【十四】XJCO3221 Parallel Computation-Introduction to GPGPU programming
1Overview
Previous lectures
So far we have looked at CPU programming.
- Shared memory systems, where lightweight threads are mapped to cores (scheduled by the OS) [Lectures 2-7].
- Distributed memory systems, with explicit communication for whole processes [Lectures 8-13].
- Many common parallelism issues (scaling, load balancing, synchronisation, binary tree reduction).
- Also some unique to each type (locks and data races for shared memory; explicit communication for distributed memory).
Today’s lecture
Today’s lecture is the first of 6 on programming GPUs (Graphics Processing Units) for general purpose calculations.
- Sometimes referred to as GPGPU programming for General Pupose Graphics Processing Unit programming.
- GPU devices contain multiple SIMD units.
- Different memory types, some ‘shared’ and some that can be interpreted as ‘distributed.’
- Programmable using a variety of C/C++-based languages, notably OpenCL and CUDA.
2Anatomy of a GPU
2.1Development of GPUs
Development of GPUs
Early accelerators were driven by graphical operating systems and high-end applications (defense, science and engineering etc.).
- Commercial 2D accelerators from early 1990s.
- OpenGL released in 1992 by Silicon Graphics.
Consumer applications employing 3D dominated by video games.
- First person shooters in mid-90s (Doom, Quake etc.)
- 3D graphics accelerators by Nvidia, ATI Technologies, 3dfx.
- Initially as external graphics cards
Programmable GPUs
- The first programmable graphics cards were Nvidia’s GeForce3 series (2001). Supported DirectX 8.0, which includes programmable vertex and pixel shading stages of the graphics pipeline.
- Increased programming support in later versions.
Early general purpose applications ‘disguised’ problems as being graphical.
- 1 Input data converted to pixel colours.
- 2 Pixel shaders performed calculations on this data.
- 3 Final ‘colours’ converted back to numerical data.
GPGPUs
In 2006 Nvidia released its first GPU with CUDA.
- General calculations without converting to/from colours.
Now have GPUs that are not intended to generate graphics.
- Modern HPC clusters often include GPUs.
- e.g. Summit has multiple Nvidia Volta GPUs per node.
- Vendors include Nvidia, AMD and Intel.
Originally designed for data parallel graphics rendering.
- Increasing use of GPUs for e.g. machine learning1 and cryptocurrencies.
2.2Overview of GPU architectures
Overview of GPU architectures
Design and terminology of GPU hardware differs between vendors.
- Nvidia different to AMD different to Intel different to . . .
Typically will have ‘a few’ SIMD processors:
- SIMD: Single Instruction Multiple Data.
- Streaming multiprocessors in Nvidia devices.
SIMD processors contain SIMD function units or SIMD cores:
- Each SIMD core contains multiple threads.
- Executes the same instruction on multiple data

SIMD processor
A typical SIMD processor has:
- A thread scheduler
- Multiple SIMD function units (‘f.u.’) or SIMD cores, each with 32/64/etc. threads.
- Local memory
Not shown but usually present: Registers, special floating point units, . . .
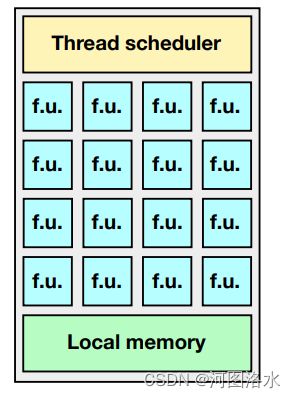
Thread scheduling is performed in hardware.
CPU with a single GPU
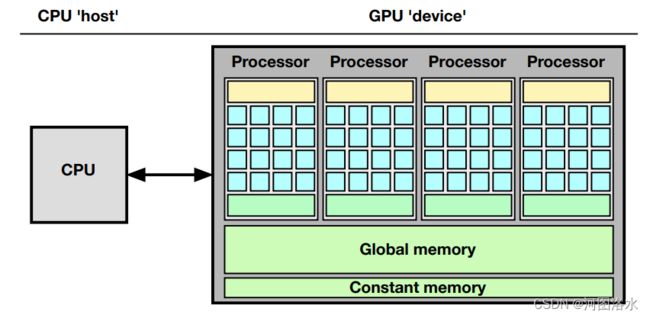 The data bus between CPU and GPU is very slow.
The data bus between CPU and GPU is very slow.
Faster for integrated GPUs
SIMD versus SIMT
Nvidia refer to their architectures as SIMT rather than SIMD.
- Single Instruction Multiple Threads.
- Conditionals can result in different operations being performed by different threads.
- However, cannot perform different instructions simultaneously.
- Therefore ‘in between’ SIMD and MIMD.
Will look at this more closely in Lecture 17, where we will see how it can be detrimental to performance.
3General purpose programming on a GPU
3.1Avaliable languages
GPU programming languages 1. CUDA
The first language for GPGPU programming was Nvidia’s CUDA.
- Stands for Common Unified Device Architecture.
- C/C++-based (a FORTRAN version also exists).
- First released in 2006.
- Only works on CUDA-enabled devices, i.e. Nvidia GPUs
As the first GPGPU language it has much documentation online. Therefore we will reference CUDA concepts and terminology quite frequently, often in footnotes.
GPU programming languages 2. OpenCL
Currently the main alternative to CUDA is OpenCL (2008).
- Stands for Open Computing Language.
- Maintained by the Khronos group after proposal by members of Apple, AMD, IBM, Intel, Nvidia and others.
- Runs on any (modern) GPU, not just Nvidia’s.
- Can also run on CPUs, FPGAs (=Field-Programmable Gate Arrays), . . . .
- C/C++ based. Similar programming model to CUDA.
- OpenCL 3.0 released Sept. 2020.
Directive based programming abstractions
OpenACC (2011):
- Open ACCelerator, originally intended for accelerators.
- Uses #pragma acc directives.
- Limited (but growing) compiler support — e.g. gcc 7+.
OpenMP:
- GPU support from version 4.0 onwards, esp. 4.5 (gcc 6+).
- Usual #pragma omp directives, with target to denote GPU.
Both give portable code, but both require some understanding of the hierarchical nature of GPU hardware to produce reasonable performance.
3.2Installing and building OpenCL
Installing OpenCL
Otherwise, download drivers and runtime for your GPU architecture:
- Nvidia: https://developer.nvidia.com/opencl
- Intel: https://software.intel.com/en-us/intel-opencl/download
- AMD: https://www.amd.com/en and search for OpenCL.
OpenCL header file
All OpenCL programs need to include a header file. Since the name and location is different between Apple and other UNIX systems, most of the example code for this module here will have the following near the start:
# ifdef __APPLE__
# include < OpenCL / opencl .h >
# else
# include < CL / cl .h >
# endifCompiling and running
We use the CUDA nvcc compiler
nvcc - lOpenCL -o < executable > < source >. cNote there is no ‘-Wall’ option for nvcc.
Executing: To execute on a GPU it will be necessary to use the batch queue (see next slide). However, it is also possible to run an OpenCL code on the login node’s CPU by launching as any normal executable:
./ < executable > [ any command line arguments ]
Running on GPU via batch jobs
Hence GPU jobs should be executed via the batch queue using the following approach:
Compile your code as described in previous slide;
Create a job submission script as outlined below;
Submit ot the batch queue using sbatch in the usual manner.
Here is a typcal batch script to run “gpu-example”: #!/bin/bash #SBATCH --partition=gpu --gres=gpu:t4:1 ./gpu-example
3.3Platforms, devices and contexts
Since OpenCL runs on many different devices by many different vendors, it can be quite laborious to initialise.
Need to determine:

Initialisation code
Most code for this module will come with helper.h, which contains two useful routines:
simpleOpenContext GPU()
Finds the first GPU on the first platform. Prints an error message and exit()s if one could not be found.
compileKernelFromFile()
Compiles an OpenCL kernel to be executed on the device. Will cover this next lecture.
You don’t need to understand how these routines work, but are welcome to take a look.
Using simpleOpenContext GPU()
1# include " helper .h" // Also includes OpenCL .
2 int main () {
3 // Get context and device for a GPU.
4 cl_device_id device ;
5 cl_context context = simpleOpenContext_GPU (& device ) ;
6
7 // Open a command queue to it.
8 cl_int status ;
9 cl_command_queue queue = clCreateCommandQueue (
context , device ,0 ,& status ) ;
10
11 ... // Use the GPU through ’queue ’.
12
13 // At end of program .
14 clReleaseCommandQueue ( queue ) ;
15 clReleaseContext ( context ) ;
16 }
4‘Hello world’ in OpenCL
displayDevices.c
Since most GPU’s cannot print in the normal sense, there is no simple ‘Hello World’ program.
Instead, try the code displayDevices.c (which doesn’t use helper.h).
- Loops through all platforms and devices.
- Lists all OpenCL-compatible devices.
- Also a list of extensions; e.g. cl khr fp64 means that device supports double precision floating point arithmetic.
- In the output, a compute unit is a SIMD processor or streaming multiprocessor.
5 Summary and next lecture
Today we have started looking at GPU programming:
- Overview of GPU architectures.
- Options for programming: OpenCL, CUDA, . . .
- How to install, compile and run an OpenCL program.
- displayDevices.c, which lists all OpenCL-enabled devices using the functions: clGetPlatformIDs clGetDeviceIDs