Flink sql 1.17笔记
环境准备
# 启动hadoop集群
# 启动Flink yarn session
(base) [link999@hadoop102 flink-1.17.0]$ bin/yarn-session.sh -d
# 启动finksql客户端
(base) [link999@hadoop102 flink-1.17.0]$ bin/sql-client.sh -s yarn-session
# 如果有初始化文件
bin/sql-client.sh embedded -s yarn-session -i conf/sql-client-init.sql
- 检查State是RUNNING 后启用Flink sql客户端

常用配置
结果显示模式
#默认table,还可以设置为tableau、changelog
SET sql-client.execution.result-mode=tableau;
执行环境
SET execution.runtime-mode=streaming; #默认streaming,也可以设置batch
默认并行度
SET parallelism.default=1;
设置状态TTL
SET table.exec.state.ttl=1000;
通过sql文件初始化
(1)创建sql文件
vim conf/sql-client-init.sql
SET sql-client.execution.result-mode=tableau;
CREATE DATABASE mydatabase;
(2)启动时,指定sql文件
/opt/module/flink-1.17.0/bin/sql-client.sh embedded -s yarn-session -i conf/sql-client-init.sql
- 初始化文件
SET sql-client.execution.result-mode=tableau;
create DATABASE db_flink;
use db_flink;
CREATE TABLE source (
id INT,
ts BIGINT,
vc INT
) WITH (
'connector' = 'datagen',
'rows-per-second'='1',
'fields.id.kind'='random',
'fields.id.min'='1',
'fields.id.max'='10',
'fields.ts.kind'='sequence',
'fields.ts.start'='1',
'fields.ts.end'='1000',
'fields.vc.kind'='random',
'fields.vc.min'='2',
'fields.vc.max'='100'
);
CREATE TABLE sink (
id INT,
ts BIGINT,
vc INT
) WITH (
'connector' = 'print'
);
流处理中的表
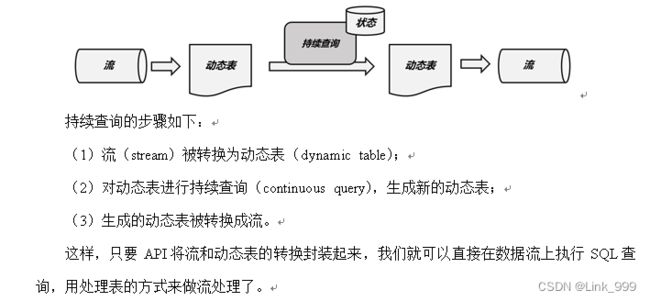
将动态表转为流
- 仅追加流
- 撤回流(先删再插)
- 更新流
时间属性
- 事件时间

ts TIMESTAMP(3),
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND
时间戳类型必须是 TIMESTAMP 或者TIMESTAMP_LTZ 类型。但是时间戳一般都是秒或者是毫秒(BIGINT 类型),这种情况可以通过如下方式转换
ts BIGINT,
time_ltz AS TO_TIMESTAMP_LTZ(ts, 3),
- 处理时间
- 在定义处理时间属性时,必须要额外声明一个字段,专门用来保存当前的处理时间。
在创建表的DDL(CREATE TABLE语句)中,可以增加一个额外的字段,通过调用系统内置的PROCTIME()函数来指定当前的处理时间属性。
CREATE TABLE EventTable(
user STRING,
url STRING,
ts AS PROCTIME()
) WITH (
...
);
数据库相关操作
1)创建数据库
(1)语法
CREATE DATABASE [IF NOT EXISTS] [catalog_name.]db_name
[COMMENT database_comment]
WITH (key1=val1, key2=val2, ...)
(2)案例
CREATE DATABASE db_flink;
2)查询数据库
(1)查询所有数据库
SHOW DATABASES
(2)查询当前数据库
SHOW CURRENT DATABASE
3)修改数据库
ALTER DATABASE [catalog_name.]db_name SET (key1=val1, key2=val2, ...)
4)删除数据库
DROP DATABASE [IF EXISTS] [catalog_name.]db_name [ (RESTRICT | CASCADE) ]
RESTRICT:删除非空数据库会触发异常。默认启用
CASCADE:删除非空数据库也会删除所有相关的表和函数。
DROP DATABASE db_flink2;
5)切换当前数据库
USE database_name;
表相关操作
创建表 语法
CREATE TABLE [IF NOT EXISTS] [catalog_name.][db_name.]table_name
(
{ | | }[ , ...n]
[ ]
[ ][ , ...n]
)
[COMMENT table_comment]
[PARTITIONED BY (partition_column_name1, partition_column_name2, ...)]
WITH (key1=val1, key2=val2, ...)
[ LIKE source_table [( )] | AS select_query ]
- 创建简单表,在控制台输出
CREATE table test(
id int,
ts bigint,
vc int
) with ('connector' = 'print');
- 元数据列
'recore_time' timestamp_ltz(3) metadata from 'timestamp'
如果自定义的列名称和 Connector 中定义 metadata 字段的名称一样, FROM xxx 子句可省略
`timestamp` TIMESTAMP_LTZ(3) METADATA
可以使用VIRTUAL关键字排除元数据列的持久化(表示只读)。
`offset` BIGINT METADATA VIRTUAL,
- 计算列
`cost` AS price * quanitity
- watermark
有界无序: WATERMARK FOR rowtime_column AS rowtime_column – INTERVAL ‘string’ timeUnit 。
- 其他方式创建表
CREATE TABLE Orders (
`user` BIGINT,
product STRING,
order_time TIMESTAMP(3)
) WITH (
'connector' = 'kafka',
'scan.startup.mode' = 'earliest-offset'
);
CREATE TABLE Orders_with_watermark (
-- Add watermark definition
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) WITH (
-- Overwrite the startup-mode
'scan.startup.mode' = 'latest-offset'
)
LIKE Orders;
查询表
查看表
(1)查看所有表
SHOW TABLES [ ( FROM | IN ) [catalog_name.]database_name ] [ [NOT] LIKE <sql_like_pattern> ]
如果没有指定数据库,则从当前数据库返回表。
LIKE子句中sql pattern的语法与MySQL方言的语法相同:
%匹配任意数量的字符,甚至零字符,\%匹配一个'%'字符。
_只匹配一个字符,\_只匹配一个'_'字符
(2)查看表信息
{ DESCRIBE | DESC } [catalog_name.][db_name.]table_name
3)修改表
(1)修改表名
ALTER TABLE [catalog_name.][db_name.]table_name RENAME TO new_table_name
(2)修改表属性
ALTER TABLE [catalog_name.][db_name.]table_name SET (key1=val1, key2=val2, ...)
4)删除表
DROP [TEMPORARY] TABLE [IF EXISTS] [catalog_name.][db_name.]table_name
查询
自动化生成数据
1)创建数据生成器源表
CREATE TABLE source (
id INT,
ts BIGINT,
vc INT
) WITH (
'connector' = 'datagen',
'rows-per-second'='1',
'fields.id.kind'='random',
'fields.id.min'='1',
'fields.id.max'='10',
'fields.ts.kind'='sequence',
'fields.ts.start'='1',
'fields.ts.end'='1000',
'fields.vc.kind'='random',
'fields.vc.min'='1',
'fields.vc.max'='100'
);
CREATE TABLE sink (
id INT,
ts BIGINT,
vc INT
) WITH (
'connector' = 'print'
);
2)查询源表
select * from source
3)插入sink表并查询
INSERT INTO sink select * from source;
select * from sink;
with字句
with source_tmp as (
select id, id+10 as new_id
from source)
select id, new_id from source_tmp;
SELECT & WHERE 子句
-- 自定义 Source 的数据
SELECT order_id, price FROM (VALUES (1, 2.0), (2, 3.1)) AS t (order_id, price)
SELECT vc + 10 FROM source WHERE id >10
SELECT DISTINCT 子句
- 注意TTL大小的设置
SELECT DISTINCT vc FROM source;
分组聚合
- SUM()、MAX()、MIN()、AVG()以及COUNT()
- 这种聚合方式,就叫作“分组聚合”(group aggregation)。想要将结果表转换成流或输出到外部系统,必须采用撤回流(retract stream)或更新插入流(upsert stream)的编码方式;如果在代码中直接转换成DataStream打印输出,需要调用toChangelogStream()。
CREATE TABLE source1 (
dim STRING,
user_id BIGINT,
price BIGINT,
row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),
WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'datagen',
'rows-per-second' = '10',
'fields.dim.length' = '1',
'fields.user_id.min' = '1',
'fields.user_id.max' = '100000',
'fields.price.min' = '1',
'fields.price.max' = '100000'
);
CREATE TABLE sink1 (
dim STRING,
pv BIGINT,
sum_price BIGINT,
max_price BIGINT,
min_price BIGINT,
uv BIGINT,
window_start bigint
) WITH (
'connector' = 'print'
);
insert into sink1
select dim,
count(*) as pv,
sum(price) as sum_price,
max(price) as max_price,
min(price) as min_price,
-- 计算 uv 数
count(distinct user_id) as uv,
cast((UNIX_TIMESTAMP(CAST(row_time AS STRING))) / 60 as bigint) as window_start
from source1
group by
dim,
-- UNIX_TIMESTAMP得到秒的时间戳,将秒级别时间戳 / 60 转化为 1min,
cast((UNIX_TIMESTAMP(CAST(row_time AS STRING))) / 60 as bigint)
- 多维分析
Group 聚合也支持 Grouping sets 、Rollup 、Cube,如下案例是Grouping sets:
SELECT
supplier_id
, rating
, product_id
, COUNT(*)
FROM (
VALUES
('supplier1', 'product1', 4),
('supplier1', 'product2', 3),
('supplier2', 'product3', 3),
('supplier2', 'product4', 4)
)
-- 供应商id、产品id、评级
AS Products(supplier_id, product_id, rating)
GROUP BY GROUPING SETS(
(supplier_id, product_id, rating),
(supplier_id, product_id),
(supplier_id, rating),
(supplier_id),
(product_id, rating),
(product_id),
(rating),
()
);
分组窗口聚合
- 从1.13版本开始,分组窗口聚合已经标记为过时,鼓励使用更强大、更有效的窗口TVF聚合
- SQL中只支持基于时间的窗口,不支持基于元素个数的窗口。
- tumble(time_attr, interval):滚动窗口
- hop(time_attr, interval, interval):滑动窗口
- session(time_attr, interval):会话窗口
1) 准备数据
CREATE TABLE ws (
id INT,
vc INT,
pt AS PROCTIME(), --处理时间
et AS cast(CURRENT_TIMESTAMP as timestamp(3)), --事件时间
WATERMARK FOR et AS et - INTERVAL '5' SECOND --watermark
) WITH (
'connector' = 'datagen',
'rows-per-second' = '10',
'fields.id.min' = '1',
'fields.id.max' = '3',
'fields.vc.min' = '1',
'fields.vc.max' = '100'
);
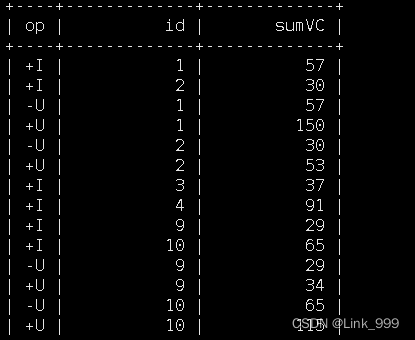
2)滚动窗口示例(时间属性字段,窗口长度)
select
id,
TUMBLE_START(et, INTERVAL '5' SECOND) wstart,
TUMBLE_END(et, INTERVAL '5' SECOND) wend,
sum(vc) sumVc
from ws
group by id, TUMBLE(et, INTERVAL '5' SECOND);
3)滑动窗口(时间属性字段,滑动步长,窗口长度)
select
id,
HOP_START(et, INTERVAL '3' SECOND,INTERVAL '5' SECOND) wstart,
HOP_END(et, INTERVAL '3' SECOND,INTERVAL '5' SECOND) wend,
sum(vc) sumVc
from ws
group by id, HOP(et, INTERVAL '3' SECOND,INTERVAL '5' SECOND);
4)会话窗口(时间属性字段,会话间隔)
select
id,
SESSION_START(et, INTERVAL '5' SECOND) wstart,
SESSION_END(et, INTERVAL '5' SECOND) wend,
sum(vc) sumVc
from ws
group by id, SESSION(et, INTERVAL '5' SECOND);
窗口表值函数(TVF)聚合
- 对于窗口表值函数,窗口本身返回的是就是一个表,所以窗口会出现在FROM后面,GROUP BY后面的则是窗口新增的字段window_start和window_end
- 语法
FROM TABLE(
窗口类型(TABLE 表名, DESCRIPTOR(时间字段),INTERVAL时间…)
)
GROUP BY [window_start,][window_end,] --可选
1)滚动窗口
SELECT
window_start,
window_end,
id , SUM(vc)
sumVC
FROM TABLE(
TUMBLE(TABLE ws, DESCRIPTOR(et), INTERVAL '5' SECONDS))
GROUP BY window_start, window_end, id;
2) 滑动窗口
要求: 窗口长度=滑动步长的整数倍(底层会优化成多个小滚动窗口)
SELECT window_start, window_end, id , SUM(vc) sumVC
FROM TABLE(
HOP(TABLE ws, DESCRIPTOR(et), INTERVAL '5' SECONDS , INTERVAL '10' SECONDS))
GROUP BY window_start, window_end, id;
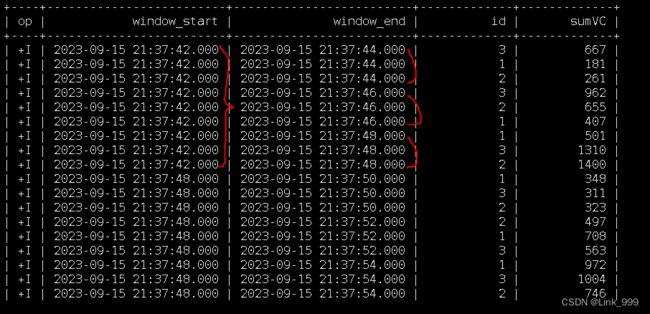
3)累积窗口
累积窗口可以认为是首先开一个最大窗口大小的滚动窗口,然后根据用户设置的触发的时间间隔将这个滚动窗口拆分为多个窗口,这些窗口具有相同的窗口起点和不同的窗口终点。
SELECT
window_start,
window_end,
id ,
SUM(vc) sumVC
FROM TABLE(
CUMULATE(TABLE ws, DESCRIPTOR(et), INTERVAL '2' SECONDS , INTERVAL '6' SECONDS))
GROUP BY window_start, window_end, id;
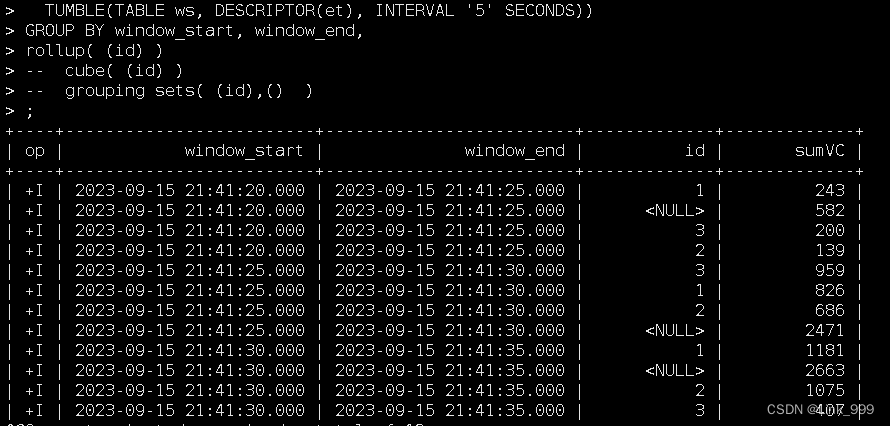
4)grouping sets多维分析
SELECT
window_start,
window_end,
id ,
SUM(vc) sumVC
FROM TABLE(
TUMBLE(TABLE ws, DESCRIPTOR(et), INTERVAL '5' SECONDS))
GROUP BY window_start, window_end,
rollup( (id) )
-- cube( (id) )
-- grouping sets( (id),() )
;
Over 聚合
- ORDER BY:必须是时间戳列(事件时间、处理时间),只能升序
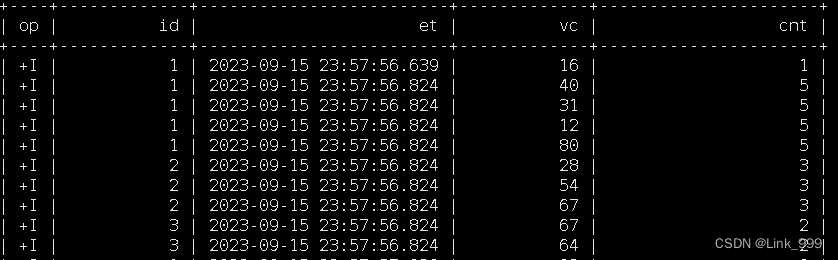
- (1)按照时间区间聚合
-- 统计每个传感器前10秒到现在收到的水位数据条数。
SELECT
id,
et,
vc,
count(vc) OVER (
PARTITION BY id
ORDER BY et
RANGE BETWEEN INTERVAL '10' SECOND PRECEDING AND CURRENT ROW
) AS cnt
FROM ws
--也可以用WINDOW子句来在SELECT外部单独定义一个OVER窗口,可以多次使用:
SELECT
id,
et,
vc,
count(vc) OVER w AS cnt,
sum(vc) OVER w AS sumVC
FROM ws
WINDOW w AS (
PARTITION BY id
ORDER BY et
RANGE BETWEEN INTERVAL '10' SECOND PRECEDING AND CURRENT ROW
);
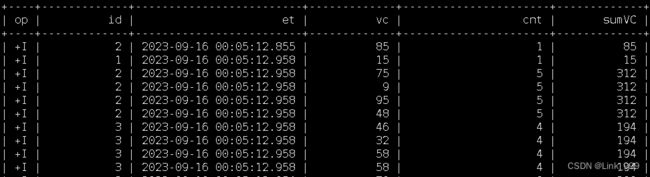
- (2)按照行数聚合
统计每个传感器前5条到现在数据的平均水位
SELECT
id,
et,
vc,
avg(vc) OVER (
PARTITION BY id
ORDER BY et
ROWS BETWEEN 5 PRECEDING AND CURRENT ROW
) AS avgVC
FROM ws
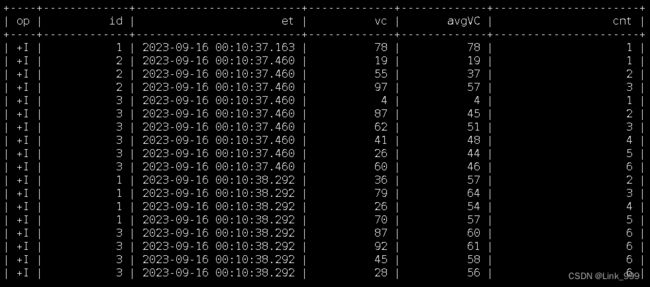
也可以用WINDOW子句来在SELECT外部单独定义一个OVER窗口:
SELECT
id,
et,
vc,
avg(vc) OVER w AS avgVC,
count(vc) OVER w AS cnt
FROM ws
WINDOW w AS (
PARTITION BY id
ORDER BY et
ROWS BETWEEN 5 PRECEDING AND CURRENT ROW
)
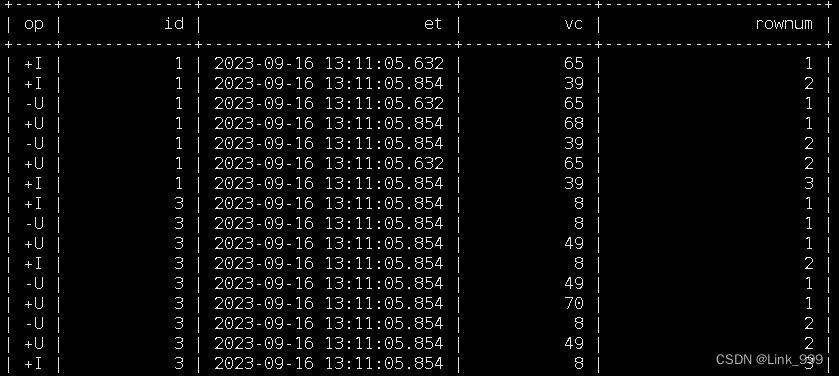
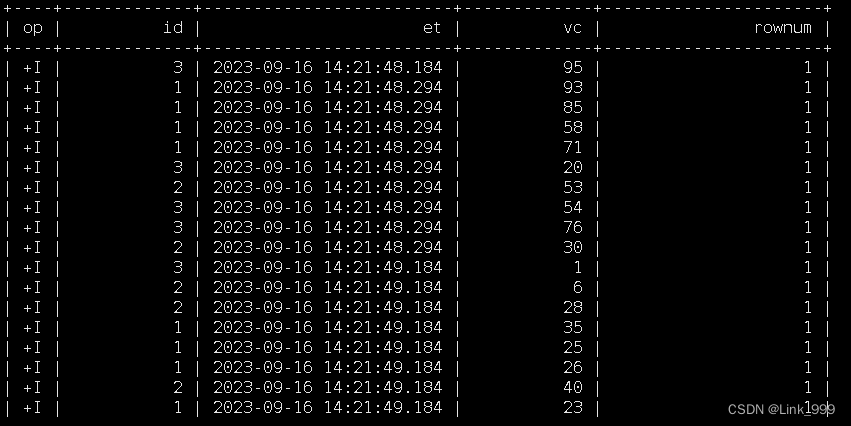
特殊语法 —— TOP-N
1)语法
SELECT [column_list]
FROM (
SELECT [column_list],
ROW_NUMBER() OVER ([PARTITION BY col1[, col2...]]
ORDER BY col1 [asc|desc][, col2 [asc|desc]...]) AS rownum
FROM table_name)
WHERE rownum <= N [AND conditions]
select
id,
et,
vc,
rownum
from
(
select
id,
et,
vc,
row_number() over(
partition by id
order by vc desc
) as rownum
from ws
)
where rownum<=3;
特殊语法 —— Deduplication去重
- 去重,也即上文介绍到的TopN 中 row_number = 1 的场景,但是这里有一点不一样在于其排序字段一定是时间属性列,可以降序,不能是其他非时间属性的普通列。
1)语法
SELECT [column_list]
FROM (
SELECT [column_list],
ROW_NUMBER() OVER ([PARTITION BY col1[, col2...]]
ORDER BY time_attr [asc|desc]) AS rownum
FROM table_name)
WHERE rownum = 1
2)案例
对每个传感器的水位值去重
select
id,
et,
vc,
rownum
from
(
select
id,
et,
vc,
row_number() over(
partition by id,vc
order by et
) as rownum
from ws
)
where rownum=1;
联结(Join)查询
-
Regular Join:
-
Inner Join(Inner Equal Join):流任务中,只有两条流 Join 到才输出,输出 +[L, R]
-
Left Join(Outer Equal Join):流任务中,左流数据到达之后,无论有没有 Join 到右流的数据,都会输出(Join 到输出 +[L, R] ,没 Join 到输出 +[L, null] ),如果右流之后数据到达之后,发现左流之前输出过没有 Join 到的数据,则会发起回撤流,先输出 -[L, null] ,然后输出 +[L, R]
-
Right Join(Outer Equal Join):有 Left Join 一样,左表和右表的执行逻辑完全相反
-
Full Join(Outer Equal Join):流任务中,左流或者右流的数据到达之后,无论有没有 Join 到另外一条流的数据,都会输出(对右流来说:Join 到输出 +[L, R] ,没 Join 到输出 +[null, R] ;对左流来说:Join 到输出 +[L, R] ,没 Join 到输出 +[L, null] )。如果一条流的数据到达之后,发现之前另一条流之前输出过没有 Join 到的数据,则会发起回撤流(左流数据到达为例:回撤 -[null, R] ,输出+[L, R] ,右流数据到达为例:回撤 -[L, null] ,输出 +[L, R]
-
Regular Join 的注意事项: 实时 Regular Join 可以不是 等值 join 。等值 join 和 非等值 join 区别在于, 等值 join数据 shuffle 策略是 Hash,会按照 Join on 中的等值条件作为 id 发往对应的下游; 非等值 join 数据 shuffle 策略是 Global,所有数据发往一个并发,按照非等值条件进行关联
--数据准备
CREATE TABLE ws (
id INT,
vc INT,
pt AS PROCTIME(), --处理时间
et AS cast(CURRENT_TIMESTAMP as timestamp(3)), --事件时间
WATERMARK FOR et AS et - INTERVAL '5' SECOND --watermark
) WITH (
'connector' = 'datagen',
'rows-per-second' = '10',
'fields.id.min' = '1',
'fields.id.max' = '3',
'fields.vc.min' = '1',
'fields.vc.max' = '100'
);
CREATE TABLE ws1 (
id INT,
vc INT,
pt AS PROCTIME(), --处理时间
et AS cast(CURRENT_TIMESTAMP as timestamp(3)), --事件时间
WATERMARK FOR et AS et - INTERVAL '0.001' SECOND --watermark
) WITH (
'connector' = 'datagen',
'rows-per-second' = '1',
'fields.id.min' = '3',
'fields.id.max' = '5',
'fields.vc.min' = '1',
'fields.vc.max' = '100'
);
--等值内连接(INNER Equi-JOIN)
SELECT *
FROM ws
INNER JOIN ws1
ON ws.id = ws1.id
--等值外连接
SELECT *
FROM ws
LEFT JOIN ws1
ON ws.id = ws1.id
SELECT *
FROM ws
RIGHT JOIN ws1
ON ws.id = ws1.id
SELECT *
FROM ws
FULL OUTER JOIN ws1
ON ws.id = ws.id
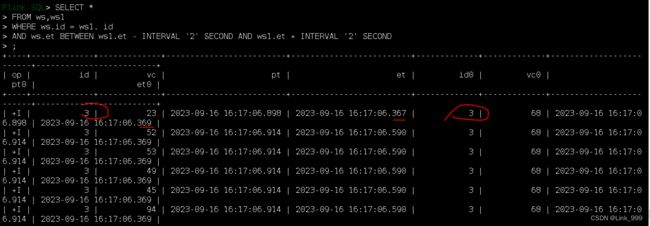
- 间隔联结查询:除了常规的联结条件外,还多了一个时间间隔的限制
- (1)ltime = rtime
(2)ltime >= rtime AND ltime < rtime + INTERVAL ‘10’ MINUTE
(3)ltime BETWEEN rtime - INTERVAL ‘10’ SECOND AND rtime + INTERVAL ‘5’ SECOND
SELECT *
FROM ws,ws1
WHERE ws.id = ws1. id
AND ws.et BETWEEN ws1.et - INTERVAL '2' SECOND AND ws1.et + INTERVAL '2' SECOND
- 维表联结查询
- Lookup Join 其实就是维表 Join,实时获取外部缓存的 Join,Lookup 的意思就是实时查找
- 上面说的这几种 Join 都是流与流之间的 Join,而 Lookup Join 是流与 Redis,Mysql,HBase 这种外部存储介质的 Join。仅支持处理时间字段。
表A
JOIN 维度表名 FOR SYSTEM_TIME AS OF 表A.proc_time AS 别名
ON xx.字段=别名.字段
CREATE TABLE Customers (
id INT,
name STRING,
country STRING,
zip STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://hadoop102:3306/customerdb',
'table-name' = 'customers'
);
-- order表每来一条数据,都会去mysql的customers表查找维度数据
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS o
JOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id;
Order by 和 limit
- 支持 Batch\Streaming,但在实时任务中一般用的非常少。
实时任务中,Order By 子句中必须要有时间属性字段,并且必须写在最前面且为升序。
SELECT *
FROM ws
ORDER BY et, id desc;
SELECT *
FROM ws
LIMIT 3;
SQL Hints
- 在执行查询时,可以在表名后面添加SQL Hints来临时修改表属性,对当前job生效。
select * from ws1/*+ OPTIONS('rows-per-second'='10')*/;
集合操作
1)UNION 和 UNION ALL
UNION:将集合合并并且去重
UNION ALL:将集合合并,不做去重。
(SELECT id FROM ws) UNION (SELECT id FROM ws1);
(SELECT id FROM ws) UNION ALL (SELECT id FROM ws1);
2)Intersect 和 Intersect All
Intersect:交集并且去重
Intersect ALL:交集不做去重
(SELECT id FROM ws) INTERSECT (SELECT id FROM ws1);
(SELECT id FROM ws) INTERSECT ALL (SELECT id FROM ws1);
3)Except 和 Except All
Except:差集并且去重
Except ALL:差集不做去重
(SELECT id FROM ws) EXCEPT (SELECT id FROM ws1);
(SELECT id FROM ws) EXCEPT ALL (SELECT id FROM ws1);
4)In 子查询
In 子查询的结果集只能有一列
SELECT id, vc
FROM ws
WHERE id IN (
SELECT id FROM ws1
)
系统函数
- https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/dev/table/functions/systemfunctions/
Module操作
-
Module 允许 Flink 扩展函数能力。目前 Flink 包含了以下三种 Module:
-
CoreModule:CoreModule 是 Flink 内置的 Module,Flink 默认开启的 Module 就是 CoreModule。
-
HiveModule:HiveModule 可以将 Hive 内置函数作为 Flink 的系统函数提供给 SQL\Table API 用户进行使用,比如 get_json_object 这类 Hive 内置函数(Flink 默认的 CoreModule 是没有的)
-
用户自定义 Module:用户可以实现 Module 接口实现自己的 UDF 扩展 Module
1)语法
-- 加载
LOAD MODULE module_name [WITH ('key1' = 'val1', 'key2' = 'val2', ...)]
-- 卸载
UNLOAD MODULE module_name
-- 查看
SHOW MODULES;
SHOW FULL MODULES;
--Flink 只会解析已经启用了的 Module。那么当两个 Module 中出现两个同名的函数且都启用时, Flink 会根据加载 Module 的顺序进行解析,结果就是会使用顺序为第一个的 Module 的 UDF,可以使用下面语法更改顺序:
USE MODULE hive,core;
需要先引入 hive 的 connector。
(1)上传jar包到flink的lib中
上传hive connector
cp flink-sql-connector-hive-3.1.3_2.12-1.17.0.jar /opt/module/flink-1.17.0/lib/
注意:拷贝hadoop的包,解决依赖冲突问题
cp /opt/module/hadoop-3.3.4/share/hadoop/mapreduce/hadoop-mapreduce-client-core-3.3.4.jar /opt/module/flink-1.17.0/lib/
(2)重启flink集群和sql-client
(3)加载hive module
-- hive-connector内置了hive module,提供了hive自带的系统函数,注意hive的版本
load module hive with ('hive-version'='3.1.2');
show modules;
show functions;
-- 可以调用hive的split函数
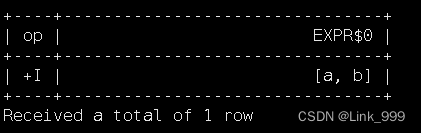
select split('a,b', ',');
常用 Connector 读写
- https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/connectors/table/overview/
kafka
- 1、下载kafka的jar包
- 2、上传到目录 /opt/module/flink-1.17.0/lib/
- 3、 重启yarn-session、sql-client
- 普通kafka表
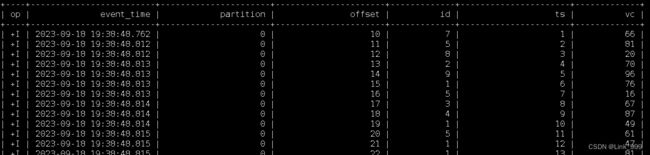
(1)创建Kafka的映射表
CREATE TABLE t1(
`event_time` TIMESTAMP(3) METADATA FROM 'timestamp',
--列名和元数据名一致可以省略 FROM 'xxxx', VIRTUAL表示只读
`partition` BIGINT METADATA VIRTUAL,
`offset` BIGINT METADATA VIRTUAL,
id int,
ts bigint ,
vc int )
WITH (
'connector' = 'kafka',
'properties.bootstrap.servers' = 'hadoop103:9092',
'properties.group.id' = 'atguigu',
-- 'earliest-offset', 'latest-offset', 'group-offsets', 'timestamp' and 'specific-offsets'
'scan.startup.mode' = 'earliest-offset',
-- fixed为flink实现的分区器,一个并行度只写往kafka一个分区
'sink.partitioner' = 'fixed', --每个 Flink partition 最终对应最多一个 Kafka partition。
'topic' = 'ws1',
'format' = 'json'
)
(2)插入Kafka表
insert into t1(id,ts,vc) select * from source;
(3)查询Kafka表
select * from t1;

- upsert-kafka表
- 如果当前表存在更新操作,那么普通的kafka连接器将无法满足,此时可以使用Upsert Kafka连接器。
Upsert Kafka 连接器支持以 upsert 方式从 Kafka topic 中读取数据并将数据写入 Kafka topic。
(1)创建upsert-kafka的映射表(必须定义主键)
CREATE TABLE t2(
id int ,
sumVC int ,
primary key (id) NOT ENFORCED
)
WITH (
'connector' = 'upsert-kafka',
'properties.bootstrap.servers' = 'hadoop102:9092',
'topic' = 'ws2',
'key.format' = 'json',
'value.format' = 'json'
);
(2)插入upsert-kafka表
insert into t2 select id,sum(vc) sumVC from source group by id;
(3)查询upsert-kafka表
upsert-kafka 无法从指定的偏移量读取,只会从主题的源读取。
select * from t2;
File
上传所需jar包到lib下
cp flink-sql-connector-hive-3.1.3_2.12-1.17.0.jar /opt/module/flink-1.17.0/lib/
cp mysql-connector-j-8.0.31.jar /opt/module/flink-1.17.0/lib/
2)更换planner依赖
只有在使用Hive方言或HiveServer2时才需要这样额外的计划器jar移动,但这是Hive集成的推荐设置。
mv /opt/module/flink-1.17.0/opt/flink-table-planner_2.12-1.17.0.jar /opt/module/flink-1.17.0/lib/flink-table-planner_2.12-1.17.0.jar
mv /opt/module/flink-1.17.0/lib/flink-table-planner-loader-1.17.0.jar /opt/module/flink-1.17.0/opt/flink-table-planner-loader-1.17.0.jar
1)创建FileSystem映射表
CREATE TABLE t3( id int, ts bigint , vc int )
WITH (
'connector' = 'filesystem',
'path' = 'hdfs://hadoop102:8020/data/t3',
'format' = 'csv'
);
2)写入
insert into t3 select * from source;
3)查询
select * from t3 where id = 1;
JDBC(MySQL)
- Flink在将数据写入外部数据库时使用DDL中定义的主键。如果定义了主键,则连接器以upsert模式操作,否则,连接器以追加模式操作。
- 在upsert模式下,Flink会根据主键插入新行或更新现有行,Flink这样可以保证幂等性。
- 上传jdbc连接器的jar包和mysql的连接驱动包到flink/lib下:
flink-connector-jdbc-3.1.0-1.17.jar
mysql-connector-j-8.0.31.jar
1)mysql的test库中建表
CREATE TABLE `ws2` (
`id` int(11) NOT NULL,
`ts` bigint(20) DEFAULT NULL,
`vc` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
2)创建JDBC映射表
CREATE TABLE t4
(
id INT,
ts BIGINT,
vc INT,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector'='jdbc',
'url' = 'jdbc:mysql://hadoop102:3306/test?useUnicode=true&characterEncoding=UTF-8',
'username' = 'root',
'password' = '000000',
'connection.max-retry-timeout' = '60s',
'table-name' = 'ws2',
'sink.buffer-flush.max-rows' = '500',
'sink.buffer-flush.interval' = '5s',
'sink.max-retries' = '3',
'sink.parallelism' = '1'
);
3)查询
select * from t4;
4)写入
insert into t4 select * from source;
savepoint
- 1、 先提交一个insert作业
(1)创建Kafka的映射表
CREATE TABLE tc(
`event_time` TIMESTAMP(3) METADATA FROM 'timestamp',
--列名和元数据名一致可以省略 FROM 'xxxx', VIRTUAL表示只读
`partition` BIGINT METADATA VIRTUAL,
`offset` BIGINT METADATA VIRTUAL,
id int,
ts bigint ,
vc int )
WITH (
'connector' = 'kafka',
'properties.bootstrap.servers' = 'hadoop103:9092',
'properties.group.id' = 'atguigu',
-- 'earliest-offset', 'latest-offset', 'group-offsets', 'timestamp' and 'specific-offsets'
'scan.startup.mode' = 'earliest-offset',
-- fixed为flink实现的分区器,一个并行度只写往kafka一个分区
'sink.partitioner' = 'fixed', --每个 Flink partition 最终对应最多一个 Kafka partition。
'topic' = 'ws2',
'format' = 'json'
);
(2)插入Kafka表
insert into tc(id,ts,vc) select * from source;
(3)查看job ID
show jobs;

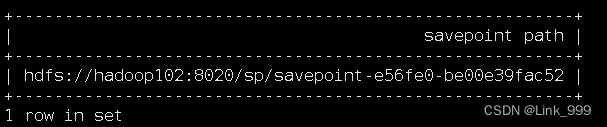
- 2、停止作业,触发savepoint
SET state.checkpoints.dir='hdfs://hadoop102:8020/check';
SET state.savepoints.dir='hdfs://hadoop102:8020/sp';
STOP JOB 'e56fe0bd5df28b07b50181a9de985171' WITH SAVEPOINT;
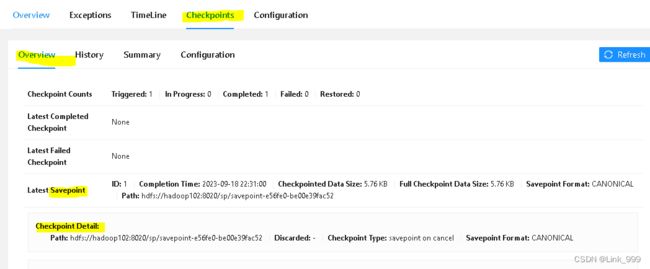
- 3、从savepoint恢复
-- 设置从savepoint恢复的路径, 之后直接提交sql,就会从savepoint恢复
SET execution.savepoint.path=' hdfs://hadoop102:8020/sp/savepoint-e56fe0-be00e39fac52';
--允许跳过无法还原的保存点状态
set 'execution.savepoint.ignore-unclaimed-state' = 'true';
- 4、恢复后重置路径
指定execution.savepoint.path后,将影响后面执行的所有DML语句,可以使用RESET命令重置这个配置选项。
RESET execution.savepoint.path;
如果出现reset没生效可以重启sql-client
catalog
- Catalog 提供了元数据信息,例如数据库、表、分区、视图以及数据库或其他外部系统中存储的函数和信息。
catalog类型
- 基于内存实现的 Catalog,所有元数据只在session 的生命周期内可用。默认自动创建,会有名为“default_catalog”的内存Catalog,这个Catalog默认只有一个名为“default_database”的数据库,会区分大小写。
- JdbcCatalog 使得用户可以将 Flink 通过 JDBC 协议连接到关系数据库。Postgres Catalog和MySQL Catalog是目前仅有的两种JDBC Catalog实现,将元数据存储在数据库中。
- HiveCatalog:有两个用途,一是单纯作为 Flink 元数据的持久化存储,二是作为读写现有 Hive 元数据的接口。注意:Hive MetaStore 以小写形式存储所有元数据对象名称。Hive Metastore以小写形式存储所有元对象名称。
- 用户自定义 Catalog
JdbcCatalog(MySQL)
- JdbcCatalog不支持建表,只是打通flink与mysql的连接,可以去读写mysql现有的库表。
- 创建Catalog
JdbcCatalog支持以下选项:
name:必需,Catalog名称。
default-database:必需,连接到的默认数据库。
username: 必需,Postgres/MySQL帐户的用户名。
password:必需,该帐号的密码。
base-url:必需,数据库的jdbc url(不包含数据库名)
对于Postgres Catalog,是"jdbc:postgresql://:<端口>"
对于MySQL Catalog,是"jdbc: mysql://:<端口>" - jar包 依赖等配置前面已经使用过,此处省略
1)创建catalog
CREATE CATALOG my_jdbc_catalog WITH(
'type' = 'jdbc',
'default-database' = 'test',
'username' = 'root',
'password' = '000000',
'base-url' = 'jdbc:mysql://hadoop102:3306'
);
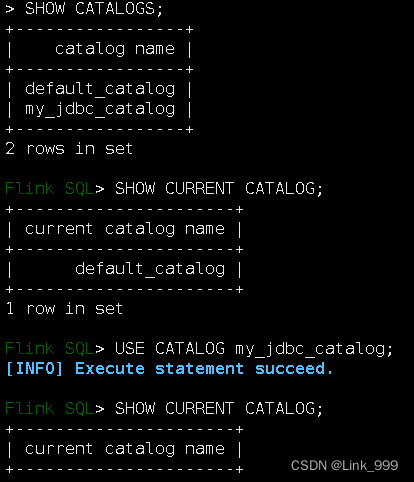
2)查看Catalog
SHOW CATALOGS;
--查看当前的CATALOG
SHOW CURRENT CATALOG;
3)使用指定Catalog
USE CATALOG my_jdbc_catalog;
4)查看当前的CATALOG
SHOW CURRENT CATALOG;
- 对当前jdbc进行查询写入等操作
hivecatalog
-
jar包 依赖等配置前面已经使用过,此处省略
-
启动外置的hive metastore服务
[link999@hadoop102 hive]$ hive --service metastore &
查看
netstat -anp|grep 9083
ps -ef|grep -i metastore
- 创建hivecatalog
CREATE CATALOG myhive WITH (
'type' = 'hive',
'default-database' = 'default',
'hive-conf-dir' = '/opt/module/hive/conf'
);
查看Catalog
SHOW CATALOGS;
--查看当前的CATALOG
SHOW CURRENT CATALOG;
使用指定Catalog
USE CATALOG myhive;
--查看当前的CATALOG
SHOW CURRENT CATALOG;
- 读写Hive表
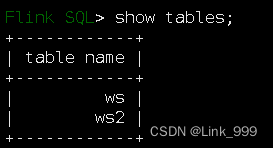
SHOW DATABASES; -- 可以看到hive的数据库
USE test; -- 可以切换到hive的数据库
SHOW TABLES; -- 可以看到hive的表
SELECT * from ws; --可以读取hive表
INSERT INTO ws VALUES(1,1,1); -- 可以写入hive表
IDEA中编写FlinkSQL
需要引入的依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-loader</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
创建表、查询表、写入表
“表环境”主要负责:
(1)注册Catalog和表;
(2)执行 SQL 查询;
(3)注册用户自定义函数(UDF);
(4)DataStream 和表之间的转换。
public class sqldemo {
public static void main(String[] args) throws Exception {
// 创建流环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 创建表环境
StreamTableEnvironment TableEnv = StreamTableEnvironment.create(env);
// 创建表
TableEnv.executeSql(
"CREATE TABLE source ( \n" +
" id INT, \n" +
" ts BIGINT, \n" +
" vc INT\n" +
") WITH ( \n" +
" 'connector' = 'datagen', \n" +
" 'rows-per-second'='1', \n" +
" 'fields.id.kind'='random', \n" +
" 'fields.id.min'='1', \n" +
" 'fields.id.max'='5', \n" +
" 'fields.ts.kind'='sequence', \n" +
" 'fields.ts.start'='1', \n" +
" 'fields.ts.end'='10', \n" +
" 'fields.vc.kind'='random', \n" +
" 'fields.vc.min'='1', \n" +
" 'fields.vc.max'='50'\n" +
");"
);
TableEnv.executeSql("CREATE TABLE sink (\n" +
" id INT, \n" +
" ts BIGINT, \n" +
" vc INT\n" +
") WITH (\n" +
"'connector' = 'print'\n" +
");");
// 查询sql
Table table = TableEnv.sqlQuery("select id, min(vc), max(vc) from source group by id;");
// 把table对象,注册成表名(创建了一个“虚拟表”)
TableEnv.createTemporaryView("tmp", table);
TableEnv.sqlQuery("select * from tmp;");
// 输出表 sql用法
TableEnv.executeSql("insert into sink select * from tmp");
// 用table api来查询
// Table source = TableEnv.from("source");
// Table result = source
// .where($("id").isGreater(5))
// .groupBy($("id"))
// .aggregate($("vc").sum().as("sumVC"))
// .select($("id"), $("sumVC"));
//
// // 输出表 table api用法
// result.executeInsert("sink");
}
}
流转表、表转流
public class tablestreamdemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<WaterSensor> sensorDS = env.fromElements(
new WaterSensor("s1", 1L, 1),
new WaterSensor("s2", 2L, 2),
new WaterSensor("s2", 3L, 3),
new WaterSensor("s5", 5L, 5),
new WaterSensor("s5", 2L, 2)
);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 流转表
Table sensorTable = tableEnv.fromDataStream(sensorDS);
Table sensorTable1 = tableEnv.fromDataStream(sensorDS, $("id").as("sid"), $("vc"));
tableEnv.createTemporaryView("sensor", sensorTable);
Table filterTable = tableEnv.sqlQuery("select id,ts,vc from sensor where vc > 2;");
Table sumTable = tableEnv.sqlQuery("select id, sum(vc) from sensor group by id;");
// 表转流
// 追加流
tableEnv.toDataStream(filterTable).print("filter0");
tableEnv.toDataStream(filterTable, WaterSensor.class).print("filter");
// changelog流
tableEnv.toChangelogStream(sumTable).print("sum");
// 只要代码中调用了datastreamAPI,就需要execute,否则不需要
env.execute();
}
}
自定义函数UDF
-
标量函数(Scalar Functions),一进一出
-
表函数(Table Functions),一进多出
-
聚合函数
-
表聚合函数
问题记录
- 1、TableAlreadyExistException :表已经存在
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.catalog.exceptions.TableAlreadyExistException: Table (or view) myflink.sink already exists in Catalog default_
catalog.
- 2、java.net.ConnectException: 拒绝连接
[ERROR] Could not execute SQL statement. Reason:
java.net.ConnectException: 拒绝连接
重启Flink 集群:(base) [link999@hadoop102 flink-1.17.0]$ bin/yarn-session.sh -d
-
3、资源不足,可以把之前跑过的job关掉,释放出资源重新跑
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Could not acquire the minimum required resources.End of exception on server side>]

-
4、sql语法问题
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.sql.parser.impl.ParseException: Encountered "\'CONNECTor\'" at line 9, column 3.
Was expecting one of:
"AS" ...
"LIKE" ...
";" ...
- 5、缺少依赖或依赖冲突

- 6、 select * from t3 where id = ‘1’;因为ID是int类型的,不能加引号,去掉引号即可
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.api.ValidationException: implicit type conversion between INTEGER and CHAR is not supported now
感谢
- 本文是尚硅谷Flink1.17的学习笔记,非常感谢尚硅谷的课程,本文用于学习和查阅。