面试必问!Redis 缓存雪崩、穿透、击穿(视频+理论)
大家好,我是徐庶老师,专注java,想要学习java的同学可以欢迎关注我。
结合视频观看效果更佳哦:Redis 击穿 雪崩 穿透——十分钟理论+实战彻底搞懂_哔哩哔哩_bilibili
前言
为了提高服务器并发量,通常会将一些热点数据先缓存,没有再请求数据库, 给数据库做了一层保护:
请求进来先从缓存中取数据,缓存取不到则去数据库中取,数据库取到了则返回给前端,然后更新缓存,如果数据库取不到则返回空数据给前端

/**
* 通过发货单查询物流信息
*/
public ExpressInfo findByDeliveryOrderId(Long id) {
String key="xushu-express:express-info:"
//从 Redis 查询物流信息
Object obj = redisTemplate.opsForValue().get(key + id);
if (obj != null) {
return (ExpressInfo) obj;
} else {
ExpressInfo expressInfo = expressMapper.selectByDeliveryOrderId(id);//数据库查询
if (expressInfo != null) {
redisTemplate.opsForValue().set(key + id, expressInfo,Duration.ofHours(2L));
return expressInfo;
} else {
throw new ClientException("发货单:{} 的物流信息不存在", id);
}
}
}
假如缓存的数据没有,后台则会一直请求数据库,对数据库造成压力,如果是请求量大或者恶意请求则会导致数据库崩溃,我们一般称为缓存穿透、缓存击穿、缓存雪崩。
缓存击穿
缓存击穿是指单个热点缓存中没有但数据库中有的数据

解决方案
1. 互斥锁
当热点key过期后,大量的请求涌入时,只有第一个请求能获取锁并阻塞,此时该请求查询数据库,并将查询结果写入redis后释放锁。后续的请求直接走缓存。
/**
* 查询商品分类信息
*/
@SuppressWarnings("unchecked")
public List<ProductCategory> findProductCategory() {
String key="product:product-category"
Object obj = redisTemplate.opsForValue().get(key);
if (obj == null) {
synchronized (this){
//进入 synchronized 一定要先再查询一次 Redis,防止上一个抢到锁的线程已经更新过了
obj = redisTemplate.opsForValue().get(key);
if(obj != null){
return (List<ProductCategory>) obj;
}
List<ProductCategory> categoryList = productCategoryMapper.selectProductCategory();
redisTemplate.opsForValue().set(key, categoryList, Duration.ofHours(2L));
}
return categoryList;
} else {
return (List<ProductCategory>) obj;
}
}
这里的场景没有必要一定使用分布式锁
你可能会奇怪,为什么这里不用分布式锁,毕竟我们生产环境的商品服务实例肯定是集群,使用 synchronized(this) 只能保证当前应用实例同时只有一个请求执行这段代码,不能保证集群中其他实例。值得注意的是我们这里并不是要对数据进行安全修改,我们仅仅是想要防止大量请求访问到 MySQL ,假设现在商品服务是 10 个实例组成的集群,那么这里的代码最坏的情况也就是 10 个请求同时访问 MySQL 查询,问题不大~~ 当然使用分布式锁肯定也没问题
其实,大多数情况下这种爆款很难对数据库服务器造成压垮性的压力。达到这个级别的公司没有几家的。所以,互斥锁因地制宜。只需对主打商品提前做好了准备,让缓存永不过期。即便某些商品自己发酵成了爆款,也是直接设为永不过期就好了,大道至简:
2. 永不过期
不设置过期时间
快过期时再次重新设置过期时间(异步、定时任务)
@Autowired
private ThreadPoolTaskExecutor poolTaskExecutor;
String getProduct(final String key) {
ValueOperations opsForValue = redisTemplate.opsForValue();
V v = opsForValue.get(key);
String value = v.getValue();
// 预存的超时时间
long timeout = v.getTimeout();
if (v.timeout <= System.currentTimeMillis()) {
// 异步更新后台异常执行
poolTaskExecutor.execute(new Runnable() {
public void run() {
String keyMutex = "mutex:" + key;
// 设置3min的超时,防止delete操作失败的时候,下次缓存过期一直不能load db
if (opsForValue.setIfAbsent(keyMutex, "1",3,TimeUnit.MINUTES)) {
Object product = db.query(key);
opsForValue.set(key, product, 60, TimeUnit.MINUTES);
redisTemplate.delete(keyMutex);
}
}
});
}
return value;
}
缓存雪崩
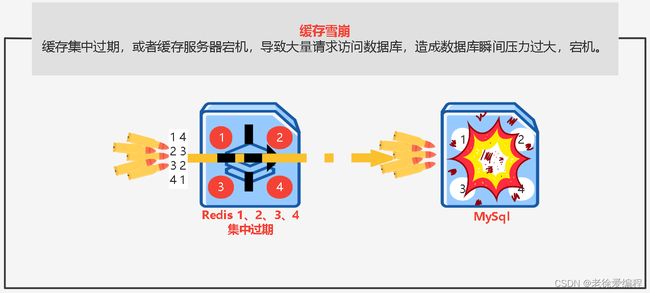
解决方案:
1. 随机失效时间
给缓存失效时间加上一个随机值,避免大量缓存集体失效。
/**
* 查询商品分类信息
*/
@SuppressWarnings("unchecked")
public List<ProductCategory> findProductCategory() {
String key="product:product-category"
Object obj = redisTemplate.opsForValue().get(key);
if (obj == null) {
synchronized (this){
//进入 synchronized 一定要先再查询一次 Redis,防止上一个抢到锁的线程已经更新过了
obj = redisTemplate.opsForValue().get(key);
if(obj != null){
return (List<ProductCategory>) obj;
}
List<ProductCategory> categoryList = productCategoryMapper.selectProductCategory();
Duration expire = Duration.ofHours(2L).plus(Duration.ofSeconds((int) (Math.random() * 100)));
redisTemplate.opsForValue().set(key, categoryList,expire);
}
return categoryList;
} else {
return (List<ProductCategory>) obj;
}
}
2. 永不过期
- 不设置过期时间 快过
- 期时再次重新设置过期时间(异步、定时任务)
缓存穿透
缓存穿透是指缓存和数据库中都没有的数据

解决方案:
1. 参数校验
数据有效性校验,不符合数据库查询规则,直接返回空 (无法完全杜绝)。
2. 缓存空对象
简单粗暴(我以前采用的就是这种),如果一个查询返回的数据为空(不管是数 据存不存在),我们仍然把这个空结果进行缓存,记住设置它的过期时间,因为这个id以后可能会有数据。
public Object getProduct(String key) {
// 从缓存中获取数据
ValueOperations opsForValue = redisTemplate.opsForValue();
Object product = opsForValue.get(key);
// 缓存为空
if (product==null) {
// 从存储中获取
product = db.query(key);
opsForValue.set(key, product);
//设置一个过期时间(300到600之间的一个随机数)
int expireTime = new Random().nextInt(300) + 300;
if (product == null) {
redisTemplate.expire(key, expireTime,TimeUnit.SECONDS);
}
return product;
} else {
// 缓存非空
return product;
}
}
布隆过滤器
使用布隆过滤器存储所有可能访问的 key,不存在的 key 直接被过滤,存在的 key 则再进一步查询缓存和数据库。
可以用布隆过滤器先做一次过滤,对于不存在的数据布隆过滤器一般都能够过滤掉,不让请求再往后端发送。当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在(概率可调控)。

布隆过滤器就是一个大型的位数组和几个不一样的无偏 hash 函数。所谓无偏就是能够把元素的 hash 值算得比较均匀。
向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash 算得一个整数索引值然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为 1 就完成了 add 操作。
向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看位数组中这几个位置是否都为 1,只要有一个位为 0,那么说明布隆过滤器中这个key 不存在。如果都是 1,这并不能说明这个 key 就一定存在,只是极有可能存在,因为这些位被置为 1 可能是因为其它的 key 存在所致。如果这个位数组比较稀疏,这个概率就会很大,如果这个位数组比较拥挤,这个概率就会降低。
这种方法适用于数据命中不高、 数据相对固定、 实时性低(通常是数据集较大) 的应用场景, 代码维护较为复杂, 但是缓存空间占用很少。
可以用redisson实现布隆过滤器,引入依赖:
<dependency>
<groupId>org.redissongroupId>
<artifactId>redissonartifactId>
<version>3.6.5version>
dependency>
示例伪代码:
package com.redisson;
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class RedissonBloomFilter {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
//初始化布隆过滤器:预计元素为100000000L,误差率为3%,根据这两个参数会计算出底层的bit数组大小
bloomFilter.tryInit(100000000L,0.03);
//将zhuge插入到布隆过滤器中
bloomFilter.add("zhuge");
//判断下面号码是否在布隆过滤器中
System.out.println(bloomFilter.contains("guojia"));//false
System.out.println(bloomFilter.contains("baiqi"));//false
System.out.println(bloomFilter.contains("zhuge"));//true
}
}
使用布隆过滤器需要把所有数据提前放入布隆过滤器,并且在增加数据时也要往布隆过滤器里放,布隆过滤器缓存过滤伪代码:
//初始化布隆过滤器
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
//初始化布隆过滤器:预计元素为100000000L,误差率为3%
bloomFilter.tryInit(100000000L,0.03);
//把所有数据存入布隆过滤器
void init(){
for (String key: keys) {
bloomFilter.put(key);
}
}
String get(String key) {
// 从布隆过滤器这一级缓存判断下key是否存在
Boolean exist = bloomFilter.contains(key);
if(!exist){
return "";
}
// 从缓存中获取数据
String cacheValue = cache.get(key);
// 缓存为空
if (StringUtils.isBlank(cacheValue)) {
// 从存储中获取
String storageValue = storage.get(key);
cache.set(key, storageValue);
// 如果存储数据为空, 需要设置一个过期时间(300秒)
if (storageValue == null) {
cache.expire(key, 60 * 5);
}
return storageValue;
} else {
// 缓存非空
return cacheValue;
}
}
注意:布隆过滤器不能删除数据,如果要删除得重新初始化数据。
public ExpressInfo findByDeliveryOrderId(Long id) {
RBloomFilter<Long> bloomFilter = redissonClient.getBloomFilter("xushu-product:bloom-filter:express-info");
if(!bloomFilter.contains(id)){
throw new ClientException("发货单:{} 的物流信息不存在", id);
}
}