正确设置PyTorch训练时使用的GPU资源
背景:
最近在使用Hugging Face的transformers api来进行预训练大模型的微调,机器是8卡的GPU,当我调用trainer.train()之后,发现8个GPU都被使用了,因为这个机器上面还有其他人跑的模型,当我进行训练的时候,GPU的使用率就接近了100%,这样导致其他人的模型响应速度特别的慢,因为他们使用的是4~7四张卡,所以我需要避开这四张卡,那怎么设置我的模型在指定的卡上面训练呢?
机器环境:NVIDIA A100-SXM
transformers版本:4.32.1
torch版本:2.0.1
方式一【失败】
通过导入os来设置GPU的可见性,代码如下:
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "2,3"通过设置环境变量CUDA_VISIBLE_DEVICES来指定torch可见的GPU,当这样设置之后,运行程序,程序会抛出如下错误:
Traceback (most recent call last):
File "/data2/.env/lib/python3.9/site-packages/torch/cuda/__init__.py", line 260, in _lazy_init
queued_call()
File "/data2/.env/lib/python3.9/site-packages/torch/cuda/__init__.py", line 145, in _check_capability
capability = get_device_capability(d)
File "/data2/.env/lib/python3.9/site-packages/torch/cuda/__init__.py", line 381, in get_device_capability
prop = get_device_properties(device)
File "/data2/.env/lib/python3.9/site-packages/torch/cuda/__init__.py", line 399, in get_device_properties
return _get_device_properties(device) # type: ignore[name-defined]
RuntimeError: device >= 0 && device < num_gpus INTERNAL ASSERT FAILED at "../aten/src/ATen/cuda/CUDAContext.cpp":50, please report a bug to PyTorch.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "
File "/data2/.env/lib/python3.9/site-packages/torch/cuda/__init__.py", line 395, in get_device_properties
_lazy_init() # will define _get_device_properties
File "/data2/.env/lib/python3.9/site-packages/torch/cuda/__init__.py", line 264, in _lazy_init
raise DeferredCudaCallError(msg) from e
torch.cuda.DeferredCudaCallError: CUDA call failed lazily at initialization with error: device >= 0 && device < num_gpus INTERNAL ASSERT FAILED at "../aten/src/ATen/cuda/CUDAContext.cpp":50, please report a bug to PyTorch.
方式二【成功】
通过export来设置GPU的可见性,代码如下:
export TRANSFORMERS_OFFLINE=1
export HF_DATASETS_OFFLINE=1
export CUDA_VISIBLE_DEVICES=1,2
export CUDA_DEVICE_ORDER=PCI_BUS_ID
nohup python data_train.py > log/log.txt 2>&1 &设置CUDA_VISIBLE_DEVICES=1,2,表示只使用1号和2号GPU
使用ps-ef |grep python找到我程序对应的进程号,进程号为:27378
再通过使用nvidia-smi来查看GPU的使用情况:
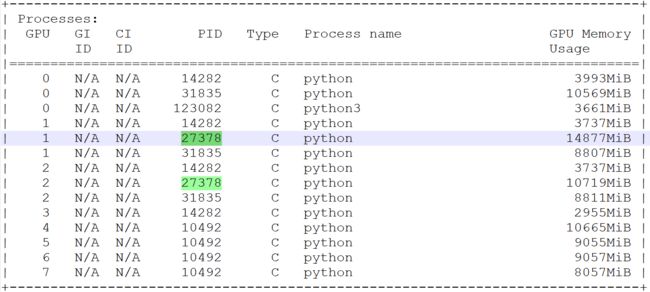
从上图中可以很明显的看到进程27378使用的是1号和2号卡
困惑:
1、为什么通过使用导入os来设置环境变量无法达到目的,而使用Linux的export却可以?