“spark三剑客”之SparkStreaming流式计算框架
一 流式计算概述
1.1 什么的流式计算
数据流 VS 静态数据
| 数据流 | 静态数据 |
| 不断产生的数据 | 存储在磁盘中的固定的数据 |
流式计算的概念
对数据流进行计算,由于数据是炼苗不断的产生的,所以这个计算也是一直再计算,不会停止
流式计算的数据流 VS 离线计算(特点大PK)
| 流式计算的数据流 | 离线计算 |
| 数据是无界的(unbounded) | 数据是有界的(unbounded) |
| 数据是动态的 | 数据是静态的 |
| 计算速度是非常快的,还是基于内存的 | 计算速度通常较慢 |
| 计算不止一次 | 计算只执行一次 |
| 算不能终止 | 计算终会终止 |
1.2 常见的两者计算框架
| 离线计算框架 | 流式计算框架 |
| mapreduce | storm |
| hive | parkStreaming |
| sparkcore | parkStreaming |
| sparksql | |
| flink-dataset |
1.3 SparkStreaming简介
1.3.1 介绍
Spark生态栈中的一个重要模块,是一个流式计算框架
SparkStreaming属于准实时计算框架
是SparkCore的api的一种扩展,使用DStream(离散流)作为数据模型。 本质就是一个时间序列上的RDD。
DStream,本质上是RDD的序列。SparkStreaming的处理流程可以归纳为下图:

流式计算框架从延迟的角度来分类:
| 纯实时流式计算 | 准实时流式计算 |
| 毫秒基本,没有延迟 来一条记录处理一条记录 |
亚秒级别,分钟级别的计算 微小的批处理 |
1.3.2 原理
1. SparkStreaming 会实时的接受输入的数据
2. SparkStreaming 会按照固定长度的时间段将源源不断进来的数据划分成batch
3. SparkStreming 会每一个batch进行一次计算,计算是不停止的
4. 每次的计算结果也是一个batch,因此结果集就是多个batch的构成
5. SparkStreaming,将数据流抽象成DStream. 称之为离散流的数据模型。本质就是一个时间序列上的RDD。
6. 在整个数据流作业中,会有多个DStream。
参考下图: rdd1 就是一个时间序列上的 DStream
rdd2 就是一个时间序列上的 DStream
rdd3 就是一个时间序列上的 DStream
rdd4 就是一个时间序列上的 DStream
8:00:00 hello world hello java hello c++
rdd1 = sc.textFile("....")
rdd2 = rdd1.flatMap(_.split(" "))
rdd3 = rdd2.map((_,1))
rdd4 = rdd3.reduceByKey(_+_)
针对于rdd1来说:
8:00:00 hello world hello java hello c++
8:00:10 no zuo no die
8:00:20 you are best
8:00:30: hello you are best
针对于rdd2来说:
8:00:00 [hello, world,hello,java,hello,c++]
8:00:10 [no,zuo,no,die]
8:00:20 [you,are,best]
8:00:30: [hello,you,are,best]
针对于rdd3来说:
8:00:00 (hello,1), (world,1),(hello,1),(java,1),(hello,1),(c++,1)
8:00:10 (no,1),(zuo,1),(no,1),(die,1)
8:00:20 (you,1),(are,1),(best,1)
8:00:30: (hello,1),(you,1),(are,1),(best,1)
参考下图: 一个DStream是由不同时间段上的同一个RDD构成的

参考下图:如果算子的返回值是DStream,则不管是哪一个时间段上的数据,只要调用了同一个算子,则返回的都同一个DStream

1.3.3 Storm VS SparkStreaming VS Flink
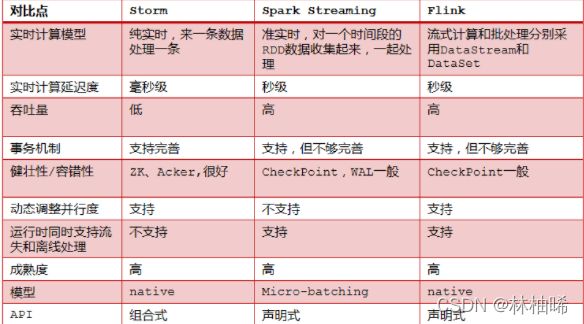
1.4 怎样选择流式处理框架
| storm | Spark Streaming | Flink |
| 需要纯实时,不能忍受1秒以上延迟的场景 | 如果一个项目除了实时计算之外,还包括了离线批处理、交互式查询、图计算和MLIB机器学习等业务功能,而且实时计算中, 可能还会牵扯到高延迟批处理、交互式查询等功能 |
支持高吞吐、低延迟、高性能的流处理 |
| 数据的处理完全精准,一条也不能多,一条也不能少 | 支持带有事件时间的窗口(Window)操作 | |
| 针对高峰低峰时间段,动态调整实时计算程序的并行度,以最大限度利用集群资源(通常是在小型公司,集群资源紧张的情况) | 支持有状态计算的Exactly-once语义 | |
| 支持高度灵活的窗口(Window)操作, 支持基于time、count、session,以及 data-driven的窗口操作 |
||
| 支持具有Backpressure功能的持续流 模型 |
||
| 支持基于轻量级分布式快照(Snapshot) 实现的容错 |
||
| 一个运行时同时支持Batch on Streamin g处理和Streaming处理 |
||
| 支持迭代计算 | ||
| 支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存 | ||
二、SparkStreaming的入门编程
pom.xml
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
4.0.0
org.example
redis
1.0-SNAPSHOT
org.apache.spark
spark-streaming_2.11
2.2.3
org.apache.spark
spark-streaming-kafka-0-10_2.11
2.2.3
redis.clients
jedis
3.0.0
org.apache.spark
spark-sql_2.11
2.2.3
❥(^_-) 个人总结: sparkstreaming的编程框架是这样的
package com.qf.bigdata
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Durations, StreamingContext}
object Demo06 {
def main(args: Array[String]): Unit = {
val context = new StreamingContext(new SparkConf().setMaster("local[*]").setAppName("wordcount"),Durations.seconds(10))
//这里就是自定义ETL操作
context.start()
context.awaitTermination()
}
}
2.1 wordcount案例演示
服务器中:nc -lp 10086
1) 获取sparkconf的入口
2)获取streaming上下文(conf,Seconds(10))
3)可以获取上下文对象使用socketTextStream(主机名,端口)
4)按照空格切分单词
5)拆分元组
6)统计单词数量
7)打印
8)启动程序
9)线程阻塞
package com.qf.sparkstreaming.day01
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}/**
* sparkCore的入门api: SparkContext
* sparkSql的入门: SparkSession
* sparkStreaming的入门API: StreamingContext
*
*
* 注意:
* 1. 要先使用nc指令 开启qianfeng01和10086端口,否则sparkStreaming会提前报错
* 在qianfeng01上运行指令: nc -lp 10086
* -l 表示监听
* -p 表示端口
*/
object Streaming_01_WordCount {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")/**
* 构造器:StreamingContext(conf:SparkConf, batchDuration:Duration)
* 第一个参数:配置对象
* 第二个参数:用于指定SparkStreaming的流式计算的batch的时间间隔,即时间片段
* Durations.milliseconds(milliseconds: Long) 毫秒级别
* Durations.seconds(seconds: Long) 秒级别
* Durations.minutes(minutes: Long) 分钟级别
* Milliseconds(milliseconds: Long) 毫秒级别
* Seconds(seconds: Long) 秒级别
* Minutes(minutes: Long) 分钟级别
*/
val context = new StreamingContext(conf, Seconds(10))/**
* 利用TCP协议的套接字,实时的监听一个端口,如果有数据,就采集,并计算。
* socketTextStream(hostname: String,port: Int,......)
* T: 泛型
* hostname: 要监听的主机名
* port:要监听的端口号
*
*/
val dStream: ReceiverInputDStream[String] = context.socketTextStream("qianfeng01", 10086)
// 打印数据流中的数据,默认打印10条记录
//dStream.print()// 按照空格切分成各个单词, 返回的是一个新的DStream
val wordDStream: DStream[String] = dStream.flatMap(_.split(" "))//构建成元组,返回一个新的DStream
val wordAndOneDStream: DStream[(String, Int)] = wordDStream.map((_, 1))//进行统计每个单词的数量,返回的是一个新的DStream
val wordCountDStream: DStream[(String, Int)] = wordAndOneDStream.reduceByKey(_ + _)//打印,默认打印10条
wordCountDStream.print()//启动程序
context.start()/**
* 因为main方法一旦结束,整个程序就结束,因此需要让main方法处于等待状态
*/
context.awaitTermination()}
}
我自己的代码
package com.qf.bigdata
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object Demo05 {
def main(args: Array[String]): Unit = {
val context = new StreamingContext(new SparkConf().setMaster("local[*]").setAppName("wordcount"),Seconds(10))
val DStream:ReceiverInputDStream[String] = context.socketTextStream("qianfeng01",10086)
//DStream.print()
val wordCount = DStream.flatMap(_.split("\\s+")).map((_,1)).reduceByKey(_+_).print()
context.start()
context.awaitTermination()
}
}

运行

2.2 从内存中的Queue中获取数据
package com.qf.sparkstreaming.day01
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.{Durations, StreamingContext}import scala.collection.mutable
/**
* 从内存中的Queue中获取数据
*/
object Streaming_02_FromQueue {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("FromQueue")
val ssc:StreamingContext = new StreamingContext(conf,Durations.seconds(10))/**
* queueStream[T: ClassTag]( queue: Queue[RDD[T]],oneAtATime: Boolean = true)
* 从一个RDD队列中获取一个或多个RDD数据,进行处理。
* queue:RDD队列
* oneAtATime: 是否一次处理一个RDD,默认值是true。 false表示队列中有多少,就一次性处理多少。 注意:从队列中获取数据时,队列中就没有该数据了。
*/
val queue = new mutable.Queue[RDD[Int]]()
val dStream: InputDStream[Int] = ssc.queueStream(queue,true)//直接打印,默认打印10行
dStream.print()//开启数据流作业
ssc.start()/**
* 利用main线程,向队列中源源不断的添加RDD。
*/
val rdd: RDD[Int] = ssc.sparkContext.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8))
for(i<- 1 to 300){
queue.enqueue(rdd)//将rdd填入队列中
Thread.sleep(1000)
// println(queue.size) //如果将oneAtATime改为false,则可证明队列中的数据每10秒都会被清空。
}// 该方法的作用就是阻塞main方法,不让其结束。因为main方法已结束,就会停止数据流作业
ssc.awaitTermination()
}
}
package com.qf.bigdata
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
import scala.collection.mutable
object Demo06 {
def main(args: Array[String]): Unit = {
val context = new StreamingContext(new SparkConf().setMaster("local[*]").setAppName("wordcount"),Durations.seconds(10))
val queue = new mutable.Queue[RDD[Int]]()
val dStream:InputDStream[Int] = context.queueStream(queue,true)
dStream.print()
context.start()
val rdd:RDD[Int] = context.sparkContext.makeRDD( List(1,2,3,4,5,6,7,8))
for(i <- 1 to 8){
queue.enqueue(rdd) //把rdd填入队列中
Thread.sleep(1000)
}
context.awaitTermination()
}
}
2.3 自定义接收器
自定义接受器就是重写接收器方法的两个方法,一个开始方法就是存放数据以及保存数据,一个是定义结束方法
package com.qf.bigdata
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Durations, StreamingContext}
object Demo06 {
def main(args: Array[String]): Unit = {
val context = new StreamingContext(new SparkConf().setMaster("local[*]").setAppName("wordcount"),Durations.seconds(10))
//从采集器中获取DStream
val dStream = context.receiverStream(new MyReceiver())
dStream.flatMap(_.split("\\s+")).map((_,1)).reduceByKey(_+_).print(20)
context.start()
context.awaitTermination()
}
class MyReceiver() extends Receiver[String] (StorageLevel.MEMORY_ONLY){
var flag = true
//开启采集数据的方法,方法是框架主动调用
override def onStart(): Unit = {
var t = new Thread(){
override def run(): Unit ={
while(flag){
val list = List("hello world hello java hello java",
"hello world welcome to china hello",
"hello world hello java c++")
val element:String = list(math.floor(math.random * 3).toInt)
//使用采集器的存储方法存储数据
store(element)
Thread.sleep(200)
}
}
}
t.start() //开启线程
}
//对于采集到结束时间,终止采集数据
override def onStop(): Unit = {flag = false}
}
}
2.4 读取本地文件
val DStream = context.textFileStream("D:\\data\\a.txt")
DStream.flatMap(_.split("\\s+")).map((_,1)).reduceByKey(_+_).print(3)
2.5 读取HDFS文件
val dStream: DStream[String] = context.textFileStream("hdfs://qianfeng01:8020/input")
dStream.flatMap(_.split("\\s+")).map((_,1)).reduceByKey(_+_).print(200)
三、SparkStreaming与Kafka的整合
3.1 简介
在实际生产环境中,kafka用的比较多,用于消息缓存,而SparkStreaming是一个准实时计算框架,所以两者的结合在企业中的用的相对较多。
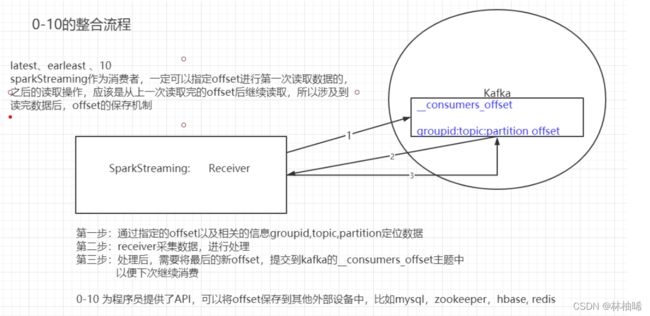
两者的整合有两个版本,一个是0-8(低版本),一个是0-10(新版本)
注意区别就是下面的三个SSL、Offset Commit API Dynamic Topic Subscription

3.2 两个版本的原理图解析
1) 0-8的原理解析图

2)0-10的原理解析图
3.3 SparkStreaming消费Kafka
包
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Durations, StreamingContext}
核心代码
var params = Map[String,String](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG->"qianfeng01:9092,qianfeng02:9092,qianfen03:9092",
ConsumerConfig.GROUP_ID_CONFIG->"g1",
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG->"earliest",
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG->"org.apache.kafka.common.serialization.StringDeserializer",
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG->"org.apache.kafka.common.serialization.StringDeserializer"
)
val dStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(context, LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](List("pet"), params))
dStream.map(_.value()).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print(200)
/**
* 使用0-10的整合API KafkaUtils.createDirectStream(
* sc:StreamingContext, : 上下文对象
* locationStrategy:LocationStrategy, : 位置策略,经常使用的是LocationStrategies.PrePreferConsistent 该策略指的是spark的RDD的一个分区对应kafka的一个分区
* consumerStrategy: ConsumerStrategy[K, V], : 消费者策略,用于订阅主题的等
* .....
* )
*/
3.4 维护offset到zookeeper上
自定义了一个MyZkUtils
package com.qf.bigdata
import org.apache.curator.RetryPolicy
import org.apache.curator.framework.CuratorFrameworkFactory
import org.apache.curator.retry.ExponentialBackoffRetry
import org.apache.kafka.common.TopicPartition
import org.apache.spark.streaming.kafka010.OffsetRange
import java.util
object MyZkUtils {
/**
* 将消费后的偏移量保存到zk上
* @param groupid
* @param ranges
*
* OffsetRange对象上的属性:topic,partition,fromOffset,untilOffset
*/
def updateOffset(groupid: String, ranges: Array[OffsetRange]): Unit = {
for(range <- ranges){
val untilOffset: Long = range.untilOffset
val partition =range.partition
val topic = range.topic
//保存到相应的路径里: /kafka/offsets/groudid/topic/partition
checkPath(s"$basePath/$groupid/$topic/$partition")
zkClient.setData().forPath(s"$basePath/$groupid/$topic/$partition",untilOffset.toString.getBytes())
}
}
val zkClient = {
//获取连接zk的客户端api
val zkClient = CuratorFrameworkFactory
.builder()
.connectString("qianfeng01:2181,qianfeng02:2181,qianfeng03:2181")
.retryPolicy(new ExponentialBackoffRetry(5000,6))
.build()
zkClient.start()
zkClient
}
val basePath = "/kafka/offsets"
/**
* 检查路径是否存在,不存在就创建
* @param path
* @return
*/
def checkPath(path: String) = {
if(zkClient.checkExists().forPath(path)==null){
//创建znode,递归创建
zkClient.create().creatingParentsIfNeeded().forPath(path)
}
}
/**
* 获取zk上某一个消费者组下的某些主题的分区里的offset
*
* @param groupid 消费者组
* @param topics 消费的主题集合
* @return
*
*
* 维护的znode路径如 :/kafka/offsets/groupid/topic/partition
*/
def getOffset(groupid: String, topics: Array[String]): Map[TopicPartition, Long] = {
//创建一个map对象,用于存储每个分区和相应的偏移量
var offsets = Map[TopicPartition, Long]()
//遍历每一个主题
for(topic <- topics){
val path = s"$basePath/$groupid/$topic"
checkPath(path) //执行完这一步,路径一定存在
//获取主题znode下的所有分区znode
val partitionsZnodes: util.List[String] = zkClient.getChildren.forPath(path)
//遍历每一个分区, 注意:如果主题下没有分区,表示还没有维护offset到zk上,循环进不去
import scala.collection.JavaConversions._
for(partitionZnode <- partitionsZnodes){
//获取partition里存储的offset
val bytes: Array[Byte] = zkClient.getData.forPath(s"$path/$partitionZnode")
val offset = new String(bytes).toLong
offsets += (new TopicPartition(topic,partitionZnode.toInt)->offset)
}
}
offsets
}
def main(args: Array[String]): Unit = {
zkClient.create().forPath("/names")
}
}
核心代码
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, HasOffsetRanges, KafkaUtils, LocationStrategies, OffsetRange}
import org.apache.spark.streaming.{Durations, StreamingContext}
val params = MyKafkaUtils.getParamToMap()
//sparkstreaming要消费的主题
val topics = Array("pet")val offsets:Map[TopicPartition,Long] = MyZkUtils.getOffset(params.getOrElse("group.id","g1"),topics)
print(offsets.size)
var dStream:InputDStream[ConsumerRecord[String, String]] = null
if(offsets.size>0) {
//不是第一次读取Kafka上的数据,而是其他时候,比如宕机并恢复后,应该从zk上保存的offset开始读取
dStream = KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, params,offsets)
)
}else{
//第一次读取Kafka上的数据
dStream= KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topics, params)
)
}dStream.foreachRDD(rdd=>{
rdd.foreach(println)
//将当前数据流中的最后一条记录的offset维护到zk上
val ranges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
//将每个分区的untilOffset保存到zk上
MyZkUtils.updateOffset(params.getOrElse("group.id","g1"),ranges)
})