cycleGAN学习笔记
cycleGAN学习笔记
源项目:https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
1.概览
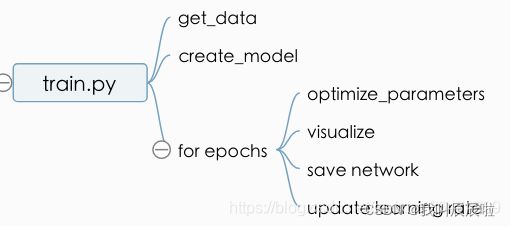
train.py
用于模型训练
–model: e.g., pix2pix, cyclegan, colorization) and
different datasets (with option --dataset_mode: e.g., aligned, unaligned, single, colorization
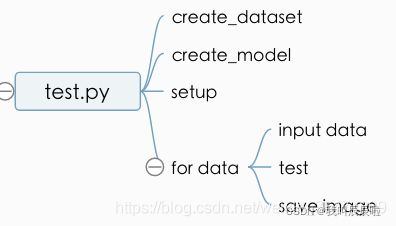
test.py
用于模型测试
data文件夹
包含关于所有数据加载数据处理的程序。
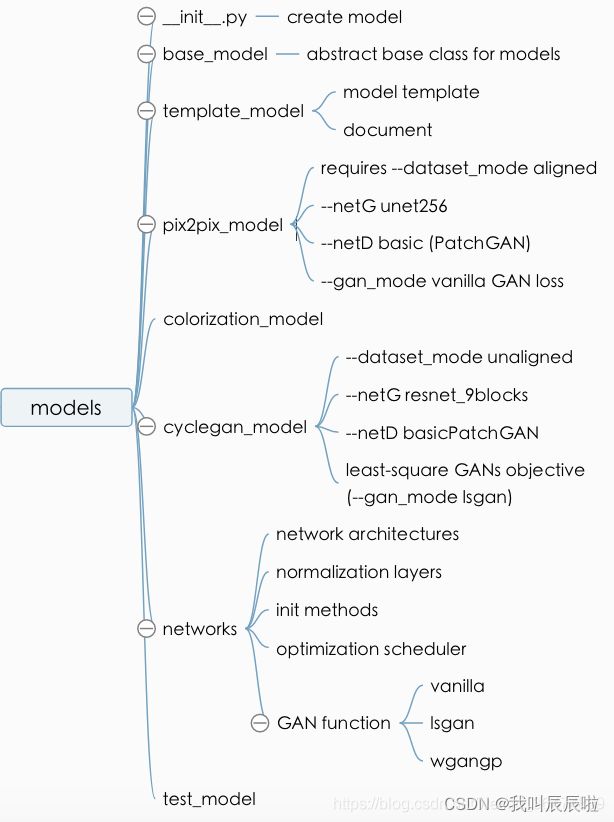
models文件夹
模型相关的objective functions, optimizations, and network architectures.
options文件夹
训练,测试以及相关模型的选项
util文件夹
相关帮助函数的杂项汇总
2.train.py
import time
from options.train_options import TrainOptions
from data import create_dataset
from models import create_model
from util.visualizer import Visualizer
if __name__ == '__main__':
# 获得数据
# get training options,在options文件夹中的train_options.py,获得训练的一些选项
opt = TrainOptions().parse()
# create a dataset given opt.dataset_mode and other options
dataset = create_dataset(opt)
dataset_size = len(dataset) # get the number of images in the dataset.
print('The number of training images = %d' % dataset_size)
# 创建模型
# create a model given opt.model and other options
model = create_model(opt)
# regular setup: load and print networks; create schedulers
model.setup(opt)
# create a visualizer that display/save images and plots
visualizer = Visualizer(opt)
total_iters = 0 # the total number of training iterations
# 训练
# outer loop for different epochs; we save the model by , +
for epoch in range(opt.epoch_count, opt.n_epochs + opt.n_epochs_decay + 1):
epoch_start_time = time.time() # timer for entire epoch
iter_data_time = time.time() # timer for data loading per iteration
# the number of training iterations in current epoch, reset to 0 every epoch
epoch_iter = 0
# reset the visualizer: make sure it saves the results to HTML at least once every epoch
visualizer.reset() # 至少一个epoch向visualizer保存结果
# update learning rates in the beginning of every epoch.
model.update_learning_rate()
for i, data in enumerate(dataset): # inner loop within one epoch
iter_start_time = time.time() # timer for computation per iteration
if total_iters % opt.print_freq == 0:
t_data = iter_start_time - iter_data_time
total_iters += opt.batch_size
epoch_iter += opt.batch_size
# unpack data from dataset and apply preprocessing
model.set_input(data)
# calculate loss functions, get gradients, update network weights
model.optimize_parameters()
# 被total_iters整除时将结果展示于visdom并存到html文件中
if total_iters % opt.display_freq == 0: # display images on visdom and save images to a HTML file
save_result = total_iters % opt.update_html_freq == 0
model.compute_visuals()
visualizer.display_current_results(
model.get_current_visuals(), epoch, save_result)
# 被total_iters整除时将loss展示于visdom并输出到工作台
if total_iters % opt.print_freq == 0: # print training losses and save logging information to the disk
losses = model.get_current_losses()
t_comp = (time.time() - iter_start_time) / opt.batch_size
visualizer.print_current_losses(
epoch, epoch_iter, losses, t_comp, t_data)
if opt.display_id > 0:
visualizer.plot_current_losses(
epoch, float(epoch_iter) / dataset_size, losses)
# 被total_iters整除时保存latest模型
if total_iters % opt.save_latest_freq == 0: # cache our latest model every iterations
print('saving the latest model (epoch %d, total_iters %d)' %
(epoch, total_iters))
save_suffix = 'iter_%d' % total_iters if opt.save_by_iter else 'latest'
model.save_networks(save_suffix)
iter_data_time = time.time()
# 被epoch整除时保存latest和对应epoch名命名的模型(这里是5)
if epoch % opt.save_epoch_freq == 0: # cache our model every epochs
print('saving the model at the end of epoch %d, iters %d' %
(epoch, total_iters))
model.save_networks('latest')
model.save_networks(epoch)
# 每个epoch结束会输出相应情况以及总时间
print('End of epoch %d / %d \t Time Taken: %d sec' % (epoch,
opt.n_epochs + opt.n_epochs_decay, time.time() - epoch_start_time))
3. test.py
import os
from options.test_options import TestOptions
from data import create_dataset
from models import create_model
from util.visualizer import save_images
from util import html
try:
import wandb
except ImportError:
print('Warning: wandb package cannot be found. The option "--use_wandb" will result in error.')
if __name__ == '__main__':
opt = TestOptions().parse() # get test options
# hard-code some parameters for test
opt.num_threads = 0 # test code only supports num_threads = 0
opt.batch_size = 1 # test code only supports batch_size = 1
# disable data shuffling; comment this line if results on randomly chosen images are needed.
opt.serial_batches = True
# no flip; comment this line if results on flipped images are needed.
opt.no_flip = True
# no visdom display; the test code saves the results to a HTML file.
opt.display_id = -1
# create a dataset given opt.dataset_mode and other options
dataset = create_dataset(opt)
# create a model given opt.model and other options
model = create_model(opt)
# regular setup: load and print networks; create schedulers
model.setup(opt)
# initialize logger
if opt.use_wandb:
wandb_run = wandb.init(project='CycleGAN-and-pix2pix',
name=opt.name, config=opt) if not wandb.run else wandb.run
wandb_run._label(repo='CycleGAN-and-pix2pix')
# create a website 创建一个网页,用于存储test集的图片
web_dir = os.path.join(opt.results_dir, opt.name, '{}_{}'.format(
opt.phase, opt.epoch)) # define the website directory
if opt.load_iter > 0: # load_iter is 0 by default
web_dir = '{:s}_iter{:d}'.format(web_dir, opt.load_iter)
print('creating web directory', web_dir)
webpage = html.HTML(web_dir, 'Experiment = %s, Phase = %s, Epoch = %s' % (
opt.name, opt.phase, opt.epoch))
# test with eval mode. This only affects layers like batchnorm and dropout.
# For [pix2pix]: we use batchnorm and dropout in the original pix2pix. You can experiment it with and without eval() mode.
# For [CycleGAN]: It should not affect CycleGAN as CycleGAN uses instancenorm without dropout.
# 利用dataset测试,通过model.test()获得相应结果,将图片存到html网页中
if opt.eval:
model.eval()
for i, data in enumerate(dataset):
if i >= opt.num_test: # only apply our model to opt.num_test images.
break
model.set_input(data) # unpack data from data loader
model.test() # run inference
visuals = model.get_current_visuals() # get image results
img_path = model.get_image_paths() # get image paths
if i % 5 == 0: # save images to an HTML file
print('processing (%04d)-th image... %s' % (i, img_path))
save_images(webpage, visuals, img_path, aspect_ratio=opt.aspect_ratio,
width=opt.display_winsize, use_wandb=opt.use_wandb)
webpage.save() # save the HTML
4.data文件夹

4.1 init.py
用于给train和test过程生成数据集
4.2 base_dataset.py
用于运用abstract base class abc。
4.3 image_folder.py
pytorch默认只从文件夹中读文件,作者可以从文件夹和子文件夹中读文件。
4.4 template_dataset.py
创建一个数据集的模板,以及详细的描述
4.5 aligned_dataset.py
用于加载样本对(主要用于pix2pix,对于我们的cycleGAN并无太大作用)
4.6 unaligned_dataset.py
用于unpaired 数据集,用于cycleGAN,训练时trainA 和trainB 中应该放入domainA和domainB中的东西,test时也是这样。
4.7 single、clolorization dataset
- image_folder.py implements an image folder class. We modify the official PyTorch image folder code so that this class can load images from both the current directory and its subdirectories.
- template_dataset.py provides a dataset template with detailed documentation. Check out this file if you plan to implement your own dataset.
- aligned_dataset.py includes a dataset class that can load image pairs. It assumes a single image directory /path/to/data/train, which contains image pairs in the form of {A,B}. See here on how to prepare aligned datasets. During test time, you need to prepare a directory /path/to/data/test as test data.
- unaligned_dataset.py includes a dataset class that can load unaligned/unpaired datasets. It assumes that two directories to host training images from domain A /path/to/data/trainA and from domain B
/path/to/data/trainB respectively. Then you can train the model with the dataset flag --dataroot /path/to/data. Similarly, you need to prepare two directories /path/to/data/testA and /path/to/data/testB during test time. - single_dataset.py includes a dataset class that can load a set of single images specified by the path --dataroot /path/to/data. It can be used for generating CycleGAN results only for one side with the model option -model test.
- colorization_dataset.py implements a dataset class that can load a set of nature images in RGB, and convert RGB format into (L, ab) pairs in Lab color space. It is required by pix2pix-based colorization model (–model colorization).
5.models
cycelGAN整体架构:
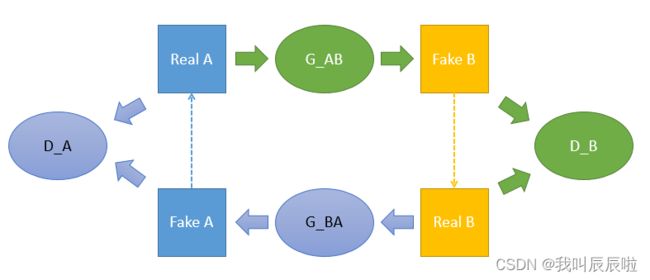
G网络的训练架构
loss有三个部分:Identity loss,GAN loss,cycle loss

D-A网络的训练架构
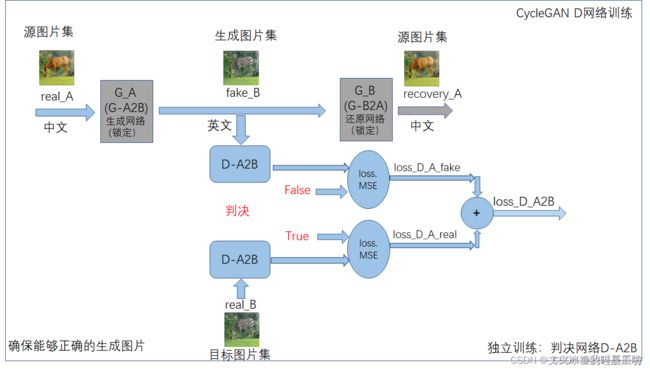
D-B网络的训练架构
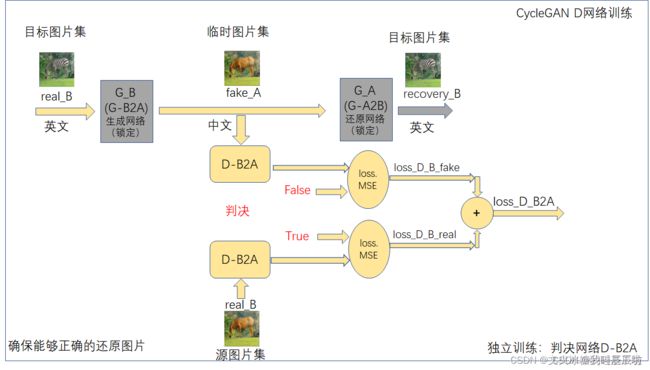
6.options和util

