Go应用服务疑似内存泄露问题排查
背景
为了保障业务的可用性,增加应用服务请求依赖服务(grpc、http)的熔断降级策略,避免依赖服务不可用的情况下,出现级联服务故障产生雪崩,通过熔断降级尽可能把影响缩放到最小。
因此需要在go应用服务中接入熔断组件,组件我们选择了:阿里开源的sentinel circuitbreaker,一顿封装后,项目接入、压测、验证并成功上线,同时上线后也进行了跟进了几个小时,一切正常。
几天后,在一次常规性的应用服务的资源监控巡查中发现内存资源使用有些异常。

看时间节点就是从熔断组件集成到项目后,就开始出现了内存的持续增长,看监控数据估算了下,一天增长10~20MB左右,还蛮有规律的。
难道是熔断组件导致的内存泄露?于是就先回滚了熔断相关内容,继续观察内存使用情况,发现内存恢复正常平稳的状态。已经确定是熔断问题导致的内存增长的问题。但是还没定位到具体是什么原因导致的这个问题,毕竟这个组件是阿里开源,并且在社区中感受好评,不应该有这种问题,还是要给与respect,带着这个疑惑,开始了内存泄露的排查之路。
排查
首先在测试环境进行压测,并发压测qps 300+,看资源监控无法复现线上的情况。
组件的使用上也只是对多做了一层的封装,并没有做了什么消耗内存的附加操作,但还是要先自我怀疑,进行了封装熔断代码重新审查,也对一些地方做了改造,通过排除法进行压测对比,也没定位到什么问题。
应用项目加入性能分析采集,使用pprof工具进行,对当前使用中(inuse_space)的堆内存进行分析,并且在测试环境中,对发布和压测后的heap采集进行diff对比,也没发现哪个代码会导致内存泄露的问题。因为测试环境无法复现,又将性能分析采集发布到生产上,跟了几天,依然无法定位问题。
一直无法定位到问题,于是开始怀疑Prometheus里监控的k8s pod 内存指标数值的准确性。查阅资料,发现端倪。
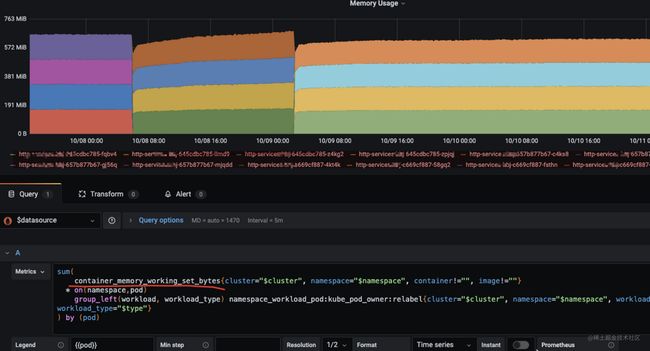
container_memory_working_set_bytes 指标统计的内存是包含(RSS+ Cache)其中cache 包含file cache,系统内核为了提高磁盘IO的效率,将读写过的文件缓存在内存中。file cache并不会随着进程退出而释放,只会当容器销毁或者系统内存不足时才会由系统自动回收。
但是因为应用服务没有做文件操作,所以也就不以为然,看看就过去了。
又历经了几天的排查,已经毫无思绪,继续review代码,最终在初始化sentinel circuitbreaker代码中,发现熔断组件会默认刷日志到文件。
// NewDefaultConfig creates a new default config entity.
func NewDefaultConfig() *Entity {
return &Entity{
// .....
Log: LogConfig{
Logger: nil,
Dir: GetDefaultLogDir(),
UsePid: false,
Metric: MetricLogConfig{
SingleFileMaxSize: DefaultMetricLogSingleFileMaxSize,
MaxFileCount: DefaultMetricLogMaxFileAmount,
FlushIntervalSec: DefaultMetricLogFlushIntervalSec,
},
},
// .....
},
}
}
然后回想起来k8s 使用内存监控指标中包含file cache的问题。就此真正原因浮出水面了。
让运维帮忙查看线上日志:

可以看出每日的日志文件占用存储空间与之前监控的每天增长的内存范围差不多。
最终代码改造:
# ....
// sentinel 初始化
conf := config.NewDefaultConfig()
// 设置不刷日志到文件(注意:k8s的使用内存指标包含:rss + file cache,使用写日志文件,会导致k8s pod监控的内存持续增长)
conf.Sentinel.Log.Metric.FlushIntervalSec = 0
# ....
剧终~
番外 - 验证
k8s中 memory.usage = working_set = memory.usage_in_bytes - total_inactive_file 根据cgroup memory关系有: memory.usage_in_bytes = memory.kmem.usage_in_bytes + rss + cache
memory.usage_in_bytes的统计数据是包含了所有的file cache的,total_active_file和total_inactive_file都属于file cache的一部分。
所以采用memory.usage_in_bytes - total_inactive_file计算出的结果并不是当前Pod中应用程序所占用的内存,当Pod内存资源紧张时total_active_file也是可回收利用的。
Docker容器内存相关状态:
cd /sys/fs/cgroup/memory
cat memory.stat
# 输出
cache 1470464
rss 35373056
rss_huge 0
mapped_file 864256
swap 0
pgpgin 32152
pgpgout 23157
pgfault 35743
pgmajfault 4
inactive_anon 0
active_anon 35332096
inactive_file 1466368
active_file 4096
unevictable 0
hierarchical_memory_limit 1073741824
hierarchical_memsw_limit 1073741824
total_cache 1470464
total_rss 35373056
total_rss_huge 0
total_mapped_file 864256
total_swap 0
total_pgpgin 0
total_pgpgout 0
total_pgfault 0
total_pgmajfault 0
total_inactive_anon 0
total_active_anon 35332096
total_inactive_file 1466368
total_active_file 4096
total_unevictable 0
通过 shell 脚本,循环写内容到文件
s=""
for ((i=1; i<=500000; i++))
do
s=$s$i;
ns="${s}\r\n";
# echo $ns;
echo $ns >> test.log
done
进过多次的执行shell,对比
before:
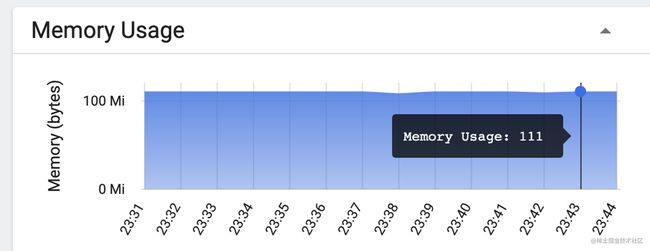
after:

可以明显看到,每次执行shell脚本,循环写入文件,文件越写越大,k8s pod内存监控使用内存不断地增长,并且没有释放掉。
参考:
- Grafana上监控kubernetes中Pod已用内存不准问题分析
- K8S问题排查-Pod内存占用高
- golang:快来抓住内存泄漏的“真凶”!
- Go内存泄漏?不是那么简单!