UnityShader入门精要个人总结--基础篇(一)
一篇仅为个人总结学习的blog,参考内容包括不限于毛星云rtr3提炼总结,插图基本上来自入门精要和提炼总结
第二章 渲染管线
感觉跟之前学到的划分方式有些不同,对比了毛的rtr3提炼书也是这种划分,还是这种方式更好啊
三个大阶段
这里划分成了三个大的阶段:应用阶段、几何阶段、光栅化
1. 应用阶段
总结
这个阶段主要是准备,从CPU为起点给到GPU,包括场景数据,包括相机位置视锥体等等,再进行一个粗粒度剔除裁剪不可见物体,最后设置渲染状态(材质纹理使用哪些shader),得到一个 渲染图元(点线三角形面) 给到几何阶段
细分
- 数据加载到显存
- 设置渲染状态
- 调用DrawCall
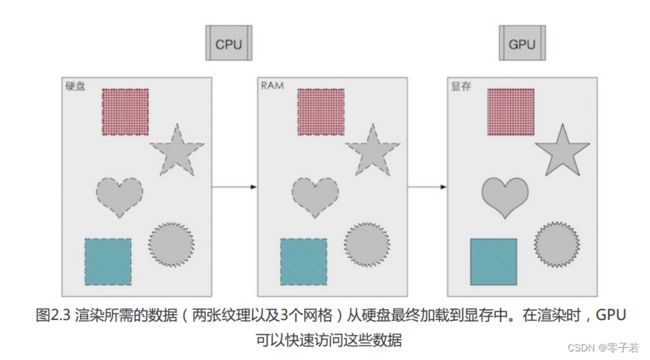
(1)数据加载到显存
渲染数据 :从硬盘 --> 系统内存(RAM) --> 显存
为什么要加载到显存(显卡)上?(鄙人操作系统严重没学好,你学好了可以跳过这段笔记…)
首先,显卡对显存访问数据是更快的,甚至很多显卡对RAM没有数据访问权限,所以要加载到显存
那么显卡对于渲染的意义是什么?
这不得不说GPU与显卡的关系,GPU(Graphic Processing Unit--图形处理器)是显卡的核心部件之一,还有显存,主板散热器so on。
所以渲染的起点是CPU,数据最后给到GPU
(2)设置渲染状态
原书的话:状态就是定义场景中网格如何被渲染。 包括使用哪些着色器(像曲面细分着色器/几何shader都是可选的),还有光源材质等等
(3)调用DrawCall
就是CPU向GPU发出的一个渲染命令(CPU:快来渲染这个东西 GPU:OK!)
DrawCall为什么影响效率?如何减少?
1 因为每次调用DrawCall,CPU会进行准备内容给到GPU,渲染没有差异,但是DrawCall越多CPU更多时间都在提交DrawCall上降低效率
2 解决方法是批处理,把小DrawCall合并成大的,更适合静态的物体。避免使用很小的网格,避免使用太多材质
因此以下2、3阶段都是在GPU进行
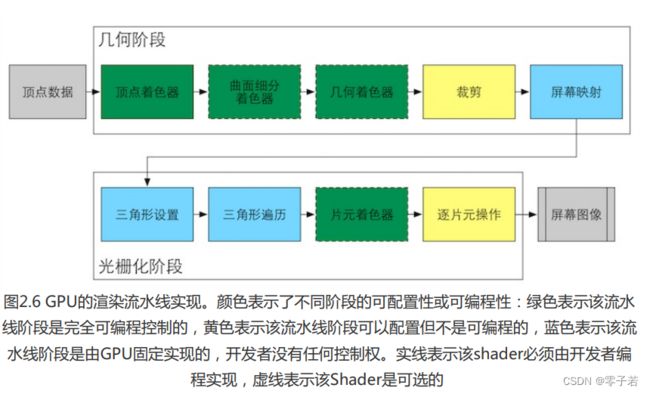
2. 几何阶段
总结
这个阶段负责大多数顶点和多边形几乎所以几何相关的事情,需要绘制的图元是什么,如何绘制,在哪里绘制。
细分
- 顶点着色器
- 投影
- 裁剪
- 屏幕映射
(1)顶点着色器
这里主要是两个任务是坐标变换和顶点着色,毛是细分了两个阶段,冯的书是合为顶点着色器,本质是一样的。
坐标变换:将模型变换到适合渲染的空间当中
经典的MVP变换过程,把顶点坐标从模型空间转换到齐次裁剪空间内。
逐顶点光照 :目的在于确定模型上顶点处材质的光照效果。
所谓的Shader,着色器,确定材质上的光照效果的这种操作被称为着色
坐标转换完毕我还需要知道这个坐标会显示成啥样吧,逐顶点着色根据着色方程,计算出这个结果,包括颜色纹理坐标等等,把这个结果丢到光栅化。
(2)投影
将模型从三维空间投射到了二维的空间中的过程
这里注意一个概念NDC,归一化设备坐标,最后能看到的模型的坐标都会被放在一个[-1,1]的cube里,这就是归一化。通常是正交和透视投影两种,具体如何归一化可以参考Games101
(3)裁剪
很好理解,在规范立方体内才会被显示,其他的摄像机看不到也不需要被渲染,所以其他部分进行裁剪。
(4)屏幕映射
主要是视口变换,放在cube里的三维坐标如何映射到二维屏幕进行显示。那么主要是矩阵缩放变换,[-1,1] 到宽width高height的屏幕进行一个缩放。
但是注意,还有一个Z轴方向的数据,这个阶段不做处理,但是数据会被传下去,这是重要的深度参考信息。
3. 光栅化
总结
将二维屏幕上的点转变为像素。顶点间缺少的像素插值补充。
主要分为两步,图元覆盖了那些像素,计算他们最终的颜色。
细分
- 三角形设置
- 三角形遍历
- 片元着色器
- 输出合并(逐片元操作)
(1)三角形设置
之前得到的一系列顶点数据,把它们装配成我们需要的三角形网格。
(2)三角形遍历
检查像素是否被三角形覆盖,覆盖则生成片元。
这一阶段包括了插值操作,三角形顶点的信息对整个覆盖区域插值。
注意片元与像素的区分
片元并不是真正意义上的像素,而是很多状态的集合,包括深度发现纹理坐标,最后需要一系列测试才会成为像素
(3)片元着色器
通过插值的结果,输出颜色值。因此这一阶段最重要的纹理贴图,得到像素颜色。
但是至此,屏幕具体的像素都没有任何变化,这些都是预备的数据,直到输出合并
(4)输出合并(逐片元操作)

模板测试:那就需要模板buffer。跟深度测试类似,但更像是一个mask,设定一个固定值,mask内显示,以外不显示
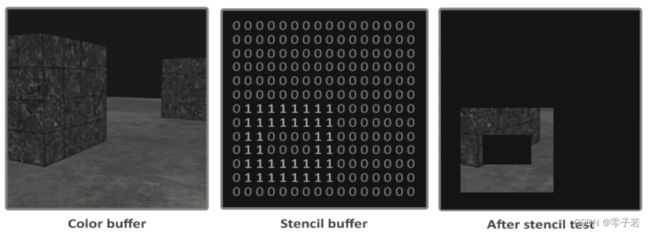
深度测试:相机只能看到近处的,被遮挡的远的物体看不到就无需渲染;
最典型就是Z-Buffer技术,只有更近的物体才有资格更新frame。
混合
这里还提到了关于透明物体渲染的一些Tips:
众所周知,不透明的物体当然是看到最近的,那么透明的呢?需要进行片元着色器中的颜色和颜色缓冲器的颜色混合。举个例子,一个玻璃放在眼前,我既可以看到玻璃,又可以看到玻璃之后的,实际看到的是这两个颜色的混合
unity中深度测试在片元着色器前,这称为Early-Z ,先判断出近处图形,再计算像素,更加高效,但是问题在于透明的物体就无法渲染了,因为远方的物体已经被剔除掉了。
4.结尾(双缓冲)
渲染中的图元必定是不能显示的,就像舞台更改背景,背景准备完毕,红布一拉,舞台展现在众人眼前。
双缓冲分为前置和后置缓冲 前置就是能看到的显示在屏幕上的图像,后置就是渲染中的,GPU不断交换两者内容,保证看到的都是连续的画面。