机器学习算法基础--逻辑回归简单处理mnist数据集项目
目录
1.项目背景介绍
2.Mnist数据导入
3.数据标签提取且划分数据集
4.数据特征标准化
5.模型建立与训练
6.后验概率判断及预测
7.处理模型阈值及准确率
8.阈值分析的可视化绘图
9.模型精确性的评价标准
1.项目背景介绍
"""
MNIST数据集是美国国家标准与技术研究院收集整理的大型手写数字数据集,包含了60,000个样本的训练集以及10,000个样本的测试集。
在这里我们给出个10000个数据集,以下我们就来简单地介绍以下这个数据集:
首先每一张mnist数据集图片都是由28x28的灰度值组成的,我们在excel中对于一张图片,采用一行784列才存储一张图片的灰度值。
所以我们10000个数据就有10000x784列数据所组成。
今天我们的任务就是通过逻辑回归做一个二分类的问题,给图片进行分类,划分成是否是5/或者其他的数据。
"""2.Mnist数据导入
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
# 读取CSV文件
data = pd.read_csv('mnist-demo.csv')
data.head()#大部分的灰度值都为0
3.数据标签提取且划分数据集
# 提取特征和标签
X = data.drop('label', axis=1).values
y = data['label']
y_binary = (y == 5).astype(int)4.数据特征标准化
# 特征标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)5.模型建立与训练
# 训练逻辑回归模型
model = LogisticRegression(max_iter=1000)
model.fit(X_train_scaled, y_train)6.后验概率判断及预测
# 预测概率
proba = model.predict_proba(X_test_scaled)
#根据后验概率进行决策差别还是比较大的
proba
%%
# 预测
predictions = model.predict(X_test_scaled)
#0表示不是5,1表示是5
predictions
7.处理模型阈值及准确率
#阈值表示的是分类的决策面,如果prob>threhold,选择第一类,如果prob<=threhold,选择第二类
# 设置阈值
threshold_box=[0,0.05,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.95,1]
Accuracy=np.zeros(13)
for i in range(len(threshold_box)):
threshold =threshold_box[i]
predictions = (proba[:, 1] > threshold).astype(int)
# 计算准确率
Accuracy[i] = accuracy_score(y_test, predictions)
print("阈值为{}时,模型的准确率为:{}".format(threshold,Accuracy[i]))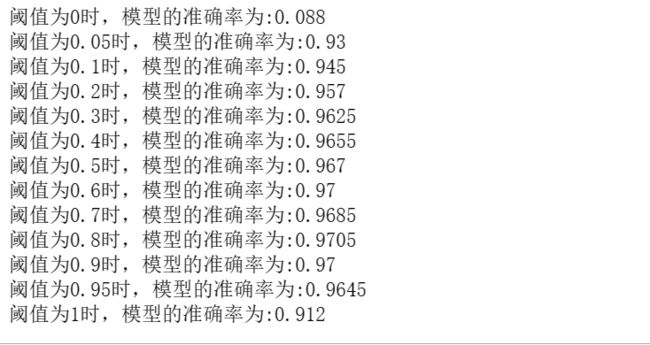
8.阈值分析的可视化绘图
#matplotlib不支持中文,我们需要添加以下的代码
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.scatter(threshold_box,Accuracy,color='r',label='Accuracy')
plt.ylim(0,1)
plt.title("不同阈值的准确率变化图")
plt.ylabel("模型分类准确率")
plt.xlabel("模型阈值")
plt.legend(loc=5,ncol=5,edgecolor='y')
plt.savefig(r"C:\Users\Zeng Zhong Yan\Desktop\不同阈值的准确率变化图.png",dpi=500)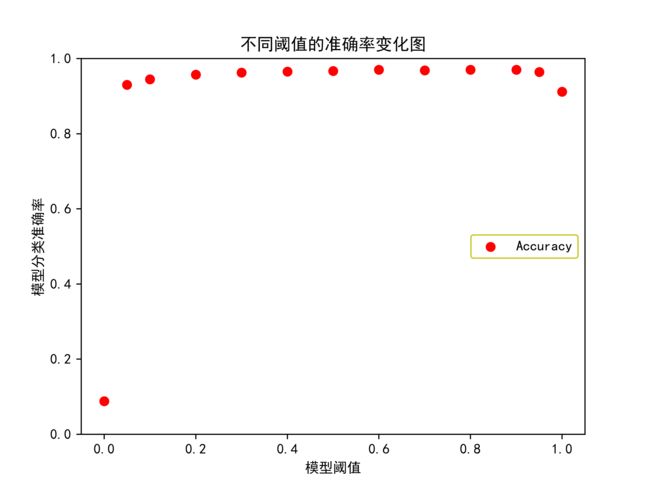
9.模型精确性的评价标准
我们给出以下的概念:
真阳性(True Positive,简称TP),也就是预测为真,实际上也为真的数据.
假阳性(False Positive,简称FP),也就是预测为真,但实际上为假的数据.
假阴性(False Negative,简称FN),也就是预测为假,但实际上为真的数据.
真阴性(True Negative,简称TN),也就是预计为假,实际上也为假的数据.
我们给出混淆矩阵的定义:
Confusion matrix=[[TP,FP],[FN,PN]]
我们同时给出几个评价指标:
1.准确率:所有的预测正确(正类负类)的占总的比重.
Accuray=(TP+TN)/(TP+TN+FP+FN)
2.精确率:正确预测为正的占全部预测为正的比例.
Precision=TP/(TP+FP)
3.召回率:即正确预测为正的占全部实际为正的比例.
Recall=TP/(TP+FN)
4.F-score:
F-score=(2*Precision*Recall)/(Precision+Recall)