PyTorch实战:实现Cifar10彩色图片分类
目录
前言
一、Cifar10数据集
class torch.utils.data.Dataset
torch.utils.data.DataLoader
二、定义神经网络
普通神经网络:
定义损失函数和优化器
训练网络-Net
CPU训练
模型准确率
编辑
GPU训练
训练网络-LeNet
模型准确率
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
前言
PyTorch可以说是三大主流框架中最适合初学者学习的了,相较于其他主流框架,PyTorch的简单易用性使其成为初学者们的首选。这样我想要强调的一点是,框架可以类比为编程语言,仅为我们实现项目效果的工具,也就是我们造车使用的轮子,我们重点需要的是理解如何使用Torch去实现功能而不要过度在意轮子是要怎么做出来的,那样会牵扯我们太多学习时间。以后就出一系列专门细解深度学习框架的文章,但是那是较后期我们对深度学习的理论知识和实践操作都比较熟悉才好开始学习,现阶段我们最需要的是学会如何使用这些工具。
深度学习的内容不是那么好掌握的,包含大量的数学理论知识以及大量的计算公式原理需要推理。且如果不进行实际操作很难够理解我们写的代码究极在神经网络计算框架中代表什么作用。不过我会尽可能将知识简化,转换为我们比较熟悉的内容,我将尽力让大家了解并熟悉神经网络框架,保证能够理解通畅以及推演顺利的条件之下,尽量不使用过多的数学公式和专业理论知识。以一篇文章快速了解并实现该算法,以效率最高的方式熟练这些知识。
博主专注数据建模四年,参与过大大小小数十来次数学建模,理解各类模型原理以及每种模型的建模流程和各类题目分析方法。此专栏的目的就是为了让零基础快速使用各类数学模型、机器学习和深度学习以及代码,每一篇文章都包含实战项目以及可运行代码。博主紧跟各类数模比赛,每场数模竞赛博主都会将最新的思路和代码写进此专栏以及详细思路和完全代码。希望有需求的小伙伴不要错过笔者精心打造的专栏:一文速学-数学建模常用模型
一、Cifar10数据集
CIFAR-10是一个广泛用于测试和验证图像分类算法的基准数据集之一,因其相对较小的规模和丰富的多样性而备受研究者关注。在深度学习领域,许多研究和论文都会以CIFAR-10作为测试数据集,以评估他们的模型性能。这些类别分别是:
- 飞机(airplane)
- 汽车(automobile)
- 鸟类(bird)
- 猫(cat)
- 鹿(deer)
- 狗(dog)
- 青蛙(frog)
- 马(horse)
- 船(ship)
- 卡车(truck)

数据集被分为训练集和测试集,其中训练集包含50,000张图片,测试集包含10,000张图片。每张图片都是![]() ,也即3-通道彩色图片,分辨率为
,也即3-通道彩色图片,分辨率为![]() 。此外,还有一个CIFAR-100的数据集,由于CIFAR-10和CIFAR-100除了分类类别数不一样外,其他差别不大,此处仅拿CIFAR-10这个相对小点的数据集来进行介绍,介绍用pytorch来进行图像分类的一般思路和方法。
。此外,还有一个CIFAR-100的数据集,由于CIFAR-10和CIFAR-100除了分类类别数不一样外,其他差别不大,此处仅拿CIFAR-10这个相对小点的数据集来进行介绍,介绍用pytorch来进行图像分类的一般思路和方法。
官方下载网址:CIFAR-10 and CIFAR-100 datasets
使用torch.utils.data加载数据:
import numpy as np
import torch
import torchvision.transforms as transforms
import os
from torch.utils.data import DataLoader
from torchvision.transforms import ToPILImage
show = ToPILImage() # 可以把Tensor转成Image,方便可视化
import torchvision.datasets as dsets
batch_size = 100
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# 定义对数据的预处理
transform = transforms.Compose([
transforms.ToTensor(), # 转为Tensor
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # 归一化 先将输入归一化到(0,1),再使用公式”(x-mean)/std”,将每个元素分布到(-1,1)
])
#Cifar110 dataset
train_dataset = dsets.CIFAR10(root='/ml/pycifar',
train = True,
download = True,
transform=transform
)
test_dataset = dsets.CIFAR10(root='/ml/pycifar',
train = False,
download = True,
transform=transform
)
#加载数据
train_loader=torch.utils.data.DataLoader(dataset=train_dataset,
batch_size = batch_size,
shuffle = True
)
test_loader = torch.utils.data.DataLoader(dataset = test_dataset,
batch_size=batch_size,
shuffle=True
)数据展示:
import matplotlib.pyplot as plt
fig = plt.figure()
classes=['plane','car','bird','cat','deer','dog','frog','horse','ship','truck']
for i in range(12):
plt.subplot(3, 4, i+1)
plt.tight_layout()
(_, label) = train_dataset[i]
plt.imshow(train_loader.dataset.data[i],cmap=plt.cm.binary)
plt.title("Labels: {}".format(classes[label]))
plt.xticks([])
plt.yticks([])
plt.show() 
数据集分为五个训练批次和一个测试批次,每个批次有10000张图像。测试批次包含从每个类别中随机选择的1000幅图像。训练批包含随机顺序的剩余图像,但一些训练批可能包含一个类中的图像多于另一个类的图像。在它们之间,训练批次包含每个类别的正好5000个图像。
数据集我们已经导入成功,需要说明的是我们之前已经对数据进行了预处理,并使数据归一化,补充一下两个需要了解的数据加载基类Dataset和DataLoader:
class torch.utils.data.Dataset
PyTorch的Dataset是一个抽象类,用于表示数据集。它允许你自定义数据集的加载方式,以便于在训练和测试过程中使用。
-
数据加载与预处理:
Dataset允许你自定义数据的加载方式,可以从文件、数据库、网络等来源加载数据。你可以在__getitem__方法中实现数据的预处理、转换等操作,以满足模型的输入要求。 -
支持索引: 通过实现
__getitem__方法,Dataset可以通过索引(如dataset[i])获取数据样本。这允许你按需读取数据,适用于大规模数据集,避免一次性加载所有数据。 -
返回样本总数:
len(dataset)返回数据集中样本的总数,便于在训练过程中设置合适的迭代次数。 -
可迭代:
Dataset可以像Python列表一样进行迭代,这意味着你可以在数据集上使用for循环。 -
与DataLoader结合使用:
Dataset通常与PyTorch的DataLoader一起使用,DataLoader可以将数据批量加载到模型中,实现了数据的批处理。 -
实现自定义数据集: 你可以继承
Dataset类,根据自己的需求创建自定义的数据集。
可以重构为:
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
sample = self.data[idx]
# 这里可以进行数据预处理或转换
return sample
# 使用示例
data = [1, 2, 3, 4, 5]
custom_dataset = CustomDataset(data)
print(len(custom_dataset)) # 输出: 5
print(custom_dataset[2]) # 输出: 3
torch.utils.data.DataLoader
torch.utils.data.DataLoader比较复杂一点,torch提供了很多参数可以用,常用的参数需要掌握:
-
dataset (Dataset): 要加载的数据集。通常是一个继承自
torch.utils.data.Dataset的自定义数据集对象。 -
batch_size (int, optional): 每个批次的样本数量。默认值为 1。
-
shuffle (bool, optional): 是否在每个 epoch 开始时随机打乱数据。默认值为 False。
-
sampler (Sampler, optional): 定义从数据集中采样样本的策略。如果指定了此参数,
shuffle参数将被忽略。 -
batch_sampler (Sampler, optional): 与
sampler相似,但返回的是一个 batch 的索引列表。 -
num_workers (int, optional): 用于数据加载的子进程数量。默认值为 0,表示所有数据将在主进程中加载。设置为大于 0 的值将启动相应数量的子进程来加载数据,可以加速数据加载。
-
collate_fn (callable, optional): 用于将一个个样本打包成一个 batch 的函数。通常在输入数据具有不同大小时使用。
-
pin_memory (bool, optional): 如果为 True,则数据加载器会将数据存储在 CUDA 固定内存中,可以加速数据传输到 GPU。默认值为 False。
-
drop_last (bool, optional): 如果为 True,则在最后一个 batch 的大小小于
batch_size时,该 batch 将被丢弃。默认值为 False。 -
timeout (numeric, optional): 在等待新数据时的超时时间(以秒为单位)。如果设置为 None,则会一直等待,直到数据准备好。默认值为 0。
-
worker_init_fn (callable, optional): 每个 worker 在开始加载数据之前会调用此函数。可以用于在 worker 中初始化一些特定的设置。
这些参数可以根据实际情况来调整,以满足数据集和模型训练的需求。例如,可以根据数据集大小、模型结构等来设置 batch_size、num_workers 等参数,以获得最佳的训练性能。
二、定义神经网络
我们可以用两种网络来对比其分类能力,一种是普通Net网络,另外用LeNet卷积网络来对比:
普通神经网络:
import torch.nn as nn
import torch
input_size = 3072 #3*32*32
hidden_size1 = 500 #第一次隐藏层个数
hidden_size2 = 200 #第二次隐藏层个数
num_classes = 10 #分类个数
num_epochs = 5 #批次次数
batch_size = 100 #批次大小
learning_rate =1e-3
#定义两层神经网络
class Net(nn.Module):
def __init__(self,input_size,hidden_size1,hidden_size2,num_classes):
super(Net,self).__init__()
self.layer1 = nn.Linear(input_size,hidden_size1)#输入
self.layer2 = nn.Linear(hidden_size1,hidden_size2)#两层隐藏层计算
self.layer3 = nn.Linear(hidden_size2,num_classes)#输出
def forward(self,x):
out = torch.relu(self.layer1(x)) #隐藏层1
out = torch.relu(self.layer2(out)) #隐藏层2
out = self.layer3(out)
return out
net =Net(input_size,hidden_size1,hidden_size2,num_classes)
Net( (layer1): Linear(in_features=3072, out_features=500, bias=True) (layer2): Linear(in_features=500, out_features=200, bias=True) (layer3): Linear(in_features=200, out_features=10, bias=True) )
定义损失函数和优化器
from torch import optim
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.SGD(net.parameters(), lr=learning_rate)训练网络-Net
神经网络的训练流程基本都是类似的:
- 输入数据
- 前向传播+反向传播
- 更新参数
CPU训练
Pytorch是默认在 CPU 上运行:
batch_size = 1000 #批次大小
for epoch in range(num_epochs):
print('current epoch + %d' % epoch)
running_loss = 0.0
for i ,(images,labels) in enumerate(train_loader,0):
images=images.view(images.size(0),-1)
labels = torch.tensor(labels, dtype=torch.long)
# 梯度清零
optimizer.zero_grad()
outputs = net(images) #将数据集传入网络做前向计算
loss = criterion(outputs ,labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 1000 == 0: # 每1000个batch打印一下训练状态
print('[%d, %5d] loss: %.3f' \
% (epoch+1, i+1, running_loss))
running_loss = 0.0
print('Finished Training')
current epoch + 0 [1, 0] loss: 2.149 current epoch + 1 [2, 0] loss: 2.025 current epoch + 2 [3, 0] loss: 1.987 current epoch + 3 [4, 0] loss: 2.020 current epoch + 4 [5, 0] loss: 1.970 Finished Training
模型准确率
#prediction
total = 0
correct =0
acc_list_test = []
for images,labels in test_loader:
images=images.view(images.size(0),-1)
outputs = net(images) #将数据集传入网络做前向计算
_,predicts = torch.max(outputs.data,1)
total += labels.size(0)
correct += (predicts == labels).sum()
acc_list_test.append(100 * correct / total)
print('Accuracy = %.2f'%(100 * correct / total))
plt.plot(acc_list_test)
plt.xlabel('Epoch')
plt.ylabel('Accuracy On TestSet')
plt.show()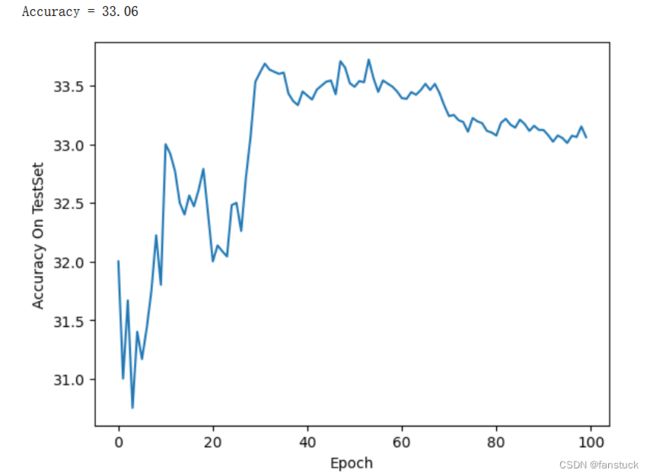
准确率只有33.06%,实际上一张图片直接给我们人来猜的话有10%概率猜对,所以这样看来神经网络还是可以有所提升的,那我们再试试卷积网络看看。
GPU训练
使用GPU训练只需要将torch的驱动device切换为GPU,且将显式地将张量(Tensors)和模型(Models)移动到 GPU 上就可:
batch_size = 1000 #批次大小
net_gpu =Net(input_size,hidden_size1,hidden_size2,num_classes)
net_gpu.cuda()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
for epoch in range(num_epochs):
print('current epoch + %d' % epoch)
running_loss = 0.0
for i ,(images,labels) in enumerate(train_loader,0):
images = images.to(device)
labels = labels.to(device)
images=images.view(images.size(0),-1)
labels = torch.tensor(labels, dtype=torch.long)
# 梯度清零
optimizer.zero_grad()
outputs = net_gpu(images) #将数据集传入网络做前向计算
loss = criterion(outputs ,labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 1000 == 0: # 每2000个batch打印一下训练状态
print('[%d, %5d] loss: %.3f' \
% (epoch+1, i, running_loss ))
running_loss = 0.0
print('Finished Training')效果是一样的,这里不再继续复写。
训练网络-LeNet
我们再来训练一个卷积网络再来看看效果,可能这里讲述卷积网络有点跳跃,之后我会详细讲述卷积神经网络的全部内容,这里大家只需要知道每个网络的性能是不同的。
import torch.nn as nn
import torch.nn.functional as F
input_size = 3072 #3*32*32
hidden_size1 = 500 #第一次隐藏层个数
hidden_size2 = 200 #第二次隐藏层个数
num_classes = 10 #分类个数
num_epochs = 5 #批次次数
batch_size = 100 #批次大小
learning_rate =1e-3
class LeNet(nn.Module):
def __init__(self,input_size,hidden_size1,hidden_size2,num_classes):
super(LeNet, self).__init__()
# 卷积层 '1'表示输入图片为单通道, '6'表示输出通道数,'5'表示卷积核为5*5
self.conv1=nn.Conv2d(3,6,5)
# 卷积层
self.conv2 = nn.Conv2d(6, 16, 5)
# 仿射层/全连接层,y = Wx + b
self.fc1 = nn.Linear(input_size, hidden_size1)
self.fc2 = nn.Linear(hidden_size1, hidden_size2)
self.fc3 = nn.Linear(hidden_size2, num_classes)
def forward(self,x):
# 卷积 -> 激活 -> 池化
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
# reshape,‘-1’表示自适应
x = x.view(x.size()[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net =LeNet(input_size,hidden_size1,hidden_size2,num_classes)
LeNet( (conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1)) (conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1)) (fc1): Linear(in_features=3072, out_features=500, bias=True) (fc2): Linear(in_features=500, out_features=200, bias=True) (fc3): Linear(in_features=200, out_features=10, bias=True) )
以上为整个卷积网络的结构,接下来直接训练看看效果:
batch_size = 1000 #批次大小
for epoch in range(num_epochs):
print('current epoch + %d' % epoch)
running_loss = 0.0
for i ,(images,labels) in enumerate(train_loader,0):
#images=images.view(images.size(0),-1) 单通道不需要
labels = torch.tensor(labels, dtype=torch.long)
# 梯度清零
optimizer.zero_grad()
outputs = net(images) #将数据集传入网络做前向计算
loss = criterion(outputs ,labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 1000 == 0: # 每1000个batch打印一下训练状态
print('[%d, %5d] loss: %.3f' \
% (epoch+1, i, running_loss ))
running_loss = 0.0
print('Finished Training')
[1, 0] loss: 2.310 current epoch + 1 [2, 0] loss: 2.301 current epoch + 2 [3, 0] loss: 2.305 current epoch + 3 [4, 0] loss: 2.303 current epoch + 4 [5, 0] loss: 2.304 Finished Training
模型准确率
#prediction
total = 0
correct =0
acc_list_test = []
for images,labels in test_loader:
#images=images.view(images.size(0),-1)
outputs = net(images) #将数据集传入网络做前向计算
_,predicts = torch.max(outputs,1)
total += labels.size(0)
correct += (predicts == labels).sum()
acc_list_test.append(100 * correct / total)
print('Accuracy = %.2f'%(100 * correct / total))
plt.plot(acc_list_test)
plt.xlabel('Epoch')
plt.ylabel('Accuracy On TestSet')
plt.show() 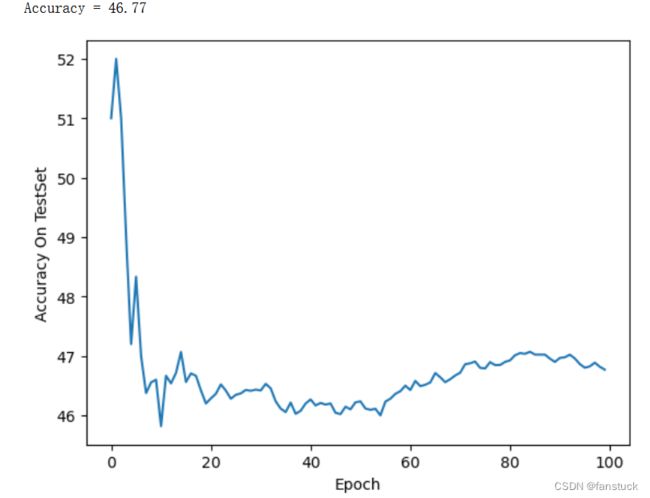
比普通的神经网络要好很多。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。