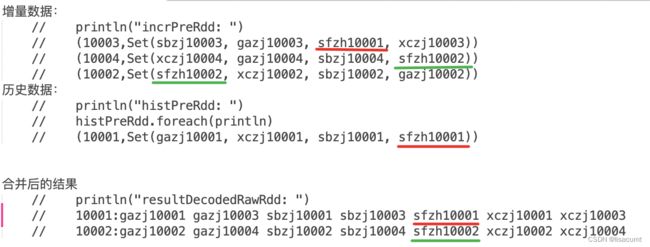
spark-单条记录含有多个号码的人员信息,把有交集号码的合并。
实现具体功能,如下图:
合并前的增量和历史数据有红色一对,和绿色一对 的号码是相同的。
因此可以认定,id是 10001 和 10003 是同一人。10002和10004是同一人。
最终取较小的id作为人员id,分别是合并结果集中的10001 和 10002。两个最后合并后的人员均有7个(8-1)各号码。
(一)读取数据
具体读取数据库的代码需要自行取消注释(默认是本地测试状态)。
DatabaseToFilesystem.scala
import com.test.utils.{Constants, LocalFileUtils, PropertyUtil, StringUtil}
import org.apache.hadoop.io.compress.GzipCodec
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import java.io.File
import java.util.Properties
import scala.collection.mutable
import scala.collection.mutable.Set
/**
* 读取数据库的数据,把结果放到hdfs(如果使用本地测试则放置在项目目录下)的目录中
* 生成forMerge目录
* id:号码1 证件2 号码3 ...
* idea本地调试参数:conf/test.properties tmp_data/preProcess/
*/
object DatabaseToFilesystem {
def main(args: Array[String]): Unit = {
val textFilePath = args(0)
val hdfsPath = args(1)
val properties = PropertyUtil.getProperties(textFilePath)
val jdbcProps = new Properties()
jdbcProps.put("url", properties.getProperty("url"))
jdbcProps.put("driver", properties.getProperty("driver"))
jdbcProps.put("user", properties.getProperty("user"))
jdbcProps.put("password", properties.getProperty("password"))
val sparkConf = new SparkConf()
/**
* 生产环境使用
*/
// val spark = SparkSession.builder().appName("Preprocess").enableHiveSupport().config(sparkConf).getOrCreate()
// 测试需要在run configuration 添加参数:conf/test.properties tmp_data/preprocess
// 分区表使用,用于加快数据读取
val predicates =
Array(
"19900101" -> "20050101",
"20050101" -> "20060101",
"20060101" -> "20070101",
"20070101" -> "20080101",
"20080101" -> "20090101",
"20090101" -> "20100101",
"20100101" -> "20110101",
"20110101" -> "20120101",
"20120101" -> "20130101",
"20130101" -> "20140101",
"20140101" -> "20150101",
"20150101" -> "20160101",
"20160101" -> "20170101",
"20170101" -> "20180101",
"20180101" -> "20190101",
"20190101" -> "20200101",
"20200101" -> "20210101",
"20210101" -> "20220101",
"20220101" -> "20230101",
"20230101" -> "20240101",
"20240101" -> "20250101",
"20250101" -> "20260101",
"20260101" -> "20270101",
"20270101" -> "20280101",
"20280101" -> "20290101",
"20290101" -> "20300101",
"20300101" -> "20310101",
"20310101" -> "20320101",
"20320101" -> "20330101",
"20330101" -> "20340101",
"20340101" -> "20350101",
"20350101" -> "20360101",
"20360101" -> "20370101",
"20370101" -> "20380101",
"20380101" -> "20390101",
"20390101" -> "20400101",
"20400101" -> "20410101",
"20410101" -> "20420101",
"20420101" -> "20430101",
"20430101" -> "20440101",
"20440101" -> "20450101",
"20450101" -> "20460101",
"20460101" -> "20470101",
"20470101" -> "20480101",
"20480101" -> "20490101",
"20490101" -> "20500101"
).map {
case (start, end) =>
s"slrq >= '$start'::date AND slrq < '$end'::date"
}
/**
* 生产环境读取数据库
*
*/
/*
val increaseRdd: RDD[(String, mutable.Set[String])]
= spark.read.jdbc(jdbcProps.getProperty("url"), tableName, predicates, jdbcProps).rdd.map(r => {
val recordId = getStrDefault(r.getAs[String]("mr_id_sq"))
val sfzh = getStrDefault(r.getAs[String]("sfzjxx"))
val gazj = getStrDefault(r.getAs[String]("gazjxx"))
val xczj = getStrDefault(r.getAs[String]("xczjxx"))
var sbzj = getStrDefault(r.getAs[String]("sbzjxx"))
val set = Set(sfzh, gazj, xczj, sbzj).filter(StringUtil.isNotNull(_))
(recordId, set)
}).filter(x => x._2 != null && !x._2.isEmpty).repartition(10).cache()
*/
/**
* 测试环境使用
*/
val spark = SparkSession.builder().appName("Preprocess").master("local[*]").config(sparkConf).getOrCreate()
val tableName = properties.getProperty("tableName")
/**
* 以下是测试代码
* 手动生成数据
*/
val sc = spark.sparkContext
val resultPath = "tmp_data/result/history"
LocalFileUtils.deleteDir(new File(resultPath))
// 测试代码:初始化历史的内容-begin
val histroyList = List(
("10001", Set("sfzh10001", "gazj10001", "xczj10001", "sbzj10001"))
)
val historyRdd = sc.makeRDD(histroyList)
println("historyRdd: ")
historyRdd.foreach(println)
historyRdd.map(ele => {
val id = ele._1
val hmString = ele._2.toList.sorted.mkString(" ")
id + ":" + hmString
})
.saveAsTextFile(resultPath, classOf[GzipCodec])
// 测试代码:初始化历史的内容-end
LocalFileUtils.deleteDir(new File(hdfsPath))
val increaseList = List(
("10002", Set("sfzh10002", "gazj10002", "xczj10002", "sbzj10002"))
, ("10003", Set("sfzh10001", "gazj10003", "xczj10003", "sbzj10003"))
, ("10004", Set("sfzh10002", "gazj10004", "xczj10004", "sbzj10004"))
)
val increaseRdd = sc.makeRDD(increaseList) // 测试代码
println("increaseRdd: ")
increaseRdd.foreach(println)
increaseRdd.map(ele => {
val id = ele._1
val hmSet = ele._2
// 替换掉字符串中的空格
val regStr = "\\s"
val hmString = hmSet.map(hm => hm.replaceAll(regStr, "")).toList.sorted.mkString(" ")
id + ":" + hmString
})
// .saveAsTextFile(hdfsPath + "/merge", classOf[GzipCodec]);
.saveAsTextFile(hdfsPath + "/forMerge", classOf[GzipCodec]); // 测试代码
}
def getStrDefault(str: String): String = {
if (str == null) null else str
}
}
(二)id聚合主程序
IDsMergeFunc.scala - 合并程序功能类
import com.test.utils.{Constants, LocalFileUtils, MD5Util, StringsRandom}
import org.apache.hadoop.io.compress.GzipCodec
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import java.util
import java.util.StringTokenizer
import scala.collection.mutable
import scala.collection.mutable.{ArrayBuffer, ListBuffer, Set}
class IDsMergeFunc {
/* def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setMaster("local[*]").setAppName("IDsMergeTesting")); // 测试代码
sc.setLogLevel("WARN")
}*/
/**
* 将 ID:号码1 号码2 号码3 ... 格式的数据解析成为RDD[String]): RDD[(String, mutable.Set[String])]的格式
*
* @param lineRdd
* @return
*/
def parseTextLine(lineRdd: RDD[String]): RDD[(String, mutable.Set[String])] = {
lineRdd.map(line => {
val lineArr = line.split(":")
val id = lineArr(0)
val hmsStr = lineArr(1)
val hmsSet = new mutable.HashSet[String]()
val st = new StringTokenizer(hmsStr)
while (st.hasMoreTokens) {
hmsSet += st.nextToken()
}
(id, hmsSet)
})
}
/**
* 将 号码 信息编码成为数字信息,见减小数据计算时候的内存占用量
*
* @param lineRdd 需要编码的rdd
* @param defaultParallelism 并行度
* @param idmergeOutput 数据输出根目录
* @param threshould 阈值,用于过滤掉太长(异常的)的数据
*/
def encodeIds(lineRdd: RDD[(String, (mutable.Set[String], String))], defaultParallelism: Int, idmergeOutput: String, threshould: Int): Unit = {
val lineEncodingPath = idmergeOutput + "lineEncoded"
val hmEncodingPath = idmergeOutput + "hmEncoded"
// lineRdd.foreach(println)
val hmRdd: RDD[String] =
lineRdd.map(ele => {
val hmList = ele._2._1.toList
hmList
}).filter(hmList => hmList.length < threshould /*&& arr.length >1*/).flatMap(x => x)
.repartition(defaultParallelism)
.persist(StorageLevel.MEMORY_AND_DISK_SER);
// println("data-flatmap: ")
// data.flatMap(ele=>ele).zipWithIndex().sortBy(x=>x._2,ascending = true,numPartitions = 1).foreach(println)
val hnEncodingRdd = hmRdd.distinct()
.zipWithIndex()
.repartition(defaultParallelism)
.persist(StorageLevel.MEMORY_AND_DISK_SER);
hnEncodingRdd.map {
case (hm, code) =>
s"$hm ${code.toInt}";
}.saveAsTextFile(hmEncodingPath, classOf[GzipCodec]);
val hmIdPair: RDD[(String, (String, String))] =
lineRdd.flatMap(ele => {
val id = ele._1
val hmSet = ele._2._1
val bz = ele._2._2
val res = new mutable.ListBuffer[(String, (String, String))]
for (hm <- hmSet) {
res.append((hm, (id, bz)))
}
res
}).partitionBy(new HashPartitioner(defaultParallelism))
hmIdPair.join(hnEncodingRdd).map(e => {
val hm = e._1
val id = e._2._1._1
val bz = e._2._1._2
val idbz = id + "|" + bz
val hmEncoding = e._2._2
(idbz, hmEncoding)
}).groupByKey(defaultParallelism)
.map { case (idbz, hmArr) =>
idbz ++ ":" ++ hmArr.toList.sorted.mkString(" ")
}
.saveAsTextFile(lineEncodingPath, classOf[GzipCodec]);
}
/**
* 用于将 ID:编码号码1 编码号码2 编码号码3 ... 转化为 ID:号码1 号码2 号码3 ...
*
* @param idHmEncodedRawRdd id和编码号码的的rdd
* @param hmEncodedRawRdd 号码和编码号码的rdd
* @param defaultParallelism 并行度
* @param idmergeResultOutput 数据根目录
* @param threshould 阈值
*/
def decodeIds(idHmEncodedRawRdd: RDD[(String, mutable.Set[String])]
, hmEncodedRawRdd: RDD[(String, String)]
, defaultParallelism: Int, idmergeResultOutput: String, threshould: Int): Unit = {
val idHmEncodedFlatRdd: RDD[(String, String)] =
idHmEncodedRawRdd
.flatMap(ele => {
val id = ele._1
val hmEncodedSet = ele._2
val tmpArr = new ArrayBuffer[(String, String)]()
for (hmEncoded <- hmEncodedSet) {
tmpArr.append((hmEncoded, id))
}
tmpArr
})
.partitionBy(new HashPartitioner(defaultParallelism))
.persist(StorageLevel.MEMORY_AND_DISK_SER);
// println("idHmEncodedFlatRdd: ")
// idHmEncodedFlatRdd.sortBy(x => (x._2, x._1), ascending = true, numPartitions = 1).foreach(println)
val hmEncoderPreRdd: RDD[(String, String)] =
hmEncodedRawRdd
.map(ele => {
val hm = ele._1
val hmEncoded = ele._2
(hmEncoded, hm)
})
.partitionBy(new HashPartitioner(defaultParallelism))
.persist(StorageLevel.MEMORY_AND_DISK_SER);
// println("hmEncoderPreRdd: ")
// hmEncoderPreRdd.foreach(println)
val rdd = idHmEncodedFlatRdd.join(hmEncoderPreRdd)
.map(ele => {
val id = ele._2._1
val hm = ele._2._2
// 此处转为含有单个号码的Set方便下一步进行聚合的,取集合的合集
(id, Set(hm))
})
rdd.reduceByKey(_ ++ _)
.filter(ele => {
val hmSet = ele._2
hmSet.size < threshould
})
.map(ele => {
val id = ele._1
val hmSet = ele._2.toList.sorted
val idsSB = new StringBuilder();
val hmString = hmSet.mkString(" ")
val line = id + ":" + hmString
line
})
// .foreach(println)
.saveAsTextFile(idmergeResultOutput + "new/", classOf[GzipCodec]);
}
/**
* 历史和新增合并后并添加标志 "i"-新增的 或者 "h"-历史的
*
* @param historyLine 历史的已生成的id和号码的数据
* @param increaseLine 需要新增计算的id和号码的数据
* @param defaultParallelism 并行度
* @return 历史和新增合并后的rdd(注意此处并不祛重,不涉及shuffer)
*/
def idsMix(historyLine: RDD[(String, mutable.Set[String])], increaseLine: RDD[(String, mutable.Set[String])]
, defaultParallelism: Int): RDD[(String, (mutable.Set[String], String))] = {
var hisLine: RDD[(String, (mutable.Set[String], String))] = null
var incLine: RDD[(String, (mutable.Set[String], String))] = null
if (historyLine != null && !historyLine.isEmpty()) {
hisLine = historyLine.map(ele => {
val id = ele._1
val hmSet = ele._2
val bz = "h"
(id, (hmSet, bz))
})
}
if (increaseLine != null || !increaseLine.isEmpty()) {
incLine = increaseLine.map(ele => {
val id = ele._1
val hmSet = ele._2
val bz = "i"
(id, (hmSet, bz))
})
}
// ready to encode hm information
val preRdd: RDD[(String, (mutable.Set[String], String))] =
hisLine.union(incLine).repartition(defaultParallelism)
preRdd
}
/**
* 主计算过程
*
* @param mixRdd 混合的数据(含历史的和新增的)
* @param IDsMergeOutput 结果输出根路径
* @param defaultParallelism 并行度
* @param threshold 阈值
*/
def idsMerge(mixRdd: RDD[(String, (mutable.Set[String], String))]
, IDsMergeOutput: String, defaultParallelism: Int, threshold: Int) {
val IDsMergeOutputPath = IDsMergeOutput + "loop"
val idFlatRddInit: RDD[(String, (mutable.Set[String], String, Int, String))] =
mixRdd.flatMap(ele => {
val id = ele._1
val bz = ele._2._2
val hmSet = ele._2._1
val tmpList = new ListBuffer[(String, (mutable.Set[String], String, Int, String))]
for (hm <- hmSet) {
tmpList.append((hm, (hmSet, id, 0, bz)))
}
tmpList
}).repartition(defaultParallelism)
var idFlatRdd = idFlatRddInit;
var loopCount = 0;
while (true) {
// pre_rdd:RDD[(String, (mutable.Set[String], Int, String))]
// 聚合计算,并生成聚合次数。
idFlatRdd = idFlatRdd
.reduceByKey((x, y) => {
// 两个set 相互聚合
val xyset = x._1.union(y._1);
val xySize = xyset.size;
val xSize = x._1.size;
val ySize = y._1.size;
var id = ""
var bz = ""
if ("i".equals(x._4) && "i".equals(y._4)) {
// 前后两条都代表(不一定是)增量数据,历史数据的id取较小者
id = if (x._2 > y._2) y._2 else x._2
bz = "i"
} else if ("i".equals(x._4) && "h".equals(y._4)) {
// x代表增量数据,y是历史数据。有历史数据的id 优先使用历史数据id
id = y._2
bz = "h"
} else if ("h".equals(x._4) && "i".equals(y._4)) {
// x代表历史数据,y是增量数据。有历史数据的id 优先使用历史数据id
id = x._2
bz = "h"
} else if ("h".equals(x._4) && "h".equals(y._4)) {
// 前后两条都代表(不一定是)历史数据,历史数据的id取较小者(遗留:这里会造成已经生成的Id消失的问题!!!)
id = if (x._2 > y._2) y._2 else x._2
bz = "h"
}
if (xySize.equals(xSize) || xySize.equals(ySize)) {
(xyset, id, Math.max(x._3, y._3), bz)
} else {
(xyset, id, Math.min(x._3, y._3) + 1, bz)
}
})
.cache();
// idsFlat.sortBy(x=>x._1,ascending = true,numPartitions = 1).foreach(println)
// 对于循环次数超过聚合次数的情况,说明数据已经聚合完毕,需要落到磁盘。
idFlatRdd
// .sortBy(x=>x._1,ascending = true,numPartitions = 1)
.filter(f => {
val mergeTimes = f._2._3
(mergeTimes + 1).equals(loopCount) && f._2._1.size <= threshold;
})
.map(xo => {
val id = xo._2._2
val idList = xo._2._1.toList.sorted.mkString(" ")
id + ":" + idList
}).distinct()
// .sortBy(x=>x._1,ascending = true,numPartitions = 1).foreach(x=>println(loopCount+" -> "+x))
.saveAsTextFile(IDsMergeOutput + f"loop-$loopCount%3d".replaceAll(" ", "0"), classOf[GzipCodec]);
// 对于还需要继续进行聚合的数据需要进行裂变。
idFlatRdd = idFlatRdd
.filter(ele => {
val mergeTimes = ele._2._3
(mergeTimes + 1 >= loopCount) && ele._2._1.size < threshold
}).flatMap(ele => {
val arr = new ArrayBuffer[(String, (mutable.Set[String], String, Int, String))]()
val hmSet = ele._2._1
val id = ele._2._2
val mergeTimes = ele._2._3
val bz = ele._2._4
hmSet.foreach(hm => {
arr.append((hm, (hmSet, id, mergeTimes, bz)))
})
arr
})
// println("final idsFlat.length: "+idsFlat.collect().length)
// idsFlat.sortBy(x=>(x._2._1.toString(),x._1),ascending = true,numPartitions = 1).foreach(x=>println(loopCount+" -> "+x))
loopCount = loopCount + 1;
if (idFlatRdd.isEmpty()) {
// 退出条件
return
}
}
}
}IDsMergeEntry.scala - 合并程序入口类
import com.test.utils.{Constants, LocalFileUtils}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
import com.test.IDsMergeInOne.IDsMergeFunc
import java.io.File
import java.util.StringTokenizer
import scala.collection.mutable
/**
* 把有相同证件id的多条数据融合为1条数据,最终生成的数据在hdfs的new目录下
* 生成数据格式 证件id1+空格+证件id2+....
* idea本地调试参数:tmp_data/preProcess/ tmp_data/merge/ tmp_data/result/ 10
*/
object IDsMergeEntry {
def main(args: Array[String]): Unit = {
val incrPath = args(0)
val idsMergeOutputParent = args(1)
val resultPathParent = args(2)
val threshold = args(3).toInt
val incrFiles = incrPath + "forMerge/*.gz"
val histFiles = resultPathParent + "history/*.gz"
val newFiles=resultPathParent+"new/"
// val sc = new SparkContext( new SparkConf().setAppName("IDsMerge"));
// 测试需要在run configuration
// 添加参数:tmp_data/preprocess/forMerge/*.gz tmp_data/result/history/*.gz tmp_data/merge/ 10
val sc = new SparkContext(new SparkConf().setMaster("local[*]").setAppName("IDsMerge")); // 测试代码
sc.setLogLevel("WARN")
LocalFileUtils.deleteDir(new File(idsMergeOutputParent))
LocalFileUtils.deleteDir(new File(newFiles))
val defaultParallelism = sc.defaultParallelism
val worker = new IDsMergeFunc();
val incrSrcRdd: RDD[String] = sc.textFile(incrFiles)
val incrPreRdd: RDD[(String, mutable.Set[String])] = worker.parseTextLine(incrSrcRdd)
// println("incrPreRdd: ")
// incrPreRdd.foreach(println)
// (10003,Set(sbzj10003, gazj10003, sfzh10001, xczj10003))
// (10004,Set(xczj10004, gazj10004, sbzj10004, sfzh10002))
// (10002,Set(sfzh10002, xczj10002, sbzj10002, gazj10002))
val histSrcRdd: RDD[String] = sc.textFile(histFiles)
val histPreRdd: RDD[(String, mutable.Set[String])] = worker.parseTextLine(histSrcRdd)
// println("histPreRdd: ")
// histPreRdd.foreach(println)
// (10001,Set(gazj10001, xczj10001, sbzj10001, sfzh10001))
val mixRdd: RDD[(String, (mutable.Set[String], String))] =
worker.idsMix(histPreRdd, incrPreRdd, defaultParallelism)
worker.encodeIds(mixRdd, sc.defaultParallelism, idsMergeOutputParent, threshold);
val lineEncodedRawRdd: RDD[String] = sc.textFile(idsMergeOutputParent + "lineEncoded/*.gz")
// println("lineEncodedRawRdd: ")
// lineEncodedRawRdd.foreach(println)
// 10002|i:1 4 6 10
// 10004|i:6 7 9 12
// 10003|i:2 3 5 11
// 10001|h:0 2 8 13
val lineEncodedPreRdd = worker.parseTextLine(lineEncodedRawRdd).map(line => {
val idbz = line._1
val idbzArr = idbz.split("\\|")
val id = idbzArr(0)
val bz = idbzArr(1)
val hmEncodedSet = line._2
(id, (hmEncodedSet, bz))
})
// println("lineEncodedPreRdd: ")
// lineEncodedPreRdd.sortBy(ele => ele._1, ascending = true, numPartitions = 1).foreach(println)
// (10001,(Set(0, 8, 2, 13),h))
// (10002,(Set(4, 1, 10, 6),i))
// (10003,(Set(3, 5, 2, 11),i))
// (10004,(Set(9, 6, 7, 12),i))
val hmEncodingRawRdd = sc.textFile(idsMergeOutputParent + "hmEncoded/*.gz");
val hmEncodingPreRdd = hmEncodingRawRdd.map(line => {
val lineArr = line.split(" ")
val hm = lineArr(0)
val hmEncoded = lineArr(1)
(hm, hmEncoded)
})
// println("hmEncodingPreRdd: ")
// hmEncodingPreRdd.sortBy(ele => ele._2.toInt, ascending = true, numPartitions = 1).foreach(println)
// (gazj10001,0)
// (xczj10002,1)
// (sfzh10001,2)
// (xczj10003,3)
// (gazj10002,4)
// (gazj10003,5)
// (sfzh10002,6)
// (xczj10004,7)
// (sbzj10001,8)
// (gazj10004,9)
// (sbzj10002,10)
// (sbzj10003,11)
// (sbzj10004,12)
// (xczj10001,13)
worker.idsMerge(lineEncodedPreRdd, idsMergeOutputParent + "resultEncoded/", defaultParallelism, threshold);
val resultEncodedRawRdd = sc.textFile(idsMergeOutputParent + "resultEncoded/*/*.gz");
val resultEncodedPreRdd = worker.parseTextLine(resultEncodedRawRdd)
// println("resultEncodedPreRdd: ")
// resultEncodedPreRdd.sortBy(line=>line._1).foreach(println)
// (10001,Set(3, 0, 8, 5, 2, 13, 11))
// (10002,Set(4, 1, 10, 9, 6, 7, 12))
worker.decodeIds(resultEncodedPreRdd, hmEncodingPreRdd, defaultParallelism, resultPathParent, threshold)
// val resultDecodingRawRdd = sc.textFile(idsMergeOutputParent + "resultDecoded/*.gz");
// println("resultDecodedRawRdd: ")
// resultDecodingRawRdd.sortBy(line=>line.split(":")(0),ascending = true,numPartitions = 1).foreach(println)
// 10001:gazj10001 gazj10003 sbzj10001 sbzj10003 sfzh10001 xczj10001 xczj10003
// 10002:gazj10002 gazj10004 sbzj10002 sbzj10004 sfzh10002 xczj10002 xczj10004
sc.stop
}
}(三)数据写回数据库
具体写回数据库的代码需要自行取消注释(默认是本地测试状态)。
FilesystemToDatabase.scala
import com.test.utils.{Constants, JDBCUtil, PropertyUtil, StringUtil}
import org.apache.hadoop.io.compress.GzipCodec
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
/**
* 把IDsMergeEntry生成的数据写入数据库表中
* idea本地调试参数:conf/test.properties tmp_data/result/
*/
object FilesystemToDatabase {
def main(args: Array[String]): Unit = {
println("args====" + args.mkString(","))
val jdbcConfigPath=args(0)
val resultPath = args(1)
val resultFile=resultPath+"new/*.gz"
val properties = PropertyUtil.getProperties(jdbcConfigPath)
println("properties====" + properties)
// val spark = SparkSession.builder().config(new SparkConf().setAppName("HdfsToGauss")).enableHiveSupport().getOrCreate()
val spark = SparkSession.builder().master("local[*]").config(new SparkConf().setAppName("HdfsToDatabase")).getOrCreate() // 测试
val sc = spark.sparkContext
import spark.implicits._
val resultDF: DataFrame = sc.textFile(resultFile)
.flatMap(ele => {
val arr = ele.split(":")
val id = arr(0)
val hmListStr = arr(1)
hmListStr.split(" ").map(hm => {
(id, hm.trim)
})
}).toDF("id", "hm")
// resultDF.show()
// +-----+---------+
// | id| hm|
// +-----+---------+
// |10001|gazj10001|
// |10001|gazj10003|
// |10001|sbzj10001|
// |10001|sbzj10003|
// |10001|sfzh10001|
// |10001|xczj10001|
// |10001|xczj10003|
// |10002|gazj10002|
// |10002|gazj10004|
// |10002|sbzj10002|
// |10002|sbzj10004|
// |10002|sfzh10002|
// |10002|xczj10002|
// |10002|xczj10004|
// +-----+---------+
// 写入数据库
/* resultDF.write.format("jdbc").mode(SaveMode.Overwrite)
.option("driver",properties.getProperty("driver"))
.option("url", properties.getProperty("url"))
.option("dbtable","newimportdata.ryxx_mx")
.option("user", properties.getProperty("user"))
.option("password", properties.getProperty("password"))
.option("batchsize",4000)
.save()*/
sc.stop
}
}
项目目录结构
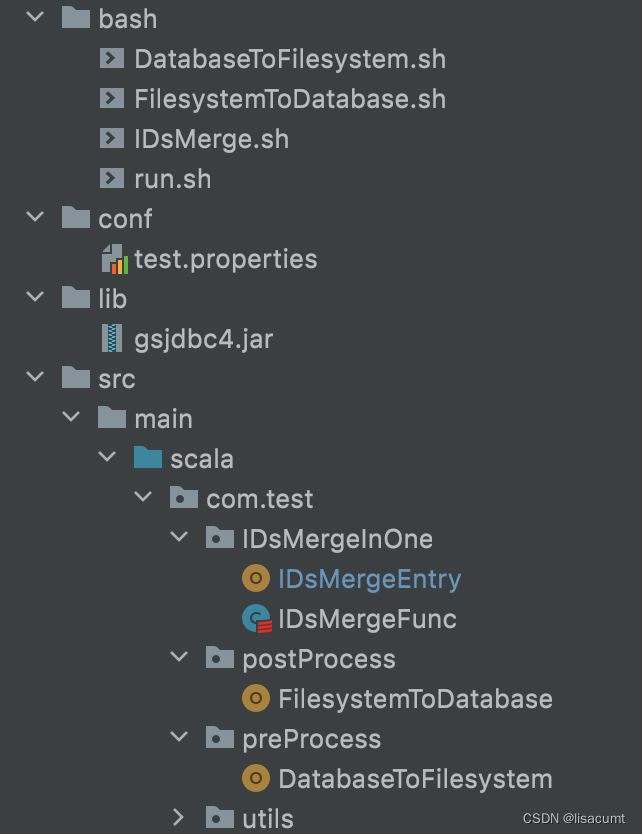
数据存储结构目录

本项目github地址:
GitHub - lschampion/IdsMerge-adv: merge ids