Python实现拍照并识别文字
Python实现拍照并识别文字
一、代码
本文通过电脑自带摄像头或IP摄像头进行拍照保存,然后调用百度OCR文字识别,最后输出文字内容。
话不多说,上代码!
# -*- coding = utf-8 -*-
# @Time : 2021/3/19 9:55
# @Author : 陈良兴
# @File : 文字识别.py
# @Software : PyCharm
import cv2
import requests
import base64
# 获取图像
def get_file_content(file):
with open(file, 'rb') as f:
return f.read()
# 获取access_token
def gettoken():
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=8BfOPz0hI1iROQqZCadVxEYj&client_secret=D1fiXcrRsjcEqu1QnMRagTucUTlERvO2'
response = requests.get(host)
# if response:
# print(response.json())
return response.json()
# 把图片里的文字识别出来
def img_to_str(filename):
# 通用文字识别(标准版)
# request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic"
# 通用文字识别(高精度版)
# request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
# 网络图片识别
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/webimage"
# 二进制方式打开图片文件
f = get_file_content(filename)
img = base64.b64encode(f)
params = {"image": img}
access_token = gettoken()
request_url = request_url + "?access_token=" + access_token['access_token']
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
# if response:
# print(response.json())
result_list = response.json()
return result_list['words_result'][-1]['words']
def main():
# 创建窗口
cv2.namedWindow("camera", 1)
# IP摄像头
# capture = cv2.VideoCapture('http://admin:[email protected]:8081/video')
# 电脑本地摄像头
capture = cv2.VideoCapture(0)
while True:
success, img = capture.read()
cv2.imshow("camera", img)
# 按键
key = cv2.waitKey(10)
if key == 27: # 对应esc键
break
if key == 32: # 对应空格键
filename = 'frames.jpg'
cv2.imwrite(filename, img)
s = img_to_str(filename)
print(s)
# 释放摄像头
capture.release()
# 关闭窗口
cv2.destroyWindow("camera")
if __name__ == '__main__':
main()
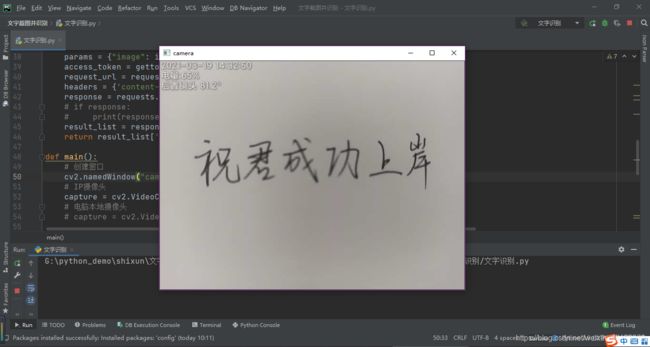
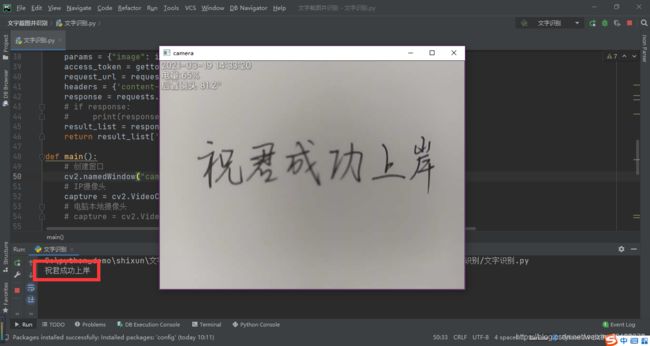
二、运行效果