Flink 必知必会经典课程2:Stream Processing with Apache Flink
简介: 本篇内容包含三部分展开介绍Stream Processing with Apache Flink:1、并行处理和编程范式;2、DataStream API概览及简单应用;3、 Flink 中的状态和时间。
作者|崔星灿
本篇内容包含三部分展开介绍Stream Processing with Apache Flink:
- 并行处理和编程范式
- DataStream API概览及简单应用
- Flink 中的状态和时间
一、并行处理和编程范式
众所周知,对于计算密集型或数据密集型这样需要计算量比较大的工作,并行计算或分而治之是解决这一类问题非常有效的手段。在这个手段中比较关键的部分是,如何对一个已有任务的划分,或者说如何对计算资源进行合理分配。
举例说明,上学期间老师有时会找同学来协助批阅考试试卷。假如卷子里面一共有ABC三个题,那么同学可能会有如下分工协作方式。
- 方式一:将所有试卷的三个题分别交给不同的人来批阅。这种方式,每个批阅的同学批自己负责的题目后就可以把试卷传给下一个批阅同学,从而形成一种流水线的工作效果。因为总共只有三道题目,这种流水线的协作方式会随着同学数量的增加而难以继续扩展。
- 方式二:分工方式一的扩展,同一题目允许多个同学来共同批阅,比如A题目由两个同学共同批阅,B题目由三个同学批阅,C题目只由一个同学批阅。这时候我们就需要考虑怎样进一步的对计算任务做划分。比如,可以把全部同学分成三组,第一组负责A题目,第二个组负责B题目第三个组负责C。第一个组的同学可以再次再组内进行分工,比如A组里第一个同学批一半的卷子,第二个同学批另一半卷子。他们分别批完了之后,再将自己手里的试卷传递给下一个组。
像上述按照试卷内题目进行划分,以及讲试卷本身进行划分,就是所谓的计算的并行性和数据并行性。

我们可以用上面有向无环图来表示这种并行性。
在图中,批阅A题目的同学,假设还承担了一些额外任务,比如把试卷从老师的办公室拿到批阅试卷的地点;负责C题的同学也额外任务,就是等所有同学把试卷批完后,进行总分的统计和记录上交的工作。据此,可以把图中所有的节点划分为三个类别。第一个类别是Source,它们负责获取数据(拿试卷);第二类是数据处理节点,它们大多时候不需要和外部系统打交道;最后一个类别负责将整个计算逻辑写到某个外部系统(统分并上交记录)。这三类节点分别就是Source节点、Transformation节点和Sink节点。DAG图中,节点表示计算,节点之间的连线代表计算之间的依赖。
关于编程的一些内容

假设有一个数据集,其中包含1~10十个数字,如果把每一个数字都乘以2并做累计求和操作(如上图所示)怎么操作呢?办法有很多。
如果用编程来解决有两个角度:第一种是采取命令式编程方式,一步一步的相当于告诉机器应该怎样生成一些数据结构,怎样的用这些数据结构去存储一些临时的中间结果,怎样把这些中间结果再转换成为最终的结果,相当于一步一步告诉机器如何去做;第二种是声明的方式,声明式编程里通常只需要告诉机器去完成怎样的任务,而不需要像命令式那样详细传递。例如我们可以把原有的数据集转化成一个Stream,然后再把 Stream转化成一个Int类型的Stream,在此过程中,把每一个数字都乘2,最后再调用 Sum方法,就可以获得所有数字的和。
声明式编程语言的代码更简洁,而简洁的开发方式,正是计算引擎追求的效果。所以在 Flink 里所有与任务编写相关的API,都是偏向声明式的。
二、DataStream API概览及简单应用
在详细介绍DataStream API之前,我们先来看一下 Flink API的逻辑层次。
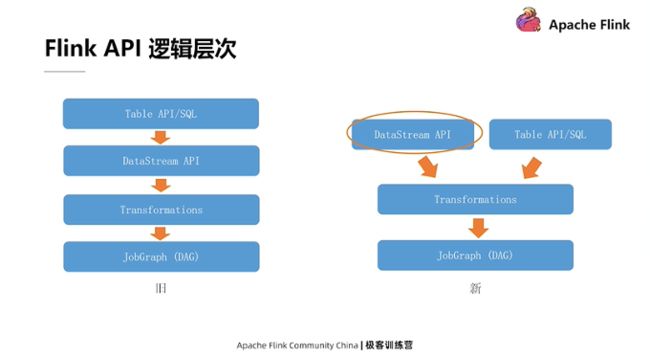
在旧版本的 Flink 里,它的API层次遵循上图左侧这样四层的关系。最上层表示我们可以用比较高级的API,或者说声明程度更高的Table API以及SQL的方式来编写逻辑。所有SQL和Table API编写的内容都会被Flink内部翻译和优化成一个用DataStream API实现的程序。再往下一层,DataStream API的程序会被表示成为一系列Transformation,最终 Transformation会被翻译成JobGraph(即上文介绍的DAG)。
而在较新版本的 Flink 里发生了一些改变,主要的改变体现在 Table API 和 SQL 这一层上。它不再会被翻译成 DataStream API 的程序,而是直接到达底层 Transformation 一层。换句话说,DataStream API 和 Table API 这两者的关系,从一个下层和上层的关系变为了一个平级的关系,这样流程的简化,会相应地带来一些查询优化方面的好处。
接下来我们用一个简单的 DataStream API 程序作为示例来介绍,还是上文乘2再求和的需求。

如果用 Flink 表示,它的基本代码如上图所示。看上去比单机的示例要稍微的复杂一点,我们一步一步来分解看。
- 首先,用 Flink 实现任何功能,一定要获取一个相应的运行环境,也就是 Sream Execution Environment;
- 其次,在获取环境后,可以调用环境的 add Source 方法,来为逻辑添加一个最初始数据源的输入;设置完数据源后可以拿到数据源的引用,也就是 Data Source 对象;
- 最后,可以调用一系列的转换方法来对 Data Source 中的数据进行转化。
这种转化如图所示,就是把每个数字都×2,随后为了求和我们必须利用 keyBy 对数据进行分组。传入的常数表示把所有的数据都分到一组里边,最后再对这个组里边的所有的数据,按照第一个字段进行累加,最终得到结果。在得到结果后,不能简单的像单机程序那样把它输出,而是需要在整个逻辑里面加一个的 Sink 节点,把所有的数据写到目标位置。上述工作完成后,要去调用 Environment 里面 Execute 方法,把所有上面编写的逻辑统一提交到远程或者本地的一个集群上执行。
Flink DataStream API 编写程序和单机程序最大的不同就在于,它前几步的过程都不会触发数据的计算,而像在绘制一个 DAG 图。等整个逻辑的 DAG 图绘制完毕之后,就可以通过 Execute 方法,把整个的图作为一个整体,提交到集群上去执行。
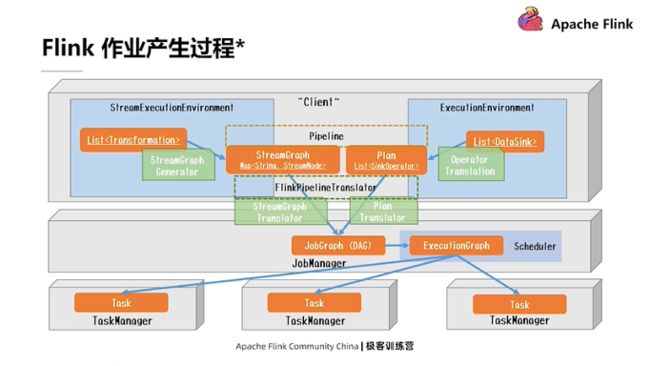
介绍到这里,就把Flink DataStream API和DAG图联系在一起了。 事实上,Flink 任务具体的产生过程比上面描述的要复杂得多,它要经过一步步转化和优化等,下图展示了Flink 作业的具体生成过程。
DataStream API里提供的转换操作
就像上文在示例代码中展示的,每一个 DataStream对象,在被调用相应方法的时候,都会产生一个新的转换。相应的,底层会生成一个新的算子,这个算子会被添加到现有逻辑的DAG图中。相当于添加一条连线来指向现有DAG图的最后一个节点。所有的这些API在调动它的时候都会产生一个新的对象,然后可以在新的对象上去继续调用它的转换方法。就是像这种链式的方式,一步一步把这个DAG图给画出来。
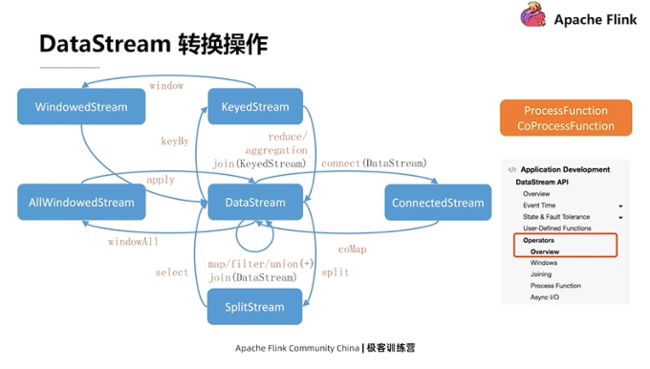
上述解释涉及到了一些高阶函数思想。每去调用 DataStream上的一个转换时,都需要给它传递的一个参数。换句话说,转换决定了你想对这个数据进行怎样的操作,而实际传递的包在算子里面的函数决定了转换操作具体要怎样完成。
上图中,除了左边列出来的 API, Flink DataStream API 里面还有两个非常重要的功能,它们是 ProcessFunction以及 CoProcessFunction。这两个函数是作为最底层的处理逻辑提供给用户使用的。上图所有左侧蓝色涉及的转换,理论上来讲都可以用底层的ProcessFunction和CoProcessFunction去完成。
关于数据分区
数据分区是指在传统的批处理中对数据Shuffle的操作。如果把扑克牌想成数据,传统批处理里的Shuffle操作就相当于理牌的过程。一般情况下在抓牌过程中,我们都会把牌理顺排列好,相同的数字还要放在一起。这样做最大的好处是,出牌时可以一下子找到想出的牌。Shuffle是传统的批处理的方式。因为流处理所有的数据都是动态来的,所以理牌的过程或者说处理数据,进行分组或分区的过程,也是在线来完成的。
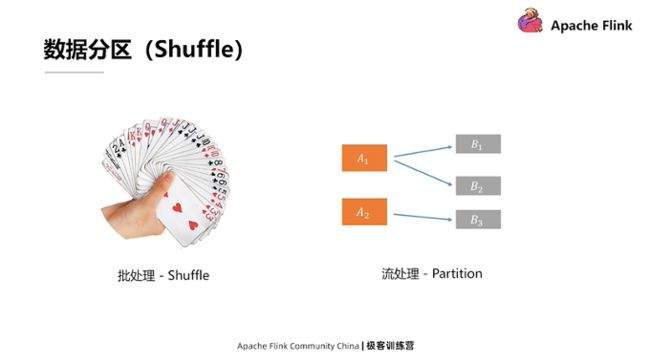
例如上图右侧所示,上游有两个算子A的处理实例,下游是三个算子B处理实例。这里展示的流处理等价于Shuffle的操作被称为数据分区或数据路由。它用来表示A处理完数据后,要把结果发到下游B的哪个处理实例上。
Flink 里提供的分区策略
图X是 Flink 提供的分区策略。需要注意的是, DataStream调用keyBy方法后,可以把整个数据按照一个Key值进行分区。但要严格来讲,其实keyBy并不算是底层物理分区策略,而是一种转换操作,因为从API角度来看,它会把DataStream转化成 KeyedDataStream的类型,而这两者所支持的操作也有所不同。

所有这些分区策略里,稍微难理解的可能是Rescale。Rescale涉及到上下游数据本地性的问题,它和传统的Rebalance,即Round-Pobin,轮流分配类似。区别在于Rescale是它会尽量避免数据跨网络的传输。
如果所有上述的分区策略都不适用的话,我们还可以自己调用 PartitionCustom去自定义一个数据的分区。值得注意的是,它只是自定义的单播,即对每一个数据只能指定它一个下游所要发送的实例,而没有办法把它复制成多份发送到下游的多个实例中。
Flink支持的连接器
上文介绍过,图X里有两个关键的节点:A节点,需要去连接外部系统,从外部系统把数据读取到 Flink的处理集群里;C节点,即Sink节点,它需要汇总处理完的结果,然后把这个结果写入到某个外部系统里。这里的外部系统可以是一个文件系统,也可以是一个数据库等。
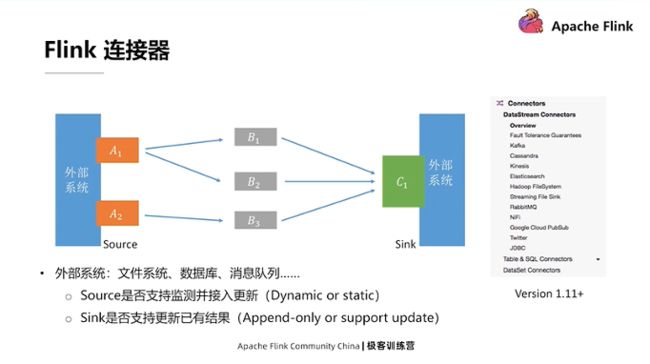
Flink 里的计算逻辑可以没有数据输出,也就是说可以不把最终的数据写出到外部系统,因为Flink里面还有一个State的状态的概念。在中间计算的结果实际上是可以通过 State暴露给外部系统,所以允许没有专门的Sink。但每一个 Flink 应用都肯定有Source,也就是说必须从某个地方把数据读进来,才能进行后续的处理。
关于 Source和Sink两类连接器需要关注的点如下:
- 对于Sourse而言,我们往往比较关心是否支持续监测并接入数据更新,然后把相应的更新数据再给传输到这个系统当中来。举例来说,Flink对于文件有相应的FileSystem连接器,例如CSV文件。CSV文件连接器在定义时,可以通过参数指定是否持续监测某个目录的文件变化,并接入更新后的文件。
- 对于Sink来讲,我们往往关心要写出的外部系统是否支持更新已经写出的结果。比如要把数据写到Kafka里,通常情况下数据写入是一种Append-Only,即不能修改已经写入系统里的记录(社区正在利用Kafka Compaction实现Upsert Sink);如果是写入数据库,那么通常可以支持利用主键对现有数据进行更新。
以上两个特性,决定了Flink 里连接器是面向静态数据还是面向动态的数据的关键点。
提醒,上面截图是 Flink 1.11版本之后的文档,连接器在 Flink 1.11 版本里有较大重构。另外,关于Table、SQL、API这个层面的连接器,比起DataStream层面的连接器,会承担更多的任务。比如是否支持一些谓词或投影操作的下推等等。这些功能可以帮助提高数据处理的整体性能。
三、Flink 中的状态和时间
如果想要深入地了解DataStream API,状态和时间是必须掌握的要点。
所有的计算都可以简单地分为无状态计算和有状态计算。无状态计算相对而言比较容易。假设这里有个加法算子,每进来一组数据,都把它们全部加起来,然后把结果输出去,有点纯函数的味道。纯函数指的是每一次计算结果只和输入数据有关,之前的计算或者外部状态对它不会产生任何影响。

这里我们主要讲一下Flink里边的有状态计算。用捡树枝的小游戏来举例。这个游戏在我看来做的非常好的一点是它自己记录了非常多的状态,比如几天没上线,然后再去和里边的 NPC对话的时候,它就会告诉你已经有好久没有上线了。换句话说,它会把之前上线的时间作为一种状态给记录下来,在生成它NPC对话的时候,是会受到这个状态的影响。
实现这种有状态的计算,要做的一点就是把之前的状态记录下来,然后再这个状态注入到新的一次计算中,具体实现方式也有下面两种:
- 第一种,把状态数据进入算子之前就给提取出来,然后把这个状态数据和输入数据合并在一起,再把它们同时输入到算子中,得到一个输出。这种方式是被用在 Spark的StructureStreaming里边。其好处是是可以重用已有的无状态算子。
- 第二种,是 Flink 现在的方法,就是算子本身是有状态的,算子在每一次到新数据之后做计算的时候,同时考虑新输数据和已有的状态对计算过程的影响,最终把结果输出出去。
计算引擎也应该像上面提到的游戏一样变得越来越智能,可以自动学习数据中潜在的规律,然后来自适应地优化计算逻辑,保持较高的处理性能。
Flink 的状态原语
Flink的状态原语涉及如何通过代码使用 Flink的状态。其基本思想是在编程的时候抛弃原生语言(例如Java或Scala)提供的数据容器,把它们更换为 Flink 里面的状态原语。
作为对状态支持比较好的系统, Flink 内部提供了可以使用的很多种可选的状态原语。从大的角度看,所有状态原语可以分为Keyed State和Operator State两类。Operator State应用相对比较少,我们在这里不展开介绍。下面重点看一下Keyed State。
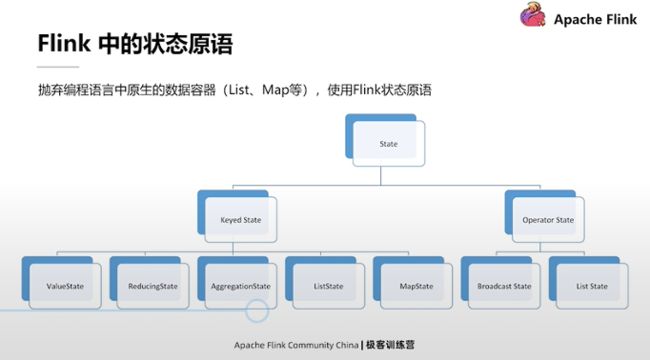
Keyed State,即分区状态。分区状态的好处是可以把已有状态按逻辑提供的分区分成不同的块。块内的计算和状态都是绑定在一起的,而不同的Key值之间的计算和状态的读写都是隔离的。对于每个Key值,只需要管理好自己的计算逻辑和状态就可以了,不需要去考虑其它Key值所对应的逻辑和状态。
Keyed State可以进一步划分为下面的5类,它们分别是:
- 比较常用的:ValueState、ListState、MapState
- 不太常用的:ReducingState和AggregationState
Keyed State只能在RichFuction中使用,RichFuction与普通、传统的Function相比,最大的不同就是它有自己的生命周期。Key State的使用方法分为以下四个步骤:
- 第一步,将 State声明为RichFunction里的实例的变量
- 第二步,在RichFunction对应的 open方法中,为 State进行一个初始化的赋值操作。赋值操作要有两步:先创建一个StateDescriptor,在创建中需要给State指定一个名称;然后再去调用RichFuntion中的getRuntimeContext().getState(…),把刚刚定义的StateDescriptor传进去,就可以获取State。
提醒:如果此流式应用是第一次运行,那么获得的State会是空内容的;如果State是从某个中间段重启的,它会根据配置和之前保存的数据的基础上进行恢复。

- 第三步,得到State对象后,就可以在RichFunction里,对对应的State进行读写。如果是ValueState,可以调用它的Value方法来获取对应值。Flink 框架会控制好所有状态的并发访问,并进行限制,所以用户不需要考虑并发的问题。
Flink 的时间
时间也是 Flink非常重要的一点,它和State是相辅相成的。总体来看 Flink引擎里边提供的时间有两类:第一类是Processing Time;第二类是Event Time。Processing Time表示的是真实世界的时间,Event Time是数据当中包含的时间。数据在生成的过程当中会携带时间戳之类的字段,因为很多时候需要将数据里携带的时间戳作为参考,然后对数据进行分时间的处理。
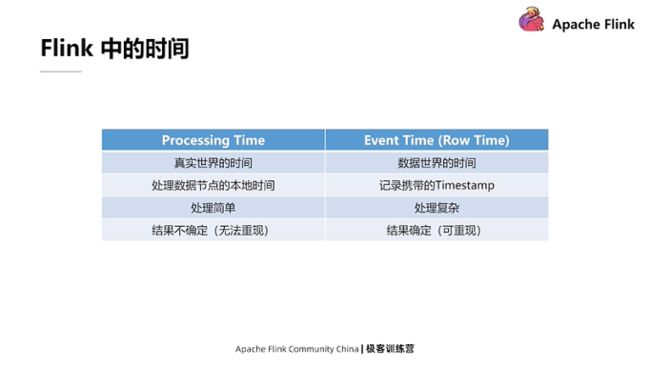
Processing Time处理起来相对简单,因为它不需要考虑乱序等问题;而Event Time处理起来相对复杂。而由于Processing Time在使用时是直接调取系统的时间,考虑到多线程或分布式系统的不确定性,所以它每次运行的结果可能是不确定的;相反,因为Event Time时间戳是被写入每一条数据里的,所以在重放某个数据进行多次处理的时候,携带的这些时间戳不会改变,如果处理逻辑没有改变的话,最后的结果也是比较确定的。
Processing Time和Event Time的区别。

以上图的数据为例,按照1~7的时间来排列的。对于机器时间而言,每个机器的时间会单调增加。在这种情况下,用Processing Time获得的时间是完美的按照时间从小到大排序的数据。对于Event Time而言,由于延迟或分布式的一些原因,数据到来的顺序可能和它们真实产生的顺序有一定的出入,数据可能存在着一定程度的乱序。这时就要充分利用数据里边携带的时间戳,对数据进行一个粗粒度的划分。例如可以把数据分为三组,第一组里最小的时间是1,第二组最小的时间是4,第三组最小的时间是7。这样划分之后,数据在组和组之间就是按从小到大的顺序排列好的。
怎样充分的把一定程度的乱序化解掉,让整个的系统看上去数据进来基本上是有顺序的?一种解决方案是在数据中间插入被称为Watermark的meta数据。在上图的例子中,前三个数据到来之后,假设再没有小于等于3的数据进来了,这时就可以插入一条Watermark 3到整个数据里,系统在看到Watermark 3时就知道,以后都不会有小于或等于3的数据过来了,这时它就可以放心大胆地进行自己的一些处理逻辑。
总结一下,Processing Time在使用时,是一个严格递增的;而Event Time会存在一定的乱序,需要通过Watermark这种办法对乱序进行一定缓解。
从API的角度来看,怎样去分配Timestamp或生成Watermark也比较容易,有两种方式:
第一种,在SourceFunction当中调用内部提供的 collectWithTimestamp方法,把包含时间戳的数据提取出来;还可以在SourceFunction中使用 emitWatermark方法去产生一个Watermark,然后插入到数据流中。

第二种,如果不在SourceFunction中可以调用DateStream.assignTimestampsAndWatermarks这个方法,同时传入两类Watermark生成器:
第一类是定期生成,相当在环境里通过配置一个值,比如每隔多长时间(指真实时间)系统会自动调用Watermar生成策略。
第二类是根据特殊记录生成,如果遇到一些特殊数据,可以采取AssignWithPunctuatedWatermarks这个方法来进行时间戳和Watermark的分配。
提醒:Flink 里内置了一些常用的Assigner,即WatermarkAssigner。比如针对一个固定数据,它会把这个数据对应的时间戳减去固定的时间作为一个Watermark。关于Timestamp分配和Watermark生成接口,在后续的版本可能会有一定的改动。 注意,新版本的Flink里面已经统一了上述两类生成器。
时间相关API
Flink 在编写逻辑时会用到的与时间相关的 API,下图总结了Event Time和Processing Time相对应的API。
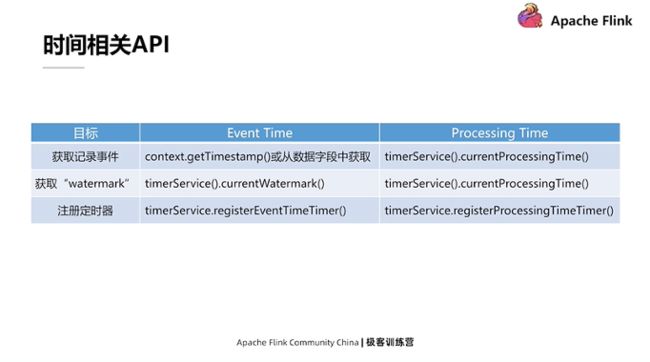
在应用逻辑里通过接口支持可以完成三件事:
- 第一,获取记录的时间。Event Time可以调context.getTimestamp,或在SQL算子内从数据字段中把对应的时间给提取出来。Processing Time可以直接调currentProcessingTime完成调取,它的内部是直接调用了获取系统时间的静态方法来返回的值。
- 第二,获取Watermark。其实只有在Event Time里才有Watermark的概念,而Processing Time里是没有的。但在Processing Time中非要把某个东西当成Watermark,其实就是数据时间本身。也就是说第一次调用timerService.currentProcessingTime方法之后获取的值。这个值既是当前记录的这个时间,也是当前的Watermark值,因为时间总是往前流动的,第一次调用了这个值后,第二次调用时这个值肯定不会再比第一次值还小。
- 第三,注册定时器。定时器的作用是清理。比如需要对一个cache在未来某个时间进行清理工作。既然清理工作应该发生在未来的某个时间点,那么可以调用 timerServicerEventTimeTimer或ProcessingTimeTimer方法注册定时器,再在整个方法里添加一个对定时器回调的处理逻辑。当对应的Event Time或者Processing Time的时间超过了定时器设置时间,它就会调用方法自己编写定时器的毁掉逻辑。
以上就是关于StreamProcess with Apache Flink的介绍,下一篇内容将着重介绍Flink Runtime Architecture。
活动推荐:
仅需99元即可体验阿里云基于 Apache Flink 构建的企业级产品-实时计算 Flink 版!点击下方链接了解活动详情:https://www.aliyun.com/product/bigdata/sc?utm_content=g_1000250506