015 大数据之Flume
1、Apache Flume初识
【Flume】Flume 简单理解及使用实例
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Flume-og采用了多Master的方式。为了保证配置数据的一致性,Flume引入了ZooKeeper,用于保存配置数据,ZooKeeper本身可保证配置数据的一致性和高可用,另外,在配置数据发生变化时,ZooKeeper可以通知Flume Master节点。Flume Master间使用gossip协议同步数据。
Flume-ng最明显的改动就是取消了集中管理配置的 Master 和 Zookeeper,变为一个纯粹的传输工具。Flume-ng另一个主要的不同点是读入数据和写出数据由不同的工作线程处理(称为 Runner)。 在 Flume-og 中,读入线程同样做写出工作(除了故障重试)。如果写出慢的话(不是完全失败),它将阻塞 Flume 接收数据的能力。这种异步的设计使读入线程可以顺畅的工作而无需关注下游的任何问题。
2、Flume安装部署
Flume启动报错,guava.java包冲突
CentOS7 yum提示:another app is currently holding the yum lock;waiting for it to exit
# 将lib文件夹下的guava-11.0.2.jar删除以兼容Hadoop 3.1.3
[atguigu@hadoop102 lib]$ rm guava-11.0.2.jar
# 可以通过强制关掉yum进程
[atguigu@hadoop102 ~]$ rm -f /var/run/yum.pid
# 杀掉占用44444端口的进程
[atguigu@hadoop102 ~]$ netstat -tlunp | grep 44444
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp6 0 0 127.0.0.1:44444 :::* LISTEN 6303/java
[atguigu@hadoop102 ~]$ kill -9 6303
[atguigu@hadoop102 apache-flume-1.9.0-bin]$ sudo netstat -nlp | grep 44444
[atguigu@hadoop102 apache-flume-1.9.0-bin]$ cat job/flume-netcat-logger.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
[atguigu@hadoop102 apache-flume-1.9.0-bin]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console
# 在一个hadoop102的一个终端在44444端口产生数据
[atguigu@hadoop102 ~]$ nc localhost 44444
# 在另一个hadoop102的一个终端监听44444端口
[atguigu@hadoop102 ~]$ bin/flume-ng agent -c conf/ -n a1 -f job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console
PS:-Dflume.root.logger=INFO,console(-D表示flume运行时动态修改flume.root.logger参数属性值,并将控制台日志打印级别设置为INFO级别。日志级别包括:log、info、warn、error)
3、Flume 1.9.0 User Guide
flume之HDFS Sink详解(转载)
3.1、单个变化文件的数据读取
[atguigu@hadoop102 job]$ cat flume-file-hdfs.conf
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /opt/module/apache-hive-3.1.2-bin/logs/hive.log
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop102:9820/flume/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k2.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 60
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k2.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
[atguigu@hadoop102 job]$ cd ..
[atguigu@hadoop102 apache-flume-1.9.0-bin]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/flume-file-hdfs.conf -Dflume.root.logger=INFO,console
[atguigu@hadoop102 logs]$ hive
which: no hbase in (/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/module/jdk1.8.0_212/bin:/opt/module/hadoop-3.1.3/bin:/opt/module/hadoop-3.1.3/sbin:/opt/module/apache-zookeeper-3.5.7-bin/bin:/opt/module/apache-zookeeper-3.5.7-bin/sbin:/opt/module/jdk1.8.0_212/bin:/opt/module/hadoop-3.1.3/bin:/opt/module/hadoop-3.1.3/sbin:/opt/module/apache-hive-3.1.2-bin/bin:/home/atguigu/.local/bin:/home/atguigu/bin)
Hive Session ID = 6956125e-de20-496d-be95-12da80653c98
Logging initialized using configuration in file:/opt/module/apache-hive-3.1.2-bin/conf/hive-log4j2.properties Async: true
Hive Session ID = 35458a63-4e24-40ba-93cd-9f38f8be02ac
hive (default)>

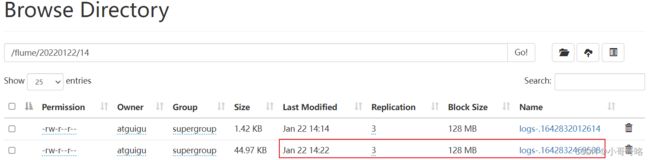
3.2、同一文件夹下多不变文件的读取
[atguigu@hadoop102 job]$ cat flume-dir-hdfs.conf
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
# 文件夹下的文件内容、文件名不能改变,否则报错
a3.sources.r3.type = spooldir
# 指定文件夹路径
a3.sources.r3.spoolDir = /opt/module/apache-flume-1.9.0-bin/upload
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
#忽略所有以.tmp结尾的文件,不上传
a3.sources.r3.ignorePattern = ([^ ]*\.tmp)
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://hadoop102:9820/flume/upload/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a3.sinks.k3.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
# 监控 /opt/module/apache-flume-1.9.0-bin/upload 下新增的文件
[atguigu@hadoop102 apache-flume-1.9.0-bin]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/flume-dir-hdfs.conf -Dflume.root.logger=INFO,console
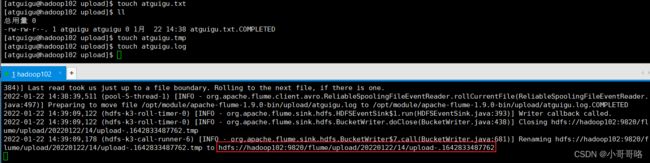
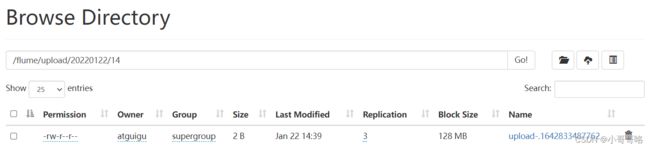
3.3、同一文件夹下多个变文件的读取
positionFile 参数:File in JSON format to record the inode, the absolute path and the last position of each tailing file.
Taildir Source维护了一个json格式的position File,其会定期的往position File中更新每个文件读取到的最新的位置,因此能够实现断点续传。
Linux中储存文件元数据的区域就叫做inode,每个inode都有一个号码,操作系统用inode号码来识别不同的文件,Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。
[atguigu@hadoop102 job]$ cat flume-taildir-hdfs.conf
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
a3.sources.r3.type = TAILDIR
# 记录读取文件的元信息
a3.sources.r3.positionFile = /opt/module/apache-flume-1.9.0-bin/taildir/tail_dir.json
# 设置需要读取的信息
a3.sources.r3.filegroups = f1 f2
a3.sources.r3.filegroups.f1 = /opt/module/apache-flume-1.9.0-bin/taildir/files1/.*file.*
a3.sources.r3.filegroups.f2 = /opt/module/apache-flume-1.9.0-bin/taildir/files2/.*log.*
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://hadoop102:9820/flume/upload2/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a3.sinks.k3.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
4、Flume进阶
4.1、Flume事务
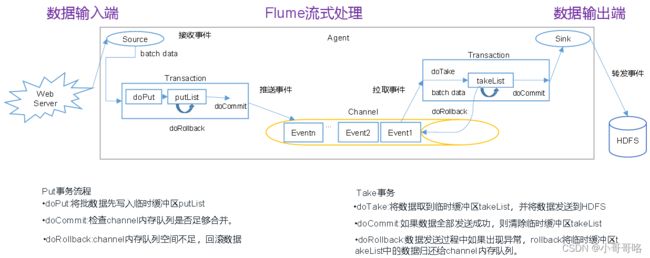
Flume使用两个独立的事务分别负责从soucrce到channel,以及从channel到sink的事件传递。在Source到Channel之间的叫put事务,在Channel到Sink之间的叫take事务。事务两个特性就是:成功了提交,失败了回滚。
- put事务:doCommit()失败时,调用doRollback方法进行事务的回滚操作:1)清空putList中的数据,2)抛出channelException异常;当source捕捉到doRollback抛出的异常,就会把刚才的一批数据重新采集一下,采集完之后重新走事务的流程。
- take事务:doCommit()失败时,调用doRollback方法进行事务的回滚操作:1)takeList中备份数据不删除,2)将takeList中的数据原封不动地还给channel;
PS:两类事务分别可能发生数据重复提交、数据重复获取;当source有回滚功能时,flume逻辑上不会丢失数据。
二进制指数退避算法
4.2、Flume Agent内部原理
Flume可以采集文件,socket数据包(网络端口)、文件夹、kafka、mysql数据库等各种形式源数据,又可以将采集到的数据(下沉sink)输出到HDFS、hbase、hive、kafka等众多外部存储系统中。Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS。
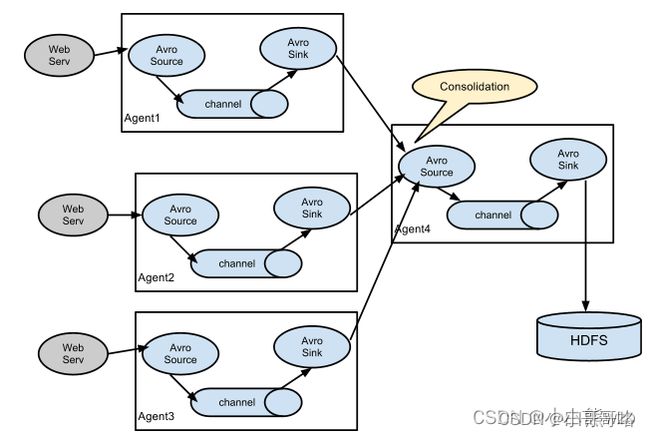
Flume中最核心的角色是agent,flume采集系统就是由一个个agent连接起来所形成的一个或简单或复杂的数据传输通道。对于每一个Agent来说,它就是一个独立的守护进程(JVM),它负责从数据源接收数据,并发往下一个目的地,如下图所示:
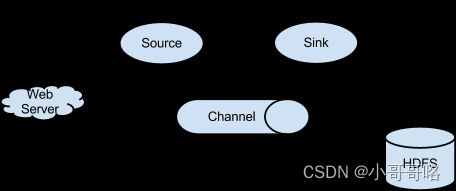
单个agent采集数据
多级agent之间串联
Agent 主要有 3 个部分组成,Source、Channel、Sink:
① source 数据源:从外界采集各种类型数据,将数据传递给channel。
② channel 临时存储数据的管道:接受Source发出的数据,临时存储,Channel 是位于 Source 和 Sink 之间的缓冲区。因此,Channel 允许 Source 和 Sink 运作在不同的速率上。Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个Sink 的读取操作。
③ sink 采集数据的传送目的:从channel中读取数据并存储到指定目的地。
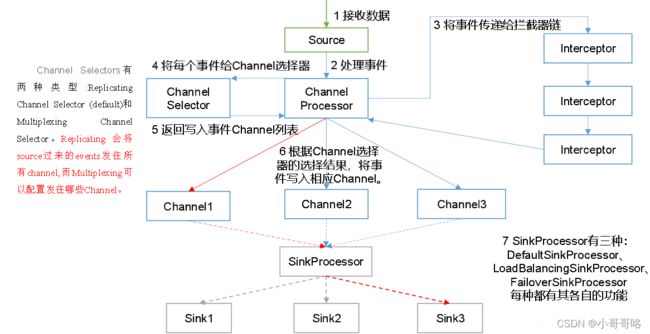
- DefaultSinkProcessor对应的是单个的Sink;
- LoadBalancingSinkProcessor和FailoverSinkProcessor对应的是Sink Group;
- LoadBalancingSinkProcessor可以实现负载均衡的功能;
- FailoverSinkProcessor可以错误恢复的功能;
Flume 详解&实战
Flume数据采集工具之agent
4.3、Flume的Source、Channel和Sink
AvroSink和AvroSource配合使用,是实现多级流动、扇出流(1到多) 、扇入流(多到1) 的基础。AvroSource接收到的是经过avro序列化后的数据,然后反序列化数据继续传输。所以,如果是AvroSource的话,源数据必须是经过avro序列化后的数据(AvroSink),也可以接收通过Flume提供的avro客户端发送的日志信息。
- Flume之Source全面解析
- flume的Source(数据源)
- Flume的Sink
- Flume Sink
flume 的 FailoverSinkProcessor 虽然可以实现故障转移,当第一个接受数据的 flume 的本身的故障难以保证。将Kafka作为Channel存储,Kafka是分布式、可扩展、高容错、高吞吐的分布式系统,Kafka通过优秀的架构设计充分利用磁盘顺序特性,在廉价的硬件条件下完成高效的消息发布和订阅。
Memory Channel在使用的过程中受内存容量的限制不能缓存大量的消息,并且如果Memory Channel中的消息没来得及写入Sink,此时Agent出现故障就会造成数据丢失。File Channel虽然能够缓存更多的消息,但如果缓存下来的消息还没有写入Sink,此时Agent出现故障则File Channel中的消息不能被继续使用,直到该Agent重新恢复才能够继续使用File Channel中的消息。Kafka Channel相对于Memory Channel和File Channel存储容量更大、容错能力更强,弥补了其他两种Channel的短板,如果合理利用Kafka的性能,能够达到事半功倍的效果。
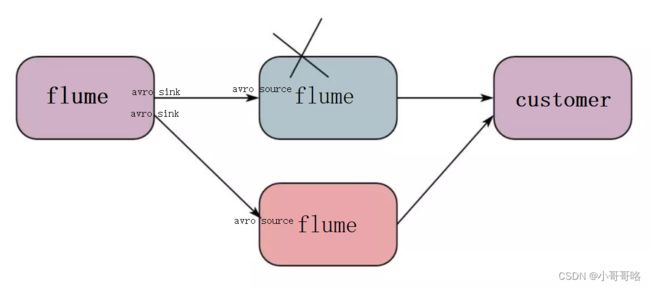
- Flume Channel Selectors
- Flume之 各种 Channel 的介绍及参数解析
如果flume已有的interceptor 、source、sink不符合需求,可以自定义
5、Flume面试
5.1、Flume的事务机制
Flume的事务机制(类似数据库的事务机制):Flume使用两个独立的事务分别负责从Soucrce到Channel,以及从Channel到Sink的事件传递。比如spooling directory source 为文件的每一行创建一个事件,一旦事务中所有的事件全部传递到Channel且提交成功,那么Soucrce就将该文件标记为完成。同理,事务以类似的方式处理从Channel到Sink的传递过程,如果因为某种原因使得事件无法记录,那么事务将会回滚。且所有的事件都会保持到Channel中,等待重新传递。
5.2、Flume采集数据会丢失吗?
根据Flume的架构原理,Flume是不可能丢失数据的,其内部有完善的事务机制,Source到Channel是事务性的,Channel到Sink是事务性的,因此这两个环节不会出现数据的丢失,唯一可能丢失数据的情况是Channel采用memoryChannel,agent宕机导致数据丢失,或者Channel存储数据已满,导致Source不再写入,未写入的数据丢失。Flume不会丢失数据,但是有可能造成数据的重复,例如数据已经成功由Sink发出,但是没有接收到响应,Sink会再次发送数据,此时可能会导致数据的重复。
6、Flume启停脚本配置
日志采集Flume启动停止脚本
#! /bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103
do
echo " --------启动 $i 采集flume-------"
ssh $i "nohup /opt/module/apache-flume-1.9.0-bin/bin/flume-ng agent --conf-file /opt/module/apache-flume-1.9.0-bin/conf/file-flume-kafka.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/apache-flume-1.9.0-bin/log1.txt 2>&1 &"
done
};;
"stop"){
for i in hadoop102 hadoop103
do
echo " --------停止 $i 采集flume-------"
ssh $i "ps -ef | grep file-flume-kafka | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9 "
done
};;
esac
说明:
1、nohup,该命令可以在你退出帐户/关闭终端之后继续运行相应的进程
2、xargs 表示取出前面命令运行的结果,作为后面命令的输入参数