大数据从入门到精通(超详细版)之HiveServer2的使用
前言
嗨,各位小伙伴,恭喜大家学习到这里,不知道关于大数据前面的知识遗忘程度怎么样了,又或者是对大数据后面的知识是否感兴趣,本文是《大数据从入门到精通(超详细版)》的一部分,小伙伴们如果对此感谢兴趣的话,推荐大家按照大数据学习路径开始学习哦。
以下就是完整的学习路径哦。
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
大数据从入门到精通文章体系!!!!!!!!!!!!!!
↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑
推荐大家认真学习哦!!!
本篇文章就详细学习一下Hive的实际操作.
文章目录
- 前言
- Hive Shell操作
-
- 操作步骤
- 数据存储位置
- 元数据存储着哪些内容呢
- Hive客户端操作
-
- 介绍与启动
- Beeline连接
- DataGrip连接

Hive Shell操作
操作步骤
在Hive的安装目录当中执行:
bin/hive
进入到hive shell界面, 在界面当中书写sql语句
创建表:
create table student(id int,name string,gender string);
此时没有指定数据库, 会默认创建表到当前数据库
插入数据:
insert into student values(1,'小明','男');
insert into student values(2,'李四','男');

此时就是自动将sql自动转为一个个map reduce任务, 在yarn中也能看到

数据存储位置
在hdfs文件当中的user/hive/warehouse目录下存放着, 这是默认的存储路径
#查看此文件夹下的路径
hdfs dfs -ls /user/hive/warehouse
#查看此文件下的所有内容
hdfs dfs -cat /user/hive/warehouse/student/*


元数据存储着哪些内容呢
库名,表明, 字段民等等数据,存储在mysql当中 , 以及这些元数据在hdfs中对应的存储节点有哪些
select * from TBLS;
select * from DBS;

Hive客户端操作
介绍与启动
在启动Hive的时候,除了必备的MetaStore服务外 , 我们前面还有提到过2种方式使用HIve :
-
bin/hive, 就是Hive Shell的客户端 , 直接写SQL -
bin/hive --service hiveserver2此时后台执行脚本 :
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &bin/hive --service metastore, 启动的是元数据管理服务bin/hive --service hiveserver2, 启动的是hiveserver2服务所以 , HiveServer2其实就是Hive内置的一个ThriftServer服务 , 提供Thrift端口供其他客户端连接
这时可以连接ThrifServer的客户端有 :
- Hive内置的beeline客户端工具(命令行形式)
- 第三方的图形化工具 , 如DataGrip这些
下面就是它们之间的关系.

话不多说, 我们开始实际操作
在安装hive的服务器上, 首先启动metastore服务 , 然后启动hiveserver2服务
#启动metastore服务
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
#启动hiveserver2服务
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &

可以看到成功启动
#查看hiveserver2 的日志
tail -f logs/hiveserver2.log

没有出现报错信息, 即启动成功
Beeline连接
在hive的服务器上可以直接使用beeline客户端进行连接 , Beeline是JDBC的客户端 , 通过JDBC和HiveServer2进行通信, 协议的地址是 :
jdbc:hive2://node:10000
这个10000端口是hiveserver2默认向外开发的端口
#进入beeline的连接界面
bin/beeline
#开始连接
!connect jdbc:hive2://node:10000
#接下来会开始输入hive的启动用户名密码,然后就可以开始连接了

show databases; #输入sql语句展示库数据
##可以看出与原生的hive连接差别还是很大的
这是beeline客户端界面

这时hive的原生界面

DataGrip连接
这种第三方的客户端页面美观大方 , 操作简洁 , 更重要的是sql编辑环境优雅 , sql语法智能提示补全 , 关键字高亮 , 查询结果智能显示 , 按钮操作大于命令操作
接下来是具体的连接步骤
-
打开DataGrip

-
选择Apach Hive进行连接
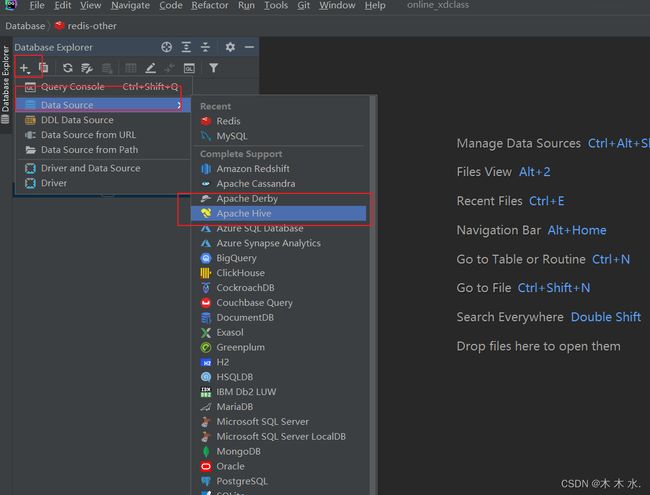
-
填写相关信息

-
此时已经连接上了

-
接下来的操作就跟平常操作mysql一样了
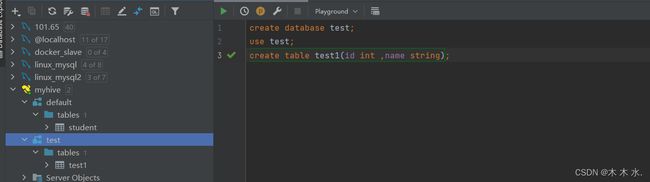
本就就结束了如何使用Hive里面的连接工具 : hiveserver2的使用 , 接下来就介绍如何使用hive的具体操作.