自己动手写数据库:关系代数和查询树执行效率的推导
上几节我们完成了 sql 解释器的实现。通过解析 sql 语句,我们能知道 sql 语句想做什么,接下来就需要执行 sql 语句的意图,也就是从给定表中抽取所所需要的数据。要执行 sql 语句,我们需要了解所谓的“关系代数”,所谓代数本质上就是定义操作符和操作对象,在关系代数里,操作符有三种,分别为 select, project 和 product,操作对象就是数据库表。
select 对应的操作就是从给定的数据表中抽出满足条件的行,同时保持每行的字段没有变化。例如语句"select * from customer where id=1234",这条语句执行后,会将 customer 表中所有记录中 id 字段等于 1234 的行给抽取出来形成一个新的表。
project 对应的操作是,从给定数据表中选取若干个字段形成新表,新表的列发生变化,但是行的数量跟原表一样,例如语句"select name, age from customer",这条语句从原表中抽取出两个字段 name,age 形成新的表,新表的列数比原表少,但行数不标。
product,它对应笛卡尔积,它的操作对象是两个表,它从依次从左边表抽取出一行,跟右边表所有行组合,因此如果左边表的行数和列数是 Lr,Lc, 右边表的行数和列数是 Rr,Rc,那边操作结果的新表中,行数为 Lr * Rr, 列数为 Lc+Rc。
结合上面的关系代数,在解析给定 sql 语句后,要想执行相应操作,我们需要构造一种特定数据结构叫查询树,查询树的特点是,它的叶子节点对应数据库表,它 的父节点对应我们上面说的关系代数操作,我们看一个具体例子:“select name, age from customer where salary>2000"
这条语句对应两种关系代数操作也就是 select 和 project,它可以对应两种查询树,第一种为:
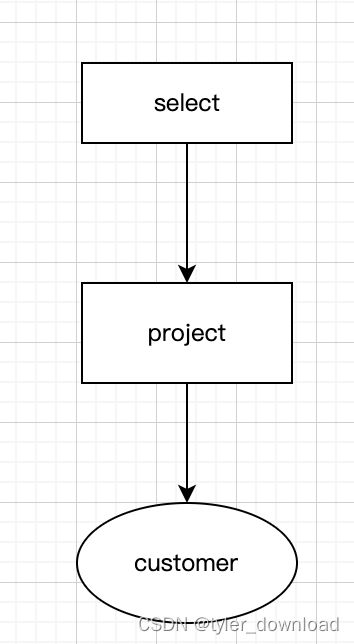
这个查询树的意思是,先对数据表 customer 做 project 操作,也就是先从表中把 name,age 这两列选出,并保证行数不变,然后在此结果上过滤每一行,将字段salary 大于 2000的行再选出来。不难想象我们还可以有另一种查询树,那就是先做 select 操作,也就是先把表中所有满足 salary>2000 的行全部选出来,然后在此基础上,再将 name,age 这两列抽出来,对应查询树如下:

大家可能感觉不同查询树本质上一样,事实上不同查询树对数据操作的效率影响很大,一种查询树对应的操作其效率可能比另一种好上十倍,乃至百倍,因此我们构造出所有可能的查询树后,还需要计算不同查询树的执行效率,然后选出最好的那种,这个步骤叫 planning。
在前面章节中,我们实现过 Scan 接口,这个接口可以套用到前面描述的几个操作符上,所以前面章节我们分别实现了 TableScan, SelectScan, ProjectScan, ProductScan,需要注意的是后面三个 Scan 对象在初始化时都要输入一个实现了 Scan 接口的对象,这就能对应到上面的查询树结构,最底部的叶子节点对应 TableScan,上一层的 SelectScan 在初始化时输入的 Scan 对象就是 TableScan,最上层节点对应 ProjectScan,它在初始化时输入的 Scan 对象就是 SelectScan。
下面我们把这几节内容结合起来用代码实现看看,先获得感性认知,后面我们再针对前面说过的 planning 做进一步分析。在前面的解析过程中,我们解析过 select 语句,它最后构造了一个 QueryData 对象,这个对象包含三部分,首先就是 fields,这部分可以用来实现 project 操作,第二部分是表名,它可以用来构造 TableScan 对象,最后的 pred 对象可以跟 TableScan 对象结合起来构造 SelectScan 对象。
在前面我们研究 record_manager 的时候实现过 TableScan,同时还提供了一个测试文件实现叫 table_scan_test.go,里面有个函数叫TestTableScanInsertAndDelete,它构造了一个数据表的数据存储,然后使用 TableScan 对象对这个表进行遍历操作,这里我们模仿当时的做法先构造一个 student 表,设置这个表只有 3 个字段,分别为 name,它为字符串类型,age,它为int 类型,最后是 id,它也是数字类型,然后我们给这个表添加几行数据,在 main.go 中增加代码如下:
func main() {
//构造 student 表
file_manager, _ := fm.NewFileManager("recordtest", 400)
log_manager, _ := lm.NewLogManager(file_manager, "logfile.log")
buffer_manager := bmg.NewBufferManager(file_manager, log_manager, 3)
tx := tx.NewTransation(file_manager, log_manager, buffer_manager)
sch := NewSchema()
//name 字段有 16 个字符长
sch.AddStringField("name", 16)
//age,id 字段为 int 类型
sch.AddIntField("age")
sch.AddIntField("id")
layout := NewLayoutWithSchema(sch)
//构造student 表
ts := query.NewTableScan(tx, "student", layout)
//插入 3 条数据
ts.BeforeFirst()
//第一条记录("jim", 16, 123)
ts.Insert()
ts.SetString("name", "jim")
ts.SetInt("age", 16)
ts.SetInt("id", 123)
//第二条记录 ("tom", 18, 567)
ts.Insert()
ts.SetString("name", "tom")
ts.SetInt("age", 18)
ts.SetInt("id", 567)
//第三条数据 hanmeimei, 19, 890
ts.Insert()
ts.SetString("name", "HanMeiMei")
ts.SetInt("age", 19)
ts.SetInt("id", 890)
//构造查询 student 表的 sql 语句,这条语句包含了 select, project 两种操作
sql := "select name, age from student where id=890"
sqlParser := parser.NewSQLParser(sql)
queryData := sqlParser.Query()
//根据 queryData 分别构造 TableScan, SelectScan, ProjectScan 并执行 sql 语句
//创建查询树最底部的数据表节点
tableScan := query.NewTableScan(tx, "student", layout)
//构造上面的 SelectScan 节点
selectScan := query.NewSelectionScan(tableScan, queryData.Pred())
//构造顶部 ProjectScan 节点
projectScan := query.NewProductionScan(selectScan, queryData.Fields())
//为遍历记录做初始化
projectScan.BeforeFirst()
for true {
//查找满足条件的记录
if projectScan.Next() == true {
fmt.Println("found record!")
for _, field := range queryData.Fields() {
fmt.Printf("field name: %s, its value is : %v:\n", projectScan.GetVal(field))
}
} else {
break
}
}
fmt.Println("complete sql execute")
tx.Close()
}
上面代码我们需要做一些分析,在 SelectScan, ProjectScan 初始化时,它需要传入 Scan 对象,如果按照第一个查询树,ProjectScan 就会作为参数传入 SelectScan 进行构造,如果按照第二个查询树,SelectScan 就会作为参数传入 ProjectScan 进行构造,但无论何种情况,TableScan 都对应查询树中的叶子节点,因此它会作为参数传给 SelectScan 或者 ProjectScan 进行构造,因此在代码中 ProjectScan.Next 就会调用到 SelectScan.Next,最后调用到 TableScan.Next,TableScan.Next 负责从最底层的文件存储中取出每一条记录返回给 SelectScan, 后者判断取出的记录是否能满足 Predicate 的约束,如果满足则返回 True,于是 ProjectScan.Next 就会得到 True,由此代码就找到了满足 where 条件的记录,然后 ProjectScan 把该记录中的给定字段拿出来,这就完成了 SQL 语句的执行,更详细的内容请在 b 站搜索“ coding 迪斯尼”查看调试演示视频,对应代码下载:
链接: https://pan.baidu.com/s/1hIACldEXaABVkbZiJAevIg 提取码: vb46
下面我们看看如何计算一个查询树的效率。在数据库系统的运行中,最消耗资源和时间的操作就是读取硬盘,相对与读取内存,读取硬盘的速度要慢两到三个数量级,也就是读取硬盘比读取内存要慢一百倍以上,由此我们判断查询树执行效率时,就要判断它返回给定数据或记录需要访问几次硬盘,访问的次数越少,那么它效率越高。
我们用 s 表示实现了 Scan 接口的对象,因此 s 可以表示 TableScan, SelectScan,ProjectScan, ProductScan 等对象的实例。使用 B(s)表示给定实例对象返回满足条件记录所需要访问的区块数,R(s)表示给定的实例对象返回所需记录前需要查询的记录数,V(s,F)表示Scan 实例对象 s 遍历数据库表后所返回的记录中,F 字段包含不同值的数量,V(s,F)比较抽象,我们看个具体例子,假设 Student 表包含三个字段,分别为 name, age, id,假设我们执行语句"select * from Student where age <= 20",这条语句执行后返回的三条记录如下:
{(name: john),(age:18),(id=1)},{(name:jim),(age:19),(id=2)},{(name:Lily),(age:20),(id=3)},{(name:mike),(age:20),(id=4)}
也就是语句执行后返回了四条记录,如果 F 对应字段 name,那么 V(s,F)=4,因为四条记录中相对于字段 name,它们的内容都不同,因此 V(s,F)=4,如果 F 对应字段 age,那么V(s,F)=3,因为四条记录中后两条对应字段 age 的数值都是 20 ,因此四条记录中相对于字段 age,数值不同的记录数就是 3.
B(s), R(s), V(s,F)在计算查询书效率的推导过程中发挥非常重要的作用。我们同时还需要主意一点是,在我们创建 SelectScan, ProductScan, ProjectScan 时,初始化函数会传入一个满足 Scan 接口的对象,例如签名代码中的 projectScan := query.NewProductionScan(selectScan, queryData.Fields()),由此对于 B(s), R(s), V(s,F)这三个公式中的 s 就对应 projectScan 这个变量,需要注意的是构造输入了一个 selectScan 实例,同时我们进入代码可以发现,projectScan 调研 Next()接口时,其实就转为调用 selectScan 的 Next 接口,于是计算 B(projectScan)其实就需要依赖的去计算 B(selectScan)。
因此我们用 s1 表示构造 s 实例所输入的参数,那么计算 B(s)就转而需要去计算 B(s1),下面我们看看 B(s), R(s), V(s,F)的推导。
第一种情况是,s 是 TableScan 的实例。由于我们在构造 TableScan 时没有输入其他 Scan 接口实例,因此 B(s), 对应的值就是 TableScan 在执行 Next 过程中所需要访问的区块数,V(s)就是TableScan 实例执行完 Next()后所遍历的记录数,V(s,F)就是它执行完 Next()调研后所遍历的记录中,针对字段 F,其数值不同的记录数。
如果 s 是 selectScan 的实例,记得该实例的构造函数还有一个 Predicate 对象,假设这个 Predicate 对应的形式为 A=c, 其中 A 表示记录中某个字段,c 是一个常量,s1 用来表示构造 selectScan 对象时传入的 Scan 对象,我们从 SelectScan 的代码可以看到,Next()接口在执行时会调用输入的 Scan 对象的 Next()接口,于是当 SelectScan 的 Next()返回时,传入的 Scan 对象访问了多少个区块,那么 SelectScan 对象就访问了对应区块,因此我们有 B(s) = B(s1),这里 s 对应 SelectScan 对象,s1 对应 构造函数传入的 Scan 对象。
我们看看R(s)的值, 我们查看SelectScan的 Scan 实现,它首先调用传入的 Scan 对象的 Next 接口去获取一条记录,然后调用Predicate 的 IsSatisfied接口来判断获取的记录是否满足过滤条件,如果满足,那么就立即返回,如果不满足就继续调用 Scan 对象的 Next 接口去获取下一条记录,直到 Scan 的 Next 返回为 False 为止。
举个例子,假设 Student 表中有 100 条记录,每条记录都包含 age 字段,假设 age 在这 100 条记录中取值情况有 4 种(这里具体取值情况关系不大,我们只需要知道取值的情况有多少种即可),于是有 V(s1, age) == 4,我们当然无法得知每种情况对应的记录条数,因此我们假设每种取值对应的记录数都相等,于是每种取值对应的记录数就是 R(s1) / V(s1, age) = 25,如果查询常量 c 取值满足 4 种情况之一,那么 SelectScan 的 Next 返回的记录数目就是 R(s1)/V(s1,age), 由此我们得出 R(s)在过滤条件满足“A=c"其中 A 对应字段,c 是一个常量,在这种情况下 R(s)取值为 R(s1)/V(s1, A)
这个问题会变得复杂,如果过滤条件为 A=B,其中 A和 B 同为表的字段。这种情况需要使用一些概率论的知识。首先假设字段 B 的取值的情况数大于字段 A,我们用 F_B 来表示字段 B 在表中的取值类别数量,用 F_A 来表示字段 A 在表中的取值类别数量。为了分析方便,我们进一步做假设,假设表有 100 条记录,其中字段 B 的取值类别有 10种,字段 A 的取值类别有 4 种,我们从表中随机取出一条记录,字段 B 取值为 10 个类别中某个类别的概率是 1 / 10,字段 A 取值正好跟字段 B 一样的概率也是 1 /10,因为字段 A 的取值要想等于 B,它也必须在 B 取值类别的范围内,而它正好取值跟当前字段 B 一样的概率也是 1 / 10,因此我们随机选出这条记录满足 A=B 的概率是 1 / 10 * 1 / 10 = 1 / 100,由于表中字段 B 可能取值的类别有 10 种,因此随机选择一条记录,它满足 A=B 的概率是 10 * 1 / 100 = 1 / 10,由此当我们遍历表中的每一条记录,能够满足 A = B 的记录数预期就是 100 * (1 / 10) = 10 条。
在上面分析中,我们假设 B 字段的取值情况数大于 A,如果是 A 的取值情况大于 B,那么分析流程一样,就是把上面 分析过程中的A,B互换即可。于是当过滤条件为 A = B ,其中 A,B 都是表中字段,那么 R(s)预期返回的记录数为 R(s1) / max{V(s1,A), V(s1,B)},由于这里涉及到一些概率论知识点,因此理解起来稍微有点复杂。
如果 s 对应的实例是 ProjectScan,那么我们从它 Next 接口的实现看,它仅仅调用了输入 Scan 对象的 Next 接口,因此后者访问了多少区块和返回多少记录,它就同样访问了多少区块和记录,因此 当 s 对应 ProjectScan 对象时,B(s)=B(s1), R(s)=R(s1), V(s,F)=V(s1,F)。
最为复杂的是 ProductScan,我们先看其实现代码,它的构造函数传入两个 Scan 对象,我们分别用 s1, s2 来表示,在其 BforeFirst()函数中,它先调用了 s1 的 Next 函数,在其 Next 函数中,如果 s2 的 Next 返回true,那么接口执行完毕,如果返回 false, 那么调用 s2 的 beforeFirst()函数将 s2 的记录指针重新指向第 1 条,然后执行 s1.Next(),也就是让 s1 的记录指向下一条,这意味着每一条来自 s1 的记录都要跟所有来自 s2 的记录相结合。
当 s1.Next()返回 false 时,ProductScan 的 Next()则返回 false,因此当 ProjectScan 的 Next()函数返回时,s1 遍历的多少区块,它也同样遍历了相同的区块。同时每当 s2的 Next 返回 false时,此时 s2 返回的区块数就是 R(s2),然后 s2 调用 BeforeFirst()接口将记录指针重新指向第一条,然后 s1 调用 Next 接口将记录指向下一条,接着 s2 再重新将所有记录再遍历一遍,这个过程它访问的区块数为 R(s2),于是在 ProductScan 的 Next()接口调用过程中,它访问了 R(s1) * B(s2) 个区块,因此综合起来它访问的区块数为 B(s1) + R(s1) * B(s2)。
对于 R(s)而言,我们在其 Next()接口中可以看到,每当 s2 遍历完所有记录后,s1 就通过 Next()指针指向下一条记录,然后 s2 再将其所有记录遍历一遍,于是 R(s) = R(s1) * R(s2)。
对 V(s,F)而言,如果 F 对应 s1 所在表中的字段,那么 V(s,F) = V(s1, F),如果对应的是s2 所在表的字段,那么 V(s,F)= V(s2, F)。
这里有一个要点在于,如果我们在构造 ProductScan 对象实例时,把两个输入的 Scan 对象互换位置,那么 B(s)的取值就会不一样,因此在构造改对象实例时,传入的 Scan 对象参数顺序不同,对其执行效率的影响也不同。
我们引入 RPB(s) = R(s) / B(s), 这个变量表示每区块对应的平均记录数量。于是 B(s) = B(s1) + R(s1) * B(s2)就可以转换为 B(s) = B(s1) + (RPB(s1) * B(s1) * B(s2)),如果我们在构造 ProductScan 的时候替换一下 s1,s2 的顺序,那么就有 B(s) = B(s2) + (RPB(s2) * B(s2) * B(s1)),由于 B(s2) * B(s1) 要远远大于 B(s1)或 B(s2),因此判断 B(s)的增长时,我们就可以忽略掉等式右边的 B(s1)或 B(s2),然后考察等式右边式子中加号右边部分,不难看出如果 RPB(s1) < RPB(s2),那么构造 ProductScan 时将 s1 放在 s2 前面,那么构造的实例在执行 Next()函数时访问的区块数就会相应要少,反之亦然。
我们看个具体例子,假设有两个表 Student, Department,其中 Student 表有字段 SId, SName,GradYear, MajorId,分别表示学生的id, 姓名,毕业时间,专业 id。Department表含有字段 DId, DName,分别表示专业 id,专业名称。
其中 Student 表对应的 B(s)有 4500,也就是它所有数据的存储占据 4500 个区块,它的 R(s)有 45000,也就是该表有 45000 条记录,V(s, SId)=45000,也就是 SId 的取值情况有 45000种,也就是每条记录对应的 SId 字段取值都不同,V(s, SName)=44960,也就是所有学生中其名字字段不同取值的情况有 44960 条,也就是 45000 个学生中有(45000 - 44960)=40 个学生,他们的名字与其他人同名,V(s, MajorId)=40,也就是这些学生分别属于 40 个不同的专业。
对于 Department 表,它对应 B(s)为 2,也就是它所有数据占据 2 个区块,R(s)=40,也就是它总共有 40 条记录,V(s, DId) = V(s, DName) = 40,也就是每条记录中字段 DId 和 DName 取值都不一样
假设我们要查找所有来自数学系的学生名字。那么首先我们要在 Department表中将 DName 字段等于”数学“的记录抽取出来,然后将所得结果与 Stduent 表做 Product 操作,最后在操作结果上查找字段 MajorId = DId 的记录,在此基础上我们再执行 Project操作,将 SName 字段抽取出来,由此对应的 sql 语句为 select Student.SName where Student.MajorId=DepartMent.DId and DepartMent.DName=“math” , 这条 sql 语句在解析后将会构造如下查询树:

根据前面代码,我们执行上面搜索树对应代码如下:
file_manager, _ := fm.NewFileManager("studentdb", 1024)
log_manager, _ := lm.NewLogManager(file_manager, "logfile.log")
buffer_manager := bmg.NewBufferManager(file_manager, log_manager, 3)
tx := tx.NewTransation(file_manager, log_manager, buffer_manager)
matedata_manager := mgm.NewMetaDataManager(true, tx)
slayout := metadata_manager.GetLayout("student", tx)
dlayout := metadata_manager.GetLayout("department",tx)
s1 := query.NewTableScan(tx, "student", slayout)
s2 := query.NewTableScan(tx, "department", dlayout)
pred1 := queryData.Pred() //对应dname = 'math'
s3 := query.NewSelectScan(s2, pred1)
s4 := query.NewProductScan(s1, s3)
pred2 := queryData.Pred() //对应 majorid=did
s5 := query.NewSelectScan(s4, pred2)
fields := queryData.Fields() //获得"sname"
s6 := query.NewProjectScan(s5, fields)
在上面代码中需要注意的是 s4,它对应 ProductScan,输入的第一个 Scan 对象是 s1,对应student 表的 TableScan 对象,它的 Next 接口会遍历所有记录,也就是 45000 条,传入的第二个 Scan 对象是s3, 它是 s2 经过 pred1 过滤后的结果,由于 Department表每条记录中 dname 字段内容都不一样,因此 s3 只包含 1 条记录。
根据 ProudctScan 代码实现,在调用其 Next接口时,它会调用一次第一个 Scan 对象的 Next 接口一次,这里这个对象对应 s1,然后调用第二个 Scan 对象的 Next 接口去遍历其所有记录,这里它对应输入的 s3,由于 s3 是SelectScan 实例,它在返回给定记录时,访问的区块数等于构造它时传入的 Scan 对象,在代码中构造 s3 的 Scan 对象是对应 Department 表的 TableScan,由于该表有 2 个区块,因此要返回给定记录,s3 需要传入的 TableScan 对象访问所有区块,于是 s3 执行完 Next 接口最多需要访问 2 个区块,由此 s4 执行 1 次 Next 接口,里面会调用构造时输入的 s1 对象,也就是对应 Student 表的 TableScan 的 Next 接口,由于该表有 45000 条记录,因此 s1 的 Next 能执行 45000次,每次执行一次 Next,就调用 s2 的 Next 一次,于是 Department 表的 2 个区块就会遍历,于是 s4 的一次 Next 执行至少就得访问 2 * 45000 次区块。
但如果我们把构造 s4 的代码改为:s4 = query.NewProductScan(s3, s1),那么 s4 执行一次 Next 接口,s3 的 Next()就会执行,由于 s3 只有 1 条记录,因此它的 Next 在代码中只执行 1 次,然后 s1 的 Next 接口会执行 45000次,于是 s1 对应数据库表的所有区块都会遍历 1 次,由于 Student 表有 4500 个区块,因此 s4 的 Next 接口只访问 4500区块,相比与前面的分析,我们仅仅是调换两个输入参数的位置,访问的区块就会大大减小,于是速度就会大大提升。
下一节我们看看如何把这节的理论用代码来实现。更多内容请在 b 站搜索 Coding 迪斯尼。