained=False)#没有经过训练
vgg16_true=torchvision.models.vgg16(pretrained=True)#经过训练的
print(vgg16_false)
print(vgg16_true)6.1.2修改官方模型
import torchvision.datasets
# train_data=torchvision.datasets.ImageNet("./data_image_net",split='train',download=True,transform=torchvision.transforms.ToTensor())
from torch import nn
vgg16_false=torchvision.models.vgg16(pretrained=False)#没有经过训练
vgg16_true=torchvision.models.vgg16(pretrained=True)#经过训练的
train_data=torchvision.datasets.CIFAR10("./dataset",download=True,transform=torchvision.transforms.ToTensor(),train=True)
#在外面加一层
# vgg16_true.add_module("add_linear",nn.Linear(1000,10))
#在里面加一层
vgg16_true.classifier.add_module("add_linear",nn.Linear(1000,10))
#修改没训练的
vgg16_false.classifier[6]=nn.Linear(4096,10)
print(vgg16_false)
print(vgg16_true)7.保存官方和自定义模型及其使用
7.1保存官方模型
7.1.1方法一
保存模型结构+参数
vgg16=torchvision.models.vgg16(pretrained=False)
#保存方法1 模型结构+参数
torch.save(vgg16,"vgg16-method1.pth")使用模型
#方法1加载
model=torch.load("vgg16-method1.pth")
print(model)7.1.2方法二
保存模型参数
vgg16=torchvision.models.vgg16(pretrained=False)
#保存方法2 参数
torch.save(vgg16.state_dict(),"vgg16-method2.pth")使用模型的参数
model=torch.load("vgg16_method2.pth")
print(model)使用模型的结构+参数
这里相当于把模型的参数送入没被训练的模型结构中
vgg16=torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16-method2.pth"))
print(vgg16)7.2保存自定义模型
保存模型
class Jason(nn.Module):
def __init__(self):
super(Jason, self).__init__()
self.conv1 = Conv2d(3, 64, 5)
def forward(self, x):
x = self.conv1(x)
return x
jason = Jason()
torch.save(jason,"jason_method1.pth")调用模型
注意:要把保存模型的文件导入调用模型中
from model_save import *
model_jason=torch.load("jason_method1.pth")
print(model_jason)8.完整模型训练
总代码:
tarin.py
import torch.optim.optimizer
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import *
#准备数据集
train_data=torchvision.datasets.CIFAR10("./dataset",train=True,download=True,transform=torchvision.transforms.ToTensor())
#准备测试集
test_data=torchvision.datasets.CIFAR10("./dataset",train=False,download=True,transform=torchvision.transforms.ToTensor())
#数据集长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练集的长度{}".format(train_data_size))
print("测试集的长度{}".format(test_data_size))
#利用dataloader加载数据集
train_dataloader=DataLoader(train_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)
#创建网络模型
jason=Jason()
#损失函数
loss_fn=nn.CrossEntropyLoss()
#优化器
learing_rate=1e-2
optimizer=torch.optim.SGD(jason.parameters(),learing_rate)
#设置训练网络的参数
#记录训练的次数
total_train_step=0;
#记录测试的次数
total_test_step=0
#训练的轮数
epoch=10
#添加ensorboard
writer=SummaryWriter("dataloader")
for i in range(epoch):
print("-----第{}轮训练开始-----".format(i+1))
#训练开始
for data in train_dataloader:
imgs,targets=data
#得到训练结果
outputs=jason(imgs)
#得到的结果和真实结果对比
loss=loss_fn(outputs,targets)
#梯度清零
optimizer.zero_grad()
#优化
loss.backward()
optimizer.step()
total_train_step=total_train_step+1
if total_train_step%100==0:
print("训练次数:{},Loss:{}".format(total_train_step,loss))
writer.add_scalar("train_loss",loss.item(),total_train_step)
#测试步骤
total_test_loss=0#总损失
total_accuracy=0#整体准确率
# 不需要梯度
with torch.no_grad():
for data in test_dataloader:
imgs,targets=data
outputs=jason(imgs)
loss=loss_fn(outputs,targets)
#加item是使输出更简洁
total_test_loss=total_test_loss+loss.item()
accuracy=(outputs.argmax(1)==targets).sum()
total_accuracy=total_accuracy+accuracy
print("整体测试集的Loss{}".format(total_test_loss))
print("整体测试集的准确率{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step=total_test_step+1
#模型按照epoch步骤保存
torch.save(jason,"jason_{}.pth".format(i))
print("模型已经保存")
writer.close()
model.py
#搭建网络
import torch
from torch import nn
class Jason(nn.Module):
def __init__(self):
super(Jason,self).__init__()
self.model=nn.Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024,64),
nn.Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x
if __name__ == '__main__':
jason=Jason()
input=torch.ones((64,3,32,32))
output=jason(input)
print(output.shape)
8.1训练模型
8.1.1数据集准备
#准备数据集
train_data=torchvision.datasets.CIFAR10("./dataset",train=True,download=True,transform=torchvision.transforms.ToTensor())
#准备测试集
test_data=torchvision.datasets.CIFAR10("./dataset",train=False,download=True,transform=torchvision.transforms.ToTensor())8.1.2数据集提取准备
#利用dataloader加载数据集
train_dataloader=DataLoader(train_data,batch_size=64)
test_dataloader=DataLoader(test_data,batch_size=64)8.1.3网络模型准备
#创建网络模型
jason=Jason()
#############################下面部分在另外一个py文件
#搭建网络
import torch
from torch import nn
class Jason(nn.Module):
def __init__(self):
super(Jason,self).__init__()
self.model=nn.Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024,64),
nn.Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x
if __name__ == '__main__':
jason=Jason()
input=torch.ones((64,3,32,32))
output=jason(input)
print(output.shape)
8.1.4损失函数准备
#损失函数
loss_fn=nn.CrossEntropyLoss()
8.1.5优化器准备
#优化器
learing_rate=1e-2
optimizer=torch.optim.SGD(jason.parameters(),learing_rate)8.1.6网络训练参数准备
#设置训练网络的参数
#记录训练的次数
total_train_step=0;
#记录测试的次数
total_test_step=0
#训练的轮数
epoch=108.1.7开始训练
for i in range(epoch):
print("-----第{}轮训练开始-----".format(i+1))
#训练开始
for data in train_dataloader:
imgs,targets=data
#得到训练结果
outputs=jason(imgs)
#得到的结果和真实结果对比
loss=loss_fn(outputs,targets)
#梯度清零
optimizer.zero_grad()
#优化
loss.backward()
optimizer.step()
total_train_step=total_train_step+1
print("训练次数:{},Loss:{}".format(total_train_step,loss))8.2测试模型
8.2.1总loss测试
#测试步骤
total_test_loss=0#总损失
# 不需要梯度
with torch.no_grad():
for data in test_dataloader:
imgs,targets=data
outputs=jason(imgs)
loss=loss_fn(outputs,targets)
#加item是使输出更简洁
total_test_loss=total_test_loss+loss.item()
print("整体测试集的Loss{}".format(total_test_loss))8.2.2总准确率测试
#测试步骤
total_accuracy=0#整体准确率
# 不需要梯度
with torch.no_grad():
for data in test_dataloader:
imgs,targets=data
outputs=jason(imgs)
#加item是使输出更简洁
accuracy=(outputs.argmax(1)==targets).sum()
total_accuracy=total_accuracy+accuracy
print("整体测试集的准确率{}".format(total_accuracy/test_data_size))8.2.3添加到tensorboard
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)
total_test_step=total_test_step+18.2.4保存模型
#模型按照epoch步骤保存
torch.save(jason,"jason_{}.pth".format(i))
print("模型已经保存")8.3注意事项
8.3.1网络模型模式
设置网络模型为训练模型

设置网络模型为测试模型

9.利用GPU训练模型
9.1方法一
通过修改如下参数即可进行GPU训练

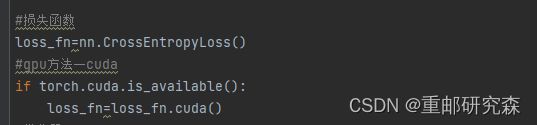
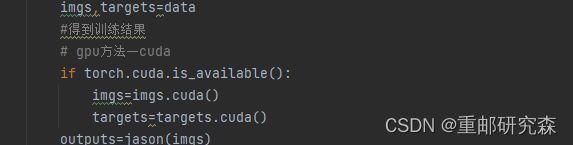
9.2方法二
通过to选择device来使用gpu
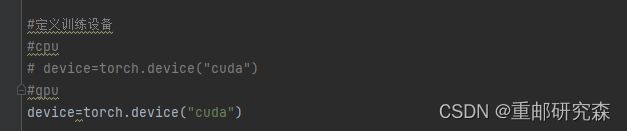



10.完整模型测试
对于上部分我们训练好的模型,我们现在想对自己的一个图片进行判断看到底能不能识别是“狗”。
10.1准备数据和模型
10.1.1准备数据
注意事项:注意图片通道数,这里转成了三通道,以及图片类型为PIL->tensor
image_path="./picture/dog.png"
image=Image.open(image_path)
image=image.convert('RGB')
print(image)
transform=torchvision.transforms.Compose( [torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
image=transform(image)
image=image.cuda()
print(image.shape)10.1.2准备模型
class Jason(nn.Module):
def __init__(self):
super(Jason,self).__init__()
self.model=nn.Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024,64),
nn.Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x
model=torch.load("jason_8.pth")
print(model)10.2验证
image=torch.reshape(image,(1,3,32,32))
model.eval()
with torch.no_grad():
image = image.cuda()
output = model(image)
print(output)
print(output.argmax(1))