【C进阶】指针和数组笔试题解析
做题之前我们先来回顾一下
对于数组名的理解:除了以下两种情况,数组名表示的都是数组首元素的地址
(1)sizeof(数组名):这里的数组名表示整个数组
(2)&(数组名) :这里的数组名也表示整个数组
一、一维数组
int a[] = {1,2,3,4};
printf("%d\n",sizeof(a));
printf("%d\n",sizeof(a+0));
printf("%d\n",sizeof(*a));
printf("%d\n",sizeof(a+1));
printf("%d\n",sizeof(a[1]));
printf("%d\n",sizeof(&a));
printf("%d\n",sizeof(*&a));
printf("%d\n",sizeof(&a+1));
printf("%d\n",sizeof(&a[0]));
printf("%d\n",sizeof(&a[0]+1));【运行结果】:(32位环境下)

【分析】:
(1)printf("%d\n", sizeof(a));数组名单独放在sizeof内部,数组名表示整个数组;
计算的就是整个数组的大小;
也就是4(4个元素)*4(每个元素都是int类型,占四个字节)=16字节
(2)printf("%d\n",sizeof(a+0));a没有单独放在sizeof内部,也没有&,则数组名表示数组首元素的地址;
+0还是首元素的地址,也就是计算数组首元素地址的大小;
是地址大小就是4/8个字节(32位机器是4个字节,64位是8个字节)
(3)printf("%d\n", sizeof(*a));
a没有单独放在sizeof内部,也没有&,则数组名表示数组首元素的地址;
*数组首元素的地址,得到的也就是数组首元素:1;
因为数组类型为int类型,那么就是4个字节
总结:*a==*(a+0)==a【0】
(4)printf("%d\n", sizeof(a + 1));
a没有单独放在sizeof内部,也没有&,则数组名表示数组首元素的地址;
a+1也就是首元素地址+1,得到的是第二个元素的地址;
是地址大小就是4/8个字节(32位机器是4个字节,64位是8个字节);
总结:a+1==&a【1】
(5)printf("%d\n", sizeof(a[1]));
a【1】就是数组第二个元素,也就是2
也就是计算数组第二个元素的大小,int类型也就是4个字节
(6)printf("%d\n", sizeof(&a));
a单独和&一起,a表示的就是整个数组的大小;
&a取出整个数组的地址;
是地址大小就是4/8个字节(32位机器是4个字节,64位是8个字节)
【注意】:
这里的&a(整个数组的地址)和a(数组首元素的地址)的区别在于类型,而非大小
a:类型为int * int *p=a;
&a:类型为int (*)【4】(数组指针) int (*p)【4】=&a;
(7)printf("%d\n", sizeof(*&a));
两种理解方法:
<1>&和*相互抵消,sizeof(*(&a))==sizeof(a),所以就和第一个一样
<2>数组指针解引用理解
首先&a是数组的地址,类型为int(*)【4】(数组指针)
然后再解引用,访问的就是4个int的数组
(8)printf("%d\n", sizeof(&a + 1));
a单独和&一起,a表示的就是整个数组的大小;
地址+1跳过整个数组,但是还是地址,也就是4/8个字节
(9)printf("%d\n", sizeof(&a[0]));
&a【0】就是取出第一个元素的地址,是地址就是4/8个字节
(10)printf("%d\n", sizeof(&a[0] + 1));
第一个元素的地址+1,也就是第二个元素的地址,是地址就是4/8个字节
总结:表示第二个元素的地址:&a【1】==&a【0】+1==a+1
二、字符数组
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", sizeof(arr));
printf("%d\n", sizeof(arr + 0));
printf("%d\n", sizeof(*arr));
printf("%d\n", sizeof(arr[1]));
printf("%d\n", sizeof(&arr));
printf("%d\n", sizeof(&arr + 1));
printf("%d\n", sizeof(&arr[0] + 1));【运行结果】:(32位环境下)

【分析】:
(1)printf("%d\n", sizeof(arr));
数组名单独放在sizeof内部,数组名表示整个数组;
计算的就是整个数组的大小;
也就是6(6个元素)*1(每个元素都是char类型,占一个字节)=6字节
(2)printf("%d\n", sizeof(arr + 0));
a没有单独放在sizeof内部,也没有&,则数组名表示数组首元素的地址;
+0还是首元素的地址,也就是计算数组首元素地址的大小;
是地址大小就是4/8个字节(32位机器是4个字节,64位是8个字节)
虽然这里是char类型,但是是指针就是4/8个字节
不要在门缝里看指针,把指针看扁了
(3)printf("%d\n", sizeof(*arr));
a没有单独放在sizeof内部,也没有&,则数组名表示数组首元素的地址;
*数组首元素的地址,得到的也就是数组首元素:‘a’;
因为数组类型为char类型,那么就是1个字节
(4)printf("%d\n", sizeof(arr[1]);
a【1】就是数组第二个元素,也就是'b'
也就是计算数组第二个元素的大小,char类型也就是1个字节
(5)printf("%d\n", sizeof(&arr));
a单独和&一起,a表示的就是整个数组的大小;
&a取出整个数组的地址;
是地址大小就是4/8个字节(32位机器是4个字节,64位是8个字节)
(6)printf("%d\n", sizeof(&arr + 1));
a单独和&一起,a表示的就是整个数组的大小;
地址+1跳过整个数组,但是还是地址,也就是4/8个字节
(7)printf("%d\n", sizeof(&arr[0] + 1));
第一个元素的地址+1,也就是第二个元素的地址,是地址就是4/8个字节
把sizeof改为strlen再来看看结果
首先回顾一下strlen函数:
它是用来求字符串的长度的,统计的是\0之前的字符个数
size_t strlen( const char *string ); (它的参数是指针,也就是个地址)
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr + 0));
printf("%d\n", strlen(*arr));
printf("%d\n", strlen(arr[1]));
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr + 1));
printf("%d\n", strlen(&arr[0] + 1));【运行结果】:
随机值(但是>=6)
随机值(但是>=6)
err
err
随机值(但是>=6)
随机值
随机值
【分析】:
(1)printf("%d\n", strlen(arr));
没有sizeof,也没与&,此时的arr表示数组首元素的地址
因为后面’\0‘位置不可知,所以只能是随机值
但是这个随机值>=6,这个6就是前面6个字符
(2)printf("%d\n", strlen(arr + 0));
没有sizeof,也没与&,此时的arr表示数组首元素的地址
+0还是数组首元素的地址,所以就跟上题一样
(3)printf("%d\n", strlen(*arr));
没有sizeof,也没与&,此时的arr表示数组首元素的地址
那么*arr就是首元素,也就是字符’a'
strlen的参数应该是个地址,但是却传了97(也就是字符'a'的ACSII值)
站在strlen的角度,认为传参进去的‘a'——97就是地址,
但是97这个地址不属于自己,不能直接进行*,如果*就是非法访问
(4)printf("%d\n", strlen(arr[1]));
arr【1】就是第二个元素,也就是字符‘b'——98,
98作为地址直接访问,属于非法访问,所以也会报错
(5)printf("%d\n", strlen(&arr));
a单独和&一起,a表示的就是整个数组的大小;
&a类型为char (*) 【6】(数组指针),而strlen的参数类型是const char *
那么就会进行类型转换,数组指针类型转换为const char *类型(类型变化)
虽然类型发生变化,但是值不变,所以还是从第一个值开始找\0,
但是后面’\0‘位置不可知,所以只能是随机值
(6)printf("%d\n", strlen(&arr + 1));
a单独和&一起,a表示的就是整个数组的大小;
+1就跳过整个数组,接着向后找\0的位置
但是后面’\0‘位置不可知,所以也是随机值
(7)printf("%d\n", strlen(&arr[0] + 1));
&arr【0】取出的是第一个元素的地址,+1就是第二个元素的地址
接着从第二个元素的位置向后找\0的位置,
但是后面’\0‘位置不可知,所以也是随机值
char arr[] = "abcdef";
printf("%d\n", sizeof(arr));
printf("%d\n", sizeof(arr + 0));
printf("%d\n", sizeof(*arr));
printf("%d\n", sizeof(arr[1]));
printf("%d\n", sizeof(&arr));
printf("%d\n", sizeof(&arr + 1));
printf("%d\n", sizeof(&arr[0] + 1));【运行结果】:(32位环境下)

【分析】:
(1)printf("%d\n", sizeof(arr));
数组名单独放在sizeof内部,数组名表示整个数组;
计算的就是整个数组的大小;
也就是7(7个元素)*1(每个元素都是char类型,占一个字节)=7字节
注意:这里数组元素直接定义了字符串,那么还有一个看不到的\0
(2)printf("%d\n", sizeof(arr + 0));
a没有单独放在sizeof内部,也没有&,则数组名表示数组首元素的地址;
+0还是首元素的地址,也就是计算数组首元素地址的大小;
是地址大小就是4/8个字节(32位机器是4个字节,64位是8个字节)
虽然这里是char类型,但是是指针就是4/8个字节
(3)printf("%d\n", sizeof(*arr));
a没有单独放在sizeof内部,也没有&,则数组名表示数组首元素的地址;
*数组首元素的地址,得到的也就是数组首元素:‘a’;
因为数组类型为char类型,那么就是1个字节
(4)printf("%d\n", sizeof(arr[1]));
a【1】就是数组第二个元素,也就是'b'
也就是计算数组第二个元素的大小,char类型也就是1个字节
(5)printf("%d\n", sizeof(&arr));
a单独和&一起,a表示的就是整个数组的大小;
&a取出整个数组的地址;
是地址大小就是4/8个字节(32位机器是4个字节,64位是8个字节)
(6)printf("%d\n", sizeof(&arr + 1));
a单独和&一起,a表示的就是整个数组的大小;
地址+1跳过整个数组,但是还是地址,也就是4/8个字节
(7)printf("%d\n", sizeof(&arr[0] + 1));
第一个元素的地址+1,也就是第二个元素的地址,是地址就是4/8个字节
把sizeof改为strlen再来看看结果:
char arr[] = "abcdef";
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr + 0));
printf("%d\n", strlen(*arr));
printf("%d\n", strlen(arr[1]));
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr + 1));
printf("%d\n", strlen(&arr[0] + 1));【运行结果】:
6
6
err
err
6
随机值
5
【分析】:
(1)printf("%d\n", strlen(arr));
没有sizeof,也没与&,此时的arr表示数组首元素的地址
统计\0之前的字符个数,也就是6个
(2)printf("%d\n", strlen(arr + 0));
没有sizeof,也没与&,此时的arr表示数组首元素的地址
+0还是数组首元素的地址,所以就跟上题一样
(3)printf("%d\n", strlen(*arr));
没有sizeof,也没与&,此时的arr表示数组首元素的地址
那么*arr就是首元素,也就是字符’a'
strlen的参数应该是个地址,但是却传了97(也就是字符'a'的ACSII值)
站在strlen的角度,认为传参进去的‘a'——97就是地址,
但是97这个地址不属于自己,不能直接进行*,如果*就是非法访问
(4)printf("%d\n", strlen(arr[1]));
arr【1】就是第二个元素,也就是字符‘b'——98,
98作为地址直接访问,属于非法访问,所以也会报错
(5)printf("%d\n", strlen(&arr));
a单独和&一起,a表示的就是整个数组的大小;
&a类型为char (*) 【6】(数组指针),而strlen的参数类型是const char *
那么就会进行类型转换,数组指针类型转换为const char *类型(类型变化)
虽然类型发生变化,但是值不变,所以还是从第一个值开始找\0,
统计\0之前的字符个数,也就是6个
(6)printf("%d\n", strlen(&arr + 1));
a单独和&一起,a表示的就是整个数组的大小;
+1就跳过整个数组,接着从\0后面开始向后找\0的位置
但是后面’\0‘位置不可知,所以也是随机值
(7)printf("%d\n", strlen(&arr[0] + 1));
&arr【0】取出的是第一个元素的地址,+1就是第二个元素的地址
接着从第二个元素的位置向后找\0的位置,
统计\0之前的字符个数,也就是5个
char* p = "abcdef";
printf("%d\n", sizeof(p));
printf("%d\n", sizeof(p + 1));
printf("%d\n", sizeof(*p));
printf("%d\n", sizeof(p[0]));
printf("%d\n", sizeof(&p));
printf("%d\n", sizeof(&p + 1));
printf("%d\n", sizeof(&p[0] + 1));【运行结果】:

【分析】:
指针变量p放的只是字符串的首地址,也就是字符’a‘的地址
(1)printf("%d\n", sizeof(p));
p是指针变量,也就是计算指针变量的大小,
是地址大小就是4/8个字节(32位机器是4个字节,64位是8个字节)
(2)printf("%d\n", sizeof(p + 1));p是一个char*的指针,+1向后偏移一个字节,也就指向第二个字符'b'的地址
但是它本质还是地址,所以还是4/8个字节
(3)printf("%d\n", sizeof(*p));
p指向字符a的地址,*p也就是字符’a'(char *的指针,解引用访问一个字节)
字符‘a’的大小也就是1个字节
(4)printf("%d\n", sizeof(p[0]));
通过p去访问数组,数组名相当于首元素地址,而p指向首元素地址,
p【0】也就是下标为0的元素(可以理解为p就相当于数组名)
p【0】==*(p+0)==*p,也就跟上题一样
(5)printf("%d\n", sizeof(&p));
&p是二级指针,是p(一级指针变量)的地址,类型是char **
是地址大小就是4/8个字节(32位机器是4个字节,64位是8个字节)
(6)printf("%d\n", sizeof(&p + 1));
&p是二级指针,是p(一级指针变量)的地址,
+1也就跳过一个char *类型,也就是跳过了p这个指针变量(从它的头部跳到了尾部)
是地址大小就是4/8个字节(32位机器是4个字节,64位是8个字节)
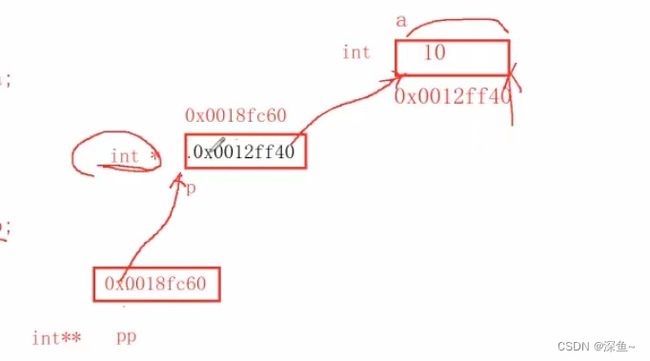
eg:
int a=10;
int *p=&a;
p+1(p本来指向a变量的头部,+1跳过一个int类型,也就跳过了一个a变量,跳到了a变量的尾部)
int **pp=&p;
pp+1(pp本来指向p指针变量的头部,+1跳过一个int*类型,也就跳过了一个p指针变量,跳到了p指针变量的尾部)
画图理解:
(7)printf("%d\n", sizeof(&p[0] + 1));
p【0】==*p, &*p==p,代表字符串首元素地址,也就是字符a的地址
p是一个char*的指针,+1向后偏移一个字节,也就指向第二个字符'b'的地址
但是它本质还是地址,所以还是4/8个字节
把sizeof改为strlen再来看看结果:
char* p = "abcdef";
printf("%d\n", strlen(p));
printf("%d\n", strlen(p + 1));
printf("%d\n", strlen(*p));
printf("%d\n", strlen(p[0]));
printf("%d\n", strlen(&p));
printf("%d\n", strlen(&p + 1));
printf("%d\n", strlen(&p[0] + 1));【运行结果】:
6
5
err
err
随机值
随机值
5
【分析】:
(1)printf("%d\n", strlen(p));
p指向字符串首字符‘a',从字符a开始向后数,直到\0,长度就为6
(2)printf("%d\n", strlen(p + 1));
p指向字符串首字符‘a',+1也就指向了第二个字符'b',
从字符b开始向后数,直到\0,长度就为5
(3)printf("%d\n", strlen(*p));
p指向字符串首字符‘a',解引用也就得到字符a
strlen收到的是97,把这个当作地址,非法访问
(4)printf("%d\n", strlen(p[0]));
p【0】也就是下标为0的元素(可以理解为p就相当于数组名),也就是字符’a‘这个元素
strlen收到的是97,把这个当作地址,非法访问
(5)printf("%d\n", strlen(&p));
&p是二级指针,指向了p(一级指针变量)的起始地址,类型是char **
在p指针内什么时候遇到\0,是未知的,所以是随机值
(6)printf("%d\n", strlen(&p + 1));
&p是二级指针,是p(一级指针变量)的地址,
+1也就跳过一个char *类型,也就是跳过了p这个指针变量(从它的头部跳到了尾部)
在p指针后面什么时候遇到\0,是未知的,所以是随机值
(7)printf("%d\n", strlen(&p[0] + 1));
p【0】就是第一个元素,&p【0】就是第一个元素的地址,
+1得到的就是第二个元素的地址,从第二个元素字符b开始数直到\0,也就是5个字节
首先来回顾一下二维数组:
1.在二维数组中,数组首元素的地址表示第一行元素的地址
2.二维数组在内存中是连续存放的
3.二维数组其实是一维数组的数组
(a【i】【j】可以将a【i】看作数组名arr,那么也就变为arr【j】)
三、二维数组
int a[3][4] = { 0 };
printf("%d\n", sizeof(a));
printf("%d\n", sizeof(a[0][0]));
printf("%d\n", sizeof(a[0]));
printf("%d\n", sizeof(a[0] + 1));
printf("%d\n", sizeof(*(a[0] + 1)));
printf("%d\n", sizeof(a + 1));
printf("%d\n", sizeof(*(a + 1)));
printf("%d\n", sizeof(&a[0] + 1));
printf("%d\n", sizeof(*(&a[0] + 1)));
printf("%d\n", sizeof(*a));
printf("%d\n", sizeof(a[3]));【运行结果】:(32位环境下)

【分析】:
(1)printf("%d\n", sizeof(a));
数组名单独放在sizeof内部,数组名表示整个数组;
计算的就是整个数组的大小;
也就是3*4(12个元素)*4(每个元素都是int类型,占四个字节)=48字节
(2)printf("%d\n", sizeof(a[0][0]));
a【0】【0】代表数组的第一个元素
因为数组的类型为int,那么一个int类型元素大小就为4字节
(3)printf("%d\n", sizeof(a[0]));
a【0】是第一行数组名,数组名单独放在sizeof内部,那么a【0】表示整个第一行数组
也就是4(第一行的四个元素)*4(int类型占4个字节)=16字节
(4)printf("%d\n", sizeof(a[0] + 1));
a【0】是第一行数组名,没有单独在sizeof内部,也没与&结合,
那么a【0】也就表示数组第一个元素的地址,此时a【0】==a【0】【0】
+1之后就是第二个元素的地址,也就相当于&a【0】【1】
是地址大小就是4/8个字节(32位机器是4个字节,64位是8个字节)
(5)printf("%d\n", sizeof(*(a[0] + 1)));
从上一题知道,a[0] + 1相当于第二个元素的地址
解引用之后也就是第二个元素,接着求第二个元素的大小
因为数组的类型为int,那么一个int类型元素大小就为4字节
(6)printf("%d\n", sizeof(a + 1));
a数组名没有单独在sizeof内部,也没与&结合,那么a就代表第一行元素的地址
+1也就是第二行元素的地址,
是地址大小就是4/8个字节(32位机器是4个字节,64位是8个字节)
a的类型为int (*)【4】(数组指针)
(7)printf("%d\n", sizeof(*(a + 1)));
两种理解方式:
1.从上题可以a + 1表示第二行元素的地址,*第二行元素的地址==第二行元素
也就是4(第二行的四个元素)*4(int类型占4个字节)=16字节
2.直接进行转换*(a+1)==a【1】,也就是第二行元素
(8)printf("%d\n", sizeof(&a[0] + 1));
a【0】是第一行数组名,单独与&结合,a【0】也就表示第一行元素
+1也就是第二行元素的地址,
是地址大小就是4/8个字节(32位机器是4个字节,64位是8个字节)
(9)printf("%d\n", sizeof(*(&a[0] + 1)));
从上题可知(&a[0] + 1)表示第二行元素的地址,
*第二行元素的地址==第二行元素
也就是4(第二行的四个元素)*4(int类型占4个字节)=16字节
(10)printf("%d\n", sizeof(*a));
a数组名没有单独在sizeof内部,也没与&结合,那么a就代表第一行元素的地址
*第一行元素的地址==第一行元素
也就是4(第一行的四个元素)*4(int类型占4个字节)=16字节
(11)printf("%d\n", sizeof(a[3]));
a【3】代表二维数组的第四行,但是没有第四行,那么这是不是就越界了呢?
这里我们就要理解sizeof的内部逻辑:
表达式有两种属性:
1.值属性:2+3=5
2.类型属性:a==int(这里的变量a代表int类型)
eg:sizeof(a),算sizeof(int)就行,不会真的去访问
sizeof不会真的去算a【3】,而是根据类型计算,sizeof看来a【3】就等于a【0】
所以sizeof(a[3])并没有越界
a【0】是第一行数组名,数组名单独放在sizeof内部,那么a【0】表示整个第一行数组
也就是4(第一行的四个元素)*4(int类型占4个字节)=16字节
本次内容就到此啦,欢迎评论区或者私信交流,觉得笔者写的还可以,或者自己有些许收获的,麻烦铁汁们动动小手,给俺来个一键三连,万分感谢 !
